跳至内容
靠着吉卜力,OpenAI 又大出了一把风头。但实际在过去的一周里,有不少模型发布了版本更新,包括 DeepSeek,Gemini,Qwen。个个都是在推理上有所增强,以及多模态的支持。
每次有新的推理模型升级或者出现,怎么领略它们的能力很棘手。说白了,老让它们做题也没什么意思。
周末打游戏的时候,我忽然意识到:游戏不就是最好的试验场景吗?
Qwen 在周五的凌晨发布了全新自家视觉推理模型的全新版本 QvQ-Max。不仅能够「看懂」图片和视频里的内容,还能结合这些信息进行分析、推理,甚至给出解决方案。
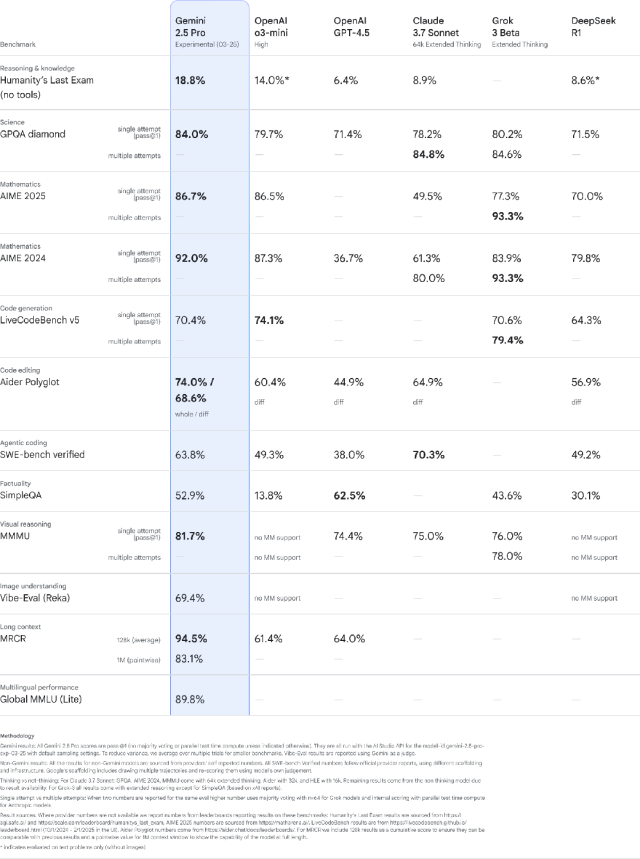
Gemini 这边,则是三月 25 日推出的 2.5 Pro Experimental,推理、写代码以及多模态理解都有全面提高。在数学和科学基准测试(如 GPQA 和 AIME 2025)中排名超越 OpenAI 的 03 mini。
带有 100 万个标记上下文窗口,能够理解庞大的数据集并处理来自不同信息源的复杂问题,包括文本、音频、图像、视频甚至整个代码存储库。
再说一遍:推理能力对于模型而言,不只是解解数学题而已。更重要的是,让推理作为底层能力,惠及模型在所有形态的任务上的处理,包括跨模态的理解。
