

我的课程笔记,欢迎关注:https://github.com/BBuf/how-to-optim-algorithm-in-cuda/tree/master/cuda-mode 。主要是LLM和cuda相关的
0x0 前言
最近SGLang在 https://github.com/sgl-project/sglang/pull/4356 中支持page_size>1的KV Cache Allocator之后让框架更加灵活,可以让用户接入新的Attention Backend,FlashMLA等先进特性。然后LinkedIn的几个小伙伴在SGLang中快速支持了FlashAttention V3的Backend,详情可以看:https://github.com/sgl-project/sglang/issues/4709 ,做了一个很好的示范。我这里尝试根据对SGLang支持Flash Attention V3的方法进行解读,如果大家有其它的Attention Backend需要对接,也可以参考他们的工作。
0x1. 效果
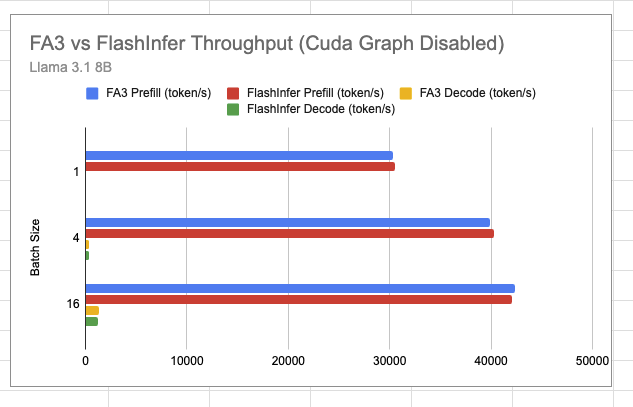
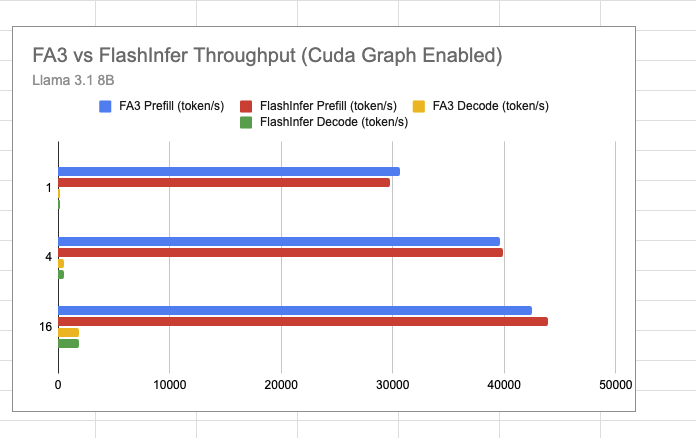
从Llama3的end2end测试结果来看基于Flash Attention V3的Backend和使用默认的FlashInfer的Backend差距不是很大,不过FA3支持FP8的Attention,后面可以期待一下支持后的性能。此外,这个支持比较早期,只支持Page Size=1,没有支持FP8和多模态模型等,可以关注Roadmap:https://github.com/sgl-project/sglang/pull/4680 ,感兴趣的话也可以参与。
0x2. 入口
可以阅读 https://github.com/zhaochenyang20/Awesome-ML-SYS-Tutorial/blob/main/sglang/code-walk-through/readme-CN.md 这里的 SGLang 代码走读对 SGLang 框架的整体有一个了解,然后文档里面ModelRunner 管理模型执行 (ModelRunner Manages Model Execution)这一节指出了ModelRunner和Attention Backend的关系以及Flashinfer Attention Backend实现的核心组件。
此外为了理解实现Flash Attention Backend时用到的一些 KV Cache 相关的数据结构,请提前阅读 https://github.com/zhaochenyang20/Awesome-ML-SYS-Tutorial/blob/main/sglang/kvcache-code-walk-through/readme-CN.md#kv-cache%E4%B8%8E%E5%86%85%E5%AD%98%E6%B1%A0 这个 SGLang KV Cache Walk Through文档。

然后支持Flash Attention V3的入口部分如下:
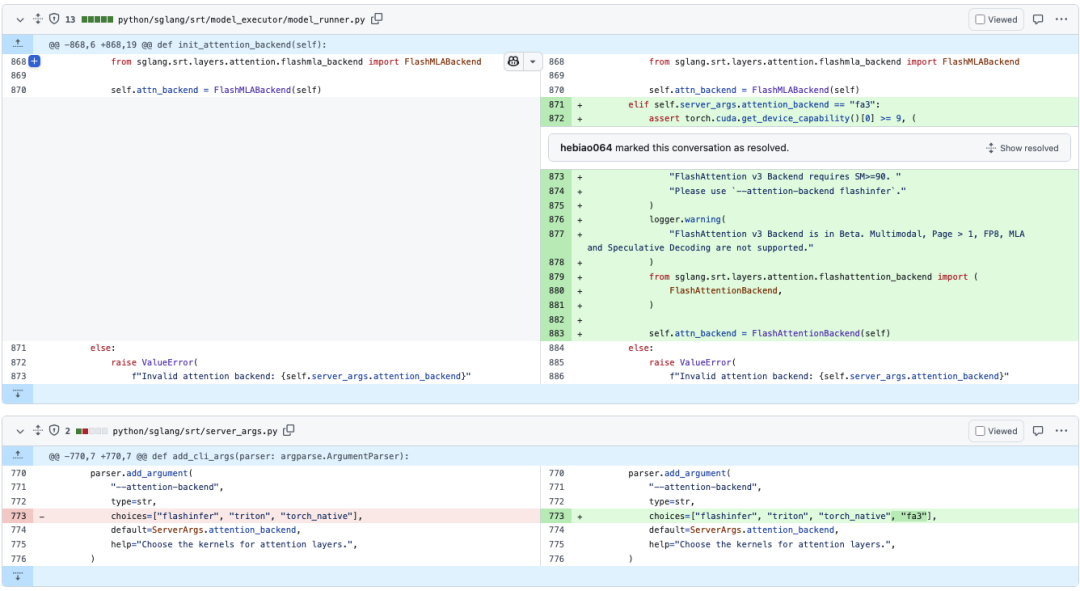
从这张图可以看到SGLang FA3 Backend的一些限制。
0x3. Flash Attention V3 Backend组件
如前所述,需要实现Flash Attention V3 Backend的一些组件,例如针对prefill/extend的forward_extend和针对decode的forward_decode,并且还需要维护forward需要的一些Meta信息,除此之外为了支持cuda graph还需要新增cuda graph初始化和replay相关的Meta信息。下面简单walk through一下这些步骤:
FlashAttentionBackend 初始化
@dataclass
class FlashAttentionMetadata:
"""用于解码操作的Meta信息,避免重复计算。"""
cu_seqlens_q: torch.Tensor = None# 查询序列的累积长度,用于批处理中定位每个序列的起始位置
cu_seqlens_k: torch.Tensor = None# 键序列的累积长度,用于批处理中定位每个序列的起始位置
max_seq_len_k: int = 0 # 批处理中最长键序列的长度
window_size: tuple = (-1, -1) # 注意力窗口大小,用于滑动窗口注意力机制,(-1, -1)表示无限窗口
page_table: torch.Tensor = None # 页表,用于在KV Cache中定位token的位置
cache_seqlens_int32: torch.Tensor = None# int32类型的序列长度,用于CUDA优化
max_seq_len_q: int = 0 # 批处理中最长查询序列的长度
class FlashAttentionBackend(AttentionBackend):
"""FlashAttention后端实现,提供高效的注意力计算。"""
def __init__(
self,
model_runner: ModelRunner,
skip_prefill: bool = False, # 是否跳过预填充阶段
