

极市导读
本文提出的 SmoothQuant 是一种无需训练的,高精度的,通用的,后训练量化 (Post-Training Quantization,PTQ) 解决方案,以实现 LLM 的 8-bit weight、8-bit activation (W8A8) 量化。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
太长不看版
提出了大语言模型后训练量化的通用技术 “平滑操作 (Smoothing)”。
本文最开始发布于 2022 年 11 月,ChatGPT 诞生的那个月,也说明本文作者有强烈的前瞻性和深远的洞察力。当时,大语言模型计算密集和显存密集。而量化技术可以减少显存并加速推理。但是,当时的方法不能同时保持精度和硬件效率。
本文提出的 SmoothQuant 是一种无需训练的,高精度的,通用的,后训练量化 (Post-Training Quantization, PTQ) 解决方案,以实现 LLM 的 8-bit weight、8-bit activation (W8A8) 量化。
SmoothQuant 基于的一个事实是 weight 相比于 activation 更容易去量化,因此通过离线将量化的难度从 activation 通过数学上的等价变换转移到 weight 上来。
SmoothQuant 实现了 LLM 中所有矩阵乘法 weight 和 activation 的 INT8 量化,包括 OPT、BLOOM、GLM、MT-NLG、Llama-1/2、Falcon、Mistral 和 Mixstral 模型。实现了 1.56 倍加速,2 倍显存节约,且精度损失可以忽略不计。SmoothQuant 能够在单个节点内服务 530B LLM,为 LLM 量化提供了一站式的解决方案,可以减少硬件成本,并民主化 LLM。
下面是对本文的详细介绍。
本文目录
1 SmoothQuant: 大语言模型后训练量化的通用技术
(来自 MIT 韩松团队,NVIDIA)
1 SmoothQuant 论文解读
1.1 SmoothQuant 研究背景
1.2 量化
1.3 量化难点回顾
1.4 SmoothQuant 方法
1.5 实验设置
1.6 精度实验结果
1.7 实际加速与显存节约
1 SmoothQuant: 大语言模型后训练量化的先驱
论文名称:SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models (ICML 2023)
论文地址:
http://arxiv.org/pdf/2211.10438
代码链接:
http://github.com/mit-han-lab/smoothquant
1.1 SmoothQuant 研究背景
大语言模型 (LLM) 在各种任务中表现出出色的性能。然而,由于其巨大的模型尺寸,为 LLM 提供服务需要消耗大量预算和能源。例如,GPT-3 模型包含 175B 参数,在FP16中运行将消耗至少 350GB 的显存,需要 8×48GB A6000 GPU 或 5×80GB A100 GPU 进行推理。由于计算和通信开销巨大,推理延迟也可能对实际应用是不可接受的。
