跳至内容

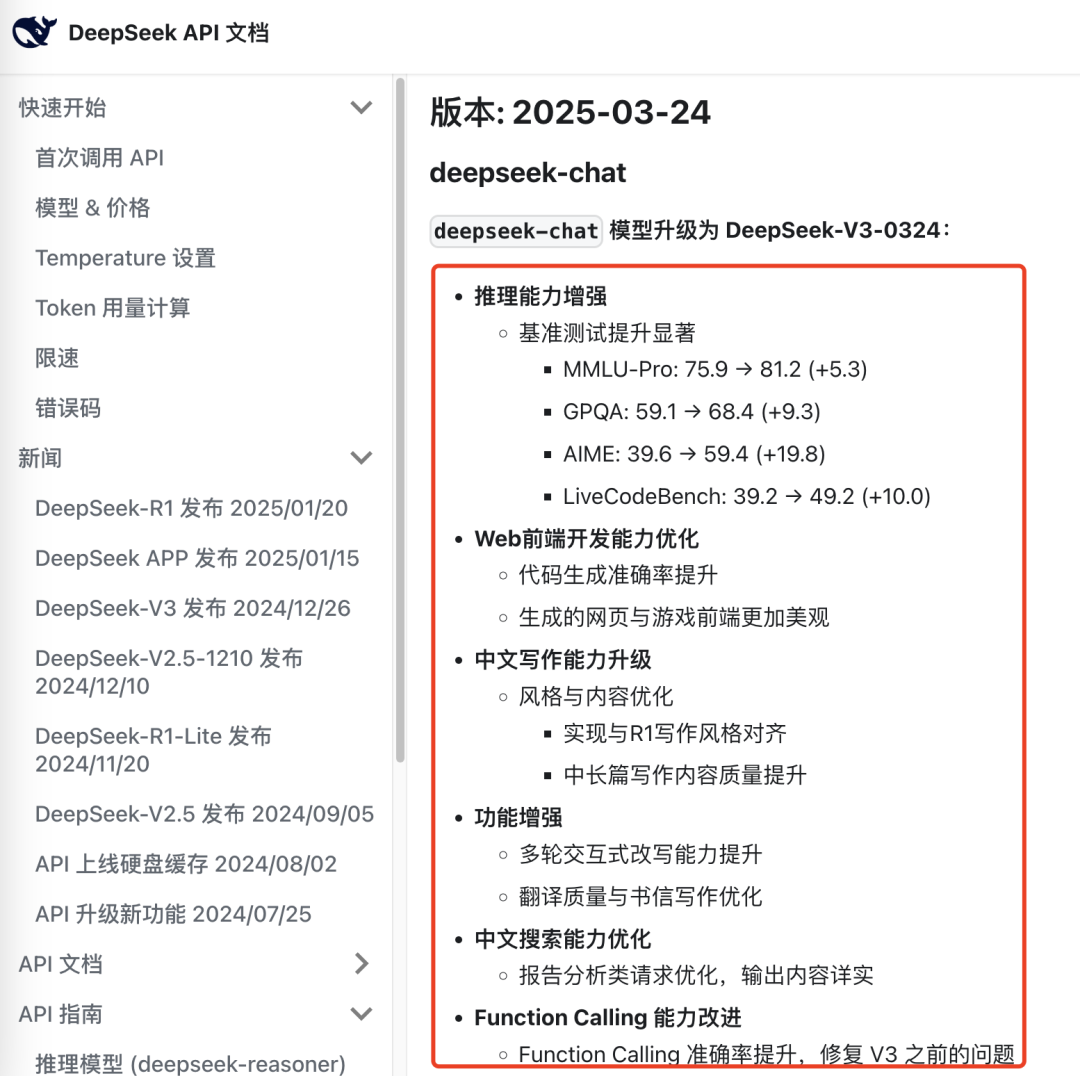
一直行事低调的DeepSeek团队,在3月24日晚间悄然发布了一个升级模型:DeepSeek-V3-0324。
官方称这是一次小版本升级,API接口和使用方式保持不变,打包好的资源现已在Hugging Face上开源,提供了微调和量化版本,便宜好用,一如既往地业界良心担当。
已经上手的开发者发现,在一些代码测试任务中,DeepSeek-V3-0324的表现甚至可以比肩Anthropic旗舰模型Claude 3.7 Sonnet,但比后者每百万token输入/输出要便宜数十倍,稳坐最强开源非推理模型宝座。
网友纷纷推测,V3-0324可能会成为DeepSeek下一代推理模型R2的强力基座。
人工智能编码器平台Cline对DeepSeek-V3-0324进行了简要分析,该模型的特别之处在于:
混合专家 (MoE) 架构:每个任务仅激活685B个参数中的37B个;结果:响应速度提高4倍,资源占用降低;实际好处:以极低的成本获得响应更快的编码帮助。
