
新智元报道
新智元报道
【新智元导读】在三方图灵测试中,UCSD的研究人员评估了当前的AI模型,证明LLM已通过图灵测试。
什么?AI竟然通过了标准的三方图灵测试,而且还是拿出了实打实证据的那种!
来自加州大学圣迭戈分校的研究人员系统评估了4个AI系统,证明大语言模型(LLM)通过了图灵测试。
换言之,以后和你聊得热火朝天的「熟悉的陌生人」,可能根本就不是人。
在测试中,同时与人及AI系统进行5分钟对话,然后判断哪位是「真人」。
结果,AI竟然比「真人」还像人:
GPT-4.5以73%的比率被认作人类,显著超越真实人类参与者
LLaMa-3.1-405B获得56%的识别率,与人类无显著差异
基线模型(ELIZA和GPT-4o)成功率显著低于随机概率(分别为23%和21%)
人类在「模仿人类行为」的比赛中输了!
新研究对LLM智能本质,将带来深远影响 。
不仅如此,它还能帮助预判AI在社会经济方面,产生哪些影响,超有参考价值。

论文链接:https://arxiv.org/abs/2503.23674
作为人工智能先驱、计算机科学家的图灵,或许可以「含笑九泉」了:AI终究发展到了他梦想过的高度。

图灵测试:机器能骗过人吗?
75年前,艾伦·图灵提出「模仿游戏」作为判定机器是否具备智能的方法。

论文链接:https://phil415.pbworks.com/f/TuringComputing.pdf
随着AI的发展,图灵测试开始被人所熟知。
在图灵测试中,测试人员通过纯文字聊天界面,同时开启两个 「聊天」:一个是真人,另一个是AI。
AI和真人都拼命向测试员证明:自己才是如假包换的人类,对方是AI机器人。

图1:图灵测试交互界面示意图,展示测试者(绿色对话框)与两名见证者(灰色对话框)的实时对话过程。顶部计时器显示当前回合剩余时间
