


作者:椰椰,大头
编辑:大头
本文已获得张宁老师授权发布,转载请联系本公众号
2025 Meet AI Compiler 第 7 期技术沙龙于 7 月 5 日在北京中关村圆满落幕。来自 AMD 的 AI 架构师张宁,在「助力开源社区,剖析 AMD Triton 编译器」为题的演讲中,围绕公司在开源社区的技术贡献,系统解读了 AMD Triton 编译器的核心技术、底层架构支撑及生态建设成果,为开发者深入理解高性能 GPU 编程与编译器优化提供了全面视角。本文为张宁老师的分享精华实录。
7 月 5 日,由 HyperAI超神经主办的 Meet AI Compiler 技术沙龙第 7 期如约而至。虽是盛夏酷暑,依旧挡不住大家的热情——现场座无虚席,不少小伙伴甚至全程站着听完每一场分享。来自 AMD、沐曦集成电路、字节跳动、北京大学的多位讲师轮番登台,从底层编译到实际落地,带来了深刻的行业洞察与趋势分析,干货满满!
关注微信公众号「HyperAI超神经」,后台回复关键字「0705 AI 编译器」,即可获取确认授权的讲师演讲 PPT。
✦
•
✦




✦
左右滑动,查看更多
✦
作为一种专为简化高性能 GPU Kernel 开发而设计的编程语言,Triton 凭借简化复杂并行计算编程的特性,已成为 LLM 推理与训练框架中的关键工具。其核心优势在于平衡开发效率与硬件性能——既避免了底层硬件细节的暴露,又能通过编译器优化释放 GPU 算力,这一特点使其在开源社区迅速普及。
身为 GPU 领域的领军企业,AMD 率先实现了对 Triton 语言的支持,并将相关代码贡献至开源社区,推动 Triton 生态的跨厂商兼容。这一举措不仅强化了 AMD 在高性能计算领域的技术影响力,更通过开源协作模式,为全球开发者提供了更灵活的 GPU 编程选择,尤其是在大模型训练与推理场景中,为算力优化提供了新路径。
在以「助力开源社区,剖析 AMD Triton 编译器」为题的演讲中,来自 AMD 的 AI 架构师张宁围绕公司在开源社区的技术贡献,系统解读了 AMD Triton 编译器的核心技术、底层架构支撑及生态建设成果,为开发者深入理解高性能 GPU 编程与编译器优化提供了全面视角。
HyperAI超神经在不违原意的前提下,对张宁老师的演讲分享进行了整理汇总,以下为演讲实录。