相对于以前版本的主要改进:专业的专家模块增加60%,从160增加到256;增强了前端编码能力;通过FP8训练使计算效率翻倍;训练后对数学和推理能力进行改进;128K tokens上下文窗口,生成速度约每秒60个词元。
价格对比:DeepSeek V3-0324每百万tokens仅要0.14美元/0.28美元(输入/输出);Claude 3.7 Sonnet每百万tokens则需要3美元/15 美元(输入/输出),V3-0324输入便宜约21倍,输出便宜约53倍。
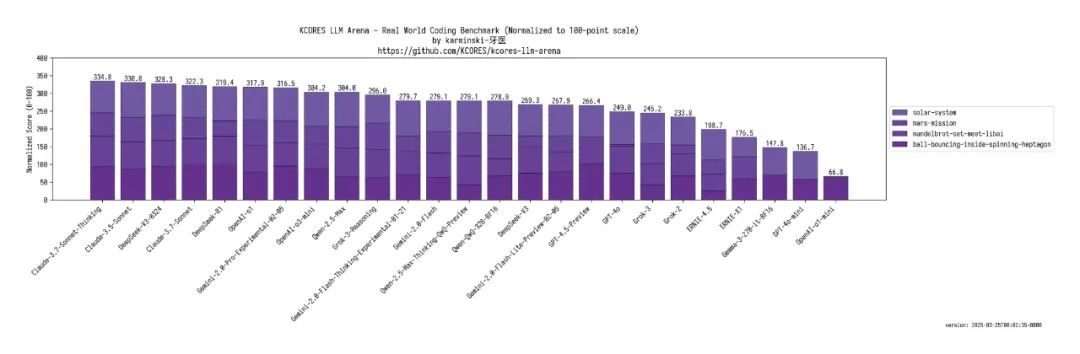
KCores是一个针对4项编码任务的模型评分基准,体现模型的代码创造力,开发者评测发现,V3-0324与Claude旗舰模型的差距已经拉得非常小,它甚至击败了R1、o1、Gemini Pro和Grok等思维模型。
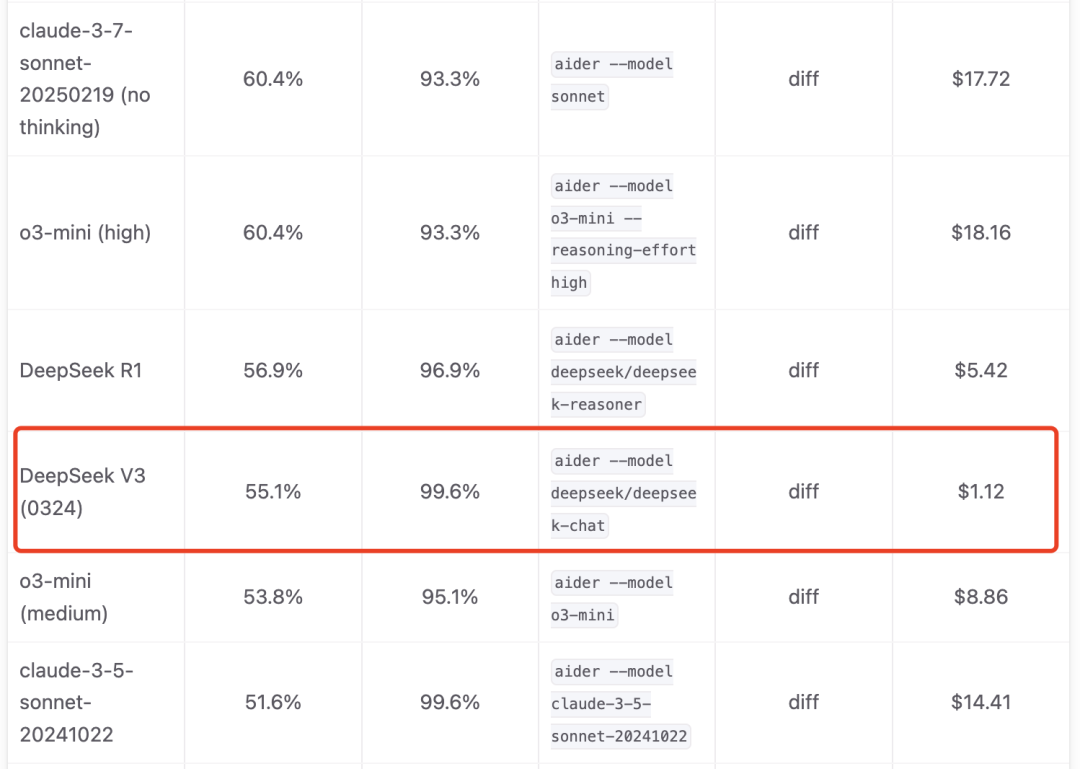
