

 在人工智能领域,单一模态模型已取得显著成果,但人类智能是多模态的。我们通过视觉、听觉等感官感知世界,并通过语言等方式交流。因此,开发能处理多种模态输入并输出的模型,对实现更接近人类智能的系统至关重要。Qwen2.5-Omni 正是在此背景下诞生,旨在打破模态壁垒,实现更自然、高效的人机交互。本文将详细介绍其技术原理、功能特点、应用场景及快速使用方法。
在人工智能领域,单一模态模型已取得显著成果,但人类智能是多模态的。我们通过视觉、听觉等感官感知世界,并通过语言等方式交流。因此,开发能处理多种模态输入并输出的模型,对实现更接近人类智能的系统至关重要。Qwen2.5-Omni 正是在此背景下诞生,旨在打破模态壁垒,实现更自然、高效的人机交互。本文将详细介绍其技术原理、功能特点、应用场景及快速使用方法。一、项目概述
Qwen2.5-Omni是阿里巴巴于2025年3月27日发布并开源的端到端全模态大模型,能处理文本、图像、音频和视频等多种输入,并生成文本与自然语音输出。Qwen2.5-Omni 的目标是构建一个能够同时处理文本、图像、音频和视频等多种模态输入,并以流式方式生成文本和自然语音响应的端到端多模态大模型。该模型不仅要在多模态任务中表现出色,还要在单模态任务中保持竞争力,同时具备实时交互的能力,为各种应用场景提供强大的技术支持。

二、技术原理
(一)模型架构
Qwen2.5-Omni 采用了创新的 Thinker-Talker 双核架构。Thinker 模块类似于大脑,负责处理文本、音频、视频等多模态输入,生成高层语义表征及对应的文本内容。它基于 Transformer 解码器架构,融合音频和图像编码器进行特征提取。Talker 模块则类似于发声器官,以流式方式接收 Thinker 实时输出的语义表征与文本,流畅合成离散语音单元。Talker 采用双轨自回归 Transformer 解码器设计,在训练和推理过程中直接接收来自 Thinker 的高维表征,并共享全部历史上下文信息,形成端到端的统一模型架构。
(二)技术创新
1. TMRoPE(Time-aligned Multimodal RoPE):这是一种新的位置编码技术,通过时间轴对齐实现视频与音频输入的精准同步。这对于处理音视频融合任务至关重要,因为它能够确保不同模态的信息在时间上保持一致,从而提高模型的理解和生成能力。
2. 流式交互设计:Qwen2.5-Omni 支持完全实时交互,能够处理分块输入并即时输出。这种设计使得模型可以像人类一样进行连续的、无延迟的对话和响应,大大提升了用户体验。
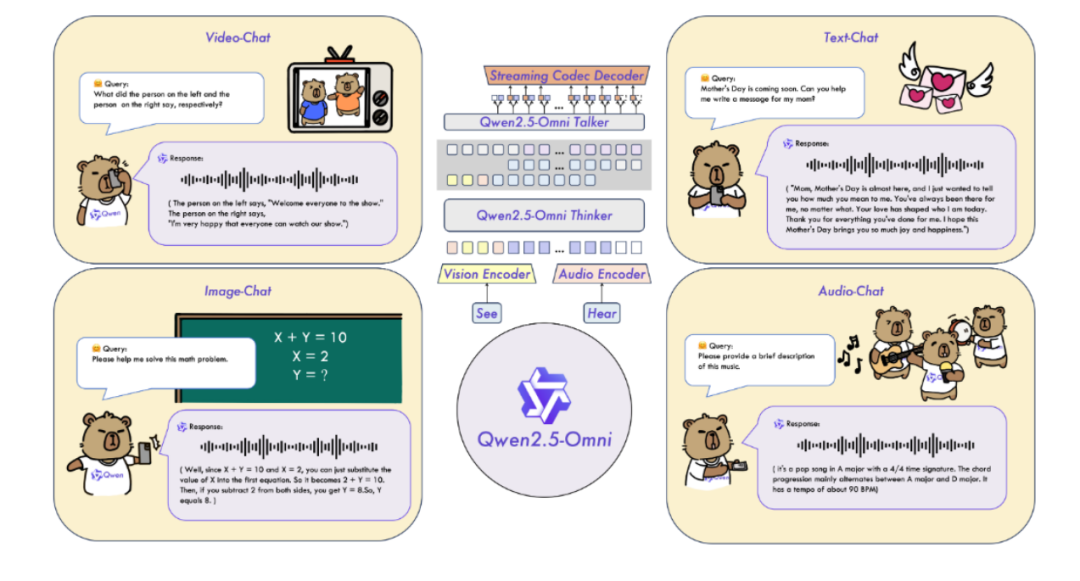
三、功能特点
(一)全能创新架构
Qwen2.5-Omni 的 Thinker-Talker 架构使其能够同时处理文本、图像、音频和视频等多种模态输入,并生成相应的文本和语音响应。这种架构不仅支持跨模态理解,还能够以流式方式输出结果,使得模型在处理复杂的多模态任务时更加高效和自然。
(二)实时音视频交互
Qwen2.5-Omni 支持实时音视频交互,能够处理分块输入并即时输出。这意味着模型可以在接收到输入数据的同时,立即生成响应,无需等待所有数据输入完成。这种实时性对于需要快速响应的应用场景(如视频会议、实时翻译等)具有重要意义。
(三)自然流畅的语音生成
Qwen2.5-Omni 在语音生成的自然性和稳定性方面表现出色。它能够生成流畅、自然的语音,超越了许多现有的流式和非流式语音生成模型。这种高质量的语音生成能力使得模型在语音交互应用中更具优势。
(四)全模态性能优势
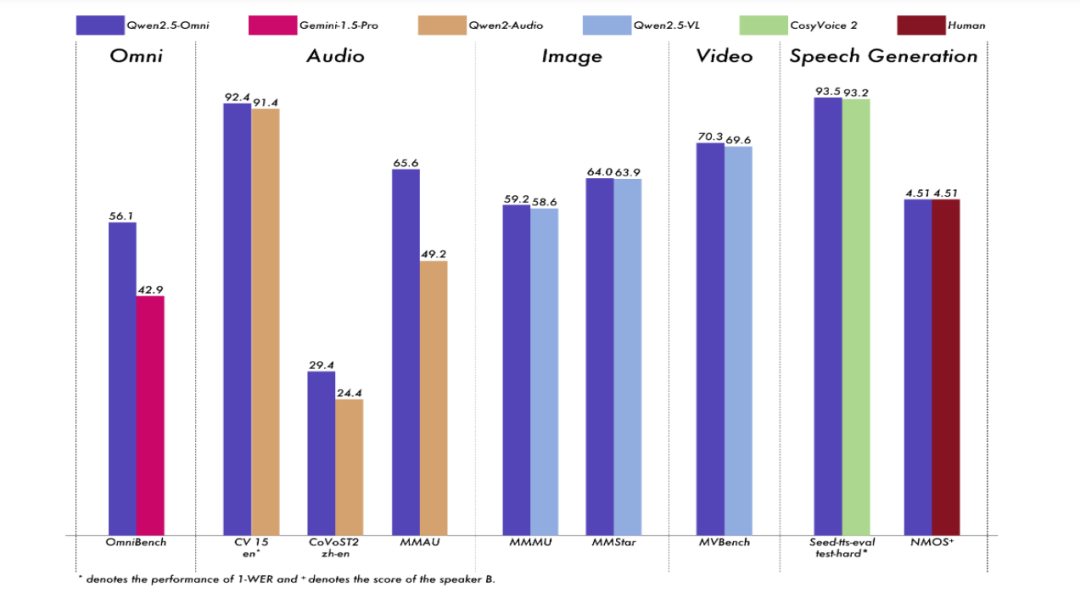
Qwen2.5-Omni 在多模态任务 OmniBench 中达到了 SOTA(State-of-the-Art)表现。此外,在单模态任务中,如语音识别(Common Voice)、翻译(CoVoST2)、音频理解(MMAU)、图像推理(MMMU、MMStar)、视频理解(MVBench)以及语音生成(Seed-tts-eval 和主观自然听感)等多个领域,Qwen2.5-Omni 也表现出色。这表明该模型不仅在多模态任务中表现出色,还在单模态任务中保持了竞争力。
(五)卓越的端到端语音指令跟随能力
