

-
关键信息可能分散在多个文本块中,难以获取完整的要点。 -
一个文本块可能同时包含相关和无关的信息。 -
很难准确定位用于回答特定问题的信息。
命题切分(Proposition Chunking)方法旨在通过将信息拆解为最小的有意义单元来解决这些问题。
命题是小型的、自包含的信息单元,可以将其视为独立的事实或主张。命题具有以下关键特征:
-
包含单一信息点。 -
可以在没有额外上下文的情况下被理解。 -
陈述一个清晰的事实或主张。 -
简洁明了。 -
其自身包含所有必要的上下文信息。
例如,相比于一整段关于第一次世界大战的文字,命题可以拆解为:
-
“第一次世界大战始于1914年。” -
“奥匈帝国的弗朗茨·斐迪南大公遇刺是第一次世界大战的导火索。” -
“第一次世界大战涉及多个欧洲国家。”
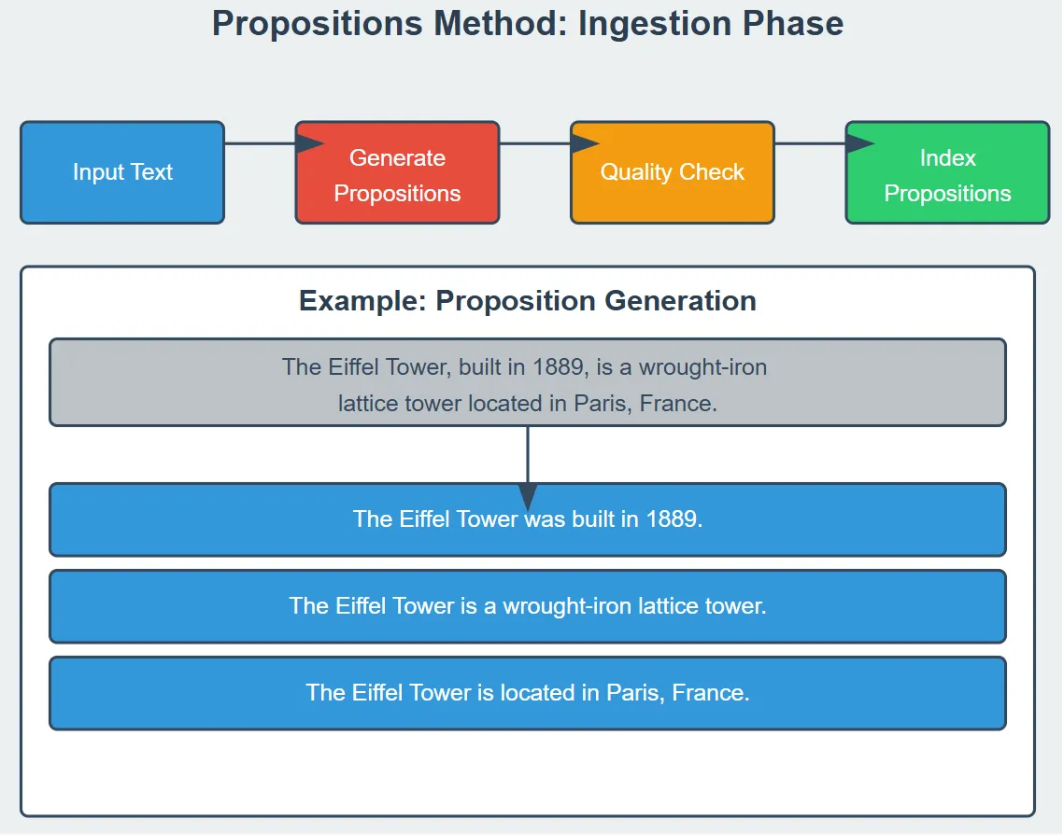
加载文档
这里我们加载一段样例文档
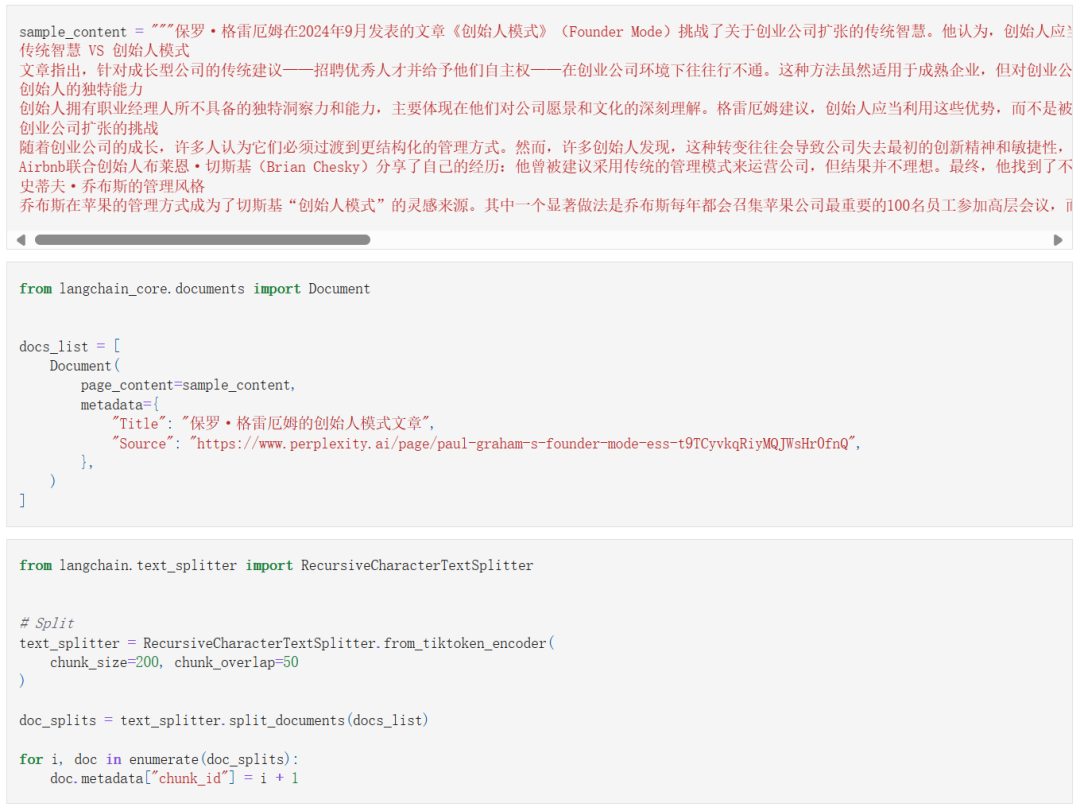
生成命题
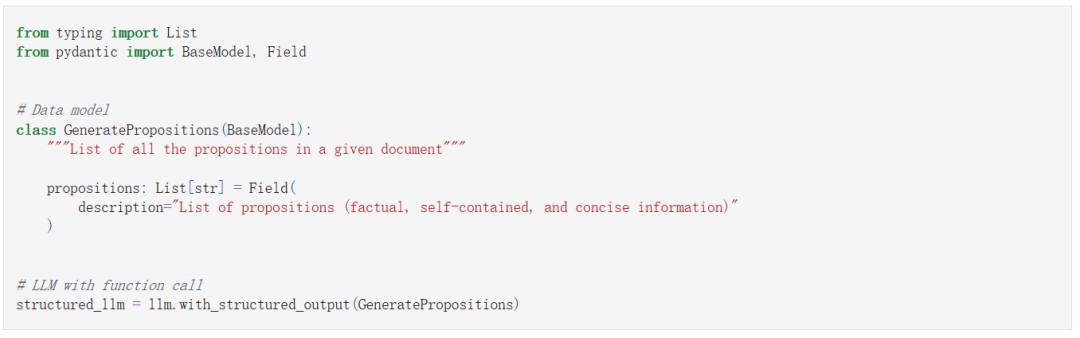