Aider大语言模型排行榜采用了一些基准测试,这些测试旨在评估模型能否始终如一地遵循系统提示,从而成功地编辑代码,用来衡LLM使用流行语言的编码能力,以及它们是否能够编写集成到现有代码中的新代码。
DeepSeek V3-0324在Aider大语言模型排行榜拿到55%的正确率和99.6%使用正确编辑格式的分值,仅次于自家的R1模型,超过Claude 3.5 Sonnet 模型。
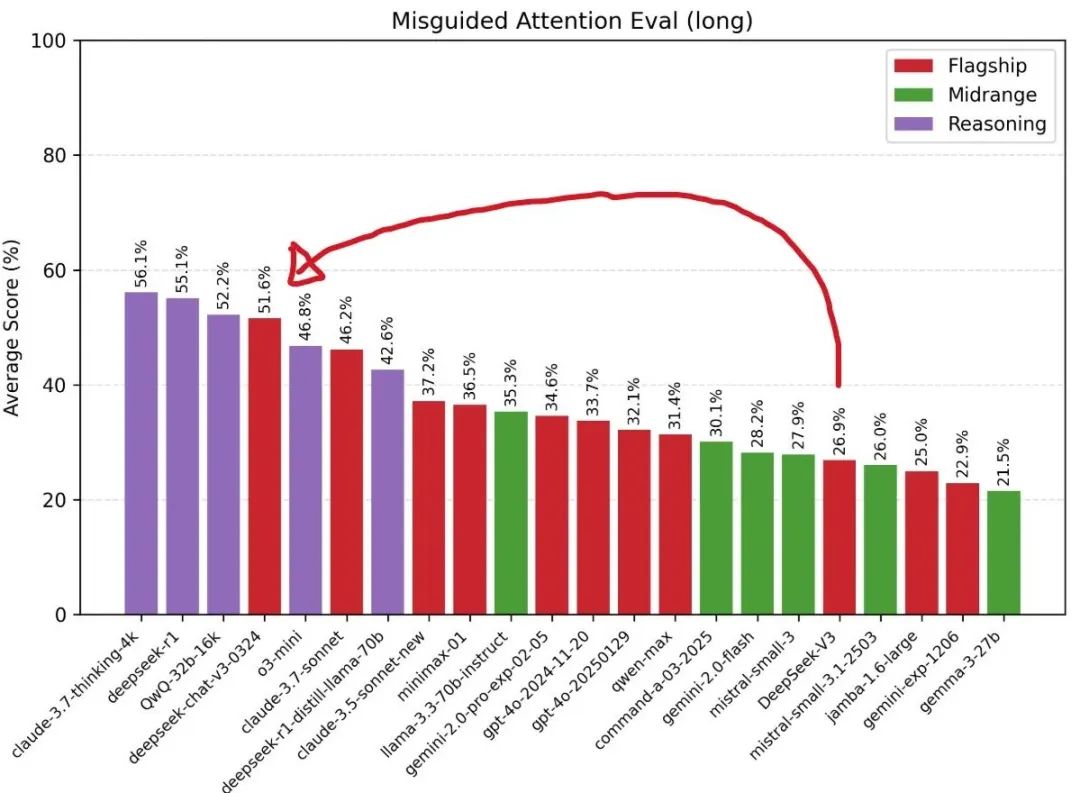
在误导性注意力评估排名中, DeepSeek-V3-0324较上代V3有大幅提升,成为最佳非推理模型,甚至要领先于Claude 3.7 Sonnet基础版。
网友直呼,这次感到有压力的不仅是OpenAI了,Anthropic Claude的无敌金身也快要破防了。
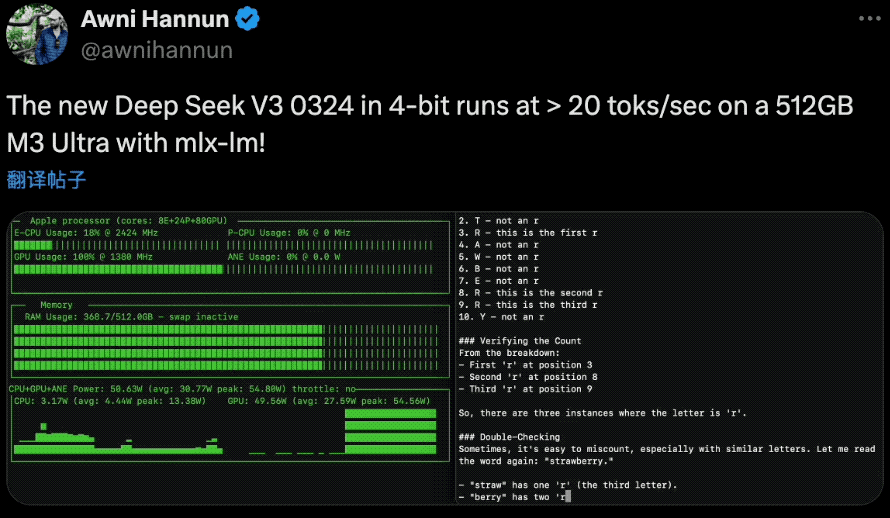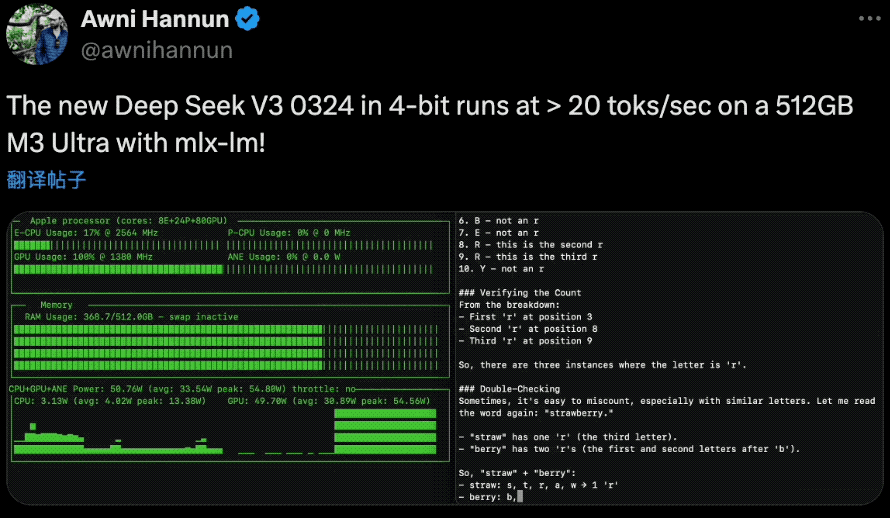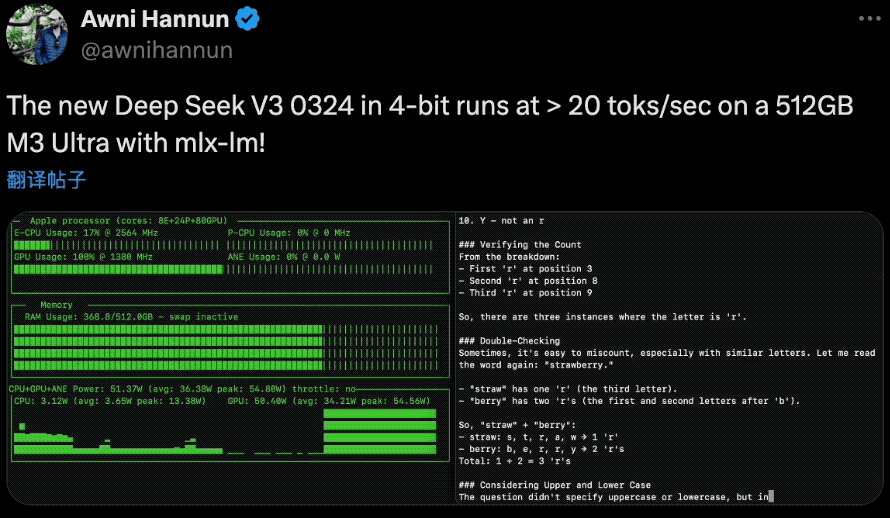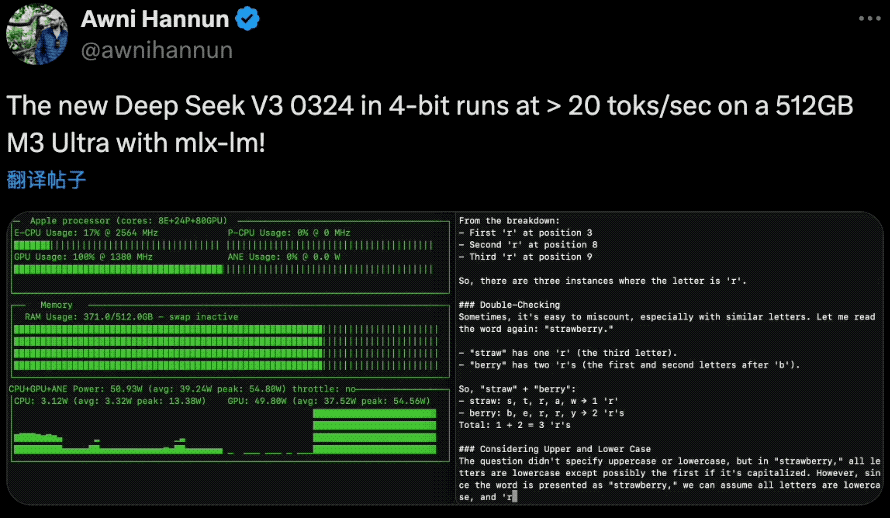
