


Alexander 的观点很明确:未来 AI 智能体的发展方向还得是模型本身,而不是工作流(Work Flow)。还拿目前很火的 Manus 作为案例:他认为像 Manus 这样基于「预先编排好的提示词与工具路径」构成的工作流智能体,短期或许表现不错,但长期必然遇到瓶颈。这种「提示驱动」的方式无法扩展,也无法真正处理那些需要长期规划、多步骤推理的复杂任务。
而下一代真正的 LLM 智能体,则是通过「强化学习(RL)与推理(Reasoning)的结合」来实现的。文章举例了 OpenAI 的 DeepResearch 和 Anthropic 的 Claude Sonnet 3.7,说明未来智能体会自主掌控任务执行的全过程,包括动态规划搜索策略、主动调整工具使用等,而不再依靠外部提示或工作流驱动。这种转变意味着智能体设计的核心复杂性将转移到模型训练阶段,从根本上提升模型的自主推理能力,最终彻底颠覆目前的应用层生态。
文章转载自「宝玉 AI」的翻译,结构略有调整。

-
高浓度的主流模型(如 DeepSeek 等)开发交流;
-
资源对接,与 API、云厂商、模型厂商直接交流反馈的机会;
-
好用、有趣的产品/案例,Founder Park 会主动做宣传。
01
模型即产品(The Model is the Product)
过去几年里,人们不断猜测下一轮 AI 的发展方向:会是智能体(Agents)?推理模型(Reasoners)?还是真正的多模态(Multimodality)?
但现在,是时候下结论了:
AI 模型本身,就是未来的产品。
目前,无论是研究还是市场的发展趋势,都在推动这个方向。
为什么这么说?
-
通用型模型的扩展,遇到了瓶颈。GPT-4.5 发布时传递的最大信息就是:模型的能力提升只能呈线性增长,但所需算力却在指数式地飙升。尽管过去两年 OpenAI 在训练和基础设施方面进行了大量优化,但仍然无法以可接受的成本推出这种超级巨型模型。
-
定向训练(Opinionated training)的效果,远超预期。强化学习与推理能力的结合,正在让模型迅速掌握具体任务。这种能力,既不同于传统的机器学习,也不是基础大模型,而是某种神奇的第三形态。比如一些极小规模的模型突然在数学能力上变得惊人强大;编程模型不再只是简单地产生代码,甚至能够自主管理整个代码库;又比如 Claude 在几乎没有专门训练、仅靠非常贫乏的信息环境下,竟然也能玩宝可梦。
-
推理(Inference)的成本,正在极速下降。DeepSeek 最新的优化成果显示,目前全球所有可用的 GPU 资源,甚至足以支撑地球上每个人每天调用一万个顶尖模型的 token。而实际上,目前市场根本不存在这么大的需求。简单卖 token 赚钱的模式已经不再成立,模型提供商必须向价值链更高层发展。
但这个趋势也带来了一些尴尬,因为所有投资人都将宝压在了「应用层」上。然而,在下一阶段的 AI 革命中,最先被自动化、被颠覆的,极有可能就是应用层。
02
下一代 AI 模型的形态
过去几周,我们看到了两个典型的「模型即产品」的案例:OpenAI 推出的 DeepResearch 和 Anthropic 推出的 Claude Sonnet 3.7。
关于 DeepResearch,很多人存在误解,这种误解随着大量仿制版本(开源和闭源)的出现,变得更严重了。实际上,OpenAI 并非简单地在 O3 模型外面套了层壳,而是从零开始训练了一个全新的模型*。