):
super().__init__()
# 断言检查:滑动窗口和编码器-解码器架构不能同时使用
assertnot (
model_runner.sliding_window_size isnotNone
and model_runner.model_config.is_encoder_decoder
), "Sliding window and cross attention are not supported together"
# 初始化Meta信息
self.forward_metadata: FlashAttentionMetadata = None# 前向传播的Meta信息,用于缓存重复计算
self.max_context_len = model_runner.model_config.context_len # 最大上下文长度
self.device = model_runner.device # 计算设备(GPU)
self.decode_cuda_graph_metadata = {} # CUDA GraphMeta信息,用于加速decode推理
self.req_to_token = model_runner.req_to_token_pool.req_to_token # 请求到token的映射池
关于model_runner.req_to_token_pool和KV Cache具体的维护过程可以看SGLang KV Cache Walk Through(文档链接:https://github.com/zhaochenyang20/Awesome-ML-SYS-Tutorial/blob/main/sglang/kvcache-code-walk-through/readme-CN.md#kv-cache%E4%B8%8E%E5%86%85%E5%AD%98%E6%B1%A0)。
初始化forward需要的一些Meta信息
def init_forward_metadata(self, forward_batch: ForwardBatch):
"""初始化前向传播的Meta信息,用于缓存计算结果以避免重复计算。
这个函数根据传入的批次信息创建和初始化FlashAttentionMetadata对象,
该对象包含了注意力计算所需的各种Meta信息。
Args:
forward_batch: 包含前向传播批次信息的ForwardBatch对象
"""
# 创建一个新的Meta信息对象
metadata = FlashAttentionMetadata()
# 获取扩展序列长度信息
extend_seq_lens = forward_batch.extend_seq_lens
# 从批次中获取原始序列长度信息
seqlens_in_batch = forward_batch.seq_lens
# 将序列长度转换为int32类型,用于后续计算
metadata.cache_seqlens_int32 = seqlens_in_batch.to(torch.int32)
# 计算批次大小和设备信息
batch_size = len(seqlens_in_batch)
device = seqlens_in_batch.device
# 计算累积序列长度(cumulative sequence lengths),用于索引KV缓存
# pad操作在前面添加0,使得结果长度为batch_size+1
metadata.cu_seqlens_k = torch.nn.functional.pad(
torch.cumsum(seqlens_in_batch, dim=0, dtype=torch.int32), (1, 0)
)
# 计算批次中最大序列长度,用于内存分配和计算优化
metadata.max_seq_len_k = seqlens_in_batch.max().item()
# 根据请求索引构建page table,用于访问token
metadata.page_table = forward_batch.req_to_token_pool.req_to_token[
forward_batch.req_pool_indices, : metadata.max_seq_len_k
]
if forward_batch.forward_mode == ForwardMode.DECODE:
# 解码模式下,每个请求只有一个query token
# 因此cumulative lengths就是简单的0到batch_size的序列
metadata.cu_seqlens_q = torch.arange(
0, batch_size + 1, dtype=torch.int32, device=device
)
else:
# 检查是否所有请求都没有前缀
extend_no_prefix = not any(forward_batch.extend_prefix_lens)
# 根据是否有前缀计算query的累积长度
ifnot extend_no_prefix:
# 有前缀时,使用扩展序列长度计算
metadata.cu_seqlens_q = torch.nn.functional.pad(
torch.cumsum(extend_seq_lens, dim=0, dtype=torch.int32), (1, 0)