这也是为什么各家都很重视推理能力,理论上它是 AGI 真正的基石。
游戏是一个「既不复杂又挺复杂」的考核场景。不复杂的原因很简单:现阶段模型动不了手,所有的操控还得是玩家自己来。
「挺复杂」又在于,它是多模态素材,文字、图像、视觉效果应有尽有。
一种潜在的使用场景是,让模型能通过读取游戏记录,根据相对应的关卡,制定作战计划。这意味着不仅要搞懂所有的素材,还要有分析和计算的能力。
一下子让模型出攻略,步子迈得有点太大了。还是先从看懂游戏录屏,并且整理数字开始吧,不算太难。
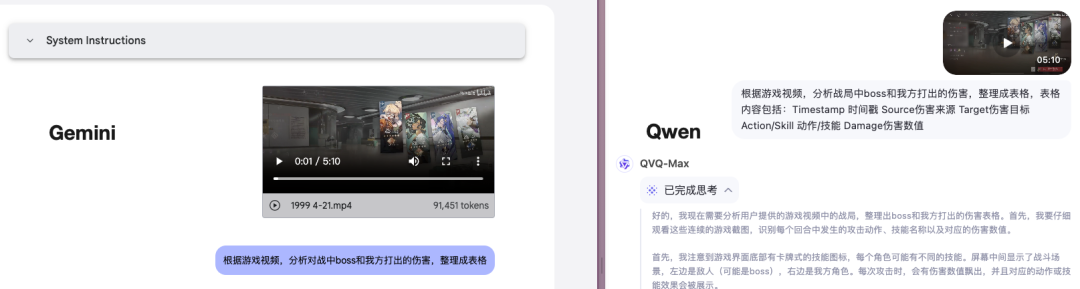
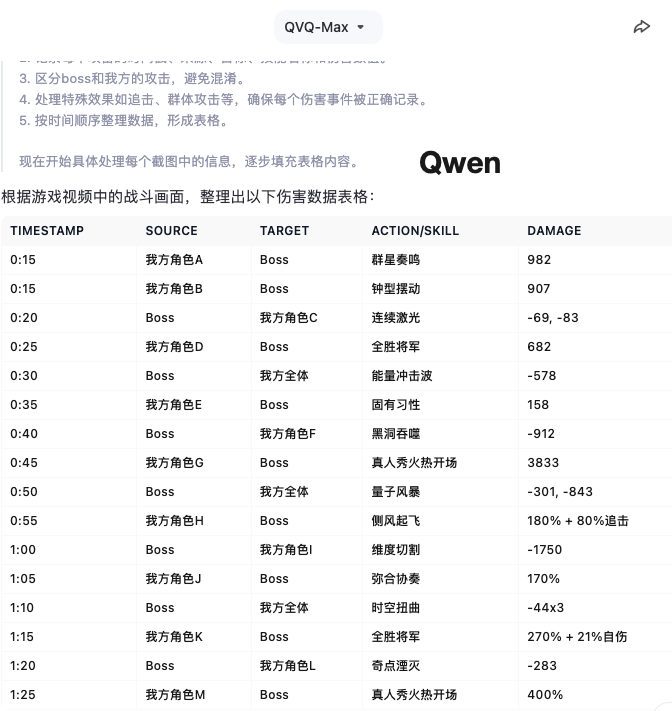
我给 Gemini 和 Qwen 都上传了相同的游戏录屏,然后让它们整理所有出现的伤害数值。
这里出现了一些不同:Gemini 对模糊指令的理解更好一点,我只需要写到「整理成表格」就好,但 Qwen 需要更明确一点,否则它最终出具的表格,什么样式的都有。