*OpenAI 的官方文档:https://cdn.openai.com/deep-research-system-card.pdf
这个模型能直接在内部完成搜索任务,根本不需要外部调用、提示词或人工流程干预:
「该模型通过强化学习,自主掌握了核心的网页浏览能力(比如搜索、点击、滚动、理解文件)……它还能自主推理,通过大量网站的信息合成,直接找到特定的内容或生成详细的报告。」
DeepResearch 不是标准的大语言模型(LLM),更不是普通的聊天机器人。它是一种全新的研究型语言模型(Research Language Model),专为端到端完成搜索类任务而设计。任何认真用过这个模型的人都会发现,它生成的报告篇幅更长,结构严谨,内容背后的信息分析过程也极为清晰。
相比之下,正如 Hanchung Lee 所指出*的,其他的 DeepSearch 产品,包括 Perplexity 和 Google 版,其实不过就是普通模型加了一点额外的小技巧:
*https://leehanchung.github.io/blogs/2025/02/26/deep-research/
「虽然谷歌的 Gemini 和 Perplexity 的聊天助手也宣称提供了『深度搜索』的功能,但他们既没有公开详细的优化过程,也没有给出真正有分量的量化评估……因此我们只能推测,它们的微调工作并不显著。」
Anthropic 的愿景也越来越明确。去年 12 月,他们给出了一个颇有争议,但我认为相当准确的「智能体」定义*。与 DeepSearch 类似,一个真正的智能体必须在内部独立完成任务:「智能体能够动态地决定自己的执行流程和工具使用方式,自主掌控任务的完成过程。」
*Anthropic 的定义:https://www.anthropic.com/research/building-effective-agents
但市面上大多数所谓的智能体公司,目前做的根本不是智能体,而是「工作流」(workflows):
也就是用预先定义好的代码路径,串联 LLM 与其他工具。这种工作流仍然有一定价值,尤其是在特定领域的垂直应用上。但对于真正从事前沿研究的人来说,很明显:未来真正的突破,必须是直接从模型层面入手,重新设计 AI 系统。
Claude 3.7 的发布,就是一个实实在在的证明:Anthropic 专门以复杂的编程任务为核心训练目标,让大量原本使用工作流模型(比如 Devin)的产品,在软件开发(SWE)相关的评测中表现大幅提升。
再举一个我们公司 Pleias 更小规模的例子:
我们目前正在探索如何彻底自动化 RAG(基于检索的生成系统)。
现阶段的 RAG 系统由许多复杂但脆弱的流程串联而成:请求路由、文档切分、重排序、请求解释、请求扩展、来源上下文理解、搜索工程等等。但随着模型训练技术的进步,我们发现完全有可能把这些复杂流程整合到两个相互关联的模型中:
一个专门负责数据准备,另一个专门负责搜索、检索、生成报告。这种方案需要设计一套非常复杂的合成数据管道,以及完全全新的强化学习奖励函数。
这是真正的模型训练,真正的研究。
03
这一切对我们意味着什么?
意味着复杂性的转移。
通过训练阶段预先应对大量可能的行动和各种极端情况,部署时将变得异常简单。但在这个过程中,绝大部分价值都将被模型训练方创造,并且最终被模型训练方所捕获。