)
else:
# 无前缀时,query和key的累积长度相同
metadata.cu_seqlens_q = metadata.cu_seqlens_k
# 设置query的最大序列长度,用于内存分配
metadata.max_seq_len_q = seqlens_in_batch.max().item()
# 保存计算好的Meta信息
self.forward_metadata = metadata
实现forward_extend和foward_decode
def forward_extend(
self,
q: torch.Tensor,
k: torch.Tensor,
v: torch.Tensor,
layer: RadixAttention,
forward_batch: ForwardBatch,
save_kv_cache=True,
):
# 确定缓存位置 - 根据是否为交叉注意力来选择
cache_loc = (
forward_batch.out_cache_loc
ifnot layer.is_cross_attention
else forward_batch.encoder_out_cache_loc
)
# 如果提供了新的key和value,则保存到KV缓存中
if k isnotNone:
assert v isnotNone# 确保value也存在
if save_kv_cache:
forward_batch.token_to_kv_pool.set_kv_buffer(
layer, cache_loc, k, v, layer.k_scale, layer.v_scale
)
# 使用预计算的Meta信息,避免重复计算
metadata = self.forward_metadata
# 计算滑动窗口大小
# 注:不需要layer.sliding_window_size - 1因为在model.get_attention_sliding_window_size()中已经减1
# 这里的窗口是双向包含的
window_size = (
(layer.sliding_window_size, 0) # 如果有滑动窗口,设置左侧窗口大小
if layer.sliding_window_size isnotNone
else (-1, -1) # 否则使用全注意力(无限窗口)
)
# 获取KV缓存并解包为key和value
kv_cache = forward_batch.token_to_kv_pool.get_kv_buffer(layer.layer_id)
key_cache, value_cache = kv_cache[0], kv_cache[1]
# 使用flash_attn_with_kvcache执行注意力计算
o = flash_attn_with_kvcache(
# 重塑query张量为所需形状
q=q.contiguous().view(-1, layer.tp_q_head_num, layer.head_dim),
# 扩展key和value缓存维度
k_cache=key_cache.unsqueeze(1),
v_cache=value_cache.unsqueeze(1),
# 页表用于定位token
page_table=metadata.page_table,
# 缓存中的序列长度
cache_seqlens=metadata.cache_seqlens_int32,
# query和key的累积序列长度,用于批处理索引
cu_seqlens_q=metadata.cu_seqlens_q,
cu_seqlens_k_new=metadata.cu_seqlens_k,
# query的最大序列长度
max_seqlen_q=metadata.max_seq_len_q,
# 注意力计算的缩放因子
softmax_scale=layer.scaling,
# 是否使用因果掩码(前缀不看后缀)
causal=True,
# 注意力窗口大小
window_size=window_size,
# logits的软上限,防止数值不稳定
softcap=layer.logit_cap,
# key和value的反缩放因子
k_descale=layer.k_scale,
v_descale=layer.v_scale,
)
# reshape输出张量并返回
return o.view(-1, layer.tp_q_head_num * layer.head_dim)
forward_decode和forward_extend的实现类似,这里不再赘述。
CUDA-Graph 支持
下面这段代码包含2个函数,init_cuda_graph_state负责初始化固定大小的张量(如page_table)以避免CUDA Graph replay 时的内存分配;init_forward_metadata_capture_cuda_graph则负责在捕获CUDA Graph阶段准备必要的Meta信息,包括序列长度、累积序列长度、Page Table等关键的信息。
def init_cuda_graph_state(self, max_bs: int):
"""Initialize CUDA graph state for the attention backend.
