
作者:王焱(已授权)
原文:https://zhuanlan.zhihu.com/p/3116018350

1 前言
Attention的计算过程中,需要之前的k和v。
但每次计算的时候,把之前的k,v重新计算一次成本太高昂,需要找个地方临时存起来,这就是KV Cache。
llama1的代码就非常简单
self.cache_k = self.cache_k.to(xq)
self.cache_v = self.cache_v.to(xq)
self.cache_k[:bsz, start_pos : start_pos + seqlen] = xk
self.cache_v[:bsz, start_pos : start_pos + seqlen] = xv
keys = self.cache_k[:bsz, : start_pos + seqlen]
values = self.cache_v[:bsz, : start_pos + seqlen]把kv的值更新到cache里,然后再从缓存中读取需要的cache。
真实业务场景中,用户对于context的需求是一直变长,但耗时太久,导致用户体验上不去,真实需求变成了不存在的需求。
举例子,当年我们做智能音箱,到后面发现用户都是听首歌,看电影之类的需求。但用户只有这样的需求么?答案是否定的,是因为之前用户的复杂需求,都是智障回答。
用户试了几次,被“教育”后,就不愿意做进阶尝试了。
用户不请求的需求,不代表真的不存在,可能是你做的太垃圾了。
随着大模型在下游的落地不断深入,未来某些特定domain,大概率会有每天,32k往上,百亿-万亿的请求。
我们搞了半年(预计要持续两年)的冯诺依曼大模型,就是要优化这块。(近期一些小分支预计也会开源出来。
KV Cache就是其中核心模块,很多地方要从零改。
我们跟SGLang的朋友,一起从头梳理了一下SGLang的kv cache部分。他们英文版本的code walk through已经开放出来。
https://github.com/zhaochenyang20/Awesome-ML-SYS-Tutorial/tree/main/sglang/kvcache-code-walk-through这篇文章会从设计思路的角度去探讨,为什么这样设计KV Cache,给我们后面的优化提供一定的借鉴和参考。
这篇文章要重点感谢,bruce,zenan,zhongtao,qwang。其中有些代码理解的现场源码battle还是让我觉得非常爽的。
2 cache管理
关于kv cache,直观上来看,有这么两个需求
-
• a) kv cache是高频读写,量级不小,如何高效的管理 -
• b) kv cache的实际业务有多种, MHA,GQA, MLA,DoubleSparse,如何做业务的隔离?
2.1 cache池
内存池的定义,如果每次都是要使用内存的时候,才去申请,效率会很低。容易导致碎片化,带来管理的困难。
但我们可以提前申请一大块内存,需要的时候从这个内存池去拿就好了,SGLang这里也一样。
2.2 二级cache池
kv cache有这些自定义类型,还在不断增长,MHA,MLA,DoubleSpars cache,管理起来比较麻烦。
使用二级内存池,一级记录high level信息,跟具体业务隔离,二级各种类继承,根据需要来调用。
2.3 一级内存池:req_to_token_pool
跟踪每个请求使用的token位置,具体的kv cache在二级内存池。
key:第i个req对应req_to_token第i行,第i个req的第j个token对应req_to_token第i行第j列
value:从二级缓存池的allocater获取的token_to_kv的内存块id(定位)
2.3.1 代码
初始化代码
sglang/srt/model_executor/model_runner.py核心函数,init_memory_pool
初始化内存池
self.req_to_token_pool = ReqToTokenPool(
size=max_num_reqs + 1,
max_context_len=self.model_config.context_len + 4,
device=self.device,
use_records=False,
)输入的最大的req请求量和max content len
实现代码
sglang\srt\mem_cache\memory_pool.py2.3.2 提供的功能
分配内存块
self.req_to_token = torch.zeros(
(size, max_context_len), dtype=torch.int32, device=device
)最大的req量级,content len
内存块的write,alloc,free,内存池的常见操作,这里不做赘述,大家自行看代码就好
2.3.3 实际操作代码
prepare_for_extend()函数非常合适来看一级内存是如何操作。
