


3 月的最后一天,由蚂蚁与清华大学交叉信息研究院吴翼老师团队联合推出的开源强化学习框架 AReaL 发布了里程碑版本——AReaL boba,正如其昵称“boba”(珍珠奶茶)所寓意的那样,AReaL 团队希望他们的工作能像美味且平易近人的奶茶一样,普惠整个 AI 开发社区,让每一位开发者都能轻松驾驭强大的推理模型。
就像 AReaL 介绍里说的那番,他们将完全致力于开源,发布所有重现所需性能模型的训练细节、数据和基础设施。AReaL boba 不仅把模型、代码、数据及实现细节通通开放出来,而且还提供非常详细的教程,真正实现了“人人可手搓顶尖大模型”的愿景。

集成 SGLang 框架,效率大幅提升!
AReaL boba 是首个全面拥抱 xAI 公司高性能推理框架 SGLang 的开源训练系统。通过引入 SGLang 并进行一系列工程优化,AReaL v0.2 在 7B 模型上的训练速度相较于 v0.1 提升了 1.5 倍,端到端训练性能提升高达 73%。如下图所示:
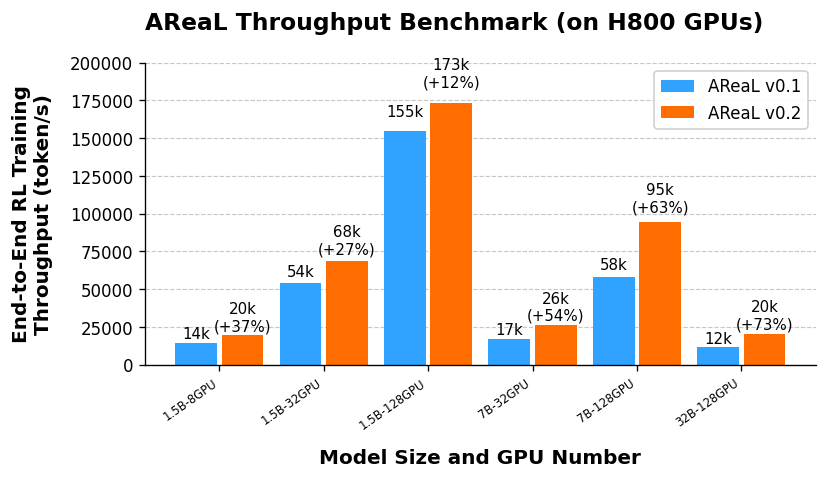
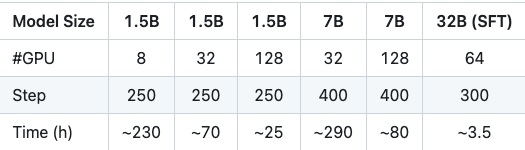
官网提供的表格进一步展示了 AReaL-boba 在不同资源配置下的训练时间:
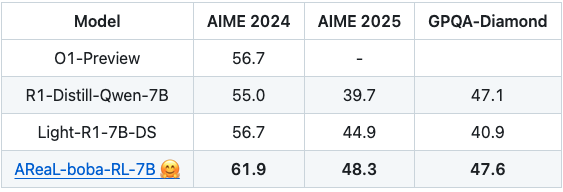
AReaL 团队通过大规模强化学习训练,使得 AReaL-boba-RL-7B 在数学推理能力上达到了同尺寸模型的 SOTA 水平。其在 AIME 2024 上取得了 61.9 分,在 AIME 2025 上取得了 48.3 分,不仅显著超越了基础模型,更是在多个基准测试中领先于同类开源模型。为了方便社区复现,团队还开源了相应的训练数据 AReaL-boba-106k。

-
GitHub 项目地址:https://github.com/inclusionAI/AReaL
-
HuggingFace 数据模型地址:https://huggingface.co/collections/inclusionAI/areal-boba-67e9f3fa5aeb74b76dcf5f0a


(文:AI科技大本营)