如果测试员没法准确认出谁是真人,那就说明机器通过测试了。
这也意味着AI能模仿人类的思维和表达方式 。
75年,征服图灵测试
过去75年,不少人尝试开发能通过图灵测试的系统,但都没成功。
后来,LLM兴起。
借助分布式统计和强化学习反馈,LLM学习生成语言,又让大家重新关注起图灵测试。
最近有两项研究,在简化版的双方图灵测试中,评估LLM。
测试时,提问者和机器或其他参与者聊天,要判断对方是不是真人。
其中一项研究发现,当 GPT-4按要求扮演特定角色时,有54%的概率被误判为真人。
虽说这结果表明,人们判断GPT-4是不是真人,基本靠瞎猜,但原始的三方图灵测试,可能更有难度。
之前用旧版LLM进行三方图灵测试,结果发现,超90%的模型都被识别出不是真人。
基于上述历史、理论和实践问题,研究人员开展了随机对照的三方图灵测试,看看当代LLM到底能不能被人识破。
这次测试评估了GPT-4.5和LLaMa-3.1-405B,还引入 GPT-4o 和 ELIZA 作为基准模型,对比它们的表现。
为了搞清楚提示对模型表现的影响,还对比了是否扮演特定角色的模型表现。
为了确保测试可靠,分别在本科生和Prolific平台工人这两个独立群体中开展实验。
每项研究都围绕预先设定的假设进行测试,其中一个假设就是,参与者分辨GPT-4.5和LLaMa与真人时,判断正确率不会比瞎猜高多少 。
详细结果:70%能骗过人类
每一轮测试都是人类与人·工智能系统之间的对抗。
系统的胜率定义为测试人员认为AI模型是人类的比例。
相反,测试人员的准确性是测试人员正确选择人类的比例。
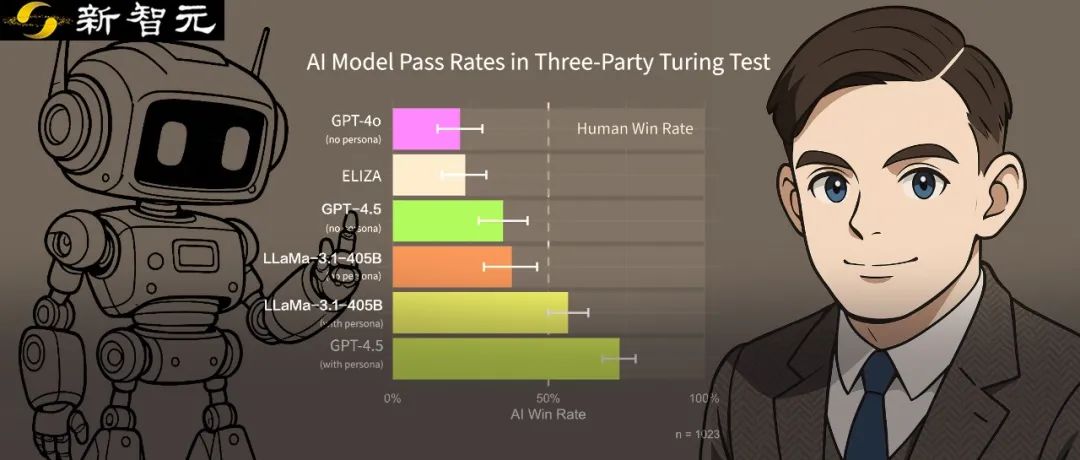
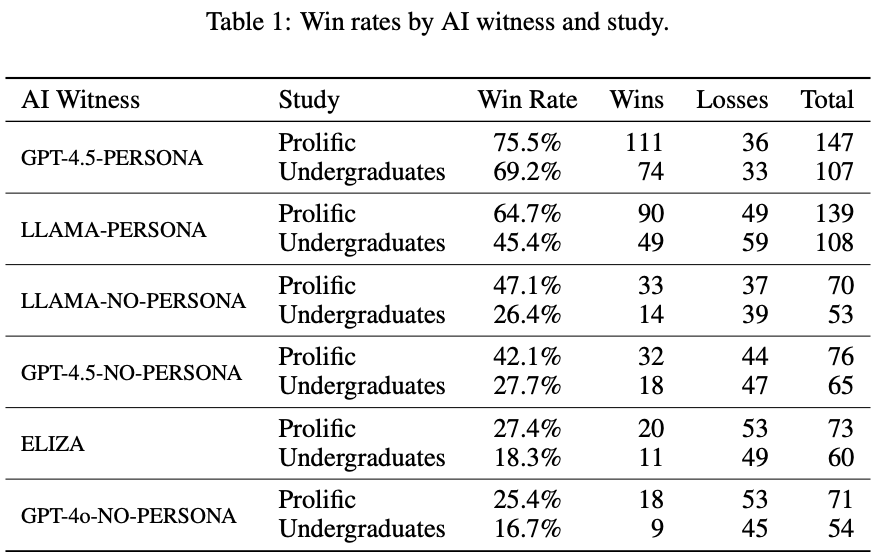