量化是降低 LMM 成本的一种有前途的方法。通过将 weight 和 activation 量化为低位整数,可以减少 GPU 显存需求、带宽,加快计算密集型操作 (即线性层中的 GEMM [General matrix multiply],注意力中的 BMM [Batch matrix multiply])。与 FP16 相比,weight 和 activation 的 INT8 量化可以将 GPU 内存使用量减半,矩阵乘法的吞吐量几乎是两倍。
然而,与 CNN 模型或更小的 Transformer 模型 (如 BERT) 不同,LLM 的 activation 很难量化。当将 LLM 扩展到 6.7B 参数之外时,激活会出现幅度较大的系统异常值[1],导致较大的量化误差和精度下降。ZeroQuant[2]应用Dynamic per-token activation 量化和分组 weight 量化。但是这个方法不能保持具有 175B 参数的大型 OPT 模型的精度。LLM.int8()[3]进一步引入混合精度分解,在 FP16 中保留异常值并使用 INT8 进行其他激活来解决精度问题。但是很难在硬件加速器上有效分解。因此,为 LLM 设计一种高效,硬件友好,又无需训练的量化方案,使所有计算密集操作使用 INT8 仍然是个开放的挑战。
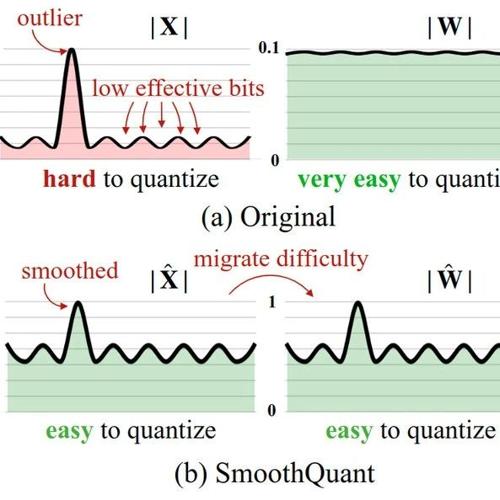
SmoothQuant 是一种准确和高效的 LLM 训练后量化 (PTQ) 解决方案。SmoothQuant 依赖于一个关键的观察结果:即使由于异常值的存在[3],activation 比 weight 更难量化,不同的 token 在其 channel 中表现出相似的变化。基于这一观察,SmoothQuant 离线将量化难度从激活迁移到权重,如图1所示。SmoothQuant 提出了一种数学上等效的 per-channel 缩放变换,可以显着 smoothing 不同 channel 之间幅值的大小,使模型量化友好。
由于 SmoothQuant 与各种量化方案兼容,作者为 SmoothQuant 实现了3个效率的量化设置级别。实验表明, SmoothQuant 硬件高效:可以保持 OPT-175B、BLOOM-176B、GLM-130B 和 MT-NLG 530B 的性能,实现在 PyTorch 上高达 1.51× 的加速和 1.96× 的显存节约。
SmoothQuant 很容易实现。作者将 SmoothQuant 集成到 FasterTransformer 中,这是最先进的 Transformer 服务框架,与 FP16 相比,实现了高达 1.56× 的加速和显存使用量减半。值得注意的是,像 OPT-175B 这样的大型模型,与 FP16 相比,SmoothQuant 允许只使用一半的 GPU,同时更快,并且能够在一个 8-GPU 节点内为 530B 模型提供服务。
1.2 量化
量化将高精度值映射到离散级别。本文整数均匀量化 (尤其是 INT8),以实现更好的硬件支持和效率。量化过程可以表示为:

其中 是浮点张量, 是量化结果, 是量化步长, 是舍入函数, 是 bit 数 (本文中为 8)。为简单起见, 作者假设张量在 0 处是对称的; 对于非对称情况 (比如在 ReLU 之后) 的讨论是相似的 (通过添加 Zero point)。