Triton:高效编程,实时编译,灵活迭代
Triton 由 OpenAI 提出,是一种专为简化高性能 GPU 内核开发设计的开源编程语言和编译器,在主流 LLM 推理训练框架中应用广泛。其核心特性包括:
* 高效编程,能简化 Kernel 开发,让开发者无需深入了解复杂的 GPU 底层架构即可高效编写 GPU 代码;
* 实时编译,支持即时编译,可动态生成和优化 GPU 代码以适应不同硬件与任务需求;
* 灵活的迭代空间结构,基于分块程序和标量线程,增强了迭代空间灵活性,便于处理稀疏操作和优化数据局部性。
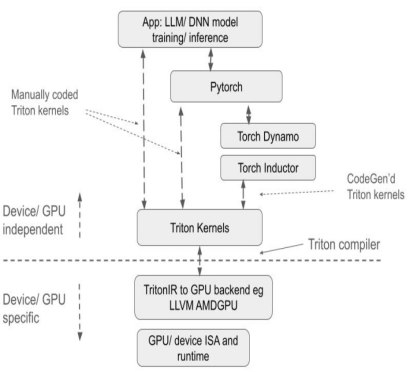
相比传统方案,Triton 的优势显著:
首先,作为开源项目,Triton 提供基于 Python 的编程环境,用户通过开发 Python Triton 代码实现 GPU Kernel,无需关注底层 GPU 架构细节,大幅降低开发难度,相比 AMD HIP 等其他 GPU 编程方式能显著提升产品开发效率。其编译器会借助多种基于GPU架构特性的优化策略,将 Python 代码转换为优化后的 GPU 汇编代码,实现上层张量操作到底层 GPU 指令的自动编译,保障代码在 GPU 上高效运行。
其次,Triton 具备良好的跨硬件兼容性,同一套代码理论上可运行在英伟达、AMD 的 GPU 以及支持 Triton 的国产 GPU 等多种硬件上。在性能与灵活性上,相比 PyTorch 等平台能提供更好性能和优化灵活性,相比 CUDA 等则能够隐藏底层 GPU 操作细节,让开发者更专注于算法实现。
相较于 PyTorch API,更加专注于计算操作的具体实现,允许开发者灵活地定义线程块切分方式,操作 Block/Tile 级别数据读写,并执行硬件相关的计算原语,特别适宜开发算子融合、参数调优等性能优化策略;
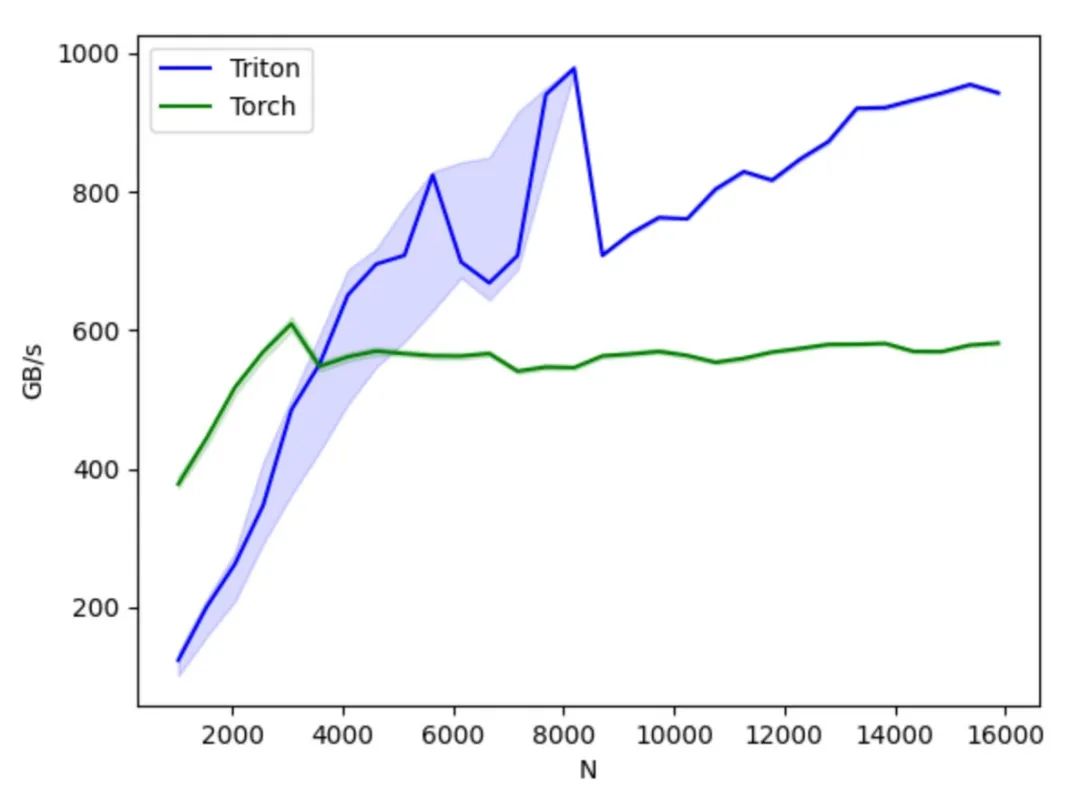
相较于 CUDA,Triton 隐藏了线程级别的操作控制,改由编译器自动接管共享存储、线程并行、合并访存、张量布局等细节,降低了并行编程模型的难度,同时提高了 GPU 代码的开发效率,达到开发效率和程序性能的有效均衡;开发者可以集中于算法的设计实现,而无需过度关心底层硬件细节和编程优化技巧,只要理解简单的并行编程原理,即可快速开发性能较佳的 GPU 代码。