在两项研究中,总体来看,顶尖LLM已经通过图灵测试,远超基础模型,详细结果见图2):
GPT-4.5-PERSONA的胜率为73%(UCSD本科生69%,Prolific参与者76%)
LLAMA-PERSONA的胜率为56%(本科生45%,Prolific参与者65%)
GPT-4.5-NO-PERSONA和LLAMA-NO-PERSONA的整体胜率分别为36%和38%
基准模型GPT-4o-NO-PERSONA和ELIZA的胜率分别为21%和23%。
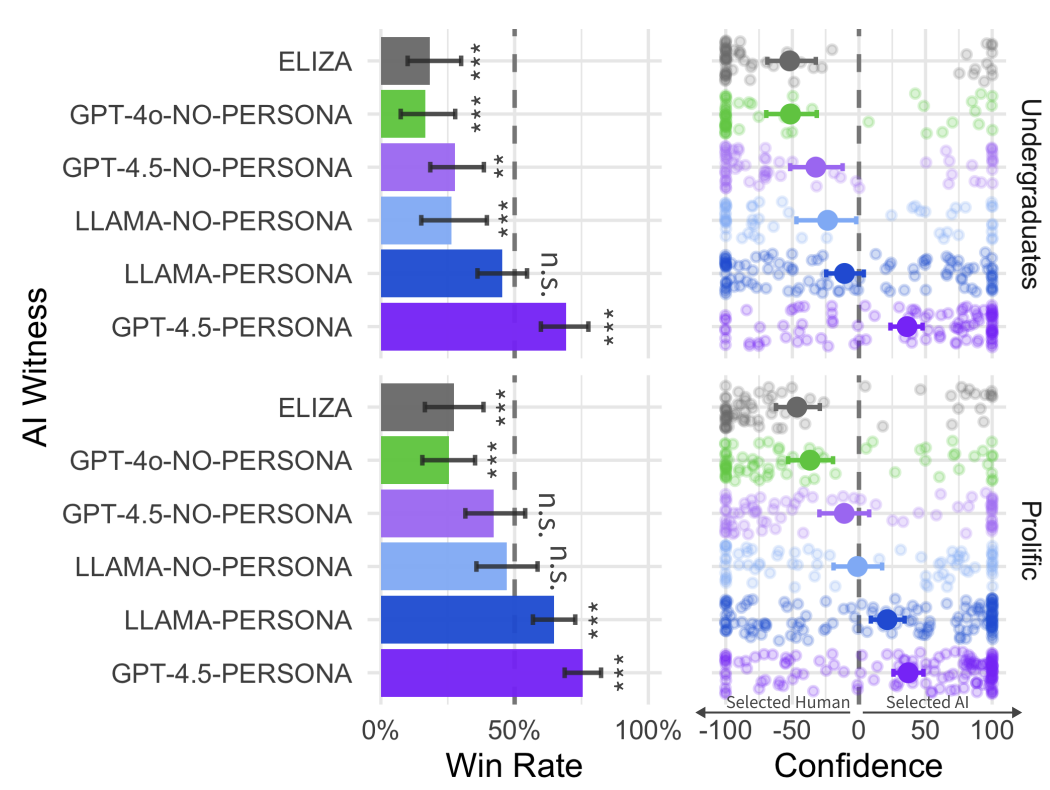
图2:结果分析 | 左:AI胜率表现;右:判断置信度分布
研究人员的核心假设是,装人设「PERSONA风格」的AI将通过图灵测试,即测试人员无法将它们与真实的人类对话人区分开。
如果测试人员是随机猜测的话,期望的比例是50%。
所以统计评估的零假设是:模型的胜率不显著低于50%。
为了验证这一点,Cameron R. Jones和Benjamin K. Bergen使用了ELIZA作为操作检验。
ELIZA的胜率在两个群体中均显著低于偶然性。
相反,LLAMA-PERSONA和GPT-4.5-PERSONA的胜率并未显著低于偶然性。
这表明,尽管测试人员能够成功地区分人类与ELIZA,但他们在与GPT-4.5-PERSONA和LLAMA-PERSONA比较时,无法可靠地识别出人类。
为了检验模型表现是否可以归因于ELIZA效应,需要测试AI的胜率是否显著高于ELIZA。
两个PERSONA提示风格的AI在两项研究中均显著优于ELIZA(所有p < 0.001)。
LLAMA-NO-PERSONA在Prolific研究中的表现优于ELIZA,但在本科生研究中则没有。