简单来说,Anthropic 想要颠覆并替代目前的那些所谓「智能体」工作流,比如像 llama index 的这种典型系统:
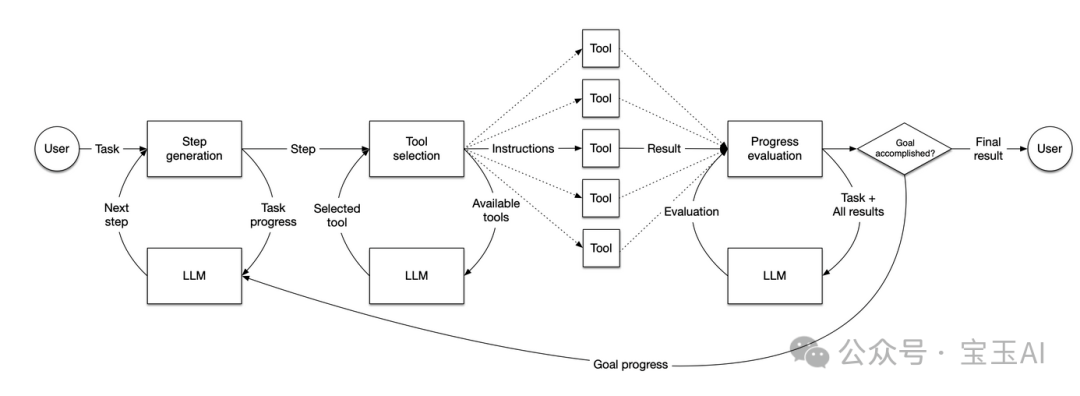
Llama Index Basic Agent
转变为这种完全模型化的方案:
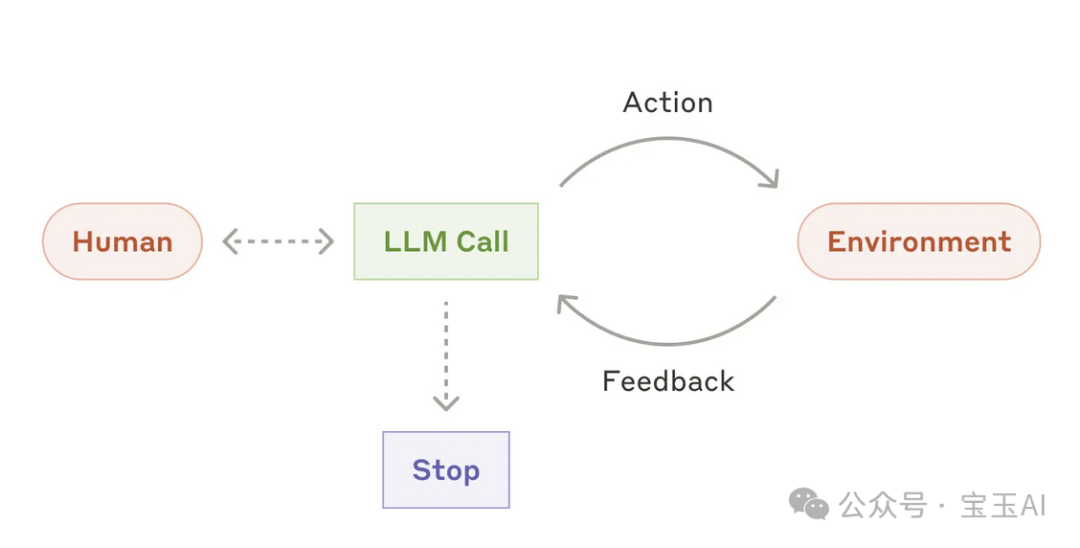
Claude Agent
04
模型供应商与应用开发商
的蜜月期结束了
目前 AI 的大趋势已经明朗:
未来 2-3 年内,所有闭源 AI 大模型提供商都会停止向外界提供 API 服务,而将转为直接提供模型本身作为产品。
这种趋势并非猜测,而是现实中的多重信号都指向了这一点。Databricks 公司生成式 AI 副总裁 Naveen Rao 也做了清晰的预测:
在未来两到三年内,所有闭源的 AI 模型提供商都会停止销售 API 服务。
简单来说,API 经济即将走向终结。模型提供商与应用层(Wrapper)之间原本的蜜月期,已彻底结束了。
市场方向可能的变化:
-
Claude Code 和 DeepSearch都是这种趋势的早期技术与产品探索。你可能注意到,DeepSearch 并未提供 API 接口,仅作为 OpenAI 高级订阅的增值功能出现;Claude Code 则只是一个极为简单的终端整合。这清晰表明,模型厂商已开始跳过第三方应用层,直接创造用户价值。
-
应用层企业开始秘密地布局模型训练能力。当前成功的应用型公司,也都意识到了这种威胁,悄悄尝试转型。例如 Cursor 拥有一款自主开发的小型代码补全模型;WindSurf 内部开发了 Codium 这样一款低成本的代码模型;Perplexity 此前一直依靠内部分类器进行请求路由,最近更是转型训练了自己的 DeepSeek 变体模型用于搜索用途。
-
当前成功的「应用套壳商」(Wrappers)实际上处于困境之中:他们要么自主训练模型,要么就等着被上游大模型彻底取代。他们现在所做的事情,本质上都是为上游大模型厂商进行免费的市场调研、数据设计和数据生成。
接下来发生什么还不好说。成功的应用套壳商现在陷入两难处境:「自己训练模型」或者「被别人拿来训练模型」。据我所知,目前投资者对「训练模型」极为排斥,甚至使得一些公司不得不隐藏他们最具价值的训练能力,像 Cursor 的小模型和 Codium 的文档化至今都极为有限。
05
市场完全没有计入
强化学习(RL)的潜力
目前 AI 投资领域存在一个普遍的问题:所有投资几乎都是高度相关的。
现阶段几乎所有的 AI 投资机构,都抱持以下一致的想法:
-
封闭 AI 厂商将长期提供 API;
-
应用层是 AI 变现的最佳途径;
-
训练任何形式的模型(不论预训练还是强化学习)都是在浪费资源;
-
所有行业(包括监管严格的领域)都会继续长期依赖外部 AI 提供商。
但我不得不说,这些判断日益看起来过于冒险,甚至是明显的市场失灵。
尤其是在最近强化学习(RL)技术取得突破的情况下,市场未能正确对强化学习的巨大潜力进行定价。
眼下,「强化学习」的威力根本没有被资本市场准确评估和体现。
从经济学角度看,在全球经济逐渐迈入衰退背景下,能够进行模型训练的公司具有巨大的颠覆潜力。然而很奇怪的是,模型训练公司却根本无法顺利获得投资。以西方的新兴 AI 训练公司 Prime Intellect 为例,它拥有明确的技术实力,有潜力发展为顶级 AI 实验室,但即便如此,其融资仍面临巨大困难。