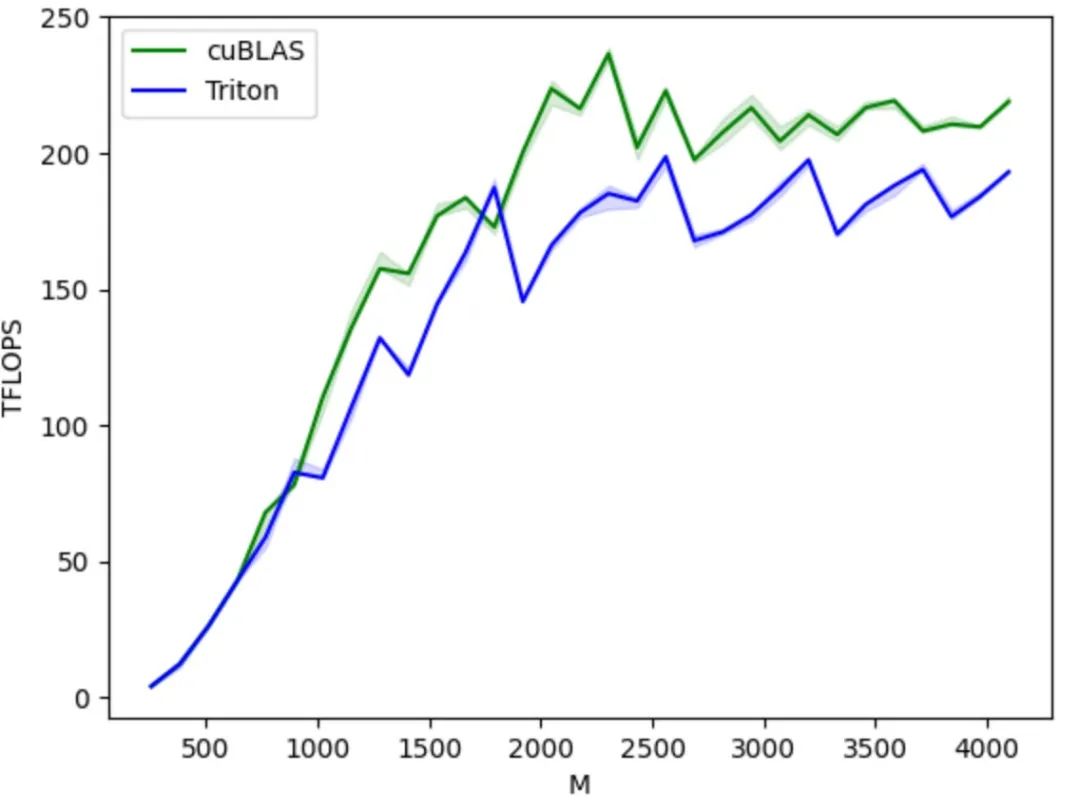
从生态角度来看,它基于 Python 语言环境,使用 PyTorch 定义的张量数据类型,其函数可以无缝融入到 PyTorch 生态体系。相对于 CUDA 的封闭,Triton 的代码开源和生态开放,也方便 AI 芯片厂商将其移植到自研芯片,利用开源社区来完善自己的工具链,同时也促进了 Triton 生态的健康发展。
AMD Triton 编译器流程
Triton 编译器包括 3 个关键模块:前端模块、优化器模块和后端机器码生成模块,下图所示:
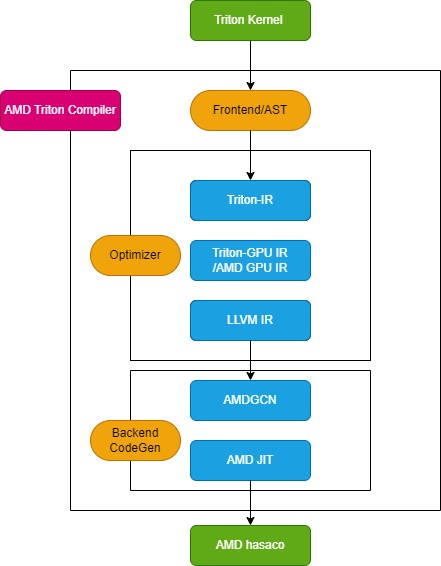
Triton 编译器模块图
前端模块
前端模块会遍历 Python Triton 内核函数的抽象语法树(AST),以创建 Triton 中间表示(Triton-IR),其内核函数会被转换为 Triton-IR。例如,标有 @triton.jit 装饰器的 add_kernel 内核函数在这个模块中会被转成相应的 IR。JIT 装饰器入口函数首先检查 TRITON_INTERPRET 环境变量的值,如果该变量为 True,则调用 InterpretedFunction,以解释模式运行 Triton 内核;如果为 False,则运行 JITFunction,在实际设备上编译并执行 Triton 内核。
内核编译的入口点是 Triton compile 函数,该函数会与目标设备及编译选项信息一起调用。此过程将创建内核缓存管理器,启动编译流水线,并填充内核元数据。此外,它还加载特定于后端的方言,例如用于 AMD 平台的 TritonAMDGPUDialect,以及处理 LLVM-IR 编译的后端专用 LLVM 模块。如果所有准备工作就绪,将调用 ast_to_ttir 函数生成该内核的 Triton-IR 文件。
优化器模块
优化器模块分为 3 个核心部分:Triton-IR 优化、Triton-GPU IR 优化和 LLVM-IR 优化。
* Triton-IR 优化
在 AMD 平台上,Triton-IR 优化流程由 make_ttir 函数定义。在这一阶段,优化过程与硬件无关,包括内联优化、通用子表达式消除、规范化、死代码消除、循环不变代码移动以及循环展开。