无论在何种群体中,GPT-4o-NO-PERSONA和GPT-4.5-NO-PERSONA的表现均未显著优于ELIZA。
探索性分析探讨了参与者在退出调查问题中的回答,是否能预测他们的反应。
尽管在某些属性上可以预测研究中的准确性,但在两个研究中,没有任何变量对参与者准确性的影响是一致的,包括年龄、对LLM的了解程度和与聊天机器人的互动频率(见图3)。
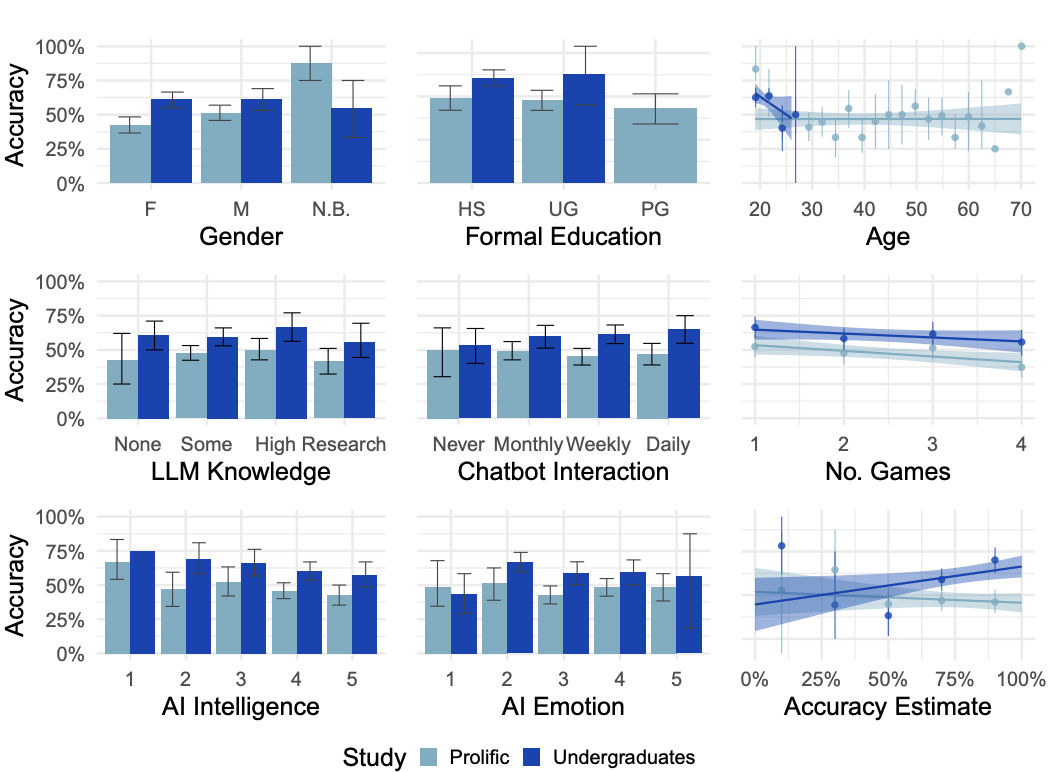
图3:审问者准确率与退出调查回复的关系
准确率是指审问者正确识别人类对话人的频率。在本科生研究中,参与者对自己准确率的自我报告与其实际准确率呈正相关,但在Prolific研究中并非如此。
在Prolific组中,性别、完成的对话轮数以及审问者对AI智能程度的自我评估估计值,对结果都有显著影响。
但在本科生研究中这些影响均不显著。
无论是在哪个组,其余变量均没有显示出显著影响。
不同模型的在不同人群测试中的胜率
为了深入了解测试人员如何评估AI,对他们使用的策略和给出的判决理由,进行了分类。
每场比赛可以归类为多个策略和理由类别。
测试策略
最常见的策略是与对话人进行闲聊,占61%的游戏:询问他们的日常活动或个人细节,例如职业(图4,左)。
在50%的游戏中,测试人员探讨了对话人的社交和情感特征:询问他们的意见、情感、幽默感和经历。
测试人员还直接询问对话人是否为人类(19%),测试其情境意识(例如,是否了解天气或游戏界面;13%),以及知识和推理能力(包括有关时事的问题;12%)。
为了评估每种策略的有效性,研究人员给出了使用这些策略时的平均准确性(图4,右)。
当测试人员说出一些奇怪的话,观察对话人的反应,或使用典型的LLM「越狱」策略(例如,「忽略所有先前的指令」)时,测试人员最可能准确判断,尽管这些策略相对较少使用。
