


极市导读
仅使用 ImageNet 数据集,超过 SD-XL 的 T2I 模型。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
太长不看版
仅使用 ImageNet 数据集,超过 SD-XL 的 T2I 模型。
很多文生图模型在十亿级别的数据集上进行训练取得了显著的成果。一个信奉的原则是 “bigger is better”,优先考虑数据量而不是质量。本文证明了小的,精心策划的数据集,可以匹配或者优于大量网上抓的数据训练的模型。
本文仅仅使用 ImageNet 数据集,通过精心的文本和图像增强,得到的效果是如图 1 所示:在 GenEval 上比 SD-XL 高 2 个点,在 DPGBench 上比 SD-XL 高 5 个点,同时仅仅使用了 1/10 的参数和 1/1000 的训练图像。
本文的结论表明:通过战略性的数据增强 (而非海量数据集) 可以为 T2I 提供可持续的路径。

专栏目录
https://zhuanlan.zhihu.com/p/687092760
本文目录
1 纯 ImageNet 做文生图:我们能走多远?
(来自 LIX, ́Ecole Polytechnique, CNRS, IP Paris, France)
1 论文解读
1.1 研究背景
1.2 使 ImageNet 的文本像素多样化
1.3 Text-space 的增强
1.4 Pixel-space 的增强
1.5 实验设置
1.6 实验结果
1 纯 ImageNet 做文生图:我们能走多远?
论文名称:How far can we go with ImageNet for Text-to-Image generation?
论文地址:
http://arxiv.org/pdf/2502.21318
Project Page:
http://lucasdegeorge.github.io/projects/t2i_imagenet/
1.1 研究背景
Text-to-image (T2I) 生成的主流观点认为,更大的训练数据集会带来更好的性能。这种 “bigger is better” 的范式推动了该领域做到了十亿规模的图-文配对数据集,如 LAION-5B、DataComp12.8B 或 ALIGN-6.6B。主流观点认为数据应该多到捕获完整的文本-图像分布。
但是本文挑战了这个观点,即:认为数据量忽略了模型训练中数据效率和质量的问题。
当前的 data curation pipeline 存在 3 大重要缺陷:
-
当前的 data curation 范式仍然包括收集和策划大量网络抓取数据集,非常费算力。 -
当前的 data curation 过程未能消除社会偏见、不适当的内容、版权材料和隐私问题,最终直接体现在经过训练的模型中。 -
对于 specialized applications 的情况,做针对性的图文对非常耗时。
越来越多的 T2I 模型,比如 PixArt-α,Stable Diffusion (SD) 等等,使用了十亿规模的数据集进行训练。社区的反应不是解决核心数据质量问题,而是:收集更多数据。这种蛮力方法放大了计算成本、curation 的复杂性和数据集 bias。
本文提出了一个根本的转变:使用更小、精心策划的数据集训练 T2I 模型。
1.2 使 ImageNet 的文本像素多样化
本文使用 ImageNet,一个著名的数据集,其 bias 和 limitation 已经被彻底研究。ImageNet 本身只有简单的 label,且以 object 为中心,从未用于 T2I 扩散模型。
本文通过 2 个维度丰富 ImageNet 数据:
-
Text-space 的增强: 使用 LLaVA,将ImageNet的类标签转换为语义丰富的场景描述。 -
Pixel-space 的增强: 使用 CutMix,对图像进行了一些混合,引入了新的概念组合,创建了一些原始数据集中不存在的新概念组合。
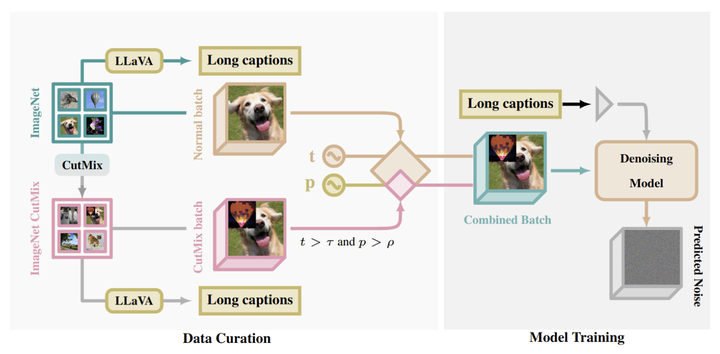
图 2 说明了本文方法的 Pipeline。
1.3 Text-space 的增强
ImageNet 是一个 class-conditional 数据集,最初用于分类和目标检测任务。为了克服 ImageNet 有限的 class-conditional,本文实现了一个 2 阶段的 Pipeline:
AIO caption:“An image of
缺点:1) 缺乏详细的描述。2) 缺乏 “person” 这个类别。
LLaVA caption: 采用 LLaVA 生成综合字幕,可以捕获到:1) 场景组成和空间关系;2) 背景元素和环境上下文; 3) 次要对象和参与者;4) 视觉属性 (颜色、大小、纹理);5) 元素之间的交互和交互。
这种增强弥补了 ImageNet 注释的差距,特别是对于类标签缺乏 person 的图像,以及多元素交互的图像。图 3 是 LLaVA 生成的更丰富的字幕示例。