此函数为extend的执行做准备,分配一二级内存,更新一级内存池。 二级内存池,因为此时kv cache的值还没有计算好,只是分配,要在forward的过程中才会写入。
代码路径
python\sglang\srt\managers\schedule_batch.py2.4 二级内存池:token_to_kv_pool
SGLang两级内存池系统中的第二级,定义多种二级内存池类,MHA,MLA,DoubleSparse等。
key:lay_id+token_cache_loc(不同层
value:真实的kv cache值
2.4.1 代码
因为有多个实现,类继承
初始化代码
sglang/srt/model_executor/model_runner.py实现代码
sglang\srt\mem_cache\memory_pool.py2.4.2 提供的功能
写入,分配,清理等核心功能。
值得注意的点,读内存,传入layer id,直接返回某一层的内存。但写内存,传入layer id loc,这个loc的k v tensor。因为推理的时候,不会有需求说读取某个指定位置的kv。
2.4.3 实际操作代码
二级内存池的set(写入)只有各个backend的forward函数才会set。保证了二级内存池set的规范化,极大降低了内存泄漏的风险。
通过类似多态来实现,这块的代码比较绕,从注册到使用。但整体写的挺干净,给SGLang点个赞。
一级内存就满世界set了,但本身小,内存泄漏问题不大。
具体python\sglang\srt\layers\attention\下面的backend结尾的py文件都可以参考。
3 cache复用
通过一二级cache池,解决了cache的管理问题。
但此时观察数据,会发现大部分请求都有大量重复的开头,如sys prompt。那我们想办法复用这些kv cache就好了。
有两种复用方式,radix和chunk。
3.1 Radix cache
3.1.1 是什么?
Radix tree可以理解为前缀树的高自定义版本
https://zhuanlan.zhihu.com/p/693556044我们大致梳理下这个内存复用的需求:
计算好的kv cache存入radix cache,新的请求匹配radix cache,如果算过了,直接就拿过来用。
理想情况下,肯定是radix cache存的越多越好。但机器是有限的,所以需要对kv cache做清理。
但清理就会碰到这么一个问题,我们如何判断一块radix cache是可以清理的。跟java的引用计数是类似的,引用归零就可以做清理。
加一,减一的时机,当req执行完毕,就可以减一。req还在forward,就要加一,代表还在用,你不能清理。
以及是按step执行,req有的执行完,有的才刚开始,会导致不同req的前缀会有重复执行,要及时做内存优化。
基于上面的需求,核心为下面三个函数。
-
• match_prefix:匹配命中了哪些cache。 -
• cache_finished_req:req执行完了,把引用-1。告诉大家,这个前缀我不用了。 -
• cache_unfinished_req:req没执行完,这个前缀我要用,引用+1。同时自己的kv cache也更新到radix tree(以及一些特殊逻辑的处理
3.1.2 代码
sglang/srt/mem_cache/radix_cache.py3.1.3 cache_unfinished_req
把未完成的req的存入radix cache。
引用计数加一,self.inc_lock_ref(new_last_node)
有一行代码非常有意思,cursor也回答不好,我们当时讨论了半小时。
self.token_to_kv_pool.free(kv_indices[len(req.prefix_indices) : new_prefix_len])
req没有执行完毕,为什么要free?cache_finished_req也有这行代码,为什么?
大家也可以自行思考为什么。(给一点提示,如果不加,会导致跟page attention类似的内存浪费问题。
3.2 Chunked cache
简单点,可以理解为把输入分成块来cache
但核心函数跟radix一致,并且更简单,不展开。
3.3 token粒度的内存池的好处
开放问题,对比vllm的page attention,SGLang做到了token粒度。
个人不靠谱看法,SGLang这种做法更好一些。
page attention只负责管理连续token的kvcache尽可能在内存连续。
radix attention也做到了管理连续token的kvcache内存连续,但是在此基础上强化前缀缓存的复用。
4 推理过程中和kv cache的交互
我们已经设计好了二级内存池,如何复用也想好了,那么在req传入到结束的生命周期,也就是推理的过程中,是如何跟二级内存池和radix(chunk)做交互的?