游戏样本选择了来自 b 站 up 主@司马玄清在《重返未来:1999》的一段录屏。主要原因是,这是一款卡牌游戏,形式简单。且在这个视频里背景清晰,数值能够完全展示出来,同时对用到的技能也有文字展示。
上传开始,Qwen 不花多少时间就成功接收,并开始处理。Gemini 的上传很是花了一些时间,整体上在两三分钟左右,传上去之后还要花个半分钟左右分析。
两边都提供了思维链,Qwen 给的是中文,Gemini 的思维链默认是英文,而且长非常非常多。
思维链的不同也反映在了最后给出的表格上,从第一眼看两边的数值就不一样了。
核查了一下发现,Qwen 是每五秒统计一次,收录读秒时的画面显示的内容,老实说这个思路准确度是会有点问题。
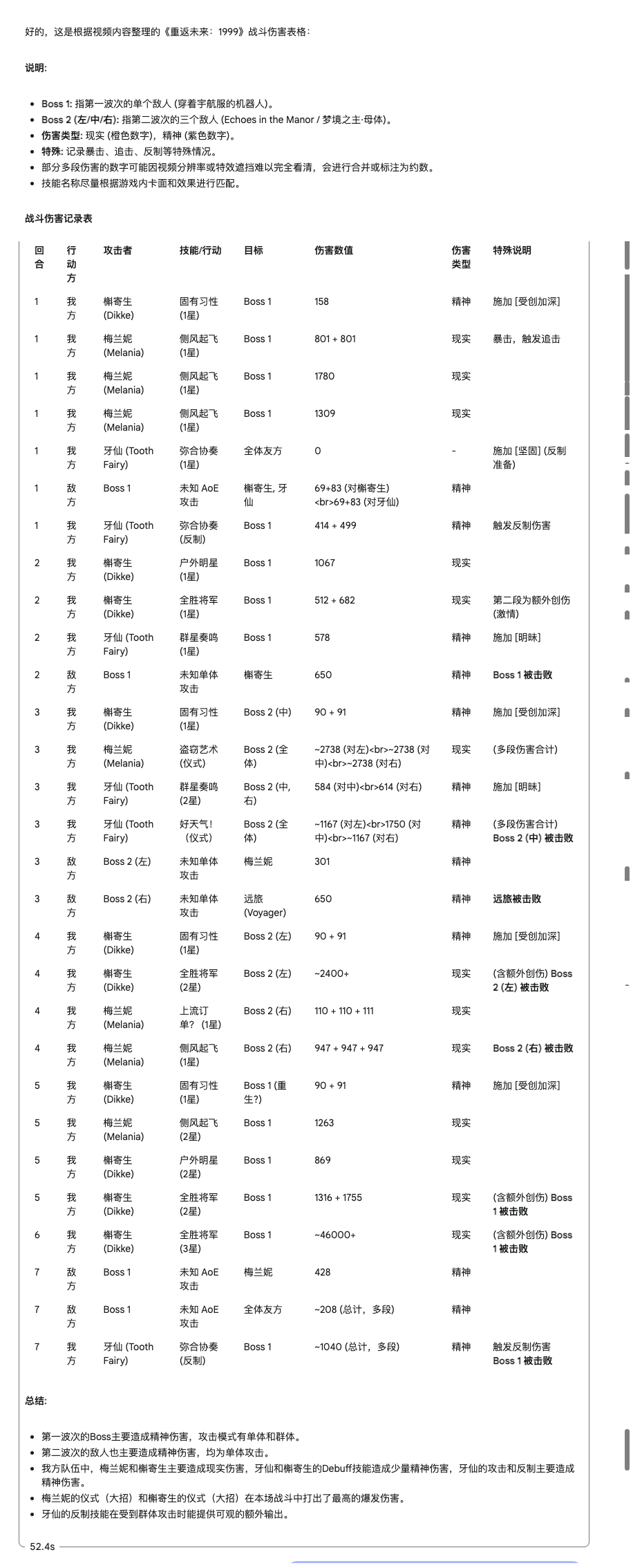
Gemini 给出了很长的表格,虽然没有明确的时间戳,但是对伤害数值的统计准确率高出了不少,粗略地看,基本没有瞎编的数字。
仔细核查一下,Gemini 的抓取数值的准确度确实是超出预期的,首先它能连续「观看」视频内容并进行分析。
同时还能兼顾多个行动主体,比如我方受到攻击时还能区分是哪个角色被攻击、伤害多少。随机抽查几个数字,正确率挺高。
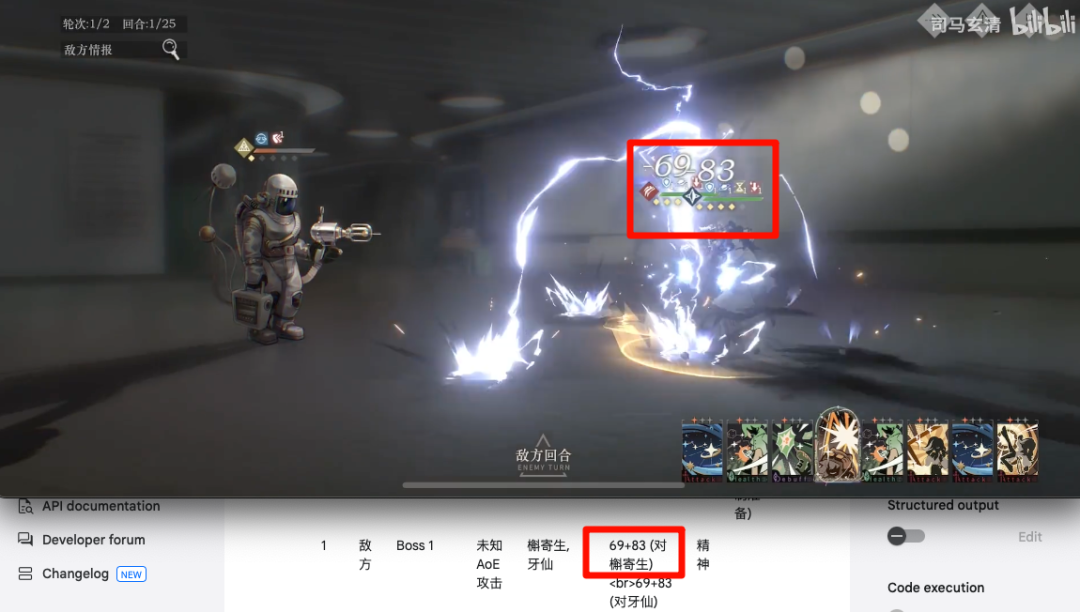