纵观欧美,真正具备训练能力的新兴 AI 公司屈指可数:
Prime Intellect、EleutherAI、Jina、Nous、HuggingFace 训练团队(规模很小)、Allen AI 等少数学术机构,加上一些开源基础设施的贡献者,基本涵盖了整个西方训练基础设施的建设和支持工作。
而在欧洲,据我所知,至少有 7-8 个 LLM 项目正在使用 Common Corpus 进行模型训练。
然而,资本却对这些真正能够训练模型的团队冷眼旁观。
「训练」成为被忽略的价值洼地
最近,甚至连 OpenAI 内部也对目前硅谷创业生态缺乏「垂直强化学习」(Vertical RL)表达了明显的不满。

我相信,这种信息来自于 Sam Altman 本人,接下来可能会在 YC 新一批孵化项目中有所体现。
这背后的信号非常明确:大厂将倾向于直接与掌握垂直强化学习能力的创业公司合作,而不仅仅依赖应用层套壳。
这种趋势也暗示了另一个更大的变化:
未来很多最赚钱的 AI 应用场景(如大量仍被规则系统主导的传统产业)尚未得到充分开发。谁能训练出真正针对这些领域的专用模型,谁就能获得显著优势。而跨领域、高度专注的小型团队,也许才更适合率先攻克这些难题,并最终成为大型实验室潜在收购的目标。
但令人担忧的是,目前大部分西方 AI 企业还停留在「纯应用层」的竞争模式上。甚至大部分人都没有意识到:
仅靠应用层打下一场战争的时代已经结束了。
相比之下,中国的 DeepSeek 已经走得更远:它不再仅仅把模型视作产品,而是视为一种通用的基础设施。正如 DeepSeek 创始人连文峰在公开采访中明确指出:
「就像 OpenAI 和 Anthropic 一样,我们将计划直接公开说明:DeepSeek 的使命并不是仅仅打造单个产品,而是提供一种基础设施层面的能力……我们会首先投入研究和训练,将其作为我们的核心竞争力。」
可惜的是,在欧美,绝大部分 AI 初创公司仍只专注于构建单纯的应用层产品,这就如同「用过去战争的将领去打下一场新战争」,甚至根本没意识到上一场战争其实已经结束了。
06
关于简单 LLM 智能体的「苦涩教训」
最近被热炒的 Manus AI 属于典型的「工作流」。我整个周末的测试*都在不断验证着这种系统的根本性局限,而这些局限早在 AutoGPT 时代就已经显现出来。尤其是在搜索任务中,这种局限表现得极为明显:
*https://techcrunch.com/2025/03/09/manus-probably-isnt-chinas-second-deepseek-moment/
-
它们缺乏真正的规划能力,经常在任务进行到一半时就「卡住」了,无法推进;
-
它们无法有效地记忆长期的上下文,通常任务持续超过 5 到 10 分钟便难以维持;
-
它们在长期任务中表现很差,多个步骤的任务会因为每一步的细微误差被放大,导致最终失败。
今天我们尝试从这个全新的、更严格的角度出发,重新定义 LLM 智能体的概念。以下内容,是在整合了来自大公司有限的信息、开放研究领域近期成果,以及我个人的一些推测之后,做的一次尽可能清晰的总结。
智能体这个概念,本质上几乎与基础的大语言模型完全冲突。
