

AI 行业大事记
2025 年 3 月
联合出品:
Jomy @ 302.AI
南乔 River @ ShowMeAI
大聪明 @ 赛博禅心
—
说明:
① 本文分类中的【模型】均指代语言模型;
② 部分配图(尤其是 gif 动图)进行了压缩,官方演示视频是非常高清和流畅的。
③ 前往 WaytoAGI 专区查看「赛博月刊」飞书版 → https://waytoagi.feishu.cn/wiki/QeQiwmb61iSAXXkNbyic2yksnKc (期待互动👏👏👏)
11月刊 | 12月刊 | 1月&2月刊
👀 趋势观察
1. 模型
✦ 自 DeepSeek-R1 爆火后,推理模型成为了各家模型公司的战略必备品。有意思的是,他们的模型命名也在有意或无意地模仿 R1,例如 X1(讯飞),T1(腾讯),Z1(智谱),甚至 R1V(昆仑万维)。
✦ 推理模型也从 R1 的纯文字能力,往多模态的方向发展。
✦ 阿里则另辟蹊径,推出了推理小模型 QwQ-32B,为企业本地化部署提供了一个极佳的选择。
✦ 非推理模型发展也并未停滞,DeepSeek-V3-0324 和 Gemini-2.5-Pro 重新树立了国内外模型的能力标杆。
✦ Gemini 和 4o 打碎了模型输出图片的枷锁,可能会引发训练全模态模型的热潮,但这条路可比训练推理模型难走得多。
2. 图像
✦ 自 Gemini 和 GPT-4o 这类“语言模型”可以输出图片后,模型本身具有的推理能力对传统图像生成模型造成了降维打击。全模态模型可以更好地理解提示词,更好地理解图片,直接淘汰了原来很多复杂的工作流。
✦ 但没有任何方案是完美的,Gemini 和 GPT-4o 的短板在于无法精准控制细节。可以预见,未来图像行业的主流方案会是:先使用全模态模型生成图片完成初稿,再使用人工或自动工作流进行细微调整。
✦ 对图片细节要求不高的 C 端客户,将会被全模态模型抢走;B 端客户也会因为全模态模型生图而大大提高创作效率。
✦ 传统的图像模型公司,无法在短期内研发出全模态模型。因为无论是训练数据,还是技术门槛,都存在难以跨越的鸿沟。传统的图像模型市场,将被头部的全模态模型公司吃掉很大一部分。
3. 视频
✦ 视频领域近期没有大的技术突破,大家在慢慢地趋向雷同。以前玩视频模板的公司开始研究视频可控性,而视频可控性做得好的公司也开始推出视频模板。
✦ 视频生成质量在缓慢地提高,但变化不如其他领域明显。
4. 音频
✦ TTS 方向。Sesame 新模型的效果让人眼前一亮,它补齐了语音生成的最后一块短板:语气和情感,彻底跨越了 AI 语音的恐怖谷。期待更多公司可以基于 Sesame 开源的研究成果优化自家的语音模型。
✦ AI 音乐有着巨大的全球市场。Suno 一直垄断着这个市场,如今终于迎来了重磅的挑战者:昆仑万维 Mureka。可转念一想,未来这个领域也会被全模态模型占领吗?
5. 3D
✦ 3D 生成领域稳定发展中,精细度越来越高,效果越来越好。
✦ 3D 生成本质是让模型去想象一个平面图的立体结构,这对于参数不大的 3D 生成模型是有些吃力的。不过,这个月大家发现,使用 4o 这种全模态模型去生成多角度图,再使用多角度图进行 3D 生成,效果会好得多。这个工作流应该会大大推动 AI 3D 生成的商业化应用进程。
6. 机器人
✦ 机器人的大脑(模型)还停留在非常初级的阶段,而机器人的身体控制已经做得比较出色了。但没有大脑的躯干,不过是具「行尸走肉」,无法带来大规模的改变。
7. 应用
✦ Manus 的爆火开启了 AI Agent 的开发热潮,让大众对 Agent 这个概念有了更感性的认识。
✦ Agent 本质上是一种思维方式,可以理解为人把更多决定权交给了 AI。
✦ Agent 生态缺少不了外部工具,因此 MCP 和 Browser Use 等工具的热度大大增加。
✦ 模型厂商(例如豆包和智谱)正在尝试把模型推理和工具调用结合起来,从而实现更强的 Agent 能力(豆包的深度思考和智谱的AutoGLM 沉思)。
8. 新闻
✦ 政府支持和监管同步进行,整体政策形式向好。
✦ 融资热度慢慢从模型相关公司转向 Agent 相关公司。
🧭 时光机
3 月 1 日
| 新闻 | 北京市印发《北京具身智能科技创新与产业培育行动计划(2025-2027年)》 → 全国范围内,政策越来越多
| 新闻 | 小红书启动首届「独立开发大赛」,提供百万奖金池和上亿流量支持
3 月 2 日(无)
3 月 3 日
| 模型 | 科大讯飞 ● 星火医疗大模型 X1 首发 &&「星火X1+DeepSeek」学习机首发
| 图像 | Minimax ● Image-01 图像生成模型上线 → 实测图片真实性很高,可以和海外模型媲美