会从三部分来展开,整体框架,举个例子,细化版本
4.1 整体框架
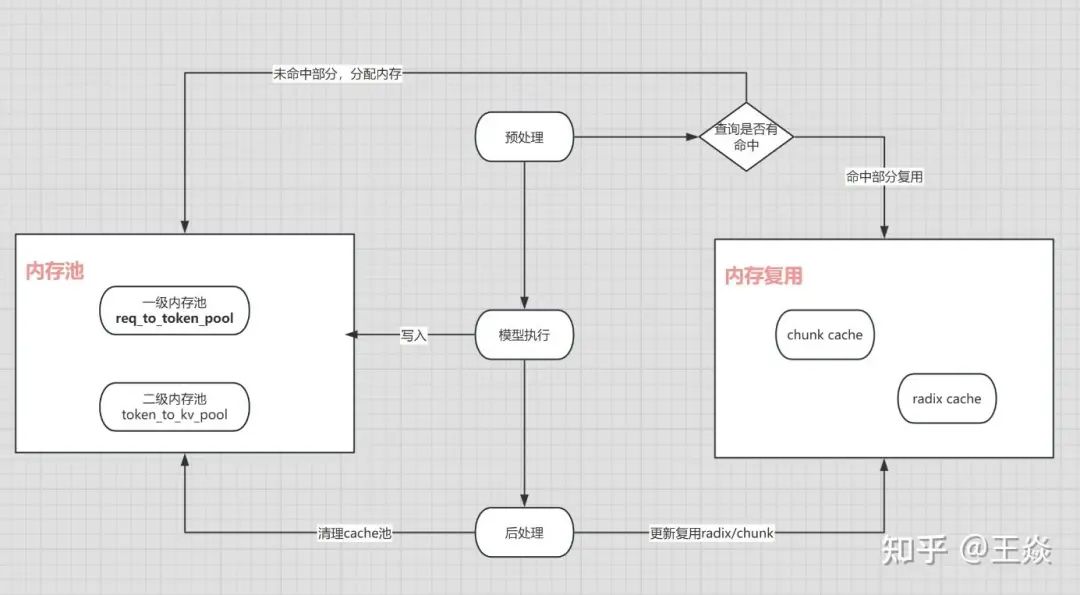
三步走
-
• a)预处理
新的req,查询是否命中,命中复用即可。没有命中,去二级缓存池申请槽位。
-
• b)模型执行
算好batch,模型执行,算出kv cache。主要跟二层kv cache池交互,把申请的槽位写入算好的kv cache。
-
• c)后处理
如果req执行完毕,radix tree 引用减一,一二级内存池做对应清理。
4.2 举例子
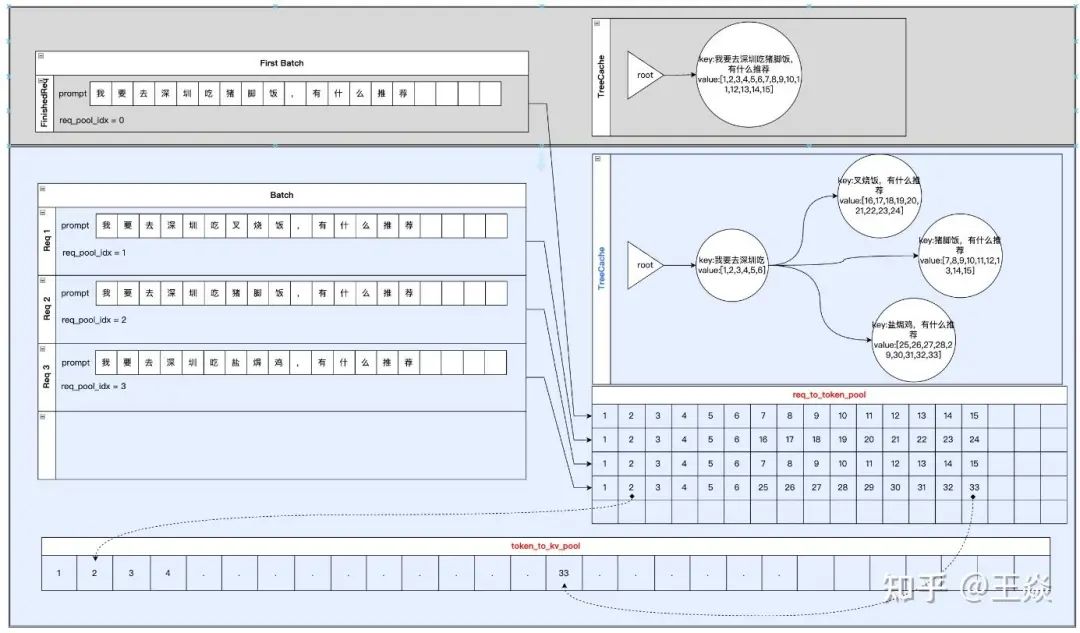