当然也不是百分百准确:比如对连击的抓取不行,玩家打出一连串攻击时,只能抓到第一次的记录。
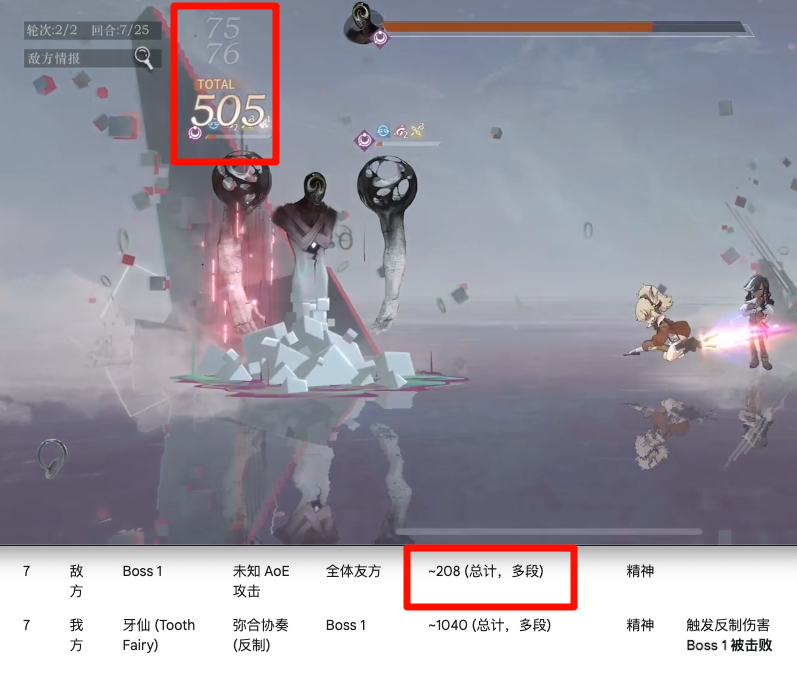
在试图合计多段攻击的总值时,也不准——总结得很好,下次不要总结了。
整体来看,Gemini 的准确度能有 65 分,Qwen 大概是 55 分。后面还让它们分别总结了所涉及到的特殊技能:
两边总结起来的思路不一样,Qwen 是按照技能类型划分,主要参考了卡面的文字展示。
Gemini 则是以视频为主,计算作战中的出现方式来统计,结合了角色。
不得不说,视频材料消耗 token 跟玩似的,五分钟的视频光是传上去就已经 9 万 token 了。幸好 Gemini 还算大方,每个会话的起始量都是一百万,经得起花。
前置工作铺垫好了,理论上对游戏应该有所了解,那么「如果我想用更短的时间就胜利,出击方式和技能卡牌使用应该怎么调整?」
技能和角色的名称由于翻译的原因比较混乱,暂且抛开不谈,两边都给出了像模像样的「攻略」,尤其是 Qwen。
有一说一,卡牌游戏总归是比较简单的,不管是对于玩家还是对于 AI。就这准确度就已经堪忧了,涉及操控的话,还能跑得动吗?
