

昨天,DeepSeek悄悄发布了V3-0324新版本,没有任何预告。
就在刚刚 DeepSeek 终于官宣了,DeepSeek V3 模型已完成小版本升级,目前版本号 DeepSeek-V3-0324,用户登录官方网页、APP、小程序进入对话界面后,关闭深度思考即可体验。

这次更新带来了重大升级,特别是在推理性能方面取得了突破性进展。作为中国本土的领先AI企业,DeepSeek再次证明了在大模型领域的实力。
主要升级亮点
-
推理性能大幅提升:新版本在多项基准测试中表现出色,超越了GPT-4.5 -
前端开发能力增强:在前端开发技能上有显著提升,以下是来自官方的示例演示 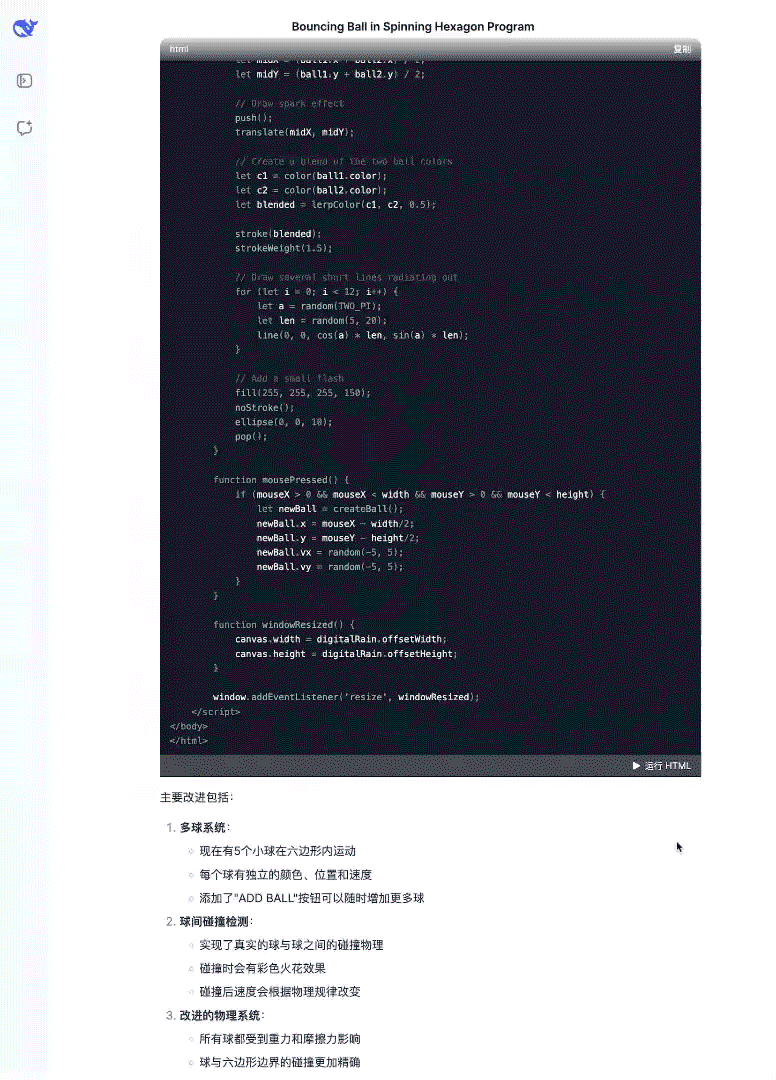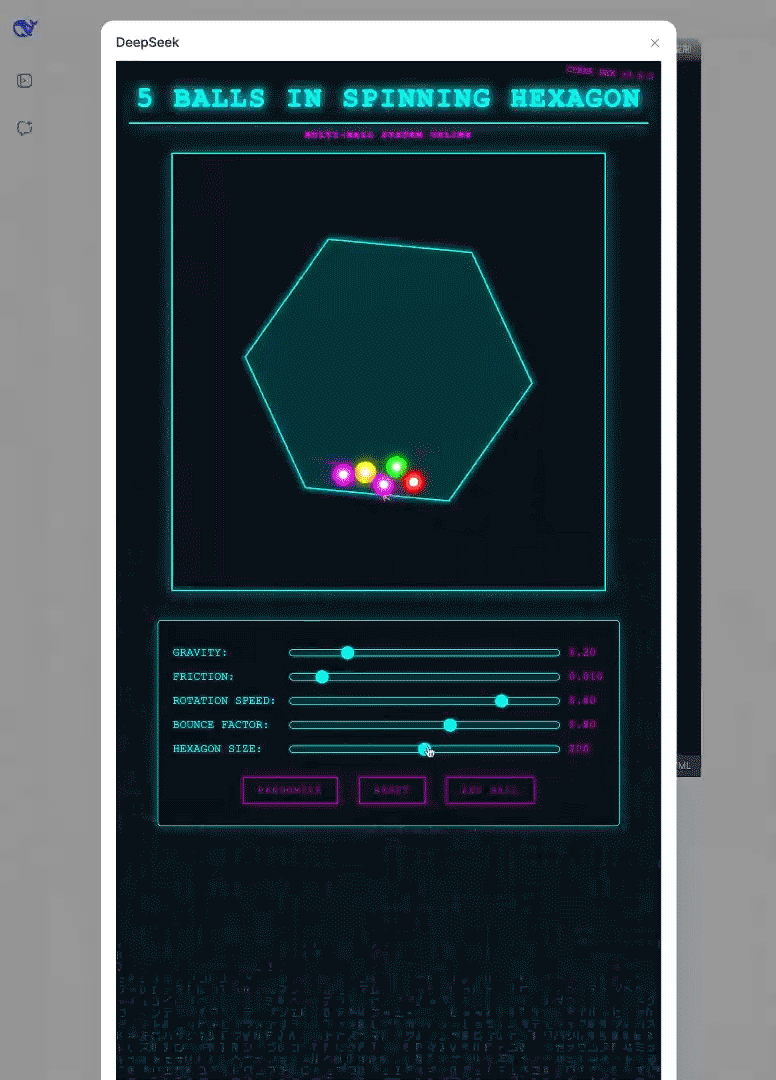