Qwen2.5-Omni 在端到端语音指令跟随方面表现出色。它能够准确理解和执行语音指令,与文本输入处理的效果相当。这种能力在 MMLU 通用知识理解和 GSM8K 数学推理等基准测试中得到了验证。
四、应用场景
(一)智能语音助手
Qwen2.5-Omni 的实时音视频交互能力和自然流畅的语音生成能力使其成为理想的智能语音助手。它可以处理用户的语音指令,实时生成语音回应,为用户提供更加自然和便捷的交互体验。
(二)多模态内容创作
在内容创作领域,Qwen2.5-Omni 可以同时处理文本、图像和视频输入,并生成相应的文本或语音描述。这使得创作者能够更加高效地生成多模态内容,如视频字幕、图像描述等。
(三)教育与培训
Qwen2.5-Omni 可以用于教育和培训领域,通过处理多种模态的输入,为学生提供更加丰富和个性化的学习体验。例如,它可以实时生成语音讲解,帮助学生更好地理解复杂的概念。
(四)智能客服
在智能客服领域,Qwen2.5-Omni 可以实时处理客户的语音或文本问题,并生成准确的回应。这种能力可以提高客服效率,改善客户体验。
五、性能表现
(一)多模态任务
Qwen2.5-Omni 在多模态任务 OmniBench 中达到了 SOTA 表现。这表明该模型在处理多模态输入和输出方面具有显著优势。
(二)单模态任务
在单模态任务中,Qwen2.5-Omni 也表现出色。例如,在语音识别(Common Voice)、翻译(CoVoST2)、音频理解(MMAU)、图像推理(MMMU、MMStar)、视频理解(MVBench)以及语音生成(Seed-tts-eval 和主观自然听感)等多个领域,Qwen2.5-Omni 都取得了优异的成绩。
(三)实时性
Qwen2.5-Omni 支持完全实时交互,能够处理分块输入并即时输出。这种实时性使得模型在需要快速响应的应用场景中具有显著优势。
(一)在线快速体验
访问下面在线地址,即可在线快速体验Qwen2.5-Omni-7B-Demo模型
体验地址:https://huggingface.co/spaces/Qwen/Qwen2.5-Omni-7B-Demo
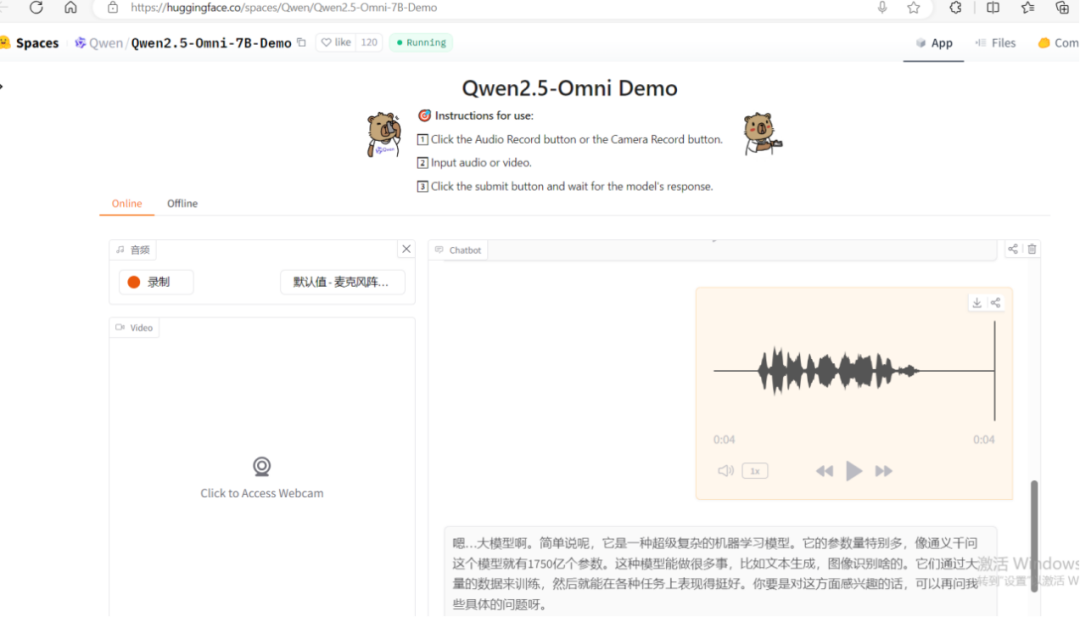
在线体验了 Qwen2.5-Omni 之后,我必须说,它的表现简直超出了我的预期,整体使用效果令人印象深刻。无论是处理复杂的多模态输入,还是生成流畅自然的语音和文本输出,Qwen2.5-Omni 都展现出了卓越的性能。特别是它的实时交互能力,让我感觉就像在和一个真正的人类进行对话一样,毫无延迟和卡顿,这种流畅的交互体验让人感觉非常棒。
(二)本地部署推理(transformers)
在开始使用 Qwen2.5-Omni 之前,需要确保你的环境满足以下要求:
-
Python 版本:推荐使用 Python 3.9 或更高版本。
-
PyTorch:安装 PyTorch 2.0 或更高版本,确保支持 CUDA 运算。
-
Transformers:安装 Hugging Face 的 Transformers 库,版本建议为 4.36.0 或更高。
-
其他依赖:安装 accelerate 和 qwen-omni-utils 库,用于加速训练和处理多模态数据。
可以通过以下命令安装必要的依赖:
pip install transformers由于Qwen2.5-Omni的代码在Hugging Face transformers中目前处于未合并阶段,尚未并入主分支,官方建议从源代码构建:pip uninstall transformerspip install git+https://github.com/huggingface/transformers@3a1ead0aabed473eafe527915eea8c197d424356pip install accelerate安装qwen-omni相关依赖工具包pip install qwen-omni-utils[decord]
以下是一个使用Qwen2.5-Omni 模型的代码示例:
import soundfile as sffrom transformers import Qwen2_5OmniModel, Qwen2_5OmniProcessorfrom qwen_omni_utils import process_mm_info# default: Load the model on the available device(s)model = Qwen2_5OmniModel.from_pretrained("Qwen/Qwen2.5-Omni-7B", torch_dtype="auto", device_map="auto")# 我们建议启用 flash_attention_2 以获取更快的推理速度以及更低的显存占用.# model = Qwen2_5OmniModel.from_pretrained(# "Qwen/Qwen2.5-Omni-7B",# torch_dtype="auto",# device_map="auto",# attn_implementation="flash_attention_2",# )processor = Qwen2_5OmniProcessor.from_pretrained("Qwen/Qwen2.5-Omni-7B")conversation = [{"role": "system","content": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech.",},{"role": "user","content": [{"type": "video", "video": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-Omni/draw.mp4"},],},]# Preparation for inferencetext = processor.apply_chat_template(conversation, add_generation_prompt=True, tokenize=False)audios, images, videos = process_mm_info(conversation, use_audio_in_video=True)inputs = processor(text=text, audios=audios, images=images, videos=videos, return_tensors="pt", padding=True)inputs = inputs.to(model.device).to(model.dtype)# Inference: Generation of the output text and audiotext_ids, audio = model.generate(**inputs, use_audio_in_video=True)text = processor.batch_decode(text_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)print(text)sf.write("output.wav",audio.reshape(-1).detach().cpu().numpy(),samplerate=24000,)

(三)本地部署推理(vLLM)
安装qwen-omni-utils和vllm相关依赖
pip install git+https://github.com/huggingface/transformers@1d04f0d44251be5e236484f8c8a00e1c7aa69022pip install acceleratepip install qwen-omni-utilsgit clone -b qwen2_omni_public_v1 https://github.com/fyabc/vllm.gitcd vllmpip install .
以下是一个使用vLLM 的代码示例:
import osimport torchfrom transformers import Qwen2_5OmniProcessorfrom vllm import LLM, SamplingParamsfrom qwen_omni_utils import process_mm_info# vLLM engine v1 not supported yetos.environ['VLLM_USE_V1'] = '0'MODEL_PATH = "Qwen/Qwen2.5-Omni-7B"llm = LLM(model=MODEL_PATH, trust_remote_code=True, gpu_memory_utilization=0.9,tensor_parallel_size=torch.cuda.device_count(),limit_mm_per_prompt={'image': 1, 'video': 1, 'audio': 1},seed=1234,)sampling_params = SamplingParams(temperature=1e-6,max_tokens=512,)processor = Qwen2_5OmniProcessor.from_pretrained(MODEL_PATH)messages = [{"role": "system","content": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech.",},{"role": "user","content": [{"type": "video", "video": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-Omni/draw.mp4"},],},]text = processor.apply_chat_template(messages,tokenize=False,add_generation_prompt=True,)audios, images, videos = process_mm_info(messages, use_audio_in_video=True)inputs = {'prompt': text[0],'multi_modal_data': {},"mm_processor_kwargs": {"use_audio_in_video": True,},}if images is not None:inputs['multi_modal_data']['image'] = imagesif videos is not None:inputs['multi_modal_data']['video'] = videosif audios is not None:inputs['multi_modal_data']['audio'] = audiosoutputs = llm.generate(inputs, sampling_params=sampling_params)print(outputs[0].outputs[0].text)
git clone https://github.com/QwenLM/Qwen2.5-Omni.gitpip install -r requirements_web_demo.txt
python web_demo.pypython web_demo.py --flash-attn2七、结语
Qwen2.5-Omni 是阿里巴巴开源的全能多模态大模型,采用创新的 Thinker-Talker 架构,具备强大的多模态处理能力,在多模态和单模态任务中均表现出色。其实时交互和自然语音生成能力使其在智能语音助手、内容创作、教育和智能客服等领域应用前景广阔。随着技术发展和场景拓展,Qwen2.5-Omni 将为人工智能带来更多创新突破。
八、项目地址
GitHub:https://github.com/QwenLM/Qwen2.5-Omni
Hugging Face:https://huggingface.co/Qwen/Qwen2.5-Omni-7B
ModelScope:https://modelscope.cn/models/Qwen/Qwen2.5-Omni-7B
官网地址:https://qwenlm.github.io/blog/qwen2.5-omni
论文地址:https://github.com/QwenLM/Qwen2.5-Omni/blob/main/assets/Qwen2.5_Omni.pdf
(文:小兵的AI视界)