这种量化器使用最大绝对值来计算 ,使其保持激活中的异常值,这对精度很重要。可以用一些校准样本的激活离线计算 ,称之为静态量化 (Static Quantization)。还可以使用激活的运行时统计信息来获得 Δ,称之为**动态量化 (Dynamic Quantization)**。
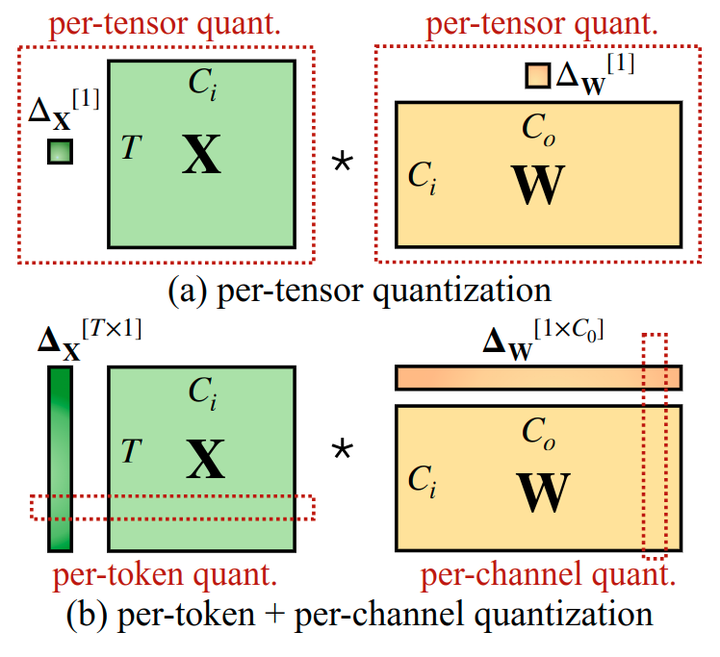
如图 2 所示,量化具有不同的粒度级别。per-tensor 量化对整个矩阵使用单个步长。可以通过对与每个 token (per-token 量化) 或 weight 的每个输出通道 (per-channel 量化) 相关联的 activation 使用不同的量化步长来进一步实现更细粒度的量化。per-channel 量化的一个粗粒度版本是为不同的通道组使用不同的量化步骤,称为 group-wise quantization[4]。
对于 Transformer 中的一个线性层 ,其中 是令牌的数量, 是输入通道, 是输出通道, 可以通过将权重量化为 , 将存储减少一半。
为了加快推理速度,需要将 weight 和 activation 量化为 INT8 (即 W8A8),以利用整数核 (如 INT8 GEMM),其由广泛的硬件 (例如 NVIDIA GPU、Intel CPU、高通 DSP 等) 支持。
1.3 量化难点回顾
众所周知,由于激活中的异常值[3][5],LLM 难以量化。这一节首先回顾了激活量化的困难,并寻找异常值之间的模式。图 4中可视化了具有大量化误差的线性层的输入激活和权重。可以找到几种模式:
1) activation 比 weight 更难量化。
权重分布相当均匀,平坦,易于量化。以前的工作表明,用 INT8 甚至 INT4 量化 LLM 的权重不会降低精度[2][3],这与本文的观察结果相呼应。
2) 异常值使得 activation 量化很困难。
activation 中的异常值规模比大多数激活值大约 100 倍。在 per-tensor 量化 (式1) 的情况下, 大的离群值主导了最大幅度, 导致非离群点 channel 的有效量化 bits/levels 较低: 假设 channel 的最大幅值为 , 整个矩阵的最大值为 , channel 的有效量化级别为 。对于非离群点 channel, 有效的量化级别将非常小 (2-3), 导致量化误差较大。
3) 异常值在固定 channel 中存在。
在一小部分 channel 中存在异常值。如果一个 channel 有一个异常值,它持续出现在所有 token 中 (图4中的红色部分)。给定 token 的 channel 之间的差异很大 (某些 channel 的 activation 非常大,但大多数很小),但给定 channel 在 token 之间的大小之间的差异很小 (异常值 channel 始终很大)。
由于异常值的持久性和每个 channel 内部的小方差,如果可以做 activation 的 per-channel 量化 (对每个 channel 使用不同的量化 step),与 per-tensor 量化相比,量化误差会小得多,而 per-token 量化帮助不大。
在图 3 中,作者模拟 per-channel activation 量化,成功地将准确度与 FP16 baseline 对标,这与[6]的研究结果一致。