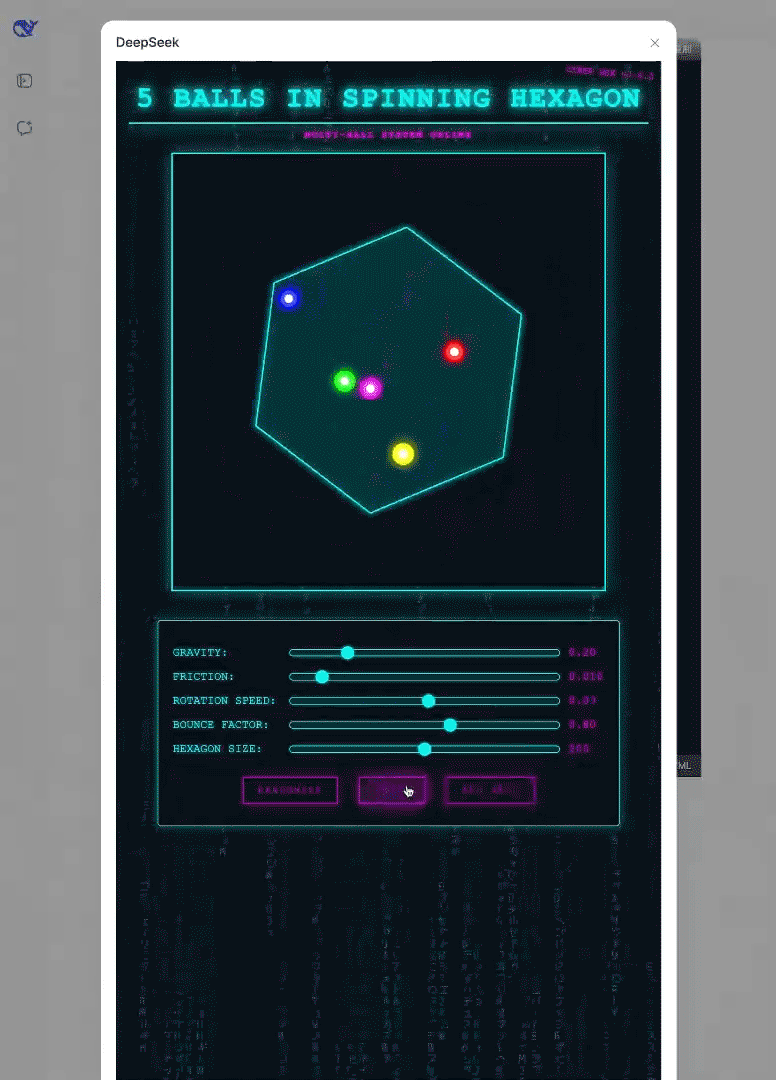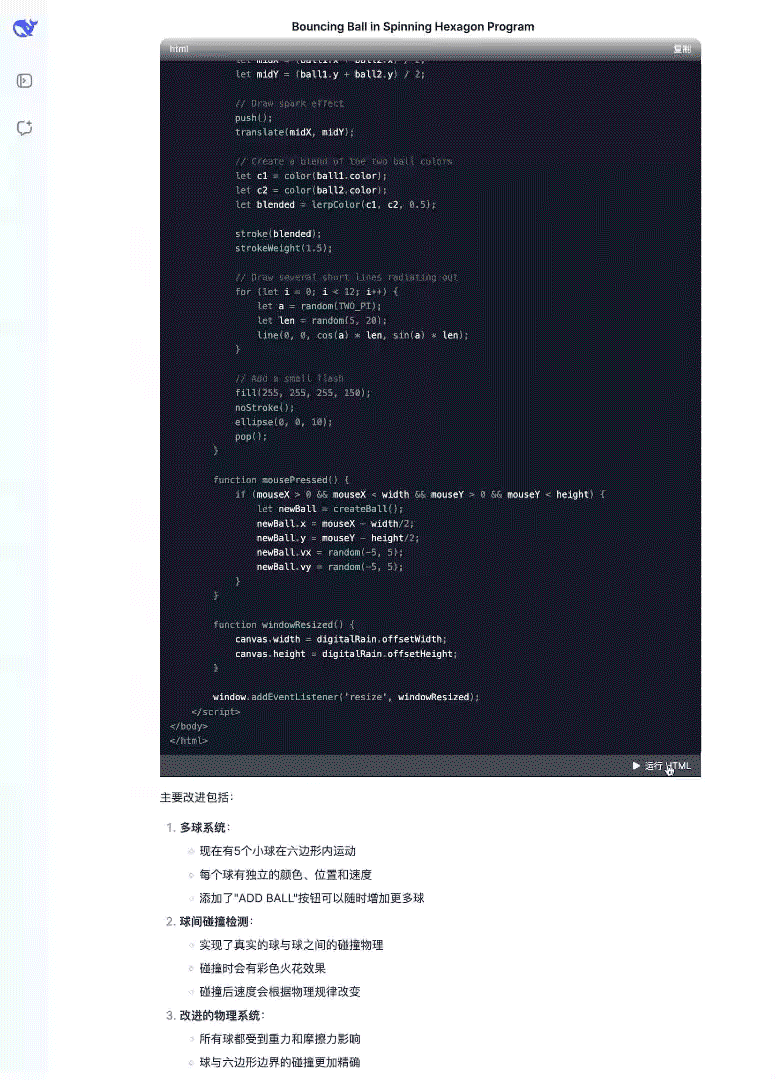
-
更智能的工具使用能力:工具调用能力得到全面增强 -
中文写作能力又升级了



这次更新显示了DeepSeek在AI技术路线上的独特思考,用更高效的方式实现了性能突破。
性能对比:数据说话
根据官方发布的数据,DeepSeek-V3-0324在重要的推理测试中都取得了领先成绩:
-
PQA Diamond测试:DeepSeek-V3得分68.4,而GPT-4.5仅为68.0 -
MATH-500测试:DeepSeek-V3得分90.7,远超GPT-4.5的82.2 -
AIME测试:DeepSeek-V3得分59.4,是GPT-4.5(26.0)的两倍多
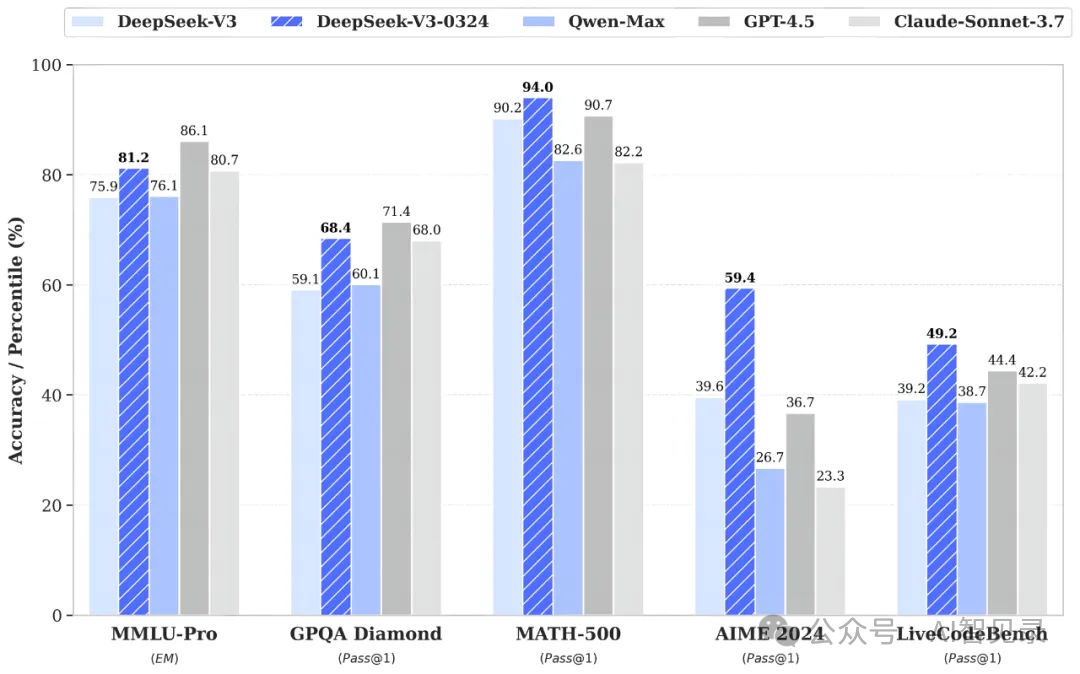
