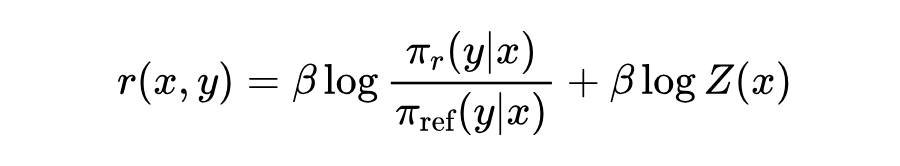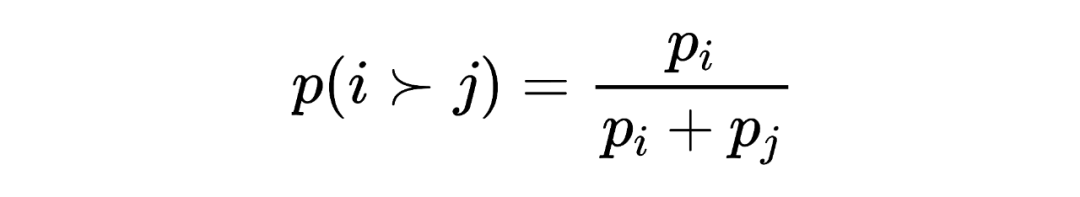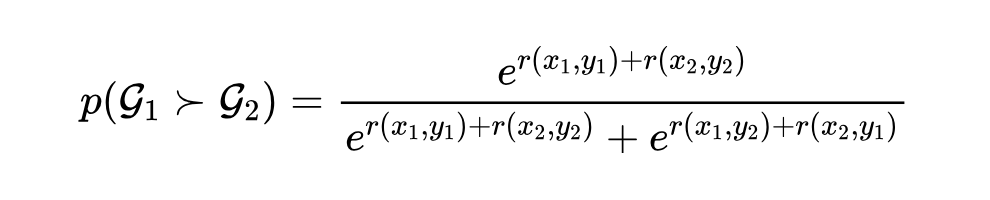论文标题:
IOPO: Empowering LLMs with Complex Instruction Following via Input-Output Preference Optimization
张兴华,余海洋,阜成,黄非,李永彬
https://arxiv.org/abs/2411.06208
https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/IOPO

背景
在大语言模型时代,随着越来越多的需求基于大模型进行 Agent 和业务应用的构建,这些需求在真实场景中往往比较复杂,导致指令的复杂性也在迅速增加,对大模型的领域知识和指令遵循能力提出了更高的要求。然而,目前仅有少量的复杂指令评测集,并缺少针对性提升模型复杂指令遵随能力的方法。
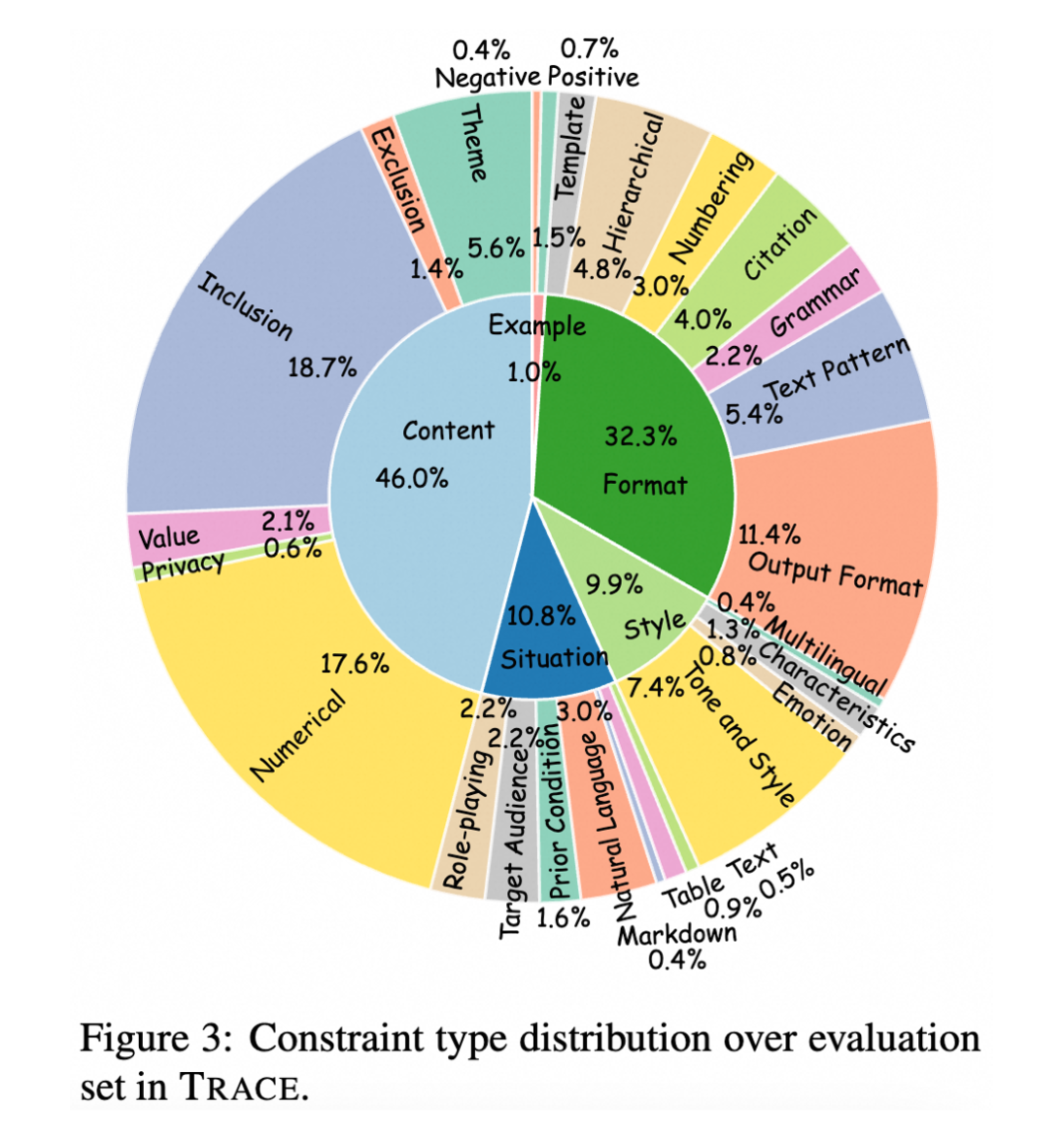
为了解决上述问题,本研究构建了复杂指令 benchmark TRACE,用于改善和评估模型的复杂指令遵循能力,其包含 12 万条训练数据和1千条评测数据。