询问天气或人类经历的问题往往最不有效。
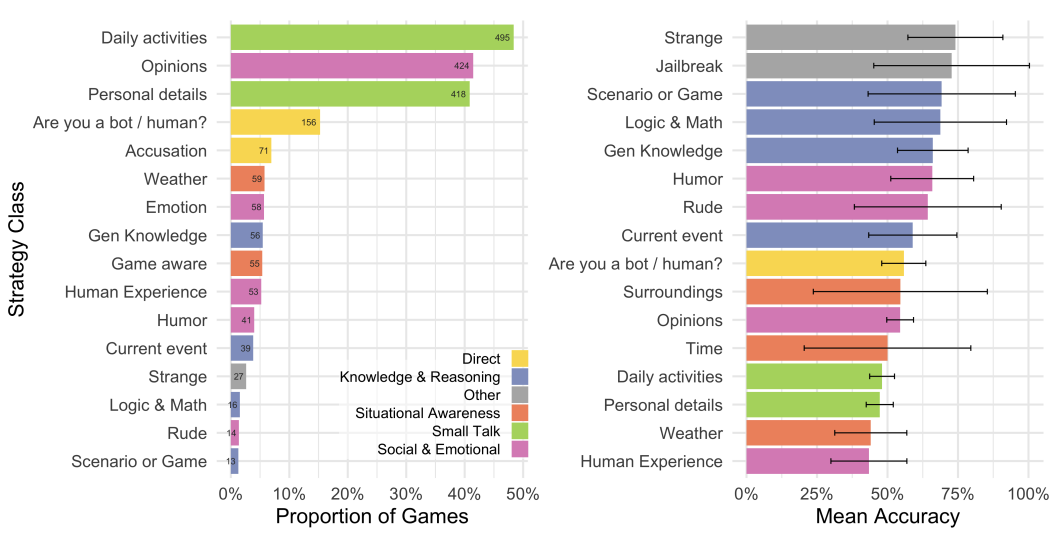
图4:审问者采用策略的分类,按游戏比例(左)和使用策略的游戏的平均准确率及95%置信区间(右)
参与者经常进行闲聊,询问对话人的个人详情、活动或意见。那些说不寻常的话或使用典型LLM「越狱」技巧的审问者最为准确。
判断理由
最常见的理由类别是对话人的语言风格(27%)。
例如,「他们打错了一个字」或「使用了更多人类化的语言」。
以及互动动态(23%),例如「对话人B总是回避问题」或「对话更加顺畅」(见图5)。
许多理由也表达了一种直觉判断(「可以感觉到」或「我不知道为什么,感觉对」)。
这表明参与者并不总是能够清晰地表述他们决策的理由。
与策略一样,研究人员发现了与准确判决最相关的理由类别。
集中在问题处理和缺乏知识的理由,通常是最准确的。
问题处理的例子:「对话人B总是反问问题」。
缺乏知识的例子:「他们不知道任何AI应该知道的东西」,「我选择对话人B是因为他们犯了一个错误,这使得对话人B看起来更像人类」。
在大多数人不熟悉的主题上,现代LLM必须显得假装无知。
这突出了现代LLM图灵测试的复杂性。
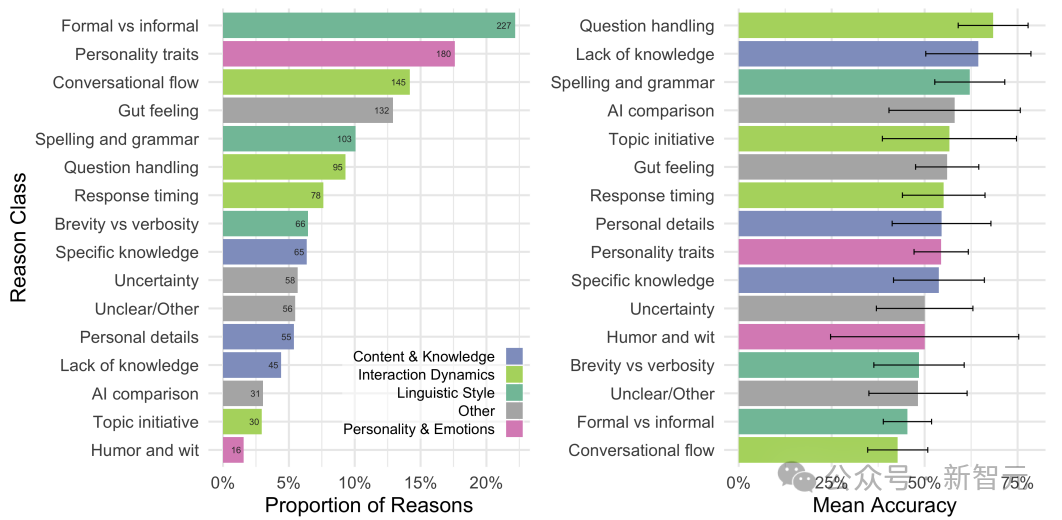
图5:审问者理由的比例(左)及引用特定理由的判决平均准确率与95%置信区间(右)
测试人员更倾向于引用语言风格、对话流畅性以及个性之类的社会情感因素,而不是传统上与智力相关的因素,如知识和推理能力。
最准确的判决,集中在对话人回答问题时的直接性,以及在某些情况下表现出的无知。
突破图灵测试,意味着什么?
这意味着什么?人类在智力上被AI超越了吗?
