
项目简介
微软 OmniParser 图像识别模型的自托管版本。
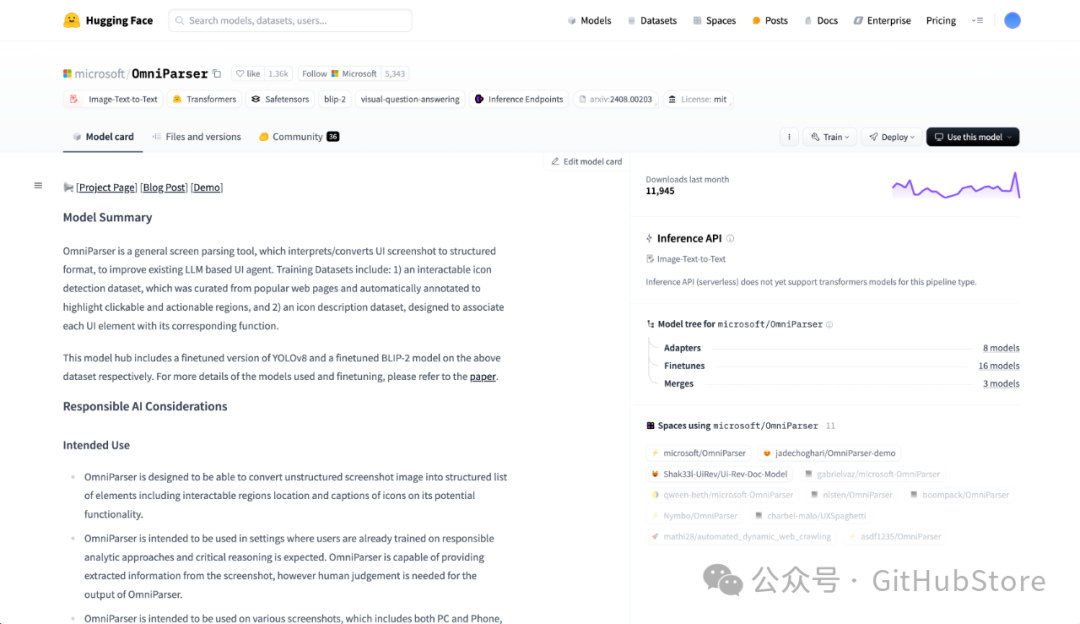
OmniParser 是一款通用屏幕解析工具,它将 UI 截图解释/转换为结构化格式,以改进现有的基于LLM的 UI 代理。训练数据集包括:1)一个可交互图标检测数据集,该数据集从流行的网页中精心挑选并自动标注以突出可点击和可操作区域,以及 2)图标描述数据集,旨在将每个 UI 元素与其对应的功能关联起来。
为什么?
已经有一个很棒的 HuggingFace gradio 应用程序为这个模型提供支持。它甚至提供了一个 API。但是
-
Gradio 的速度比直接提供模型(就像我们在这里做的那样)要慢得多 -
HF is rate-limited HF 有速率限制
它是如何工作的
如果您查看 Dockerfile,我们会从 HF 演示镜像开始,以检索所有权重和实用函数。然后我们添加一个简单的 FastAPI 服务器(在 main.py 下)来提供模型服务。
入门指南
环境要求
-
GPU 16GB 内存(建议使用交换空间)
本地
-
克隆仓库 -
构建 Docker 镜像: docker build -t omni-parser-app . -
运行 Docker 容器: docker run -p 7860:7860 omni-parser-app
自托管 API
我建议在 fly.io 上托管,因为它使用 CLI 部署既快又简单。
此存储库已准备好在 fly.io 上部署(请参阅 fly.toml 进行配置)。只需运行 fly launch 并按照提示操作。
文档
访问 http://localhost:7860/docs 查看 API 文档。只有一个路由 /process_image 返回
-
图像上绘制了边界框(以 base64 格式) -
解析列表中的文本描述元素 -
解析元素的边界框坐标
示例
|
|
|
|---|---|
 |
 |
相关项目
查看 OneQuery,这是一个浏览网页并返回针对任何查询(简单或复杂)的结构化响应的代理。OneQuery 使用 OmniParser 增强其功能。
项目链接
github.com/addy999/omniparser-api
扫码加入技术交流群,备注「开发语言-城市-昵称」
(文:GitHubStore)