这些测试结果证明,DeepSeek-V3的推理能力已经超越了当前市场上最先进的大语言模型。特别是在数学和推理能力测试中,DeepSeek-V3的优势非常明显。
技术优势的背后
与其他大模型不同,DeepSeek采用了更高效的训练方法。据公开报道,DeepSeek的开发成本仅为GPT-4等模型的一小部分,约600万美元,而主流大模型开发成本通常超过1亿美元。
这种高效率的背后是对硬件资源的优化利用,DeepSeek团队巧妙地结合了高端和普通计算芯片,在保持高性能的同时大幅降低了成本。这种创新思路证明AI发展不只依赖无限的算力投入,而是取决于算法和架构的优化。
使用建议
可以根据不同场景灵活调整模型的工作模式:
-
对于日常问答、内容创作等常规任务,关闭 深度思考 可提高响应速度 -
对于数学问题、编程、复杂推理等任务,开启 深度思考 能发挥模型的最大潜力
访问 https://chat.deepseek.com/ 进行体验。
注意,体验时要管理深度思考,这样才能用上最新的 V3 模型。

开源与许可
值得注意的是,DeepSeek将模型采用MIT许可证发布,与DeepSeek-R1保持一致。这表明公司坚持开源精神,允许开发者自由使用和修改这些模型。
开源地址:https://huggingface.co/deepseek-ai/DeepSeek-V3-0324
API使用保持不变
对于已经在使用DeepSeek API的开发者,这是一个好消息——API使用方式保持不变,这意味着开发者可以无缝升级到新版本,而不需要修改现有代码。
这种向后兼容性考虑显示了DeepSeek对开发者体验的重视,让技术升级不再是负担。
网友的评价
今天就已经有网友对 DeepSeek-V3-0324 代码做了实测,结论就是超越 DeepSeek-R1!甚至超越 Claude-3.7!