Args:
max_bs (int): Maximum batch size to support in CUDA graphs
This creates fixed-size tensors that will be reused during CUDA graph replay
to avoid memory allocations.
"""
# 初始化用于解码操作的固定大小张量
# 创建一个字典来存储CUDA图的Meta信息
self.decode_cuda_graph_metadata = {
# Page Table用于token映射 (batch_size, max_context_len)
# 这个张量将用于在KV缓存中查找正确的位置
"page_table": torch.zeros(
max_bs, self.max_context_len, dtype=torch.int32, device=self.device
),
}
def init_forward_metadata_capture_cuda_graph(
self,
bs: int,
num_tokens: int,
req_pool_indices: torch.Tensor,
seq_lens: torch.Tensor,
encoder_lens: Optional[torch.Tensor],
forward_mode: ForwardMode,
spec_info: Optional[Union[EagleDraftInput, EagleVerifyInput]],
):
"""Initialize forward metadata for capturing CUDA graph."""
# 创建新的Meta信息对象来存储前向传播所需的信息
metadata = FlashAttentionMetadata()
# 获取序列信息并转换为int32类型(CUDA需要)
metadata.cache_seqlens_int32 = seq_lens.to(torch.int32)
batch_size = len(seq_lens)
device = seq_lens.device
# 计算累积序列长度,用于批处理索引
# 添加前导0,使形状从[batch_size]变为[batch_size+1]
metadata.cu_seqlens_k = torch.nn.functional.pad(
torch.cumsum(seq_lens, dim=0, dtype=torch.int32), (1, 0)
)
# 预计算最大序列长度,用于优化注意力计算
metadata.max_seq_len_k = seq_lens.max().item()
# 设置Page Table,用于在KV缓存中查找正确的位置
# 根据请求池索引选择相应的行
metadata.page_table = self.decode_cuda_graph_metadata["page_table"][
req_pool_indices, :
]
if forward_mode == ForwardMode.DECODE:
# 对于解码模式,预计算query的累积序列长度
# 在解码模式下,每个批次只有一个query token
metadata.cu_seqlens_q = torch.arange(
0, batch_size + 1, dtype=torch.int32, device=device
)
else:
# 目前仅支持解码模式的CUDA图
raise ValueError("Do not support Prefill Mode cuda graph")
# 将Meta信息存储在字典中,以便后续使用
self.decode_cuda_graph_metadata[bs] = metadata
self.forward_metadata = metadata
这两个函数实现了CUDA Graph replay阶段的Meta信息初始化功能。
def init_forward_metadata_replay_cuda_graph(
self,
bs: int,
req_pool_indices: torch.Tensor,
seq_lens: torch.Tensor,
seq_lens_sum: int,
encoder_lens: Optional[torch.Tensor],