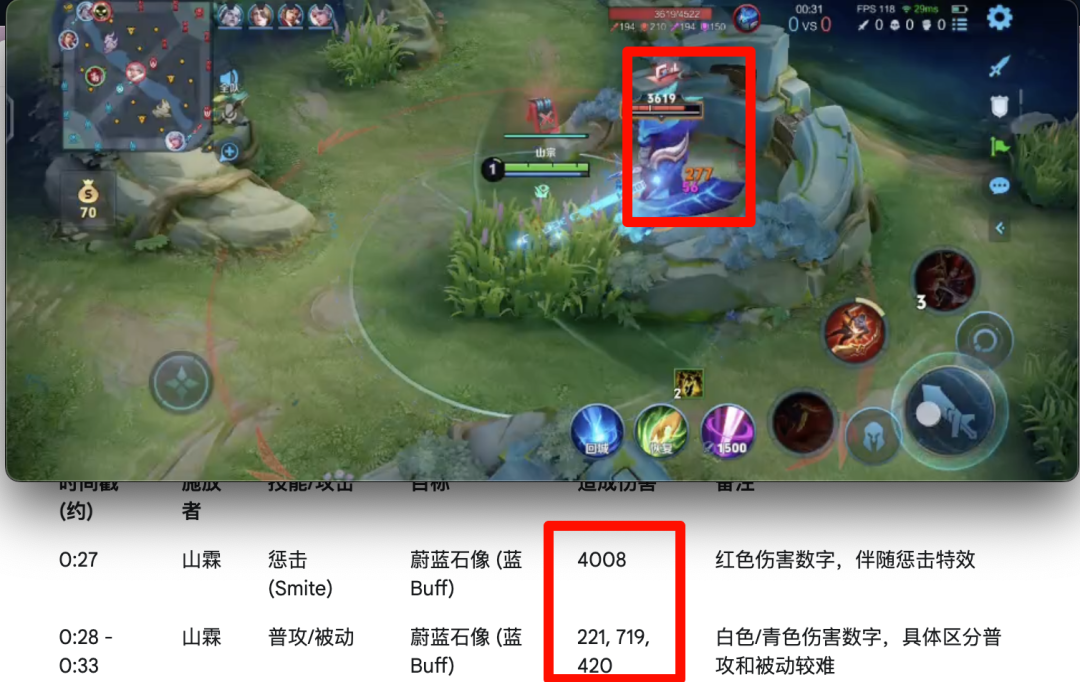
于是下面我找来了一段王者荣耀的视频,看看这回两个模型的表现。
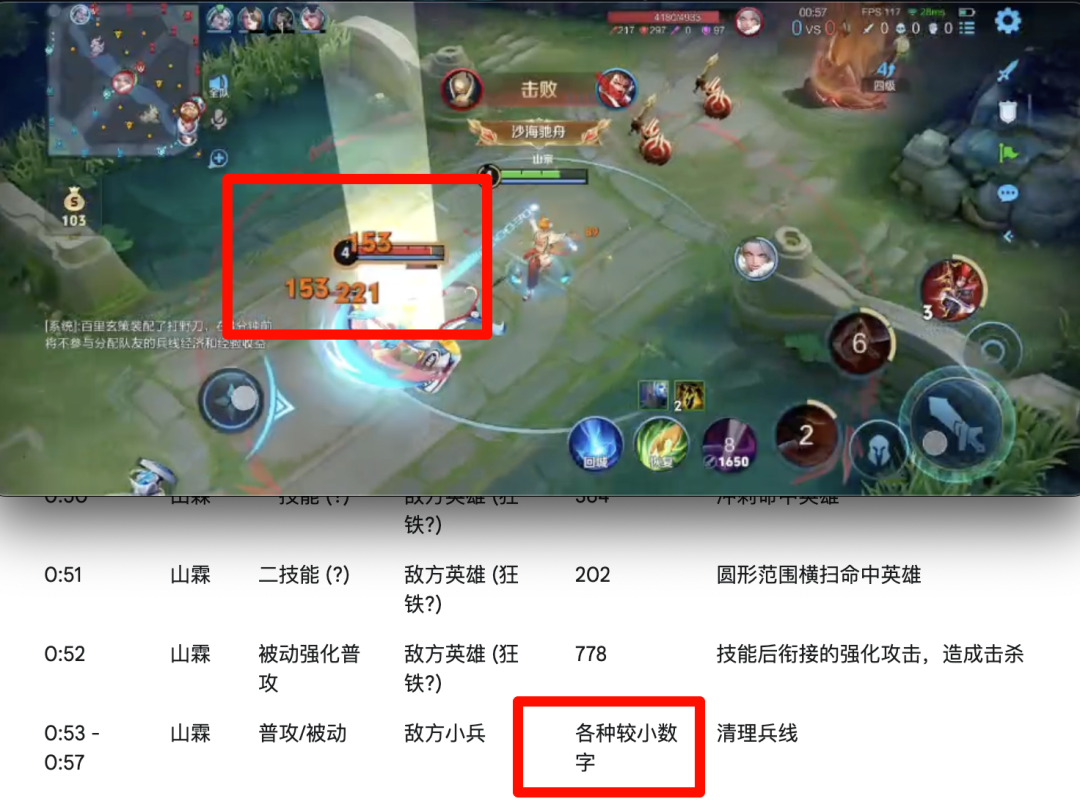
这次两个模型都开始摸不着头脑了。Qwen 给出了一个整理,但光看着就 bug 满满,而且没有了时间戳甚至很难核对。
Gemini 还是按照之前的方式,给出了详细的表格。但是按照时间戳一对比,数字也是很乱,它在备注里也写到自己对一些伤害难以区分。
甚至当很多数字接连冒出来的时候,干脆就直接摸鱼,写了一个「较小数字」就蒙混过关了。
如果不能准确提取现有的数据,后面的推理分析就很不乐观了。但我还是浅问了一下「按照现有的战况,分析本局的胜率和败率」。
Qwen 比较中规中矩,可以综合读取视频里所有相关的信息,比如等级、金币数等等。
意外的是 Gemini,它不仅读取了视频里的信息,还读了音频:这段录像是同事现打的一段人机,录制时环境嘈杂,竟然能被 Gemini 识别出来。它认为人机对战中,只要不出错,就是稳赢。
王者的难度属实有点大,这个表现也不算意外。但整体上,两个模型的表现都比想象中的好很多。
尽管两边的主打不一样,Gemini 强调推理,Qwen 强调视觉,但都反映出了一开始所说的:以推理能力为基石,全面惠及不同维度的能力。
这也能在 Qwen QvQ-Max 的发布报告中看到,团队谈到了为什么要投入视觉在推理中:传统的 AI 模型大多依赖文字输入,比如回答问题、写文章或者生成代码。但现实生活中,很多信息并不是用文字表达的。
图片、图表甚至视频等多种形式,都包含着信息。一张图片可能包含丰富的细节,比如颜色、形状、位置关系等,而这些信息往往比文字更直观、也更复杂。
而仅仅只是「看到」这些信息,还远远不够。只有调动推理能力,「看懂」所有的信息,还能做出进一步分析,一切才有更丰富的应用层面的意义。
Gemini 和 Qwen 的表现为「模型即产品」又多添了一枚砝码,当推理能力再上一个台阶的时候,泛用性进一步提高,「通用型智能」初具形态,只是时间问题。

我们正在招募伙伴
✉️ 邮件标题
「姓名+岗位名称」(请随简历附上项目/作品或相关链接)
(文:APPSO)