* Triton-GPU IR 优化
在 AMD 平台上,Triton-IR 优化流程由 make_ttgir 函数定义,用于提升 GPU 性能。基于 AMD GPU 特点和优化经验,我们还开发了特定的优化流程,如下图所示:
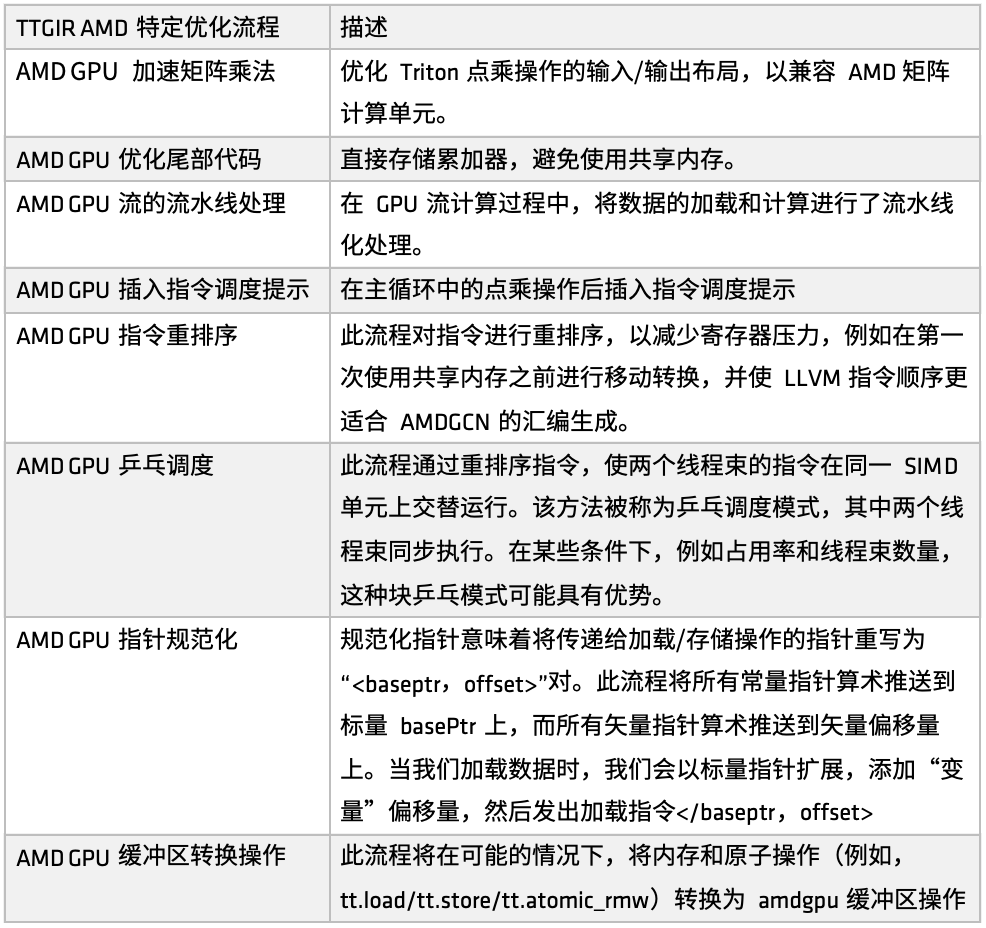
AMD GPU-IR 特定优化
首先,针对 AMD GPU 的加速矩阵乘法,优化重点在于 Triton 中点乘操作的输入/输出布局,使其更好地兼容 AMD 的矩阵计算单元(如 Matrix)。该优化涉及大量针对 CDNA 架构的匹配处理,是整个实现中工作量较大的一部分。如果希望在 AMD 平台上对 Triton 生成的代码进行深度优化,这部分实现值得重点参考。
其次,在尾部处理阶段,优化策略为直接存储累加器,从而避免使用共享内存,减少共享内存的访问压力,提高整体效率。
接着,在 GPU 流计算过程中,引入了加载与计算的流水线化处理。即在前一个任务执行的同时,调用相应的内存进行数据加载,形成加载与计算并行执行的模式。这种机制在许多用户场景中已有良好效果。在流水线优化基础上,还引入了指令调度提示,用于在计算单元或远程操作完成后对指令流进行引导,提升指令级别的响应效率。
随后,AMD 实现了多套针对不同目标的指令重排序,包括:缓解寄存器压力、避免冗余资源分配与释放、优化加载-计算流程的衔接等。其中一部分重排序与流水线机制紧密结合,另一部分则聚焦于调整 LLVM IR 的指令顺序,以更好地服务于 AMDGCN 汇编的生成规则。
除了指令重排序与调度提示外,我们还引入了另一项调度优化策略——乒乓调度。通过循环调度机制,让两个线程束在同一个 SIMD 单元上交替执行,避免空闲与等待,从而提高计算资源的利用率。
此外,AMD 还进行了指针规范化与缓冲区操作转换方面的优化。该优化的主要目标是将指令有效映射到具体业务应用中,实现更高效的原子指令执行。
这些优化流程首先将 Triton-IR 转换为 Triton-GPU IR。在此过程中,布局信息被嵌入到 IR 中。以下图为例,张量以 #blocked 布局形式表示。

流程示例图
如果尝试另一个 Triton 矩阵乘法示例,通过上述优化流程引入共享内存访问以提高性能,这是矩阵乘法的常见优化解决方案,同时使用了设计用于 AMD MFMA 加速器的 amd_mfma 布局。
