

项目简介
方法
-
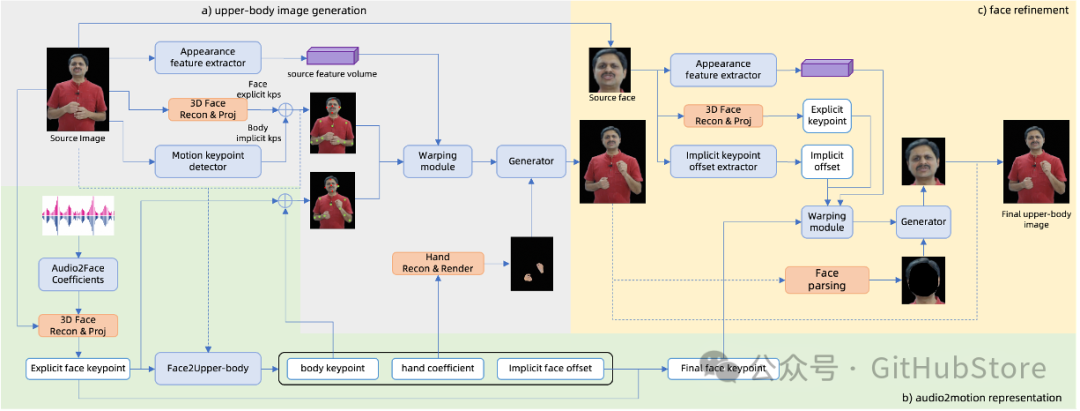
提出了一种高效的分层运动扩散模型,用于音频到运动的表示,基于输入音频分层生成面部和身体控制信号,同时考虑显性和隐性运动信号以实现精确的面部表情。此外,引入了细粒度表情控制,以实现表情强度不同的变化,以及从参考视频中实现的风格化表情迁移,旨在产生可控和个性化的表情。 -
混合控制融合生成模型旨在用于上半身图像生成,该模型利用显式关键点进行直接和可编辑的面部表情生成,同时引入基于显式信号的隐式偏移来捕捉不同头像风格上的面部变化。我们还注入显式手部控制,以实现更准确和逼真的手部纹理和动作。此外,采用面部细化模块来增强面部逼真度,确保高度表达和逼真的肖像视频。 -
构建了一个可扩展的实时生成框架,用于交互式视频聊天应用,该框架可以通过灵活的子模块组合适应各种场景,支持从头部驱动动画到带有手势的上半身生成的各种任务。此外,我们还建立了一个高效的流式推理管道,在 4090 GPU 上以最大 512 × 768 的分辨率实现 30fps,确保实时视频聊天中的流畅和沉浸式体验。
交互式演示
项目链接
https://humanaigc.github.io/chat-anyone/
扫码加入技术交流群,备注「开发语言-城市-昵称」
(文:GitHubStore)