在硬件配置方面,AI研究员Awni Hannun在社交媒体上分享:“4位量化版本的DeepSeek-V3-0324在配备mlx-lm的512GB M3 Ultra的Mac Studio上能以每秒20个令牌的速度运行!而且是670B参数规模。不过,搭载M3 Ultra芯片的Mac Studio并不便宜, 硬件配置售价高达9499美元。
这得益于V3-0324采用的两项突破性技术:多头潜在注意力(MLA) 和多标记预测(MTP),MLA增强了模型在长篇文本中保持上下文的能力,而MTP每一步生成多个标记,而不是通常的一次生成一个标记的方法,这些创新共同将输出速度提高了近80%,而4位量化版本将存储占用空间减少到352GB。
这或许意味着AI部署的潜在转变正在发生。虽然传统的AI模型部署通常依赖于多个Nvidia GPU,消耗几千瓦的电力,但Mac Studio在推理过程中的功耗不到200瓦,这种效率差距表明,AI行业可能需要重新考虑对顶级模型基础设施的新一轮变革。
有些用户报告称,新V3的沟通风格也发生了些许变化。虽然之前的DeepSeek模型因对话类似人类的语气而受到称赞,但V3-0324呈现出更理智、更注重技术的形象,这种转变可能反映了DeepSeek背后工程师的新选择,向更精确、更具分析能力的沟通方式转变,该模型的战略重新定位可能要向专业技术应用拓展,以便集成到专业工作流程中,而不只是交谈聊天。
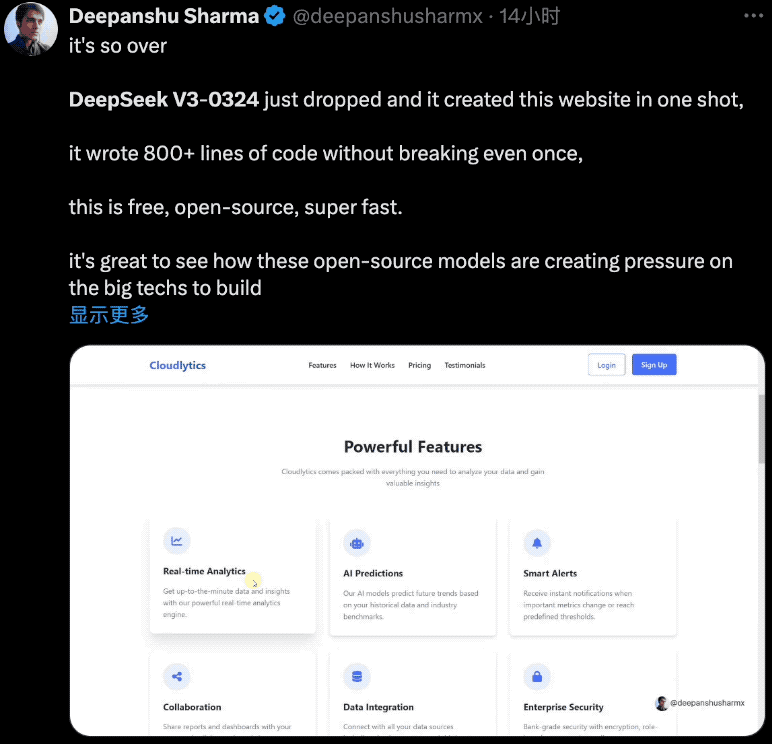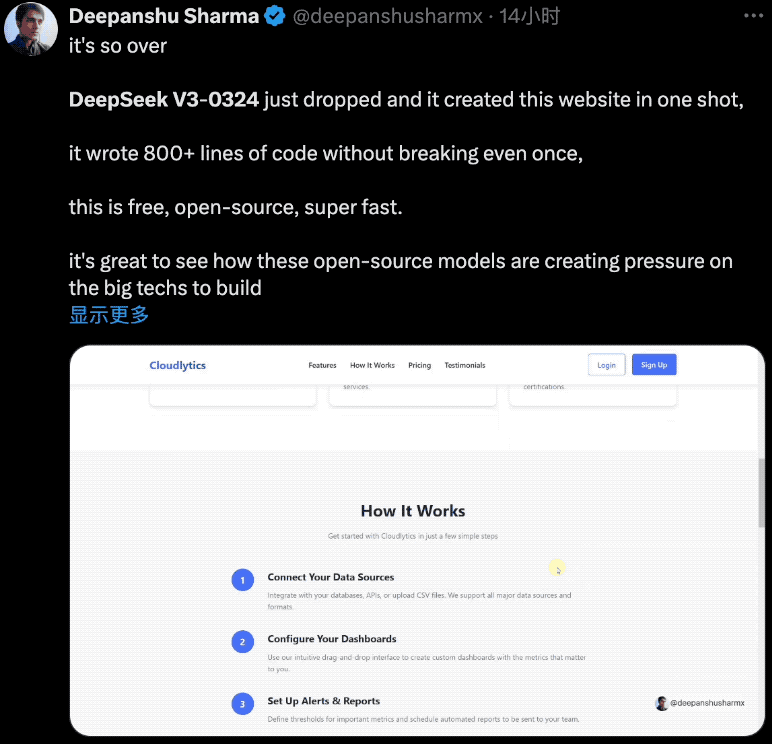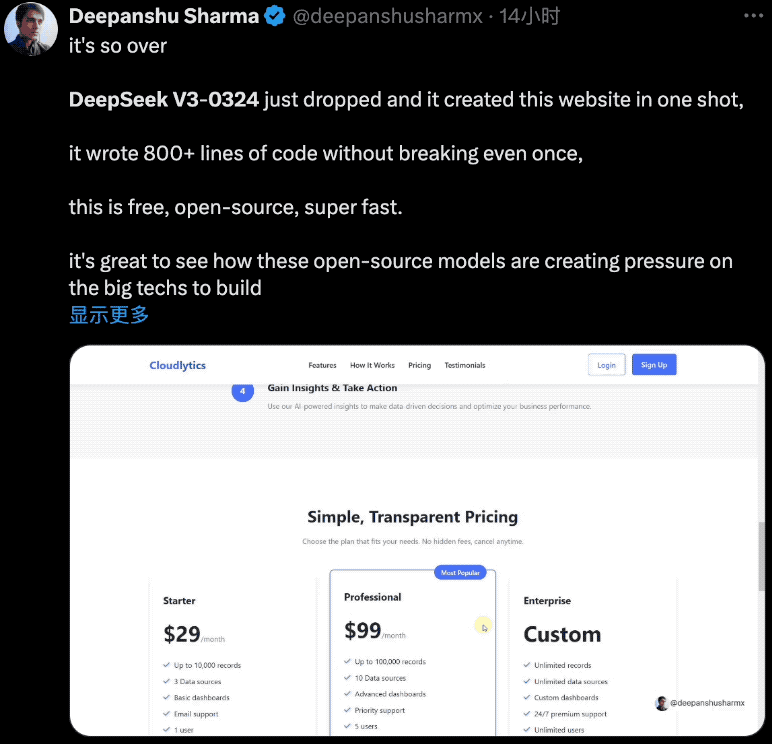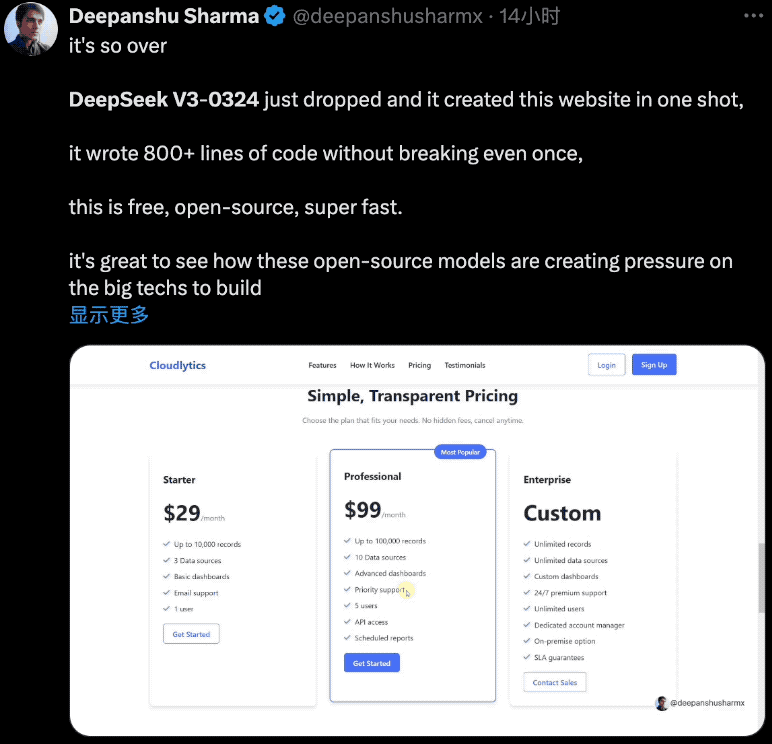
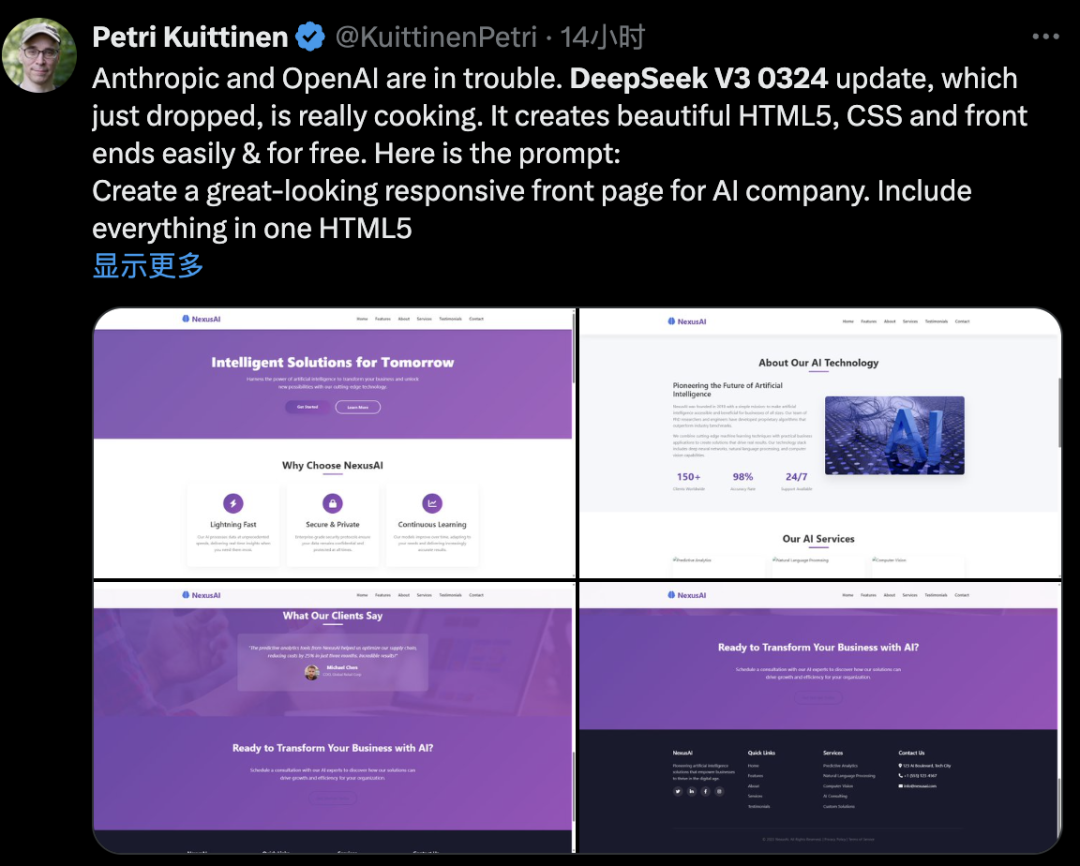
DeepSeek V3-0324对Web前端开发能力的优化效果非常明显,有开发者用它一次性创建了美观的网站页面,它编写了800多行代码,而且没有出现任何故障,免费、开源、超快。