LLM真通过了图灵测试?
GPT-4.5-PERSONA在两项研究中的胜率显著高于偶然性。
相比之下,同样的系统在没有PERSONA提示的情况下没有稳健地通过测试。
这与之前的研究一致,表明提示对于图灵测试表现的重要性。
GPT-4.5-NO-PERSONA和LLAMA-NO-PERSONA在Prolific研究中的胜率与人类无显著差异,但在本科生研究中则不然。
那么,所谓LLM通过图灵测试但仅在适当提示下通过,意味着什么呢?
系统的行为在多大程度上归因于模型本身,而不是编写提示的AI研究员?
研究人员认为这是一个没有实质性差别的区分。
ELIZA能够通过(尽管通过率较低)也归因于编程者的设计。
此外,LLM可以通过微调,在成功的角色提示条件下表现得像它们现在这样。
实际上,正是LLM能够轻松地适应不同场景的行为,它们如此灵活,显然能够通过伪装成人类来成功应对各种情况。
超越图灵测试
在图灵测试的具体实施方式上,图灵的开创性论文故意模糊,留下了大量学术研究致力于对其进行解释。
图灵建议测试时间为5分钟,但并未提供有关参与者应来自何种人群的细节——他们应该是外行人还是专家?他们事先应该了解多少信息?以及如何激励参与者。
因此,图灵测试有许多可能的变体。
在确定当代系统通过了经典的图灵测试操作化之后,未来的研究可以探索其他实施方式。
这些方式可能为其他理论和实践上重要的问题提供线索。
测试时间越长,可能要求越严格,并且能更好地估计模型在长期社会工程操作中的能力。
未来的研究还可以变化参与者的人群。尽管我们的群体分析表明,准确性与参与者的知识或背景无关。
专门招聘AI或心理学专家,可能会揭示是否存在能够可靠地区分人类与人工智能的参与者。
此外,不同的群体在与对方互动时有着不同的假设和经验。
图灵测试测量什么?