让 LLM 以结构化的形式生成命题,先定义好结构和 LLM:
接下来设定一个少样本提示和系统提示,指导 LLM 如何从给定的文本中生成命题:
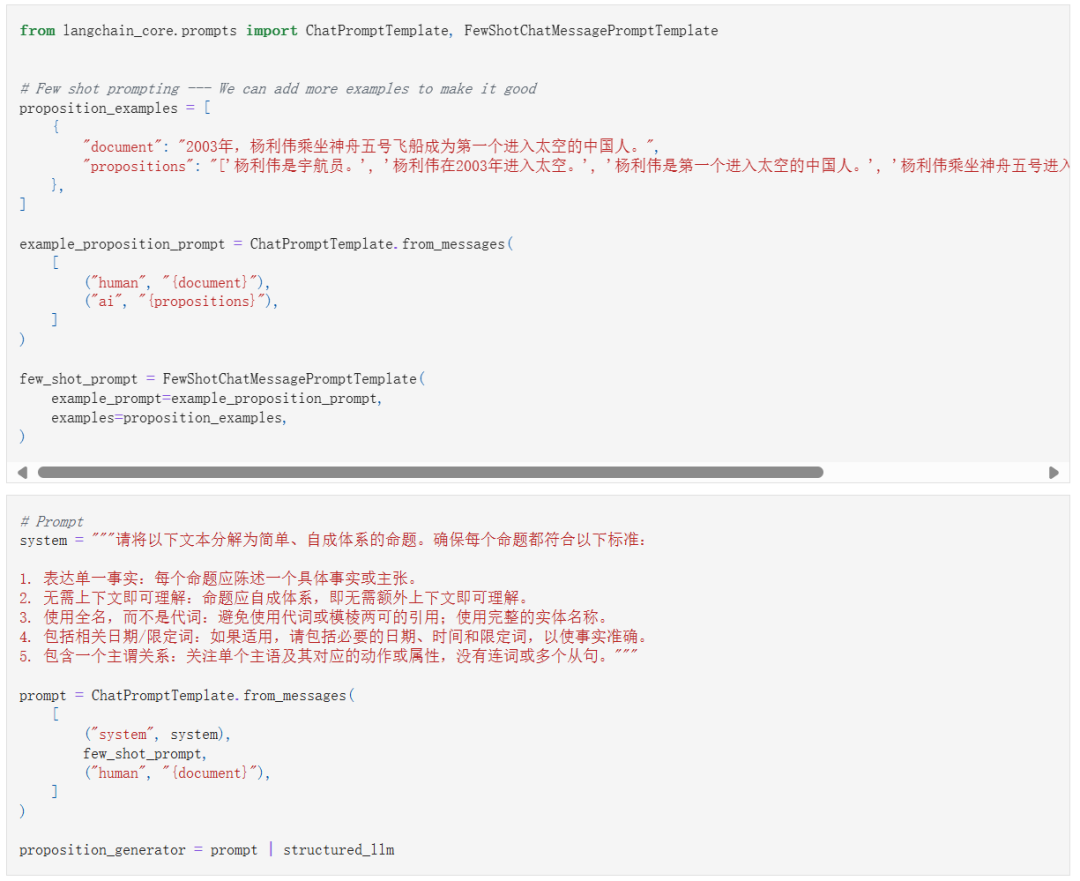
生成命题:
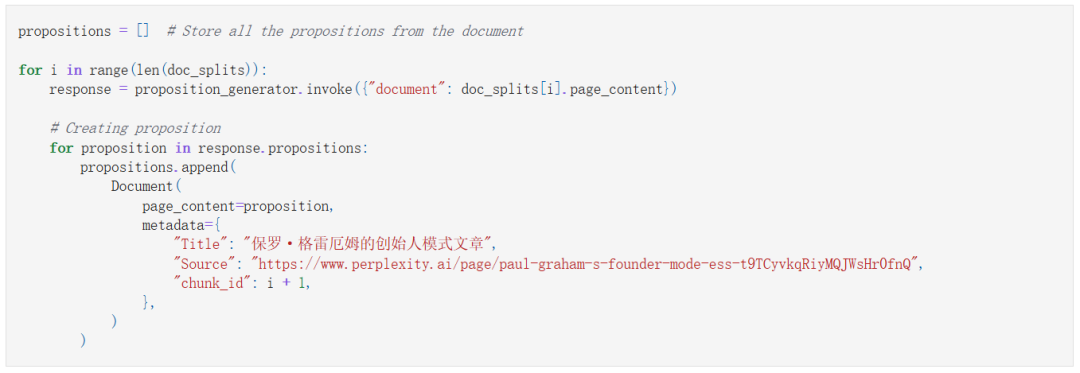
评估命题
-
准确性(Accuracy) -
清晰度(Clarity) -
完整性(Completeness) -
简洁性(Conciseness)