进一步,本文提出了 IOPO(Input-Output Preference Optimization),使 LLM 在学习 Response(Output)偏好的同时细致探索指令(Input)偏好。具体来说,IOPO 不仅将指令作为输入来直接学习 Response 偏好,且基于相同的 Response 深入探索指令差异,以促进对细粒度约束的有效感知。
实验结果证明,本文在 TRACE 训练集上进行 IOPO 偏好对齐训练,相比 DPO,在 TRACE 域内评测数据和域外通用复杂指令评测数据上均取得了显著提升。

TRACE基准
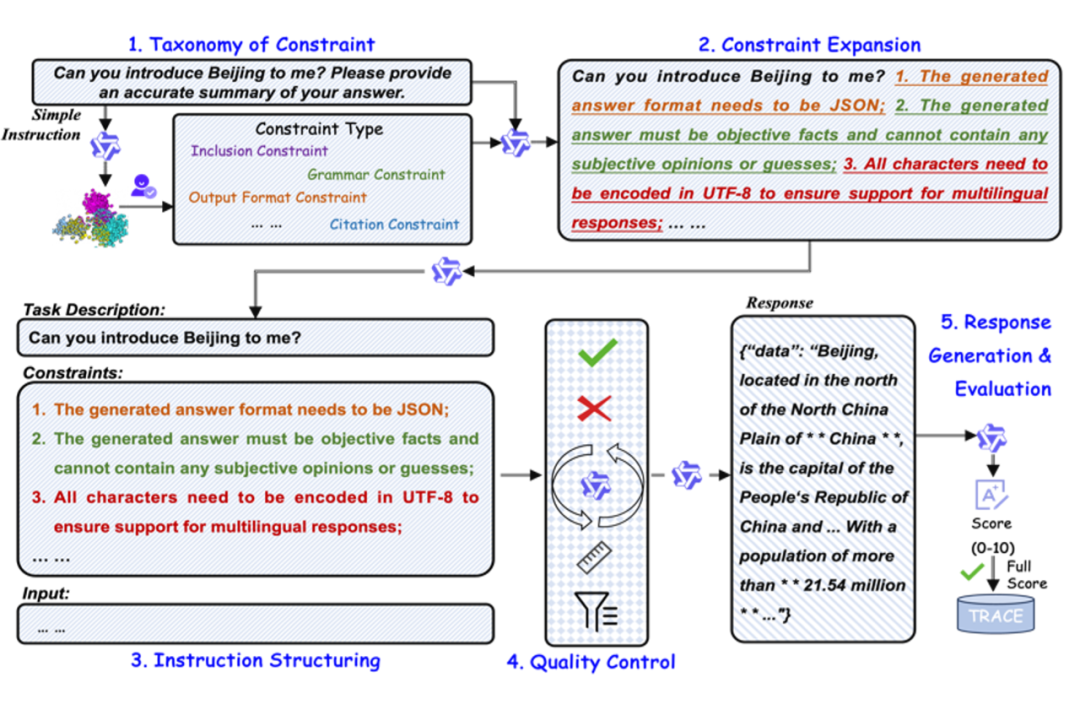
SFT 数据构建
1)约束类型体系构建:从大量开源的简单指令中基于 LLM 归纳指令类型,再经过人工专家归纳总结出 5 大类 26 小类约束类型体系。
2)约束扩展:基于约束类型,提示 LLM 将简单指令扩展为包含多个约束的复杂指令。
3)指令结构化:从扁平的复杂约束指令文本数据中,抽取出任务描述、任务约束、任务输入,实现复杂约束指令输入的结构化表示。
4)指令控制:提示 LLM 对扩展后指令进行冗余、不完整等质量控制,确保扩展后复杂指令的合理性。
5)Response 生成与评估:基于校验后的指令,提示 LLM 生成对应的 Response;利用 LLM 评估 Response 对指令中多种约束的遵循能力,并选取遵循指令中所有约束的 Response,形成 SFT 指令数据。