最后,在实验验证中,我以一个复杂度更高的 Matrix Multiplication 矩阵层为例。在确认 GPR(General Purpose Register)映射的过程中,插入了大量硬件相关指令,如 MFMA、转置(Transposed)、共享内存调用等。通过减少 bank 冲突、应用 swizzled 操作等方式,结合指令重排序与流水线化处理策略,所有这些优化都会在 Triton IR 转换过程中自动加入,实现更强的硬件适配能力与性能提升。

流程示例图
* LLVM-IR 优化
在 AMD 平台上,优化流程通过 make_llir 函数定义。此函数包括 2 个部分:IR 级别优化和 AMD GPU LLVM 编译器配置。对于IR级别优化,AMD GPU 特定的优化流程包括 LDS/共享内存相关优化和 LLVM-IR 级别的通用优化,如下图所示:
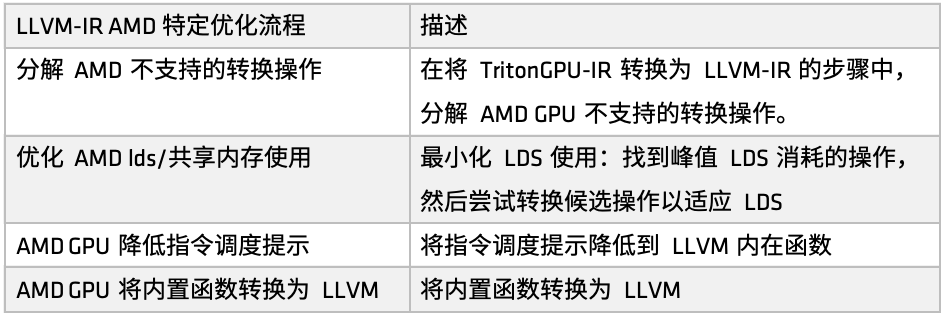
LLVM-IR特定优化流程
首先,对部分 AMD 不支持的转换操作进行分解处理。例如,在 Triton GPU IR 向 LLVM-IR 的转换过程中,如果遇到当前尚不支持的转换路径,我们会将这些操作拆解为更基础的子操作,从而确保整个转换流程能够顺利完成。
在配置 AMD GPU LLVM 编译器时,首先初始化 LLVM 目标库和上下文,设置 LLVM 模块上的编译参数,然后为 AMD GPU HIP 内核设定调用约定,并配置一些 LLVM-IR 属性,如 amdgpu-flat-work-group-size、amdgpu-waves-per-eu 和 denormal-fp-math-f32,最后运行 LLVM 优化,并将优化级别设为 OPTIMIZE_O3。
属性配置参考文档:
https://llvm.org/docs/AMDGPUUsage.html
后端机器代码生成模块
后端机器代码生成模块主要负责将中间代码转化为可在硬件上运行的二进制文件。该阶段主要分为 2 个步骤:生成 AMDGCN 汇编代码和构建最终的 AMD hsaco ELF 文件。