在传统的智能体研究中,智能体(Agent)总是处于一个有约束的环境里:比如想象一下你被困在一个迷宫里,你可以向左走,也可以向右走,但你不能随便飞起来,也不能突然钻进地下,更不能凭空消失——你会受到物理规则甚至游戏规则的严格限制。真正的智能体,即便处于这种约束环境中,也会拥有一些自由度,因为你有多种方式来完成游戏。但无论怎么行动,每一次决策背后,都需要你有明确的目标:赢得最终的奖励。有效的智能体会逐渐记忆过去走过的路,形成一些有效的模式或经验。
这种探索的过程,被称为 「搜索(search)」。而这个词其实非常贴切:一个智能体在迷宫中的探索行为,和人类用户在网络搜索时不停点击链接,探索自己想要的信息,几乎是完美的类比。关于「搜索」的研究,学界已经有几十年的历史。举一个最新的例子:Q-star 算法(曾被传言是 OpenAI 新一代模型背后的算法,当然至今还没完全确认)其实来源于 1968 年的 A-Star 搜索算法。而最近由 PufferLib 完成的宝可梦训练实验,就生动地展现了这种智能体「搜索」的全过程:我们看到智能体不断尝试路径,失败后再重试,不断地往返摸索最优路径。

Pokemon RL experiment by PufferLib
基础语言模型和智能体的运行方式几乎截然相反:
-
智能体会记住它们的环境,但基础语言模型不会。语言模型只根据当前窗口内的信息来回应。
-
智能体有明确的理性约束,受限于实际条件,而基础语言模型只是生成概率较高的文本。虽然有时它们也能表现出前后一致的逻辑,但始终无法保证,甚至随时可能因为「美学需求」而脱离轨道。
-
智能体能制定长期策略,它们可以规划未来的行动或回溯重来。但语言模型只擅长单一推理任务,在面对需要多步复杂推理的问题时,很快就会「饱和」(multi-hop reasoning),难以处理。整体来看,它们被文本规则约束,而不是现实世界的物理或游戏规则。
将语言模型与智能体化结合的最简单方法,就是通过预定义的提示(prompt)和规则来约束输出。目前绝大部分的语言模型智能体系统都是这种方式,然而这种做法注定会撞上 Richard Sutton 提出的「苦涩教训」(Bitter Lesson)。
人们经常误解「苦涩教训」,认为它是指导语言模型预训练的指南。但它本质上讲的是关于智能体的设计,讲的是我们往往想直接把人类的知识「硬编码」到智能体当中——例如「如果你碰壁了,就换个方向;如果多次碰壁,就回头再试试」。这种方法在短期来看效果很好,很快就能看到进步,不需要长时间训练。但长期来看,这种做法往往走向次优解,甚至会在意料之外的场景里卡住。
Sutton 这样总结道:
「我们必须学会苦涩的教训:人为地去预设我们思考的方式,长期来看并不奏效。AI 研究的历史已经反复验证:
1)研究者经常试图将知识提前写入智能体;
2)这种做法短期内效果明显,也让研究者本人很有成就感;
3)但长期来看,性能很快达到上限,甚至阻碍后续发展;
4)最终的突破反而来自完全相反的方法,即通过大量计算资源进行搜索和学习。最终的成功让人有些苦涩,因为它否定了人们偏爱的、以人为中心的方法。」
我们再把这个道理迁移到现在 LLM 的生产应用中。像 Manus 或常见的 LLM 封装工具,都在做着「人为设定知识」的工作,用提前设计好的提示语引导模型。这或许短期内最省事——你甚至不需要重新训练模型——但绝不是最优选择。最终你创造的是一种混合体,部分靠生成式 AI,部分靠规则系统,而这些规则恰恰就是人类思维中对空间、物体、多智能体或对称性等概念的简单化抽象。