这个图举了几个实际的req来讲清楚,整体流程是怎么走的。
感谢zenan和zhongtao
4.3 细化版本
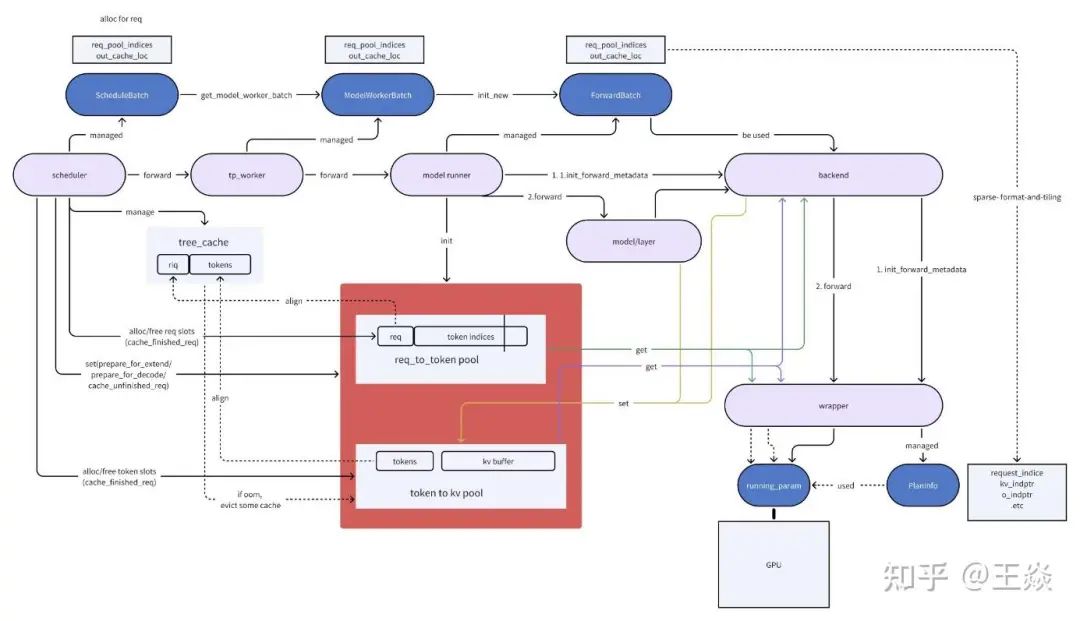
这个图要感谢bruce,非常详细
往期推荐

美团基于SGLang的INT8无损满血版DeepSeek R1部署方案解析
DP MLA For DeepSeek In Sglang
DeepSeek MLA在SGLang中的推理过程及代码实现
SGLang 源码学习笔记:Cache、Req与Scheduler
(文:GiantPandaCV)