然而,per-channel activation 量化不能很好地映射到硬件加速的 GEMM kernel。在这些内核中,缩放只能沿着矩阵乘法的外部维度执行 (即 token 维度、权重的输出通道维度),可以在矩阵乘法完成后应用:
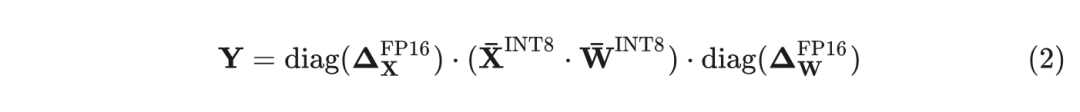
因此,之前的工作都对线性层使用 per-token activation 量化[3][2],尽管它们无法解决 activation 量化的难度 (仅略好于 per-tensor 量化)。
1.4 SmoothQuant 方法
SmoothQuant 将输入 activation 除以 per-channel 的平滑因子 来 “Smooth” 输入 activation。为了保持线性层的数学等价性,作者以相反的方向相应地缩放权重:
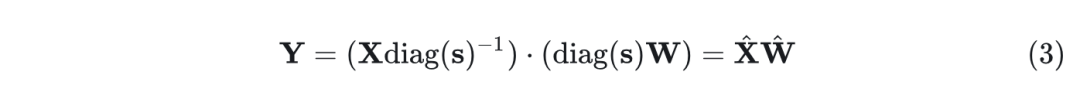
考虑到输入通常由先前的线性操作 (例如线性层、Layer Normalization 等) 产生,因此可以很容易地离线将平滑因子融合到前一层的参数中,这不会从额外的缩放中产生 Kernel 调用开销。
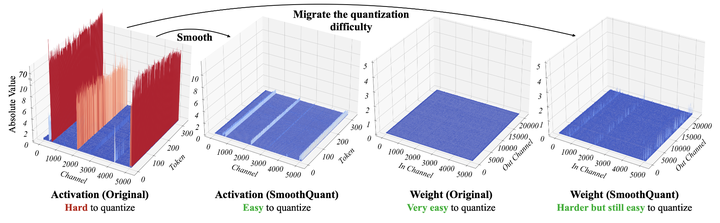
将量化难度从 activation 转移到 weight
本文的目标是为每个 channel 选择一个平滑因子 , 使得 易于量化。为了减少量化误差, 应该增加所有通道的有效量化位。当所有 channel 都具有相同的最大幅值时, 总有效量化位将是最大的。因此, 一个直接的选择应该是 ,其中 代表第 个输入 channel, 。这种选择确保在划分之后, 所有 activation channel 都将具有相同的最大值, 很容易量化。注意, activation 的范围是动态的; 对于不同的输入样本, 它是不同的。这里作者使用来自预训练数据集的校准样本来估计 activation channel 的规模[7] 。
然而, 这个公式将所有量化困难推向权重。作者发现在这种情况下, 权重 (现在将异常值通道迁移到权重) 的量化误差会很大, 从而导致较大的精度下降。另一方面, 还可以通过选择 将所有量化难度从 weight 推到 activation。同样, 由于 activation 量化误差, 模型性能很差。因此, 需要拆分 weight 和 activation 之间的量化难度, 以便它们都易于量化。
在这里,作者引入了一个超参数迁移强度 (migration stength) , 用于控制想要从 activation 迁移到 weight 的难度, 使用以下等式:
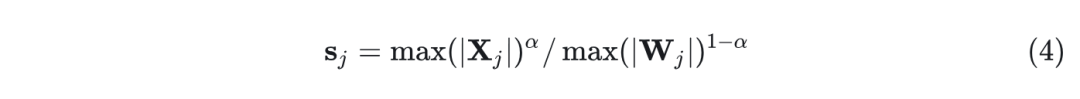
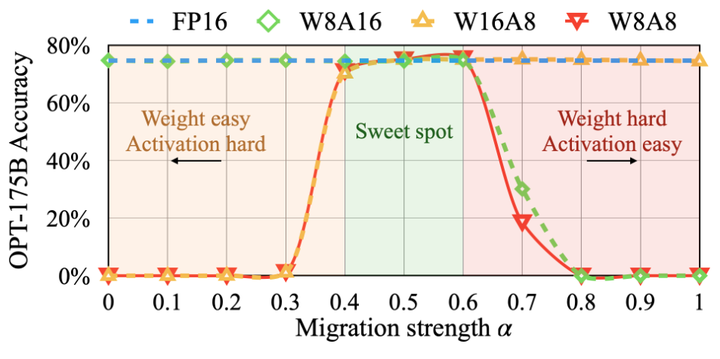
作者发现,对于大多数模型,例如所有 OPT 和 BLOOM 模型, 是一个良好的平衡点,可以均匀地分割量化难度,特别是当使用相同的量化器进行 weight 和 activation 时 (比如 per-tensor, static quantization)。该公式确保相应通道的 weight 和 activation 具有相似的最大值,因此共享相同的量化难度。图 6 说明了当取 时的平滑变换。对于其他一些激活异常值更显着的模型 (比如 GLM-130B 具有 ∼30% 的异常值,这对于激活量化来说更加困难),就可以选择更大的 将更多的量化难度迁移到权重 (比如 0.75)。