1.4 Pixel-space 的增强
对于图像增强,引入了一个结构化的 CutMix 框架,该框架系统地结合了概念,同时保留了对象中心性。本文定义了 4 种增强模式,每一种模式都旨在保持视觉连贯性,同时引入新的概念组合,如下:
(Half-Mix)
-
规模:2 幅图像都保持其原始分辨率。 -
位置:沿高度或宽度的确定性拆分。 -
覆盖范围:每个概念占最终图像的 50%。 -
保存:这 2 个概念都保持全分辨率。
(Quarter-Mix)
-
规模:CutMix 图像大小调整为 50% 边长。 -
位置:四个角之一的固定放置。 -
覆盖率:第二个概念占最终图像的 25%。 -
保存:基本图像中心区域保持不变。
(Ninth-Mix)
-
规模:CutMix 图像大小调整为 33.3% 的边长。 -
位置:沿图像边界的固定放置。 -
覆盖率:第二个概念占最终图像的 11.1%。 -
保存:基本图像中心,角保持不变。
(Sixteenth-Mix)
-
规模:CutMix 图像大小调整为 25% 边长。 -
位置:随机放置不是中央 10% 区域。 -
覆盖率:第二个概念占最终图像的 6.25%。 -
保存:基本图像中心区域保持不变。
每个增强策略生成 1,281,167 个样本,匹配 ImageNet 的训练集大小。图 3 显示了不同结构化增强的示例。
还定义了,从所有 4 种模式统一采样。每个模式的比例相等 (25%),以保持相同的总样本数。图像增强后,将 LLaVA 字幕应用于所有生成的图像,确保视觉和文本表示之间的语义对齐。这就可以得到详细的描述,可以在保持自然语言流畅性的同时准确反映增强的内容。
然后,使用增强之后的图片进行训练,算法如图 3 所示。
注意,这里作者的设置是:
当扩散过程的 timesteps ( 是一个超参数)时,以一定的概率 从 里采样,否则就从 中采样。