更直白地讲,如果 Manus AI 至今无法很好地订机票,或在与老虎搏斗时提出有用建议,并不是因为它设计得差,而是它遭遇了「苦涩教训」的反噬。提示(Prompt)无法无限扩展,对规则硬编码无法无限扩展。你真正需要的是从根本上设计能够搜索、规划和行动的真正的 LLM 智能体。
07
强化学习(RL)+ 推理:
真正的成功之路
这是一个很难的问题。现在公开的信息很少,只有 Anthropic、OpenAI、DeepMind 等少数实验室了解细节。到目前为止,我们只能根据有限的官方消息、非正式传言以及少量的公开研究来了解一些基本情况:
-
与传统智能体类似,LLM 智能体同样采用强化学习进行训练。你可以把语言模型的学习看作一个「迷宫」:迷宫里的道路就是关于某件事可能写出来的所有文字组合,迷宫的出口就是最终想要的「奖励」(reward)。而判断是否抵达奖励的过程就称为「验证器」(verifier)。William Brown 的新开源库 Verifier 就是专门为此设计的工具。目前的验证器更倾向于针对数学公式或代码这样的明确结果进行验证。然而,正如 Kalomaze 所证明的,即使针对非严格验证的结果,通过训练专门的分类器,也完全可以构建有效的验证器。这得益于语言模型的一个重要特点:它们评估答案的能力远远优于创造答案的能力。即使用规模较小的语言模型来做「评委」,也能明显提高整体性能和奖励机制的设计效果。
-
LLM 智能体的训练是通过「草稿」(draft)来完成的,即整个文本被生成后再被评估。这种方式并不是一开始就确定的,最初研究倾向于对每个单独的词汇(token)展开搜索。但后来由于计算资源有限,以及近期推理(Reasoning)模型取得突破性的进展,「草稿式」推理逐渐成为主流训练方式。典型的推理模型训练过程,就是让模型自主生成多个逻辑步骤,最终选择那些能带来最佳答案的草稿。这可能会产生一些出人意料的现象,比如 DeepSeek 的 R0 模型偶尔在英文与中文之间突然切换。但强化学习并不在乎看起来是不是奇怪,只在乎效果是否最好。就像在迷宫里迷路的智能体一样,语言模型也必须通过纯粹的推理寻找出路。没有人为预定义的提示,没有提前规定好的路线,只有奖励,以及获得奖励的方法。这正是苦涩教训所给出的苦涩解决方案。
-
LLM 的草稿通常会被提前划分为结构化的数据片段,以方便奖励的验证,并在一定程度上帮助模型整体的推理过程。这种做法叫做「评分标准工程」(rubric engineering),既可以直接通过奖励函数来实现,也可以在大实验室更常见的方式下,通过初步的后训练阶段完成。
-
LLM 智能体通常需要大量草稿数据以及多阶段训练。例如,当进行搜索任务训练时,我们不会一下子评价搜索结果,而是评价模型获取资源的能力、生成中间结果的能力、再获取新资源、继续推进、改变计划或回溯等等。因此,现在训练 LLM 智能体最受青睐的方法是 DeepSeek 提出的GRPO,特别是与 vllm 文本生成库配合时效果最佳。前几周,我还发布了一个非常受欢迎的代码笔记本(Notebook),基于 William Brown 的研究成果,仅使用 Google Colab 提供的单个 A100 GPU,就成功地实现了 GRPO 算法。这种计算资源需求的大幅下降,毫无疑问将加速强化学习与智能体设计在未来几年真正走向大众化。
08
等一下,
这东西怎么规模化?