将 SmoothQuant 应用于 Transformer
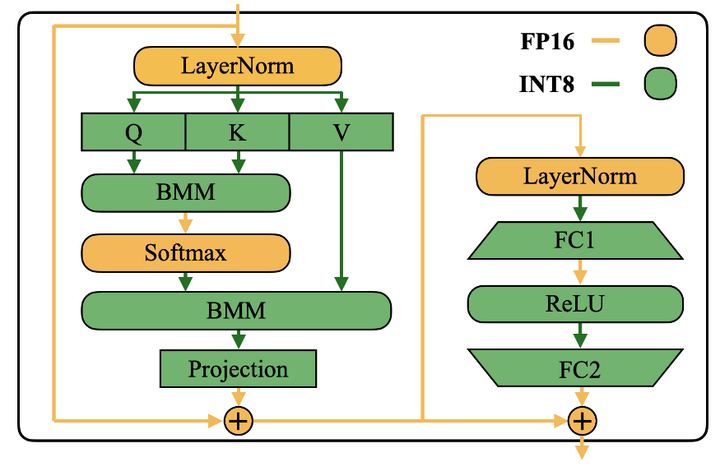
线性层占用 LLM 模型的大部分参数和计算。默认情况下,作者对 Self-attention 和 FFN 的输入 activation 执行 smoothing 并用 W8A8 量化所有线性层。作者还在注意力计算中量化了 BMM 算子。如下图7所示,作者为 Transformer Block 设计了一个量化流。用 INT8 量化注意层中线性层和 BMM 等计算量大算子的输入和输出权值,同时保持激活为 FP16,用于 ReLU、Softmax 和 LayerNorm 等其他轻量级元素操作。这样设计有助于平衡准确性和推理效率。
1.5 实验设置
Baselines
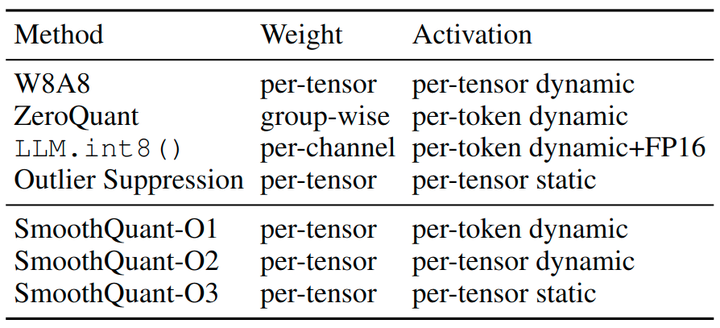
与4个基线进行比较,INT8 PTQ 的设置,无需重新训练模型参数:W8A8 朴素量化,ZeroQuant[2],LLM.int8()[3] 和 Outlier Suppression[5]。由于 SmoothQuant 与量化方案正交,作者从 O1 到 O3 提供了逐渐激进和有效的量化级别。基线和 SmoothQuant 的详细量化方案如图8所示。
模型和数据集
作者选择3个 LLM 家族来评估 SmoothQuant:OPT[8]、BLOOM[9]和 GLM-130B[10]。
作者使用7个零样本评估任务:LAMBADA、HellaSwag、PIQA、Winogrande、OpenBookQA、RTE、COPA 和一种语言建模数据集 WikiText 来评估 OPT 和 BLOOM 模型。作者使用 MLU、MNLI、QNLI 和 LAMBADA 来评估 GLM-130B 模型,因为上述一些基准出现在 GLM130B 的训练集中。
作者使用 lm-eval-harness[11]来评估 OPT 和 BLOOM 模型,并使用 GLM-130B[12]的官方 repo 进行评估自己。最后,作者将本文方法扩展到 MT-NLG 530B[13],并首次支持在单个节点内服务 >500B 模型。请注意,作者专注于量化前后的相对性能变化,而不是绝对值。
Activation Smoothing
迁移强度 是所有 OPT 和 BLOOM 模型的一般最佳点, GLM-130B 的 , 因为它的激活更难量化。通过在 Pile 验证集的子集上运行快速 grid search 来获得合适的 。为了获得 activation 的统计数据,作者使用来自预训练数据集 Pile 的 512 个随机句子校准 smoothing 因子和 static quatization 步长, 并为所有下游任务应用相同的平滑和量化模型。通过这种方式, 对量化的 LLM 的通用性和 Zero-Shot 性能进行基准测试。
实现方案
作者用2个后端实现 SmoothQuant:
-
用于概念验证的 PyTorch Huggingface[14]。 -
FasterTransformer[15],作为生产环境中使用的高性能框架的一个例子。