1.5 实验设置
数据集:ImageNet,图片 rescale 到 256 × 256 分辨率。
VAE:使用 SD 的。
Text Encoder:T5。
Sampling:250 steps 的 DDIM。
评价指标:
-
FID:50k in-distribution ImageNet 验证集,30k out-of-distribution MSCOCO captions 验证集。 -
Precision and Recall, Density and Coverage:评估保真度和多样性,使用 Dinov2 backbone。 -
CLIPScore (CS):评估生成图片与 text prompts 的对齐能力。 -
GenEval 和 DPGBench。除了使用 GenEval 提供的默认短文本 prompts 外,作者还使用了 Llama-3.1 扩展这些 prompts,以近似训练期间使用的长提示的分布。
1.6 实验结果
作者在 GenEval 和 DPGBench 基准测试中测试了 DiT-I 和 CAD-I 模型的组成能力,并将性能与流行的最先进模型进行了比较,如图 4 和 5 所示。
图 4 报告了 GenEval 的结果,模型以 256×256 分辨率进行评估。⋄ 表示原始 GenEval prompts。⋆ 表示 extended GenEval prompts。与 SD3 相比,本文模型在分辨率为 256×256 时平均比 SD3 (0.56) 表现更好 (CAD-I 0.57,DiT-I 0.57),当使用扩展提示 ⋆ 进行评估时。本文模型也优于 SD1.5 (0.43),SD2.1 (0.50),SDXL (0.55) 和 PixArt-α (0.48),尽管这些模型以更高的分辨率进行评估。该基准测试中的分辨率至关重要。即使没有扩展提示 ⋄,本文的 CAD-I 模型在全分辨率下也能成功达到 SDXL 的性能,同时参数少 10 倍,只在 0.1% 数据上训练。
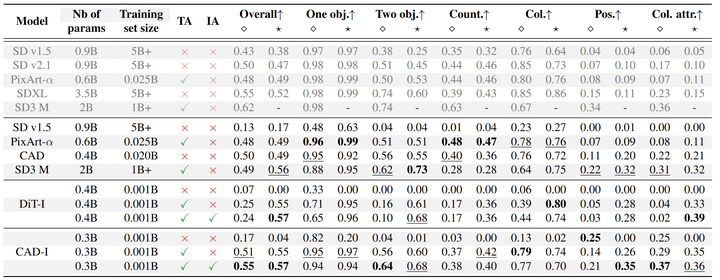
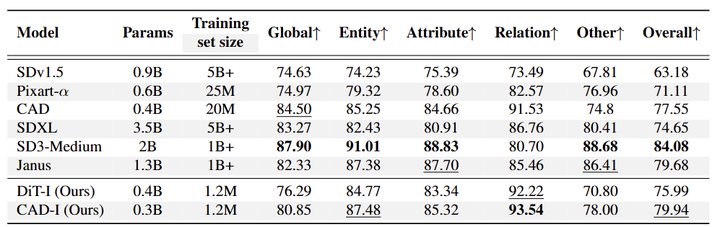
图 5 报告了 DPGBench 上的结果,这个基准类似于 Geneval,但提示更复杂。作者观察到与 GenEval 类似的趋势:使用 DiT-I 实现了 76% 的整体准确率,比 SDXL 提高了 1.3%。CAD-I 的总体得分为 79.94%,比 SDXL 高出 +5%,PixArt-α 高出 +8%。令人印象深刻的是,本文模型达到了与 Janus 相当的准确度,这是一个具有生成能力的 1.3B 参数 VLM。值得注意的是,本文模型都特别擅长关系,CAD-I 为 93.5%,DiT-I 为 92.2%。
作者也分析了本文的增强对图像质量的影响。使用 DiTI 和 CAD-I 并在 ImageNet 上训练,带有短标题 “An image of …”,或从 LLaVA 获得的长字幕。图 6 报告了在 ImageNet 和 COCO 验证集上测试时的结果。本文的增强能够达到很低的 FID (DiT-I 为 8.52,CAD-I 为 6.62),并且具有更好的 precision, recall, density, 以及 coverage 分数。
对于 COCO,这一趋势都更加显着,这是一个 Zero-Shot 任务。本文的增强模型是唯一能够正确遵循提示的模型 (CLIP score 增加:DiT-I 从 13.16 到 24.85; CAD-I 从 12.89 到 26.60),同时保持相似的图像质量 (略高的 FID,但使用 Dinov2 backbone 的 FID 要低得多)。

不同模型之间的比较如图 7 所示。使用 “An image of …” 的 prompt 格式,基线模型 (AIO) 在 prompt 含有 ImageNet 类之外的概念时难以生成连贯的图像。通过文本增强 (TA),该模型展示了改进的概念理解和组合能力,尽管图像质量仍然有限。结合文本和图像增强(TA + IA)可以提高图像质量和更好的即时理解。这种改进在 pirate ship 场景中尤为明显:虽然 TA 模型生成了一艘船尴尬地放在一碗汤中,但 TA + IA 模型创造了更自然的 pirate ship 在碗中航行的样子。同样,hedgehog and hourglass 示例中,TA + IA 组合显示出更精细的细节,更加美观,而 TA 模型很难渲染可识别的 hedgehog。


(文:极市干货)