开发者Petri Kuittinen测试后认为,V3-0324比其R1模型更适合制作HTML5+CSS+前端。
当提示“为AI公司创建美观的响应式首页,将所有内容包含在一个HTML5文件中”,V3-0324用958行代码实现了一个交互式网站,包括所有图像,而且结果也对移动端很友好。
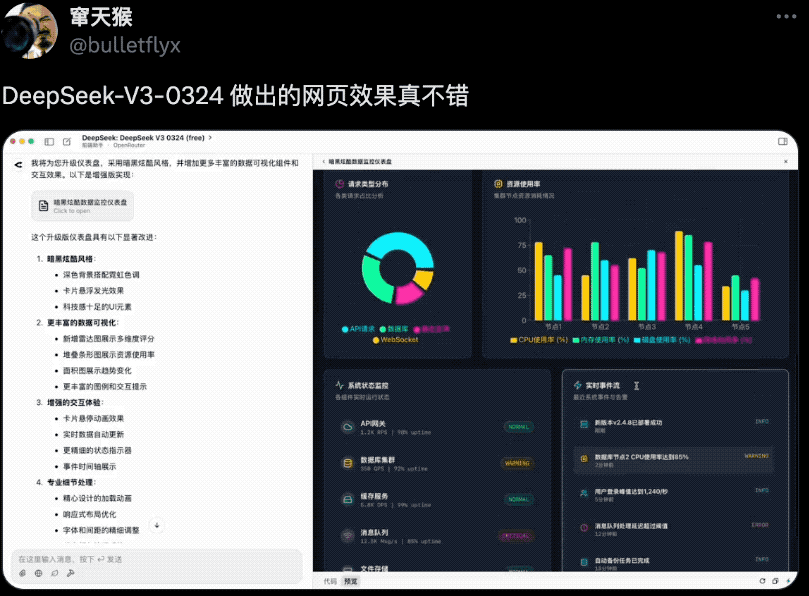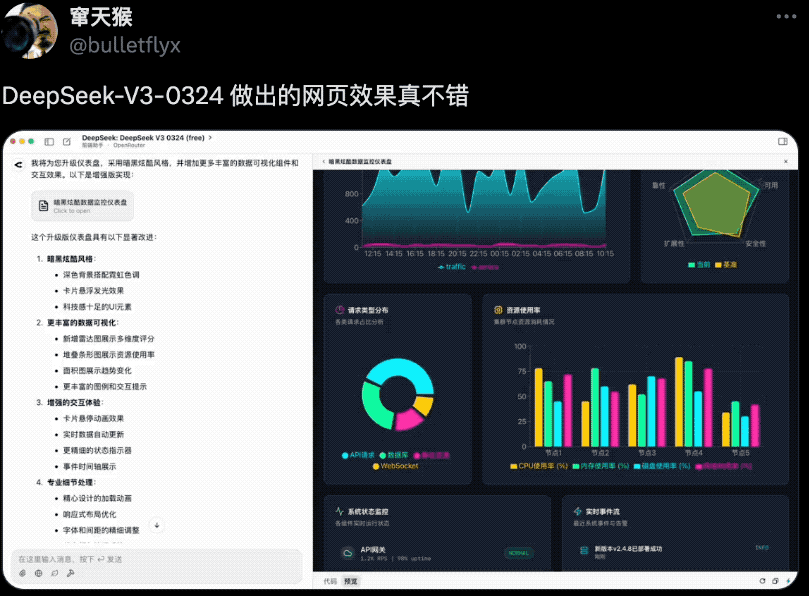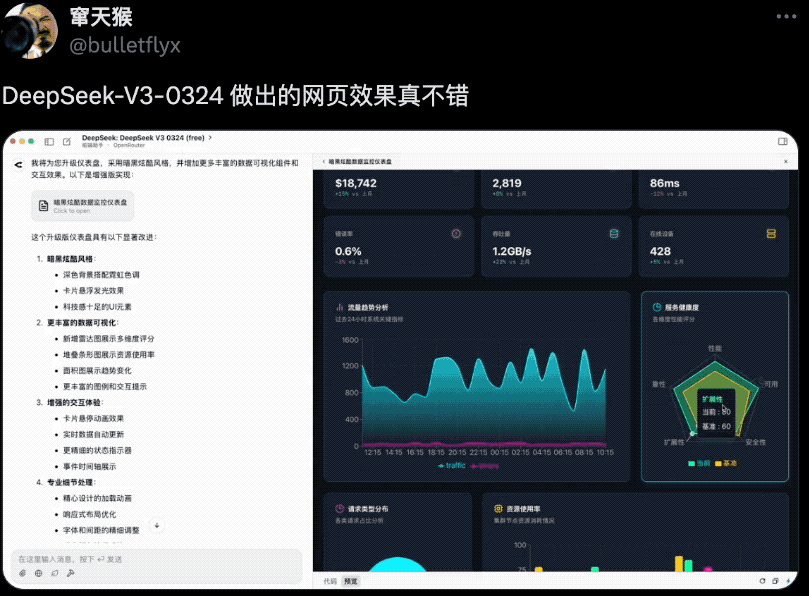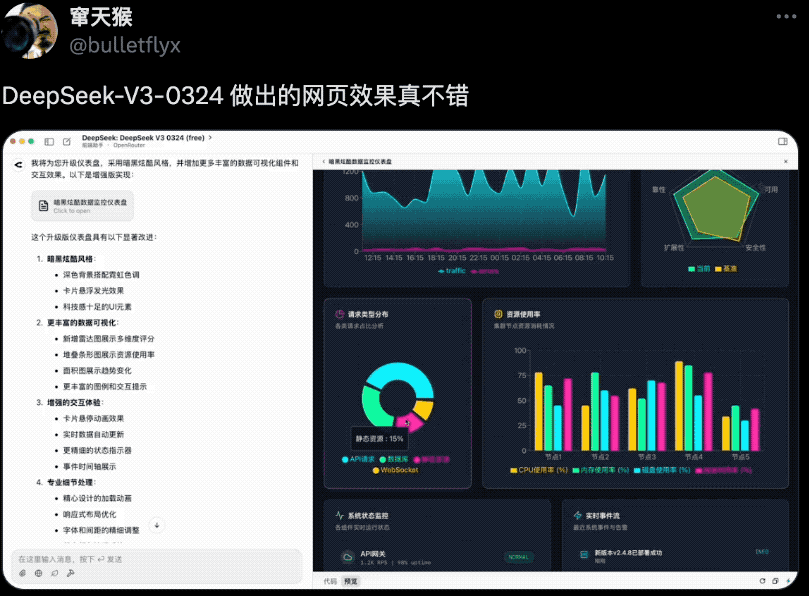
还有网友用它做出了炫酷的数据分析仪表盘,实现了一些可视化组件和交互效果,一点不比真人程序员写出来的效果差。
