



3月31日,在新一期百度AI DAY活动上,百度文小言宣布品牌焕新与功能升级,除了品牌视觉形象变化外,在产品层面,文小言聚焦模型开放与功能的进一步创新,还有在语音语言交互底层技术方面的变革。
百度AI产品创新业务负责人薛苏表示:“AI的未来不再是单纯的技术参数比拼,而是如何通过多模型协同,真正为用户创造价值,文小言希望通过开放生态,整合顶尖模型能力,做出更强大、更简单的AI产品。”

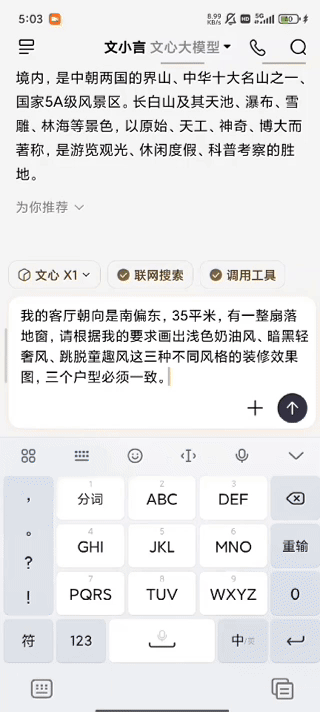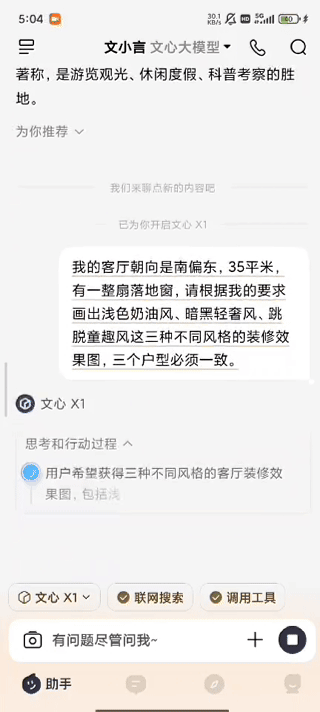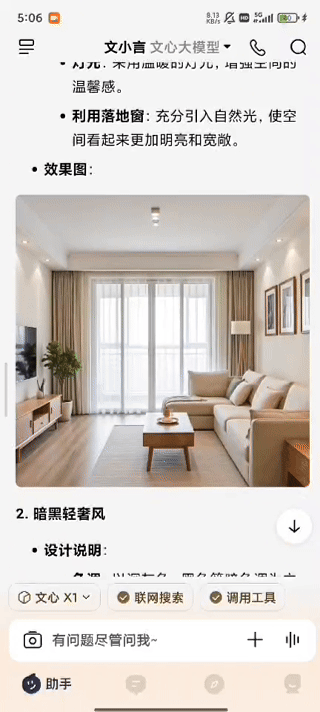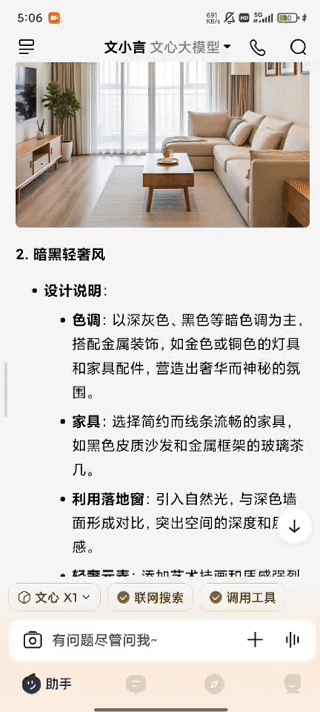


值得关注的是文小言在交互技术层面的一些创新。
据百度语音首席架构师贾磊在现场讲解,百度团队在三个方面对语音交互进行了迭代:1、开发了业界首个基于全新互相关注意力(Cross-Attention)的端到端语音语言大模型;2、识别文本一体化,实现内容理解和快速问答;3、文本合成一体化,实现业内领先的流式逐字的LLM驱动的多情感语音合成。

这种在语音交互技术层面的改进可实现超低时延与超低成本。
在典型的语音问答场景中,语音交互等待时间可压缩至1秒左右,调用成本较行业均值据说可下降约50%-90%,同时流式逐字的LLM驱动的多情感语音合成让交互听感也更加舒适。

one more thing,还有一个趣味性的小功能叫做“图个冷知识”。
用户可把文小言预设成“历史学者”“科技达人”“哲学家”等人设视角,可以为同一张图片赋予不同角度的解读,可以提高用户的发散思维和多视角见解能力。
从行业趋势来看,当下很多AI应用产品都开始PK全链路自主执行能力,迈向真正的实用型生产力工具阶段,通过 “规划-执行-验证” 多代理协同架构,智能体应用可独立完成从目标设定到成果交付的全流程任务,这正在成为新一轮的技术竞争焦点,有望催生出超级爆款应用。
但市场的竞争也相当激烈,用户对AI应用的期待值越来越高,它需要解决实际工作生活中的需求痛点、需要有丝滑流畅的智能体验、还要整合各种实用的强大功能,操作起来还要简单好用。
文小言正在紧跟市场节奏稳扎稳打技术底盘,同时寻找产品爆发突破口,给出来自百度的一份答卷。

(文:头部科技)