首先调用 translateLLVMIRToASM 函数,在 make_amdgcn 阶段生成 AMD 汇编代码。这一过程完成了从中间代码到目标架构指令集的映射,为后续的二进制生成奠定了基础。随后,编译器通过 assemble_amdgcn 函数,配合 ROCm 的链接模块,在 make_hsaco 阶段生成 AMD hsaco ELF(Executable and Linkable Format)二进制文件,该文件即为可在 AMD GPU 上直接运行的最终二进制,包含了完整的设备端指令与元信息。
通过这两个步骤,编译器将高级中间表示高效转换为底层 GPU 可执行代码,确保了程序能够在 AMD Instinct 系列等 GPU 上顺利运行,并充分发挥底层硬件性能。
AMD GPU 开发者云
AMD 正式面向全球开发者和开源社区开放其高性能 GPU 云平台 —— AMD Developer Cloud,旨在让每一位开发者都能无障碍接入世界级计算资源,便捷地访问 AMD Instinct MI 系列 GPU 资源,快速上手 AI 和高性能计算任务。
在 AMD Developer Cloud 中,开发者可以根据需求灵活选择计算资源:
* 小型:1 个 MI 系列 GPU(192 GB 显存)
* 大型:8 个 MI 系列 GPU(1536 GB 显存)
平台最大程度降低了配置门槛,用户无需繁琐安装,可即时启动基于云的 Jupyter Notebook。只需一个 GitHub 账户或邮箱,即可轻松完成配置。此外,AMD Developer Cloud 提供了预配置的 Docker 容器,内置主流 AI 软件框架,最大限度减少了环境搭建时间,同时也保留了高度灵活性,允许开发者根据具体项目需求自定义代码。
欢迎各位开发者来亲自体验 AMD Developer Cloud,在这里运行你的代码、验证你的想法,平台将为你提供稳定、强大、灵活的算力支持,加速创新与落地。
AMD Developer Cloud 链接:
https://www.amd.com/en/developer/resources/cloud-access/amd-developer-cloud.html
获取 PPT:关注微信公众号「HyperAI超神经」,后台回复关键字「0705 AI 编译器」,即可获取确认授权的讲师演讲 PPT。
扫码备注「AI 编译器」加入活动群



戳“阅读原文”,免费获取海量数据集资源!
(文:HyperAI超神经)