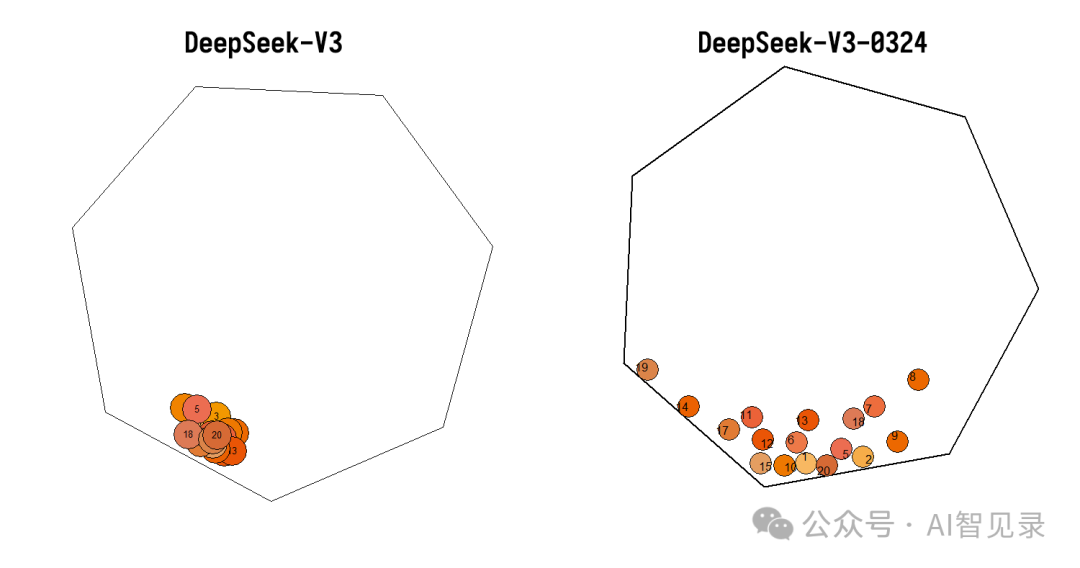

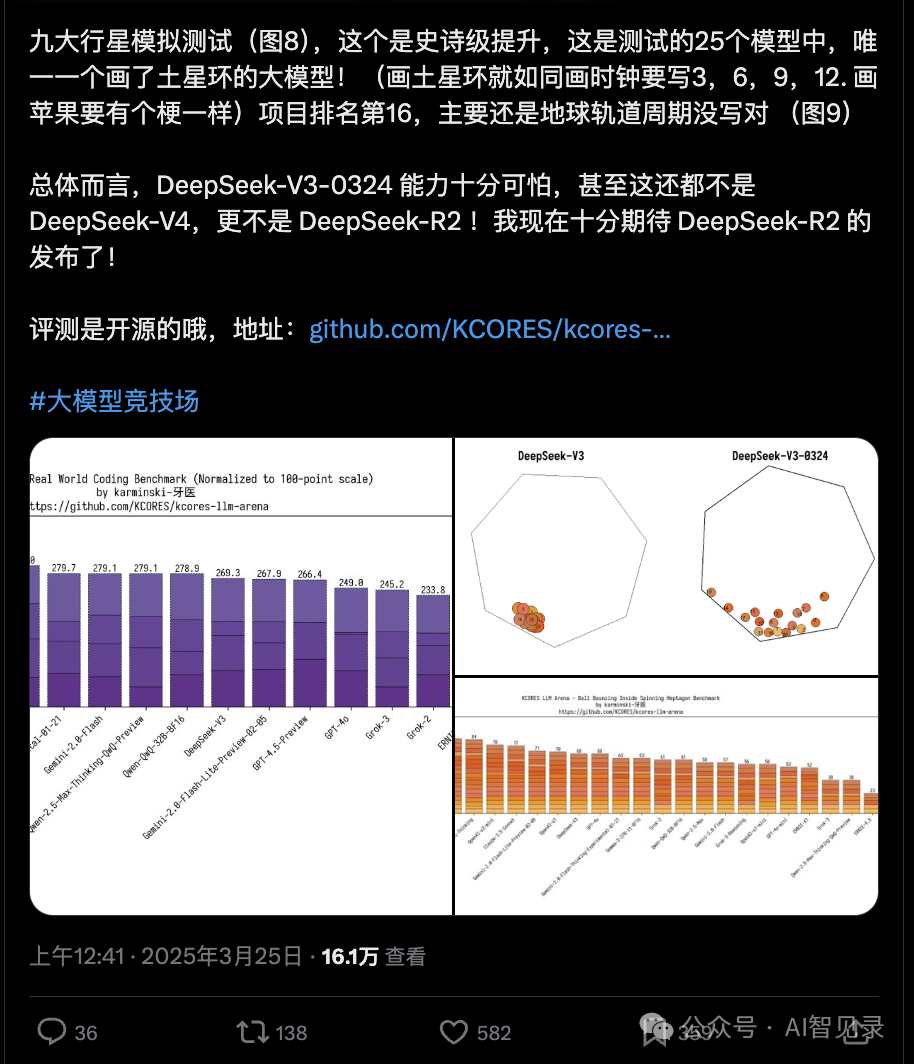
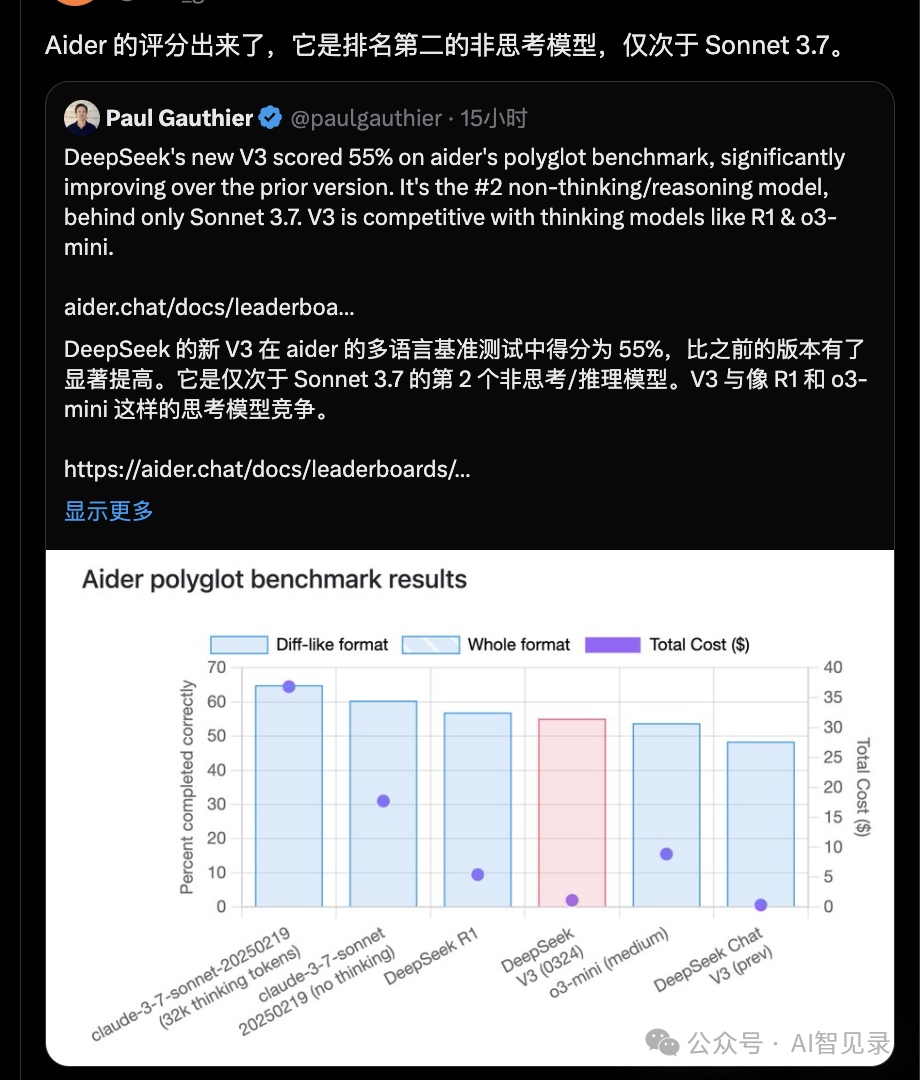
总结
DeepSeek-V3-0324的发布标志着AI技术的又一重要突破。它不仅在性能上超越了行业领先的GPT-4.5,还用更高效的方式实现了这一目标,为AI发展提供了新思路。
这种”用更少做更多”的理念,或许将成为未来AI发展的重要方向。我们期待看到这一强大模型在各个领域的应用,以及它将如何推动AI技术的进一步发展。
(文:AI智见录)