forward_mode: ForwardMode,
spec_info: Optional[Union[EagleDraftInput, EagleVerifyInput]],
seq_lens_cpu: Optional[torch.Tensor],
):
"""初始化用于重放CUDA图的前向传播Meta信息。
Args:
bs: 批次大小
req_pool_indices: 请求池索引,用于定位每个请求的token
seq_lens: 每个请求的序列长度
seq_lens_sum: 所有序列长度的总和
encoder_lens: 编码器序列长度(可选)
forward_mode: 前向传播模式(解码/验证等)
spec_info: 特殊输入信息(用于Eagle模式)
seq_lens_cpu: CPU上的序列长度(可选)
"""
# 截取实际批次大小的序列长度
seqlens_in_batch = seq_lens[:bs]
# 获取预先分配的Meta信息对象
metadata = self.decode_cuda_graph_metadata[bs]
# 将序列长度转换为int32类型,CUDA操作需要
metadata.cache_seqlens_int32 = seqlens_in_batch.to(torch.int32)
# 计算累积序列长度,添加前导0,用于批处理索引
metadata.cu_seqlens_k = torch.nn.functional.pad(
torch.cumsum(seqlens_in_batch, dim=0, dtype=torch.int32), (1, 0)
)
# 预计算最大序列长度,用于内存优化
metadata.max_seq_len_k = seqlens_in_batch.max().item()
# 清零超出最大序列长度的page table部分,避免使用陈旧数据
metadata.page_table[:, metadata.max_seq_len_k :].fill_(0)
# 将请求对应的token映射复制到page table中
metadata.page_table[:, : metadata.max_seq_len_k].copy_(
self.req_to_token[req_pool_indices[:bs], : metadata.max_seq_len_k]
)
# 保存Meta信息以供解码阶段使用
self.forward_decode_metadata = metadata
def get_cuda_graph_seq_len_fill_value(self):
"""获取CUDA图中序列长度的填充值。
Returns:
int: 用于填充序列长度的默认值(0)
"""
return0
需要指出的是这几个函数都是在为CUDA Graph的捕获和重放做准备,真正的CUDA Graph捕获是在 https://github.com/sgl-project/sglang/blob/main/python/sglang/srt/model_executor/cuda_graph_runner.py#L165 这里的 CudaGraphRunner 完成的。而针对Decode应用捕获后的CUDA Graph也就是replay是在 https://github.com/sgl-project/sglang/blob/d89c0e4b7ed3b9d4b119cf66544765cc4c7adadb/python/sglang/srt/model_executor/model_runner.py#L90C7-L90C18 这个ModelRunner类的forward中完成的。下面红框部分:
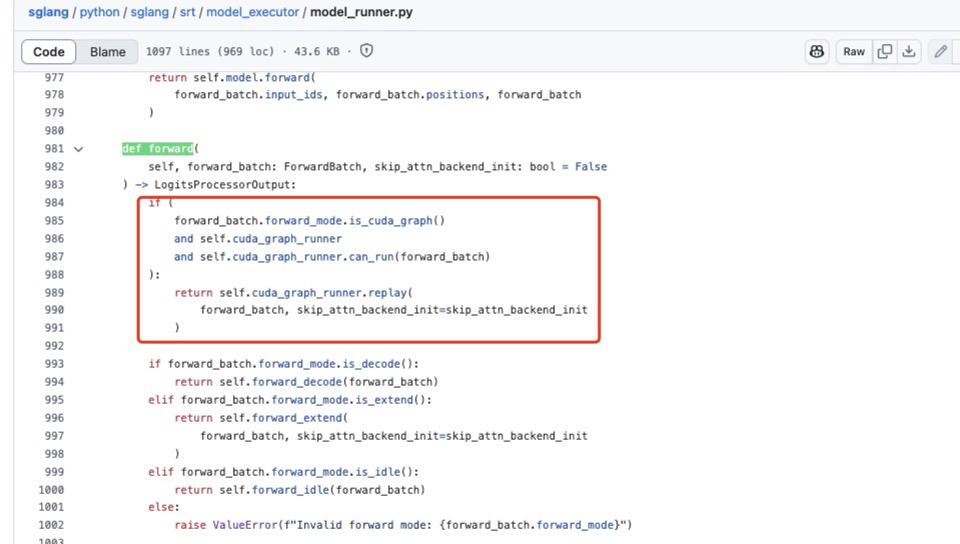
0x4. 总结
简要总结了一下在 SGLang 支持 Flash Attention V3 Backend的步骤并对关键组件如初始化Meta信息,不同模式的forward实现和cuda graph准备工作进行了注释,如果读者有类似需求可以参考。此外,博客提到的两篇前置的SGLang Code走读和KV Cache代码走读也是极力推荐的。
———————————————-分割线———————————————–
打扰了,还有人买我家的枇杷吗?可以点这个链接:攀枝花米易枇杷
(文:GiantPandaCV)