上面说的那些内容都是基础模块。从这里出发,想走到 OpenAI 的 DeepResearch,以及现在各种新兴的、能处理一连串复杂任务的智能体,中间还隔着一段距离。允许我稍微展开一点联想。
目前,开源社区的强化学习(RL)和推理研究,主要集中在数学领域,因为我们发现网上有很多数学习题的数据,比如一些被打包进 Common Crawl 里的题库,再被 HuggingFace 的分类器抽取出来(比如 FineMath)。但是,很多其他领域,特别是「搜索」,我们是没有现成数据的。因为搜索需要的不是静态的文本,而是真实的行动序列,比如用户浏览网页时的点击、查询日志、行为模式等等。
我之前做过一段时间的日志分析,当时模型(尽管还是用马尔科夫链这种比较老旧的方法,虽然最近几年这个领域飞速发展了)居然还经常用上世纪 90 年代末泄露出来的 AOL 搜索数据训练!近来,这个领域终于多了一个关键的开源数据集:维基百科的点击流数据(Wikipedia clickstream),这个数据集记录了匿名用户从一篇维基百科文章跳到另一篇文章的路径。但我问你一个简单的问题:这个数据集在 HuggingFace 上有吗?没有。事实上,HuggingFace 上几乎没有真正具备「行动性」(agentic)的数据,也就是说,这些数据能帮助模型学习规划行动。目前整个领域依然默认要用人工设计的规则系统去「指挥」大语言模型(LLM)。我甚至怀疑,连 OpenAI 或者 Anthropic 这种大厂,也未必能拿到足够数量的这种数据。这是传统科技公司,尤其是谷歌这样的公司,依然占据巨大优势的地方——毕竟,你不可能随便买到谷歌积累的海量用户搜索数据(除非数据在暗网上泄露了某些片段)。
但其实有一种解决办法,就是模拟生成数据,也就是「仿真」。传统的强化学习模型是不需要历史数据的,它们通过反复不断的尝试,探索并学会环境里的各种规律和策略。如果我们把这种方式用到搜索任务上,就会类似于游戏领域的 RL 训练:让模型自由探索,找到正确答案时给奖励。可是,在搜索领域,这种探索可能会非常漫长。比如你想找到某个特别冷门的化学实验结果,可能隐藏在 1960 年代某篇苏联老论文里,模型只能靠暴力搜索和语言上的一些微调,一次又一次地尝试后终于偶然找到了答案。然后,模型再尝试理解并总结出那些能提高下次找到相似答案可能性的规律。
我们算一下这种方式的成本:以一种典型的强化学习方法为例,比如 GRPO,你一次可能同时有 16 个并发的探索路径(我甚至猜测大实验室的真实训练并发数远不止 16 个)。每个探索路径都可能连续浏览至少 100 个网页,那意味着一次小小的训练步骤里就要发出大概 2,000 次搜索请求。而更复杂的强化学习训练,往往需要数十万甚至上百万个步骤,尤其是想让模型拥有通用的搜索能力的话。这意味着一次完整训练可能需要数亿次的网络请求,说不定会把一些学术网站顺便给 DDOS 攻击了……这样一来,你真正的瓶颈反倒不再是计算资源,而变成了网络带宽。
游戏领域的强化学习也碰到了类似的问题,这也是为什么现在最先进的方法(比如 Pufferlib)会把环境重新封装成「对模型而言看起来像雅达利游戏的样子」,其实本质没变,只不过模型能看到的数据是高度标准化的、经过优化的。当把这个方法应用到搜索上时,我们可以直接利用现成的 Common Crawl 大规模网络数据,把这些数据「伪装」成实时的网页返回给模型,包括 URL、API 调用和各种 HTTP 请求,让模型误以为它正在真实地访问网络,而实际上所有数据早就提前准备好了,直接从本地的高速数据库里查询就可以了。
所以,我估计未来要训练一个能够搜索的 LLM 强化学习智能体,可能的方式会是这样的:
-
先创建一个大型的模拟搜索环境,这个环境的数据集是固定的,但在训练时不断「翻译」成模型能理解的网页形式反馈给模型。
-
在强化学习正式训练之前,先用一些轻量的有监督微调(SFT)给模型「预热」一下(类似 DeepSeek 的 SFT-RL-SFT-RL 这种训练路线),用的可能是一些已经有的搜索模式数据,目的是让模型提前熟悉搜索思考的逻辑和输出格式,从而加速后面的 RL 训练。这类似一种人为设定好的训练「模板」。
-
然后,需要准备一些难度不同的复杂查询问题,以及对应的明确的验证标准(verifier)。具体操作可能是搭建复杂的合成数据管道,从现有资源反向推导出这些标准,或者干脆直接雇佣一批博士级别的专家来手动打标签(代价非常高昂)。
-
接下来就是真正的多步强化学习训练了。模型收到一个查询后,会主动发起搜索,得到结果后,可以进一步浏览网页,或者调整搜索关键词,这个过程是分成多个连续步骤的。从模型角度来看,就像是在真实地浏览互联网,而实际上背后的一切数据交换都是提前准备好的搜索模拟器在完成。
-
当模型足够擅长搜索之后,可能还会再做一轮新的强化学习(RL)和监督微调(SFT),但这一次的重心转向「如何写出高质量的最终总结」。这步很可能也会用到复杂的合成数据管道,让模型将之前输出的长篇内容切成小片段,再经过某种推理重新组装起来,提升它生成结果的质量和逻辑连贯性。
09
真正的智能体,
是不靠「提示词」工作的
终于,我们真正拥有了「智能体」(Agent)模型。那么相比原本的工作流程或模型编排来说,它到底带来了哪些变化?只是单纯提高了质量,还是意味着一种全新的范式?
