

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
昨晚,国内著名大模型平台DeepSeek开源了V3模型的最新版本0324。
不过DeepSeek相当低调,国内的公众号、国外的社交平台没有做任何宣传,就是“悄悄”地把模型上传到huggingface。
根据国外网友测试显示,V3-0324最大亮点之一就是代码能力,只需要简单的文本提示就能快速开发各种网站、App,可以比肩目前全球最强的闭源代码模型Claude 3.7 Sonnet思维链版本。
但V3-0324是开源且免费的,推理效率更快。
开源地址:https://huggingface.co/deepseek-ai/DeepSeek-V3-0324/tree/main
有网友表示,新版V3 在不到 60 秒的时间内解开了一道密码谜题。Sonnet 3.7 花了大约 5 分钟却未能解开。
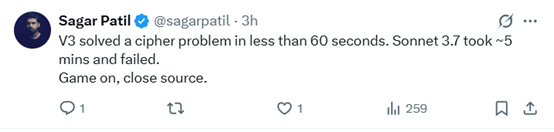
这就是为什么我不介意中国领先。他们有人力资源,这个巨人已经觉醒,我们将从中获得更好的科技成果。
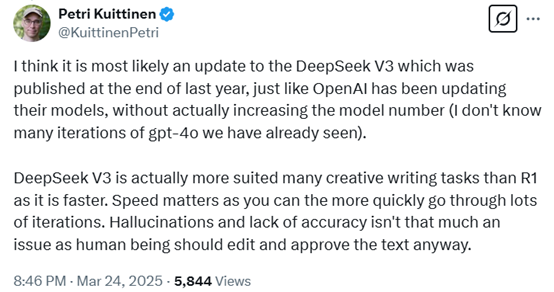
有网友分析,认为这很可能是去年年底发布的 DeepSeek V3 的一次迭代更新,就像 OpenAI 一直在更新他们的模型一样,而没有真正增加模型的编号(我不知道我们已经见过多少个 gpt-4 的迭代版本)。
DeepSeek
V3 实际上比 R1 更适合许多创意写作任务,因为它更快。速度很重要,因为你可以更快速地进行多次迭代。幻觉和准确性不足并不是大问题,因为人类应该编辑和批准文本。
DeepSeek的影响凸显了一个重要的技术转变。

还有人立刻对V3-0324进行了评测,一次性开发了一个网站写了800多行代码且没有出现任何错误。这是免费的、开源的、超级快的。很高兴看到这些开源模型如何给大公司施加压力,促使它们以更低的成本构建更好的模型。
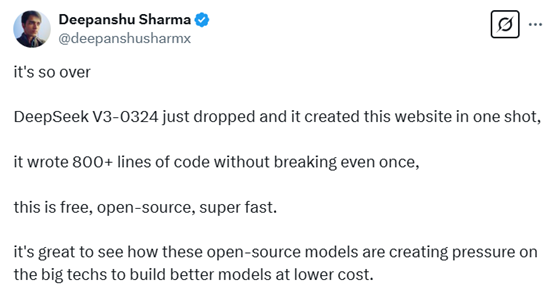
新版V3 模型仅用一个提示就完成了这个登陆页面的编码。这个新的 DeepSeek-V3 模型在编程能力上已经达到了和 Claude 3.7 Sonnet 相同的水平,同时还是无限制且免费的。
提示词:用 HTML/CSS/JS 编写一个现代化的登陆页面,并将所有内容放到一个文件中!
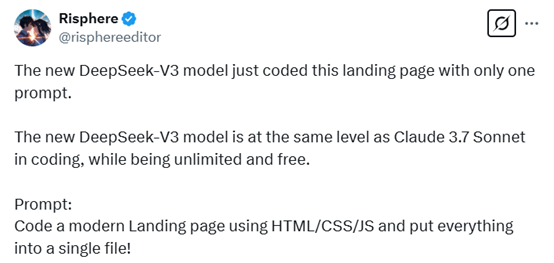
我让新的 DeepSeek V3 模型构建最美丽且复杂的动画脚本。只用一个 HTML/JS 脚本!

该网友还补充道“我们正在与未来对话”,相当满意V3的代码能力。

V3简单介绍
V3是一个拥有 6710 亿参数的专家混合模型(Moe),其中370 亿参数处于激活状态。
在传统的大模型中,通常会采用密集的神经网络结构,模型需要对每一个输入token都会被激活并参与计算,会耗费大量算力。
此外,传统的混合专家模型中,不平衡的专家负载是一个很大难题。当负载不均衡时,会引发路由崩溃现象,这就好比交通拥堵时道路瘫痪一样,数据在模型中的传递受到阻碍,导致计算效率大幅下降。
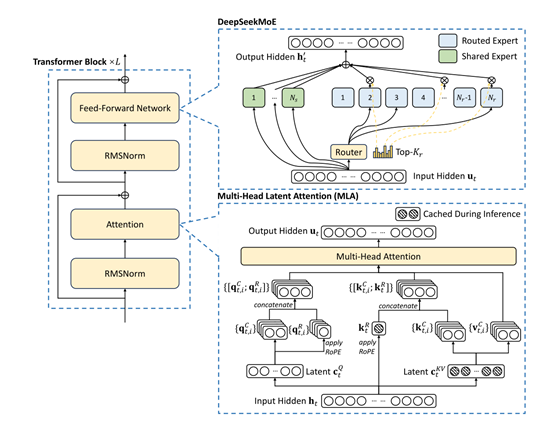
为了解决这个问题,常规的做法是依赖辅助损失来平衡负载。然而,这种方法存在一个弊端,那就是辅助损失一旦设置过大,就会对模型性能产生负面影响,就像为了疏通交通而设置过多限制,却影响了整体的通行效率。
DeepSeek对V3进行了大胆创新,提出了辅助损失免费的负载均衡策略,引入“偏差项”。在模型训练过程中,每个专家都被赋予了一个偏差项,它会被添加到相应的亲和力分数上,以此来决定top-K路由。
模型会持续监测每一批训练数据中专家的负载情况。如果某个专家负载过重,就像一座桥梁承受了过多的车辆,此时就减小其偏差项;反之,如果负载过轻,就增加偏差项。
通过这种动态调整, V3能够在训练过程中有效平衡专家负载,而且相比那些仅依靠纯辅助损失来平衡负载的模型,它的性能得到了显著提升。
此外,V3还采用了节点受限的路由机制,以限制通信成本。在大规模分布式训练中,跨节点的通信开销是一个重要的性能瓶颈。通过确保每个输入最多只能被发送到预设数量的节点上,V3 能够显著减少跨节点通信的流量,从而提高训练效率。
这种路由机制不仅减少了通信开销,还使得模型能够在保持高效的计算-通信重叠的同时,扩展到更多的节点和专家。
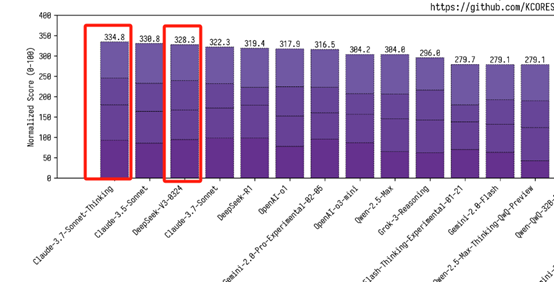
根据国外开源评测平台kcores-llm-arena对V3-0324最新测试数据显示,其代码能力达到了328.3分,超过了普通版的Claude 3.7 Sonnet(322.3),可以比肩334.8分的思维链版本。
(文:AIGC开放社区)