在 PyTorch Huggingface 和 FasterTransformer 框架中,使用 CUTLASS INT8 GEMM kernel 实现了 INT8 线性模块和批处理矩阵乘法 (BMM) 函数。作者简单地将原始浮点 (FP16) 线性模块和 bmm 函数替换为本文的 INT8 kernel 作为 INT8 模型。
1.6 精度实验结果
OPT-175B 结果
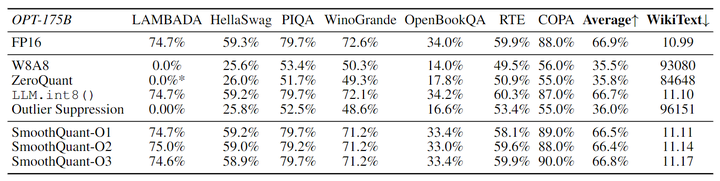
SmoothQuant 可以处理很大的 LLM (其 activation 更难量化) 的量化。本文研究了 OPT-175B 的量化。如图9所示,SmoothQuant 可以与所有量化方案在所有评估数据集上匹配 FP16 准确度。LLM.int8() 可以匹配浮点精度,因为它们使用浮点值来表示异常值,这会导致较大的延迟开销。W8A8、ZeroQuant 和 Outlier Suppression 基线产生几乎随机的结果,这表明直接量化 LLM 的 activation 会破坏性能。
不同 LLMs 结果
SmoothQuant 可以应用于各种 LLM 中。在表 4 中,作者展示了 SmoothQuant 可以量化所有现有的超过 100B 参数的 LLM。与 OPT-175B 模型相比,BLOOM 176B 模型更容易量化:没有一个基线完全破坏模型,即使是朴素的 W8A8 per-tensor 动态量化只会将准确率降低 4%。SmoothQuant 的 O1 和 O2 级别成功地保持了浮点精度,而 O3 级别 (per-tensor, static) 将平均精度降低了 0.8%,作者将其归因于 static quantization 收集的统计数据与真实评估样本激活统计之间的差异。相反,GLM-130B 模型更难量化。尽管如此,SmoothQuant-O1 可以匹配 FP16 精度,而 SmoothQuant-O3 仅会降低 1% 的精度,明显优于 Baseline。作者遵循 Outlier Suppression[5]的做法在校准静态量化时 clip 了前 2% 的 token。注意,不同的模型/训练设计有不同的量化困难,这将激发未来的研究。
不同大小 LLM 的结果
SmoothQuant 不仅适用于 100B 参数以外的非常大的 LLM,而且适用于较小的模型。在图 10 中,作者展示了 SmoothQuant 可以适合 OPT 模型的所有尺度,将 FP16 精度与 INT8 量化相匹配。

指令调优 LLM 结果
SmoothQuant 也适用于指令调优 LLM,结果如图11所示。作者使用 WikiText-2 和 LAMBADA 数据集在 OPT-IML-30B 模型上测试 SmoothQuant。结果表明,SmoothQuant 通过 W8A8 量化成功地保留了模型的精度,而 Baseline 模型则无法做到这一点。SmoothQuant 是一种旨在平衡 Transformer 模型量化难度的通用方法。由于指令调优 LLM 的体系结构与普通 LLM 没有根本的不同,并且它们的预训练过程非常相似,SmoothQuant 也适用于指令调优 LLM。

LLaMA 模型结果
通过初步实验,作者发现与 OPT 和 BLOOM 等模型相比,LLaMA 模型通常具有不太严重的激活异常值问题。尽管如此,SmoothQuant 对于 LLaMA 模型仍然很奏效。作者在图12中提供了 LLaMA W8A8 量化的一些初步结果。SmoothQuant 使 W8A8 量化性能的下降可以忽略不计。