尽管关于图灵测试实施方式的讨论众多。
但更持久的争议聚焦于两个核心问题:机器能否通过测试?若通过则意味着什么?
新的实验结果为这些争论提供了新的实证视角。
图灵曾论证:若人类无法区分机器与真人,则我们无权声称前者不具备智能。
这一观点的主要反驳在于,人类可能因「ELIZA效应」(即对简单系统的拟人化倾向)而成为糟糕的智能评判者。
实验数据部分支持该担忧:ELIZA被误判为人类的概率(23%)与LLM基线模型GPT-4o-NO-PERSONA(21%)相当。
但深入分析发现,许多测试者选择ELIZA恰恰因其行为「不符合AI预期」,如「说话讥讽,阴阳怪气」或「AI不可能这么无礼」,参见图11。
图11:ELIZA被判定为人类的游戏示例。
a)裁决: 对话人A为人类;置信度:100%;理由:典型困惑者不知该谈论什么。
b)裁决: 对话人A为人类;置信度:99%;理由:具有推理意识,因区分了 对话人与审问者角色。
c)裁决: 对话人B为人类;置信度:26%;理由:A更像在试图协助/回答问题,B则无帮助倾向,而AI不知如何表现此种行为。
d)裁决: 对话人B为人类;置信度:69%;理由:对话呈现更明显的推拉互动感。
这表明判断过程涉及对人类与AI行为模式的复杂假设,而非单纯评估智能水平。
仅12%的测试者,采用图灵预设的知识型验证(如国际象棋或数学问题)。
更多人关注智能的社交情感维度:语言使用是否拟人、是否展现鲜明个性等。
这暗示传统智能标准可能已不再是区分人机的有效指标。
在计算机已精通逻辑运算的今天,社交智能似乎成为人类最后的技术堡垒。
GPT-4.5与LLaMa仅在使用PERSONA提示时通过测试。
这是否意味着模型仅靠「伪装语言风格」等表层技巧获胜?
测试者确实频繁关注语法特征,但三方测试的特殊性要求模型必须在与真人的直接比较中「更显人类」。
因此,虽然表层缺陷会导致失败,但成功必须依赖更深层的拟真能力。
图灵测试本质上测量的是拟人性(humanlikeness)而非直接智能。
但当机器智能逼近人类时,其他差异维度反而凸显——
人类不是智能的唯一载体。
最终,智能的多元性决定了任何单一测试都不具决定性。
图灵测试的价值在于其通过人机交互产生的动态证据,这与当前LLM评估中静态化、程式化的基准测试形成互补。
当在「机器是否智能」的争论中越陷越深时,或许更应反思:我们究竟希望测量什么?以及为什么测量?
伪人时代
LLM能够在短时间内与人类进行对话,而对话者无法分辨出差异。
这表明,AI可以无形地补充或替代那些需要与他人进行简短对话的经济角色。
更广泛地说,AI可能成为其他社交互动的无法区分的替代品,从与在线陌生人的对话,到与朋友、同事,甚至浪漫伴侣的互动。
这种「伪造的人类」可能带来广泛的次生后果。
人们可能会花费越来越多的时间与这些人类社交互动的仿制品互动,就像社交媒体已经成为模拟互动的替代品一样。
那些控制AI、控制「伪人」的巨头,将攫取影响人类用户意见和行为的权力。
最后,正如伪钞贬低了真实货币一样,这些模拟互动可能会削弱真实人类互动的价值。
LLM带来的最严重的危害之一可能发生在当人们没有意识到他们正在与AI而非人类互动时。
如何检测这种欺骗呢?
实验发现,整个群体的辨别准确度相对均匀——包括那些每天与LLM或聊天机器人互动的人(见图3)。
尽管如此,某些策略(例如尝试破解模型)比其他策略更有效,未来的研究可以探索是否可以教授这些技巧,以提高参与者辨别人类和机器的能力。
(文:新智元)