IOPO 偏好数据构建
1)针对扩展的指令 ,基于 LLM 等通过增删改操作修改 中的约束得到 ,使 不再满足 中的约束。
2)提示 LLM 产生满足 约束但不满足 约束的 Response 。
3)通过 LLM 评估 的质量,确保其相比 ,更好地遵循 中的约束。
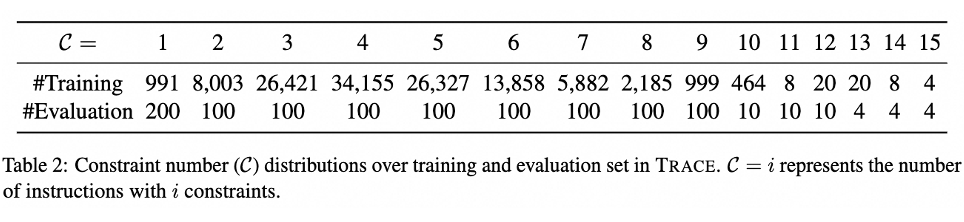
2.2 数据统计
TRACE 总共包含 119,345 条指令数据用于模型训练,1,042 条指令数据用于评测。其中,每条指令中的约束数量范围为 1~15,训练和评测集的平均约束数量分别为 4.36 和 4.89。

IOPO偏好对齐算法
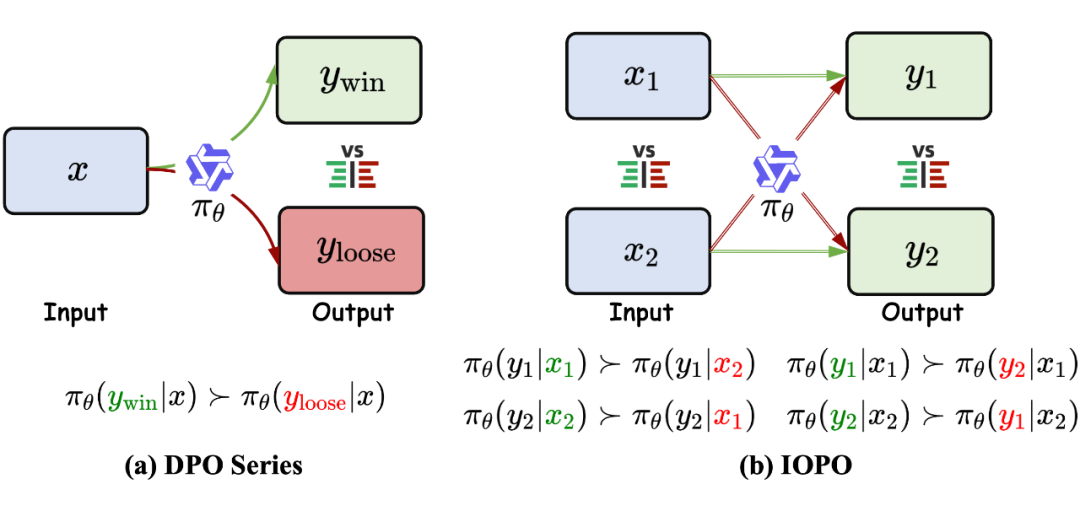
RLHF 以及衍生出来的如 DPO 等一系列对齐算法,都是基于输入 去探索输出 ,在细粒度复杂约束指令场景中难以高效感知 中的细粒度约束,因此如果在基于 去探索 的同时,也能够基于 去探索更优的 ,去感知 中的细粒度约束,将能够提升细粒度复杂约束指令场景中的对齐效果。
IOPO 构造在指令约束方面具有细微差异的输入(, ),对应的输出为(, ),得到四个相应的偏好对(, )、(, )、(, )和(, ),然后可以形成偏好组对 ( = {<, >, <, >}, = {<, >, <, >}),IOPO 的优化目标如下:

如 DPO 中推导,reward 函数 可以用策略模型 进行表示
其中,。
Bradley–Terry Model 是 item、group 或 object 之间成对比较结果的概率模型,给定一对目标 和 ,其公式如下:
其中, 为赋予 的正值分数, 表示相比 更偏好 。
因此,针对 和 对,定义 的赋予分数 , 为 ,得到针对偏好组对 和 的 BT 公式:
最后可以对参数化的策略模型 形式化最大似然损失如下:
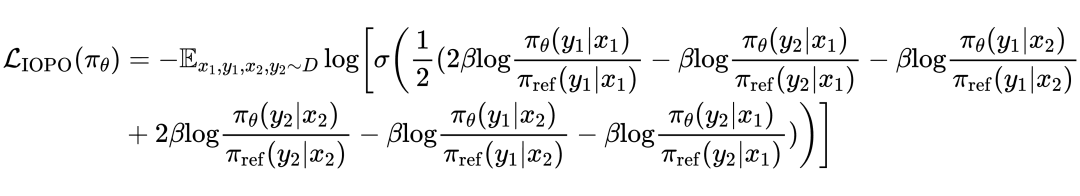

本文在域内数据 TRACE 以及公开的复杂指令数据 IFEval 和 CFBench 域外评测数据上进行实验,以 Qwen2-7B-Instruct 和 Llama3.1-8B-Instruct 为基座模型,在 TRACE 训练集上分别进行SFT、DPO、IOPO 等实验。
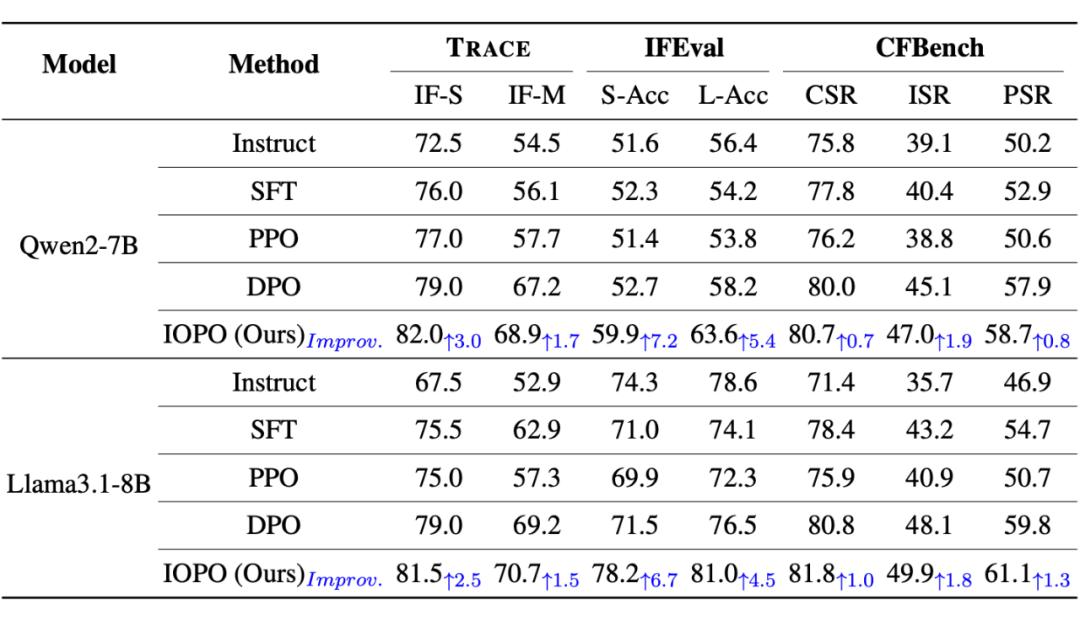
▲ 表1: 域内和域外复杂指令评测集上的实验结果
仅在 TRACE 训练集上调优得到的 IOPO 模型,直接在域内评测集 TRACE 和域外的IFEval、CFBench 上进行评测,IOPO 相比 SFT、DPO 在域内和域外均具有显著优势,证明了 IOPO 良好的泛化能力以及建模输入偏好的必要性。