Llama-2、Falcon、Mistral 和 Mixral 模型结果
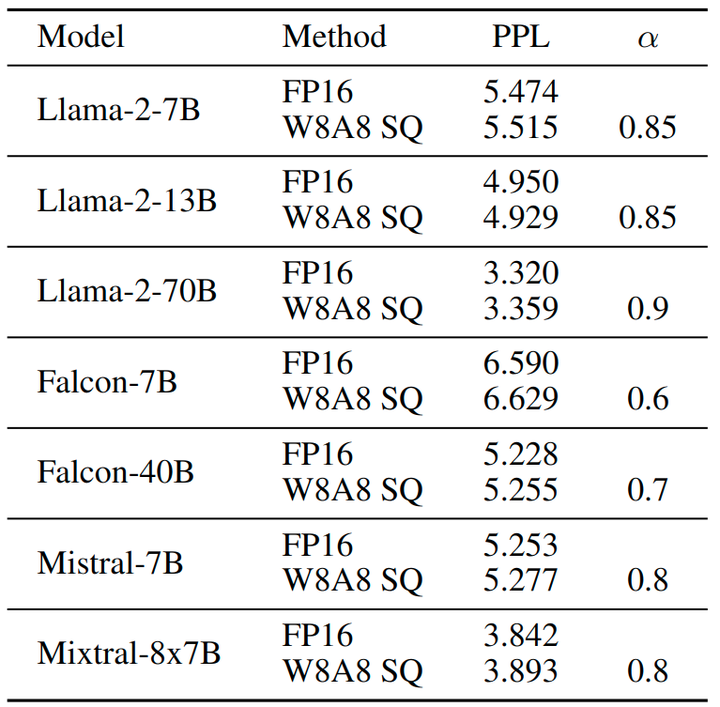
作者使用不同的架构对最近的几个 LLM 应用 SmoothQuant,例如 Llama-2、Falcon、Mistral 和 Mixstral——值得注意的是,Mixstral 模型是专家混合 (MoE) 模型。结果如图13所示,表明 SmoothQuant 使 W8A8 量化成为可能,同时在这些不同的架构中以最小的损失保持性能。
1.7 实际加速与显存节约
作者还展示了集成到 PyTorch 和 FasterTransformer 中的 SmoothQuant-O3 的测量加速和显存节约。
上下文阶段:PyTorch 实现
作者测量一次为 1 个 Batch 里面 4 个句子生成所有隐藏状态的端到端延迟,即上下文阶段的延迟。在此过程中记录峰值 GPU 显存使用量。只将 SmoothQuant 与 LLM.int8() 进行比较,因为它是唯一现有的量化方法,可以在所有尺度上保持 LLM 的精度。由于 Huggingface 缺乏模型并行性的支持,因此对于 PyTorch 实现,作者只测量 SmoothQuant 在单个 GPU 的性能,评估了 OPT-6.7B、OPT-13B 和 OPT-30B。在 FasterTransformer 库中,SmoothQuant 可以与 Tensor Parallelism 算法无缝集成,因此作者测试了 SmoothQuant 在 OPT-13B、OPT-30B、OPT-66B 和 OPT-175B 上的单 GPU 和多 GPU 的性能。所有的实验都是在 NVIDIA A100 80GB GPU 服务器上进行的。
在图 14 中,作者展示了基于 PyTorch 实现的推理延迟和峰值显存使用量。SmoothQuant 始终比 FP16 基线快,当序列长度为 256 时,OPT-30B 的速度提高了 1.51 倍。还可以看到模型越大,加速度越显著。另一方面,LLM.int8() 几乎总是比 FP16 Baseline 慢,这是由于混合精度 activation 表示的开销很大。在内存方面,SmoothQuant 和 LLM.int8() 几乎可以将 FP16 模型的内存使用减半,而 SmoothQuant 节省了稍微更多的内存,因为它使用了完整的 INT8 GEMM。
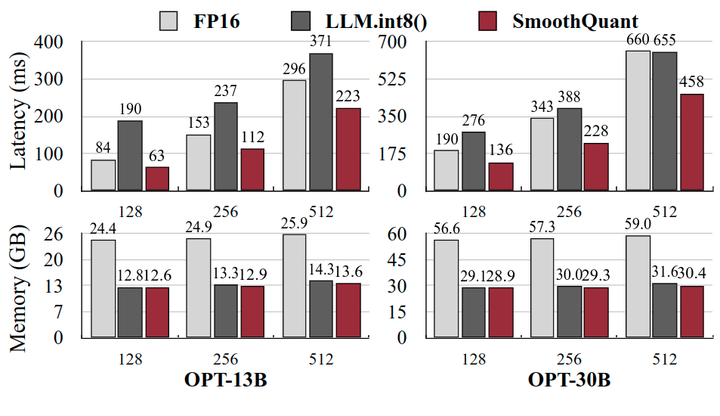
上下文阶段:FasterTransformer 实现
如图15所示,与 FasterTransformer 的 OPT FP16 实现相比,SmoothQuant-O3 在使用单个 GPU 时可以进一步将 OPT-13B 和 OPT-30B 的推理延时减少高达 1.56 倍。这很有挑战性,因为与 OPT-30B 的 PyTorch 实现相比,FasterTransformer 已经快 3 倍。值得注意的是,对于必须分布在多个 GPU 的较大模型,SmoothQuant 仅使用一半数量的 GPU (OPT-66B 使用1个,OPT-175B 使用4个)实现了相似甚至更好的延时。这可以极大地降低服务 LLM 的成本。使用 FasterTransformer 中的 SmoothQuant-O3 时所需的内存量减少了近 2 倍。