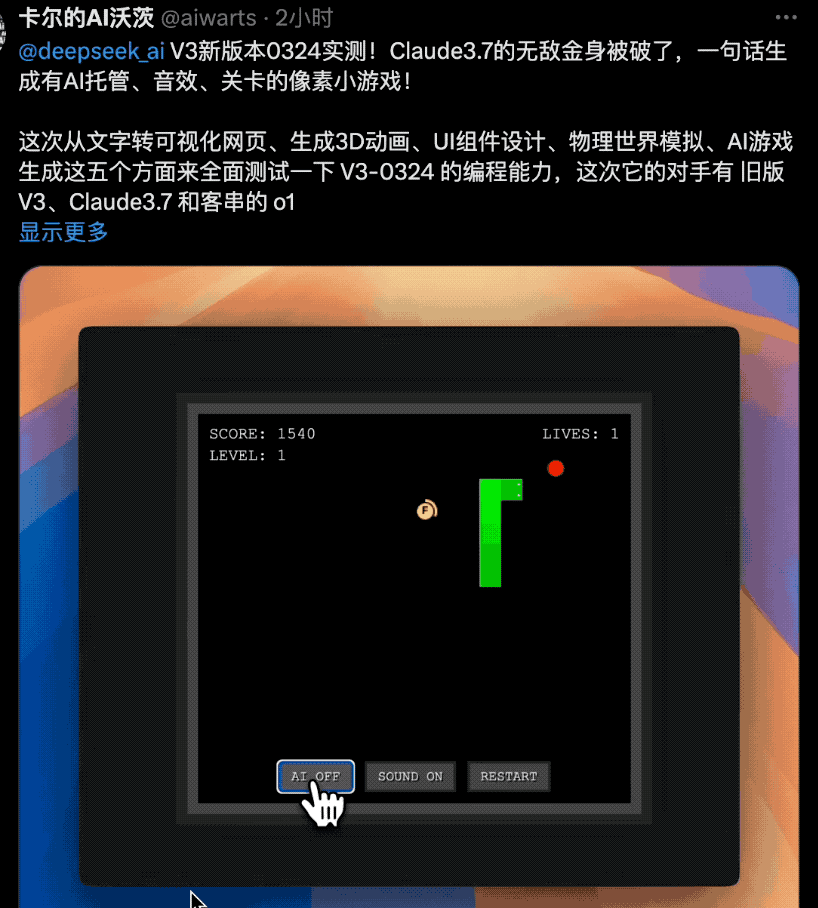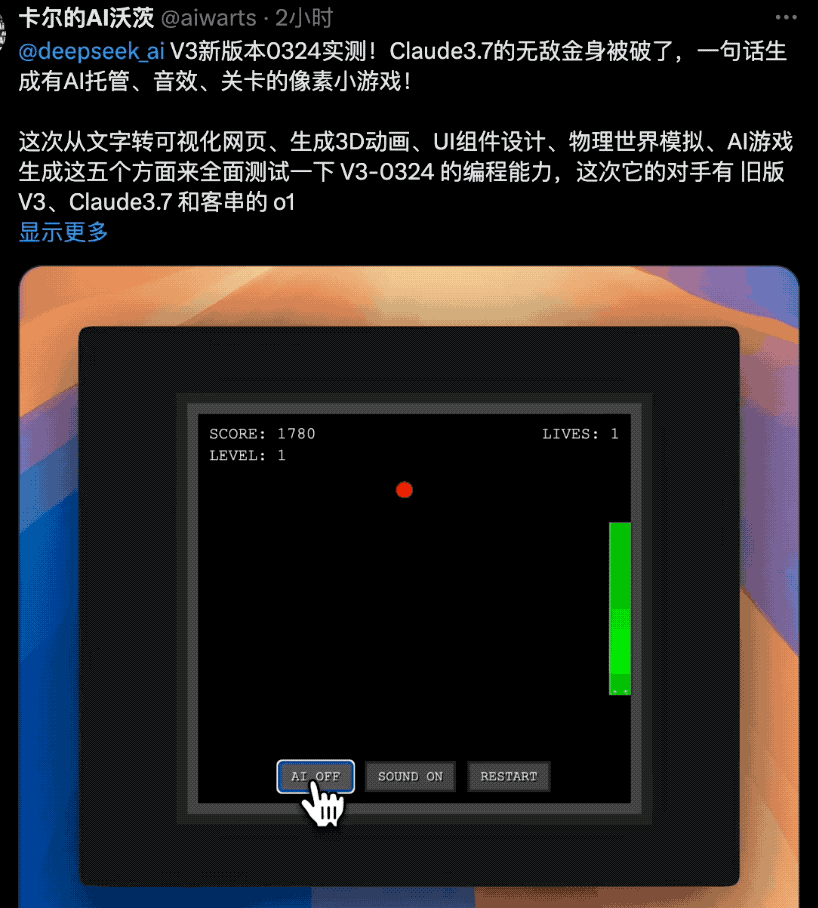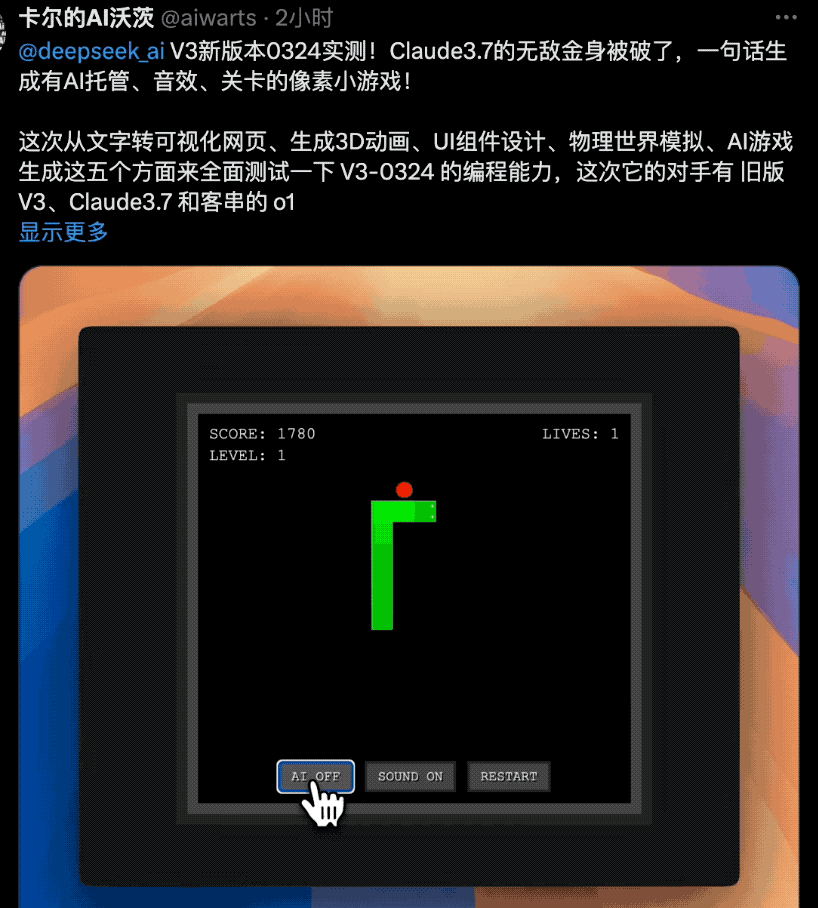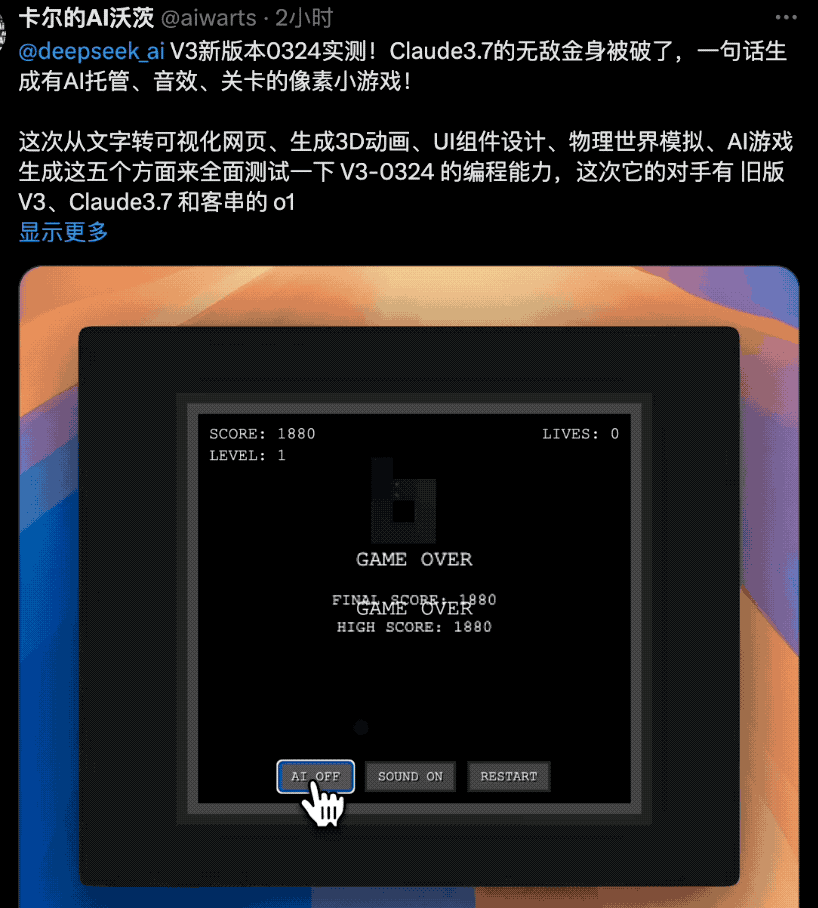
不仅是网页,它还能一句话生成有AI托管、音效、关卡的像素小游戏!在AIGame这条路上,Grok还没实现的愿望可能要被新V3超车赶上。
网友表示,DeepSeek说的这波“小版本更新”有点谦虚了,实测能力已经比上代V3实现了质的改进。
V3-0324出来后,R2什么时候会问世?这成为广大开发者关注和期待的下一个焦点。
有网友根据DeepSeek的发布节奏进行推测:2024.12 V3基础版到2025.01 R1推理版间隔了36天,2025.03 V3-0324到R2,如果一切顺利很可能会赶在在4月或者5月推出,这种”基础模型→推理增强”的迭代模式,正在改写行业规则。
业内人士分析,如果DeepSeek-R2遵循R1一样的开发轨迹和节奏,它很可能会直接挑战OpenAI的下一个旗舰模型GPT-5,双方的对阵代表着AI未来发展的两种相互竞争的愿景,DeepSeek在开源AI生态系统号召力、超低价API服务和建立在免费基础模型之上的企业解决方案开辟出了全新价值途径,正在大大提升中国AI技术的全球吸引力。
同时,这一现象也正在迅速缩小人们认知中的中美之间在AI领域的差距。就在几个月前,大多数美国分析人士估计中国在AI能力上落后美国1到2年,如今,这一差距已大幅缩短到仅为3到6个月,中国在某些领域已经接近持平甚至占据领先地位。
随着V3-0324进入全球各地的研究实验室和开发者平台,竞争格局不再仅仅局限于打造最强大的AI模型,而在于让尽可能多的人能够利用其AI模型进行创新开发,顶尖开源AI模型可能会凭借其广泛的普及性以及全球开发者贡献的集体创新智慧,在竞争中日益胜过封闭系统。
这与当年安卓系统对移动生态系统的影响有着相似之处,谷歌决定免费提供安卓系统,从而创建了一个最终在全球市场占据主导份额的超级平台,作为一家慷慨分享顶尖AI技术的公司,DeepSeek可能会对未来全球AI商业格局产生类似安卓系统般的影响力。

(文:头部科技)