IOPO 相比 DPO 会消耗更多的 token,为探究这一因素的影响,本文将 IOPO 训练数据适配到 SFT 和 DPO 进行训练,确保其具有相同数量的训练 token,分别记为 SFT 和 DPO。
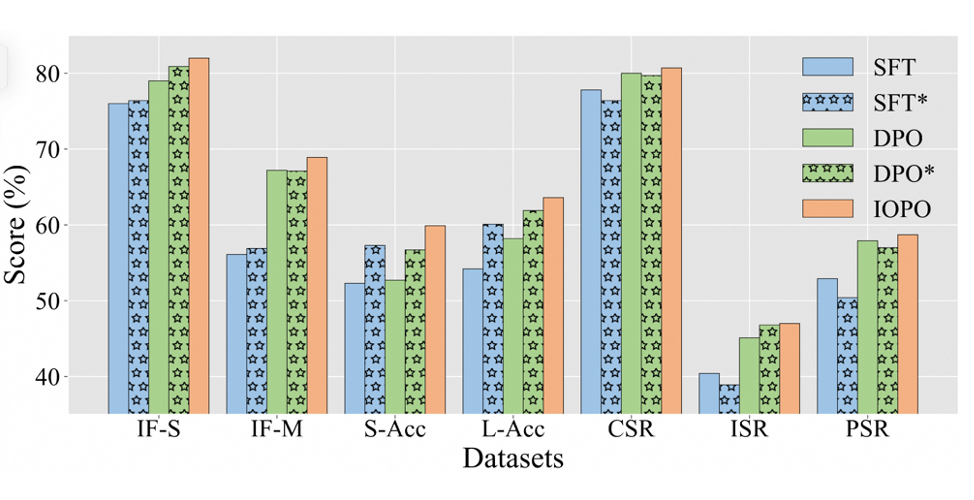
▲ 图1: Qwen2-7B上相同token量下的性能比较
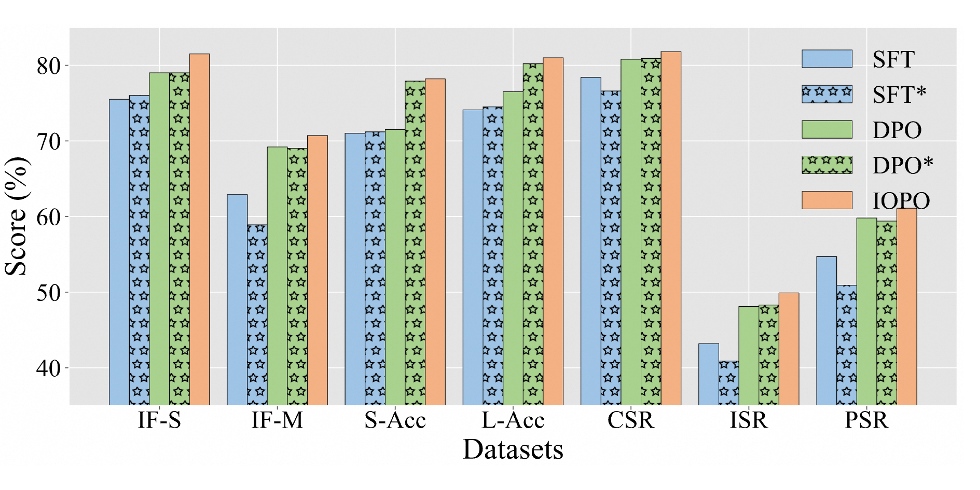
▲ 图2: Llama3.1-8B上相同token量下的性能比较
从上图可以看出,SFT 和 DPO 的性能相比 SFT 和 DPO 有升有降,并且 IOPO 仍然具有明显的优势,证明了 IOPO 性能的提升不是主要来自于消耗更多的训练 token,而是受益于更优异的输入输出偏好的约束感知建模能力。

结语
大语言模型的迅速发展,促使其在软件设计、agent 构造等方面获得广泛应用,但随之而来的是指令复杂度的迅猛增长,持续提升模型的复杂指令遵循能力对大模型的落地应用具有重要的研究价值。
IOPO 通过考虑指令输入和 Response 输出中的偏好,在直接学习 Response 偏好的同时更细微的感知指令中的细粒度约束,显著提升了 LLM 遵循复杂指令的能力。
(文:PaperWeekly)