Decoding 阶段
图16中,作者展示了 SmoothQuant 可以显着加速 LLM 的自回归解码。与 FP16 相比,SmoothQuant 不断减少每个令牌的解码延迟 (高达 1.42 倍的加速)。此外,SmoothQuant 将 LLM 推理的内存占用减半,能够以显着降低的成本部署 LLM。

单个节点运行 530B 模型
SmoothQuant 支持的模型可以进一步扩展到 500B 量级,从而实现 MT-NLG 530B[13]的高效、准确的 W8A8 量化。如图17和18所示,SmoothQuant 能够以可忽略的精度损失实现 530B 模型的 W8A8 量化。减小的模型尺寸允许我们在类似的延时下使用一半的 GPU (16 到 8) 完成模型的服务,支持在单个节点 (8×A100 80GB GPU) 内启用 >500B 模型的服务。
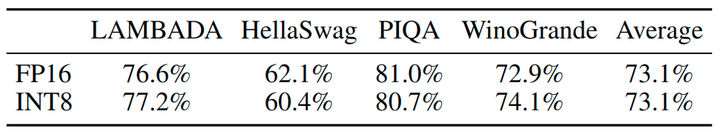

参考
-
^L. Llm.int8(): 8-bit matrix multiplication for transformers at scale -
^abcdZeroquant: Efficient and affordable post-training quantization for large-scale transformers -
^abcdefLlm.int8(): 8-bit matrix multiplication for transformers at scale -
^Q-bert: Hessian based ultra low precision quantization of bert -
^abcOutlier Suppression: Pushing the Limit of Low-bit Transformer Language Models -
^Understanding and overcoming the challenges of efficient transformer quantization -
^Quantization and training of neural networks for efficient integerarithmetic-only inference -
^OPT: Open Pre-trained Transformer Language Models -
^BLOOM: A 176B-Parameter Open-Access Multilingual Language Model -
^GLM-130B: An Open Bilingual Pre-trained Model -
^https://github.com/EleutherAI/lm-evaluation-harness -
^https://github.com/THUDM/GLM-130B -
^abUsing DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model -
^https://github.com/huggingface/transformers -
^https://github.com/NVIDIA/FasterTransformer

(文:极市干货)