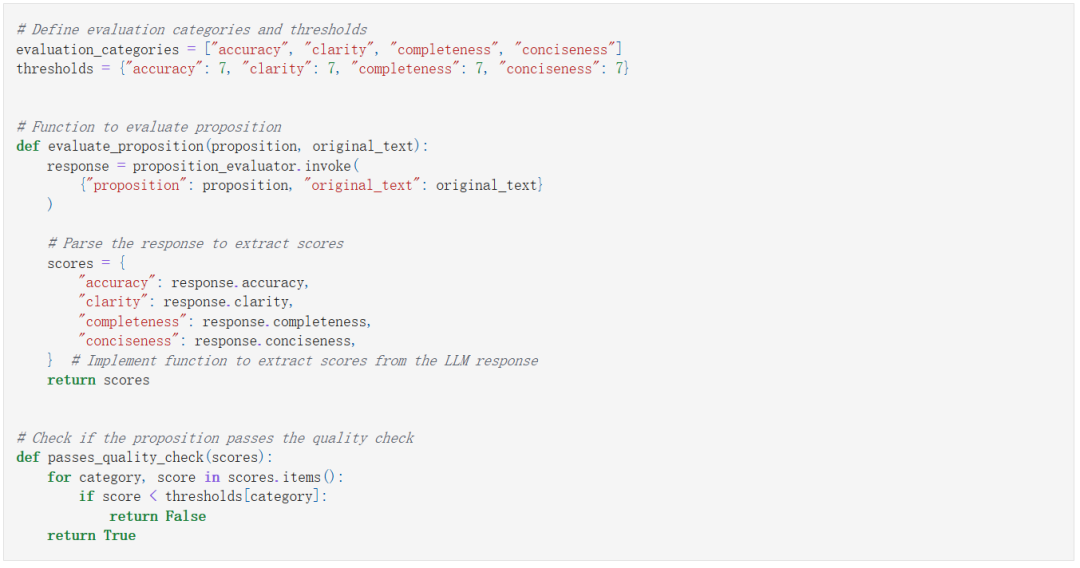
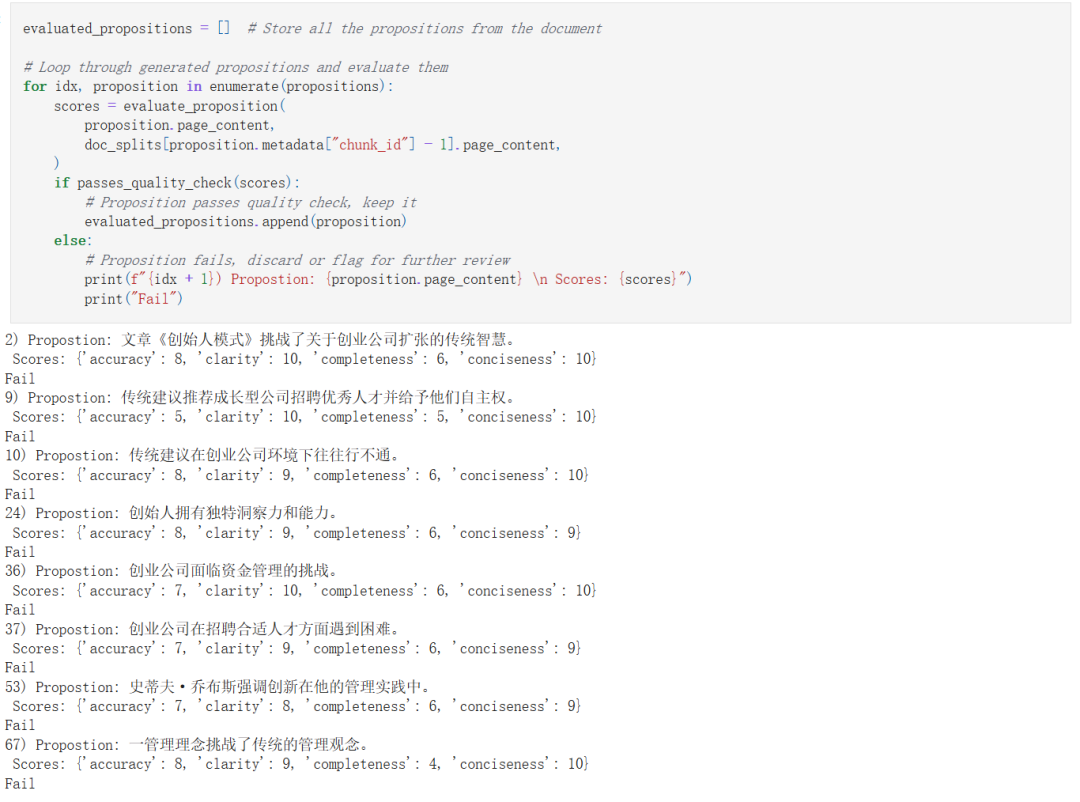
生成命题嵌入并进行测试
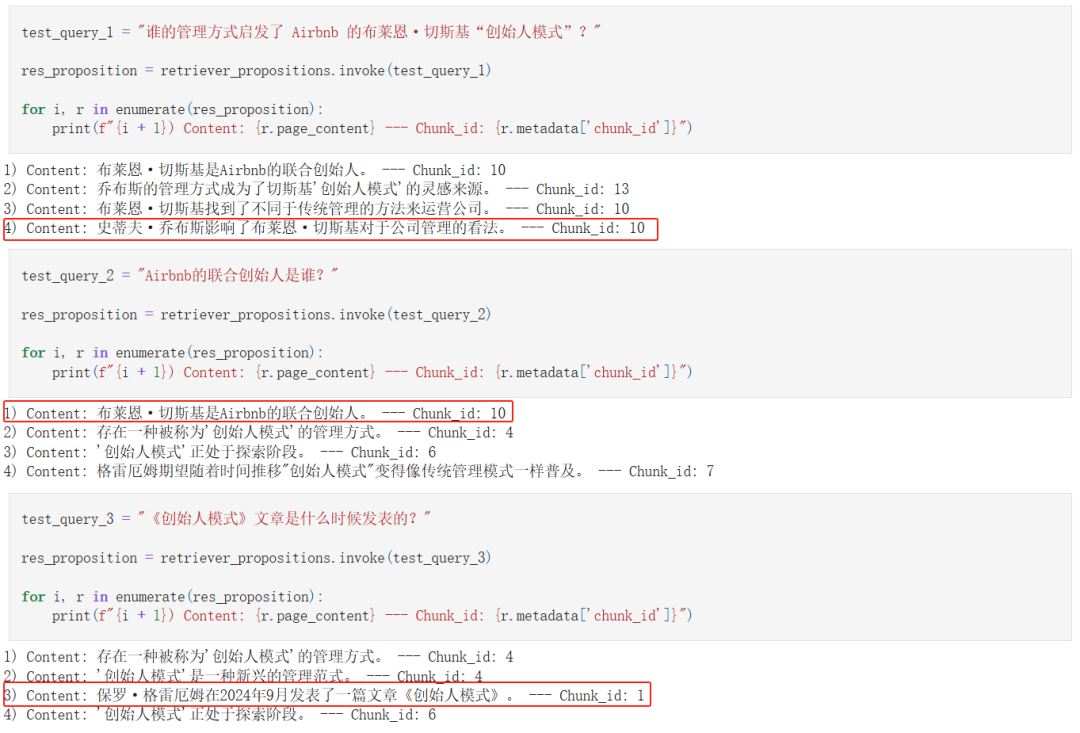
为了简单起见,我就直接使用了内存向量数据库 FAISS。

然后选择了三个查询测试一下,效果还行。
命题方法提供了一种新的思维方式,帮助我们更高效地表示和检索信息。虽然它并非万能解决方案,但在提高信息检索的精度和有效性方面具有很大潜力。
如果你正在构建需要检索和使用信息的 AI 系统,命题方法或许可以考虑作为提升系统性能的一种策略。
本文源代码:
https://github.com/realyinchen/RAG/blob/main/RAG101/004-Proposition_Chunking.ipynb
查阅此前文章:
《RAG101第三课:通过添加验证和优化构建可靠的RAG》
《RAG101第二课:一个简单的CSV文件RAG工作流》
《RAG101第一课:一个简单的RAG工作流》
文章来源:PyTorch研习社
(文:PyTorch研习社)