我们先回顾一下 Anthropic 对智能体的定义:「大语言模型(LLM)智能体能动态地自主指挥自己的行动和工具使用,并始终掌控完成任务的具体方式。」为了更直观地理解这一点,我再用一个我熟悉的场景举个例子:搜索。
之前业内曾广泛猜测,随着大语言模型拥有了更长的上下文窗口,传统的「检索增强生成」(RAG)方法会逐渐消亡。但现实情况并非如此。原因有几个:超长上下文计算成本太高,除了简单的信息查询外,准确性不够,并且很难追溯输入的来源。因此,真正的「智能体搜索」并不会完全取代 RAG。更可能发生的是,它会高度自动化,帮我们把复杂的向量数据库、路由选择、排序优化等过程自动整合。未来一个典型的搜索过程可能会是这样的:
-
用户提出问题后,智能体会分析并拆解问题,推测用户的真实意图。
-
如果问题模糊,智能体会主动向用户提问,以便进一步确认(OpenAI 的 DeepResearch 已经能做到这一点)。
-
然后,模型可能会选择进行一般性搜索,也可能根据情况直接选择特定的专业数据源。由于模型记住了常见的 API 调用方式,它可以直接调用对应的接口。为了节约计算资源,智能体会更倾向于利用网络上已有的 API、站点地图(sitemaps)以及结构化的数据生态。
-
搜索过程本身会被模型不断学习和优化。智能体能够自主判断并放弃错误的搜索方向,并像经验丰富的专业人员一样,转而尝试其他更有效的路径。目前 OpenAI 的 DeepResearch 一些非常惊艳的结果就展示了这种能力:即便某些资源没有被很好地索引,它也能通过连续的内部推理找到准确的资源。
-
整个搜索过程中,智能体的每一步决策和推理都会留下清晰的内部记录,从而实现一定程度的可解释性。
简单来说,搜索过程将会被智能体直接「工程化」。智能体不需要额外的数据预处理,而是直接基于现有搜索基础设施去灵活应变,寻找最佳路径。同时,用户也无需专门训练就能与生成式 AI 高效交互。正如 Tim Berners-Lee 十多年前所强调的:「一个真正的智能体,就是在每个具体场景中,都能自动完成用户心里想做却没明确说出来的事情。」
我们再将这种实际的智能体思路应用到其他领域去看一下实际效果:比如一个网络工程智能体,也将能直接与现有基础设施交互,自动生成路由器、交换机、防火墙的配置方案,根据需求分析网络拓扑结构、给出优化建议,或自动解析错误日志,定位网络问题的根本原因。
再比如金融领域的智能体,未来则能够自动、精准地实现不同金融数据标准之间的转换,比如从 ISO 20022 到 MT103 标准的翻译。以上这些能力,现阶段通过简单的系统提示(system prompts)是根本做不到的。
然而,目前能够真正开发出这样智能体的公司只有少数几个巨头实验室。他们手握所有关键资源:专有技术、部分关键数据(或者制造这些数据的合成技术),以及将模型变成产品的整体战略眼光。这种技术高度集中未必是一件好事,但某种程度上,也要归咎于资本市场对模型训练长期价值的低估,使得这一领域的创新发展受到限制。
我通常不喜欢过度炒作某些新概念,但智能体背后蕴藏的巨大颠覆潜力和商业价值,让我坚信我们迫切需要民主化地推动实际智能体的训练和部署:公开验证模型、GRPO(目标导向的奖励策略优化)的训练数据样本,以及在不久的将来,公开复杂的合成数据管道和仿真器等基础设施。
2025 年会是智能体崛起的一年吗?或许还有机会,我们拭目以待。
(文:Founder Park)