
自托管的微软OmniParser图像转文本模型,让图像解析变得轻而易举
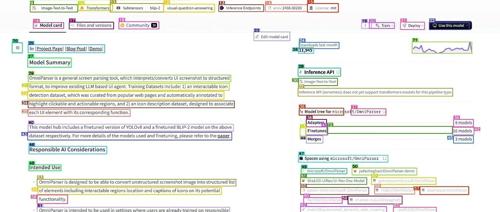
微软 OmniParser 图像识别模型的自托管版本,包含训练数据集和 FastAPI 服务器实现。通过 fly.io 简单部署,并提供 API 进行图像解析与边界框绘制等操作。
微软 OmniParser 图像识别模型的自托管版本,包含训练数据集和 FastAPI 服务器实现。通过 fly.io 简单部署,并提供 API 进行图像解析与边界框绘制等操作。

OmniParser V2发布,准确率提升和推理速度加快。OmniParser通过视觉解析界面元素,支持大语言模型,提供高效跨平台自动化解决方案。
微软发布OmniParser 2.0版本,能将屏幕截图转化为LLM可读结构化元素,提高多模态大模型的视觉识别准确度,并支持与多种语言模型集成。

微软发布OmniParser V2版本,能将屏幕截图转化为LLM可读懂的结构化元素,提高多模态大模型的视觉识别准确度。适用于自动化测试、操作等场景任务。通过像素级屏幕理解能力,支持多种大型语言模型。

微软发布OmniParser V2版本,可将大语言模型变成AI Agent,识别精准度提升39.6%,微软开源OmniTool和Gradio支持开箱即用。

本公众号介绍Omniparser框架及其在文本识别、关键信息提取和表格识别中的应用。通过两阶段、三种序列化方式有效压缩原始长序列,并使用空间和字符导向的窗口提示增强理解能力。
