

对于习惯数字阅读的人来说,扫描版 PDF 的最大痛点,就是它仅仅是纸质书的静态复制,而非真正的电子书。
如果你想要提取内容,手动复制麻烦不说,往往还会带上页眉页脚、乱七八糟的分页符,甚至 OCR(光学字符识别)也可能把“人类”识别成“八八艹”。
更别提那些包含数学公式、表格和复杂排版的书籍,转换起来更是噩梦。
今天介绍一款开源的 PDF 处理工具:PDF Craft,专注于将扫描书籍的 PDF 文件转化为 Markdown 或 EPUB 格式。
它基于本地 AI 模型运行核心功能,同时支持远程调用 LLM(如 DeepSeek V3)处理复杂任务。PDF Craft 的设计目标是“高效、精准、隐私友好”,通过智能算法和 LLM 技术,不仅提取文本,还能重构书籍结构,保留图表和公式。
该项目采用模块化架构,支持本地和远程两种模式。
本地模式利用 DocLayout-YOLO 和 OnnxOCR 等技术实现完全离线转换,而远程模式通过 LLM 增强了对大部头书籍的处理能力,为用户提供更优质的电子书转换体验。
核心功能
相比传统的 OCR 或 PDF 解析工具,PDF Craft 具备多个独特亮点:
-
• 本地 AI 驱动,无需联网,保护隐私 -
• Markdown & EPUB 输出,兼容性强 -
• 智能清理页眉、页脚、页码、脚注 -
• 公式、图表智能处理 -
• 自动构建目录和章节
快速使用
PDF Craft 支持本地运行,安装和使用方式也非常简单,支持 Python 环境部署。
使用 Python 自带的 pip 包管理命令就可一键安装完成。
pip install pdf-craft提示:如果你希望使用 GPU 加速,需要根据你的显卡配置安装相应的 CUDA 版本。
具体使用方法:
① PDF 转化为 MarkDown
此操作无需调用远程的 LLM,仅凭本地算力(CPU 或显卡)就可完成。第一次调用时会联网下载所需的模型。遇到文档中的插图、表格、公式,会直接截图插入到 MarkDown 文件中。
from pdf_craft import PDFPageExtractor, MarkDownWriter
extractor = PDFPageExtractor(
device="cpu", # 如果希望使用 CUDA,请改为 device="cuda:0" 这样的格式。
model_dir_path="/path/to/model/dir/path", # AI 模型下载和安装的文件夹地址
)
with MarkDownWriter(markdown_path, "images", "utf-8") as md:
for block in extractor.extract(pdf="/path/to/pdf/file"):
md.write(block)执行完成后,会在指定的地址生成一个 *.md 文件。若原 PDF 中有插图(或表格、公式),则会在 *.md 同级创建一个 assets 文件夹,以保存图片。而 MarkDown 文件中将以相对地址的形式引用 assets 文件夹中的图片。
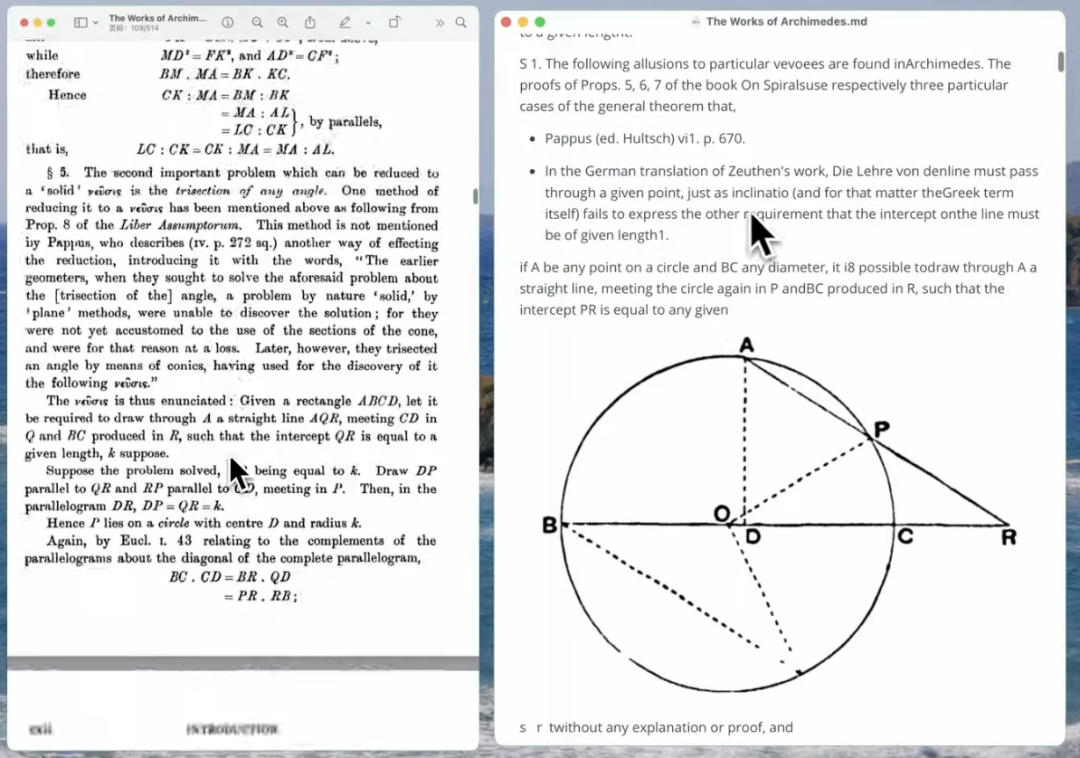
转化效果如下:

② PDF 转化为 EPUB
将使用 OCR 从 PDF 中扫描并识别文字。因此,也需要先构建 PDFPageExtractor 对象。(重复性操作代码省略掉了,可以参考上一步的)
from pdf_craft import PDFPageExtractor
extractor = PDFPageExtractor(
device="cpu", # 如果希望使用 CUDA,请改为 device="cuda:0" 这样的格式。
model_dir_path="/path/to/model/dir/path", # AI 模型下载和安装的文件夹地址
)之后,需要配置 LLM 对象。建议使用使用 DeepSeek,本库的 Prompt 基于最新的 V3 模型调试。
from pdf_craft import LLM
llm = LLM(
key="sk-XXXXX", # LLM 供应商提供的 key
url="https://api.deepseek.com", # LLM 供应商提供的 URL
model="deepseek-chat", # LLM 供应商提供的模型
token_encoding="o200k_base", # 进行 tokens 估算的本地模型名(与 LLM 无关,若不关心就保留 "o200k_base")
)如上两个对象准备好后,就可以开始扫描并分析 PDF 书籍了。
from pdf_craft import analyse
analyse(
llm=llm, # 上一步准备好的 LLM 配置
pdf_page_extractor=pdf_page_extractor, # 上一部准备好的 PDFPageExtractor 对象
pdf_path="/path/to/pdf/file", # PDF 文件路径
analysing_dir_path="/path/to/analysing/dir", # analysing 文件夹地址
output_dir_path="/path/to/output/files", # 分析结果将写入这个文件夹
)在分析结束后,将 output_dir_path 文件夹地址传给如下代码作为参数,即可最终生成 EPUB 文件。
from pdf_craft import generate_epub_file
generate_epub_file(
from_dir_path=output_dir_path, # 来自上一步分析所产生的文件夹
epub_file_path="/path/to/output/epub", # 生成的 EPUB 文件保存路径
)转化效果如下:

写在最后
在互联网时代,我们每天都在和各种数字化文档打交道,但扫描版 PDF 仍然是数字阅读的一大痛点。
无论是研究学术资料、阅读老旧书籍,还是归档重要文件,PDF Craft 都能提供一个高效、智能的解决方案,让原本“静态”的扫描版 PDF 变成真正可阅读、可搜索、可编辑的电子书。
它的价值,远不止于转换格式,更是一种数字化阅读体验的升级。
GitHub 项目地址:https://github.com/oomol-lab/pdf-craft

● 一款改变你视频下载体验的神器:MediaGo
● 新一代开源语音库CoQui TTS冲到了GitHub 20.5k Star
● 最新最全 VSCODE 插件推荐(2023版)
● Star 50.3k!超棒的国产远程桌面开源应用火了!
● 超牛的AI物理引擎项目,刚开源不到一天,就飙升到超9K Star!突破物理仿真极限!

(文:开源星探)