| 视频 | Minimax ● I2V-01-Director「镜头控制」图生视频模型上线 → 和 Luma 类似,使用提示词来控制镜头
| 应用 | 字节跳动 ● Trae 国内版发布 → 国内版 Cursor
| 应用 | 字节跳动 ● 火山引擎「大模型应用实验室」开源 6 款 AI 应用 → 只有 API 不够了,要喂到开发者嘴边了
| 应用 | 秘塔 ● 视频搜索功能上线 → 原理是对 B 站的视频字幕做了提取和总结,再进行文字的检索
| 机器人 | 灵初智能 ● Psi R0.5 端到端 VLA 模型发布
| 融资 | 智谱 ● 完成多笔战略融资,杭州、珠海、成都等城市参与 → 各地政府纷纷上了智谱的车
| 融资 | Anthropic(Claude) ● 完成 35 亿美元 E 轮融资,公司估值达到 615 亿美元 → 与 OpenAI 的 3400 亿估值差了很多
| 新闻 | MWC25 世界移动通信大会在西班牙巴塞罗那举行
| 新闻 | 深圳市一天之内「四箭齐发」打造创新之城与产业高地 → 深圳政策加码,这一次 AI 浪潮里珠三角的存在感太低了
3 月 4 日
| 模型 | 字节跳动 ● SuperGPQA 知识推理基准测试集(开源) → 更严格的测试集,可以看到各家模型的真实水准
| 图像 | 智谱 ● CogView4 图像生成模型,支持中英文字符生成(开源) → 图片 AI 味挺重,优势是中文渲染
3 月 5 日
| 音频 | SparkAudio ● Spark-TTS 文本转语音模型
| 应用 | 蝴蝶效应 ● Manus 通用 AI Agent 上线并开启邀测 → Manus 的爆火引领了 AI Agent 的开发热潮
| 融资 | 爱诗科技 AIsphere ● 完成 A5 轮融资 && PixVerse 月活突破 1500 万 → 继续在 2C 的路上越做越好
| 新闻 | Richard Sutton 和 Andrew Barto 两位强化学习先驱共同获得图灵奖 → 没有他们就没有今天的推理模型
3 月 6 日
| 模型 | 阿里巴巴 ● QwQ-32B 推理模型发布(开源) → 第一个可轻松本地部署的真推理模型,利好小企业
| 模型 | Mistral AI ● Mistral OCR 模型开放 API → 实测速度真的很快
| 视频 | 腾讯 ● HunyuanVideo-I2V 图生视频模型发布(开源) → 腾讯模型也全方位覆盖了
| 应用 | Google ● AI Mode 搜索新功能开始测试
| 应用 | 硅基智能 ● HeyGem 数字人合成工具(HeyGen 开源替代品)
3 月 7 日
| 模型 | Google ● Gemini Embedding 文本嵌入模型发布并上线
| 应用 | Hedra Labs ● Character-3 多模态 AI 数字人视频生成模型 → 期待尽快开放 API 接入
3 月 8 日(无)
3 月 9 日(无)
3 月 10 日
| 模型 | 字节跳动 ● COMET 通信优化系统(开源) → 自从 DeepSeek 爆火后,MoE 架构也被越来越多模型公司选择
| 机器人 | 智元机器人 ● Genie Operator-1 通用具身基座大模型
| 新闻 | OpenAI 转投 CoreWeave,微软自研大模型,二者关系日益紧张
3 月 11 日
| 模型 | 阿里巴巴 ● R1-Omni 全模态大语言模型(开源)
3 月 12 日
| 模型 | OpenAI ● Responses API 和 Agents SDK 发布 → 此次升级全部都是为了 Agent 生态而准备的
| 模型 | Google ● Gemma 3 多模态系列模型(开源) → 一个很适合本地部署的多模态小模型
| 模型 | Google DeepMind ● Gemini Robotics 和 Gemini Robotics-ER 模型发布
| 图像 | Google ● Gemini 2.0 Flash 原生图像生成功能开放 → 开启了 3 月通过 LLM 生成图片的浪潮,对传统图片生成模型形成了降维打击
| 图像 | 字节跳动 ● Seedream 2.0 文生图模型技术报告发布 → 字节很愿意分享技术细节,对行业是个大好事
3 月 13 日
| 模型 | Cohere ● Command A 极致性能+极低算力的企业级模型(开源) → 111B 的参数量,比传统的 32B 或 70B 门槛还是高了不少,所以热度不高
| 应用 | 阿里巴巴 ● 夸克升级为 AI 旗舰应用,推出「AI 超级框」概念 → 夸克想成为阿里 AI 的超级 App
3 月 14 日
| 音频 | Sesame ● CSM 1B 语音合成模型(开源) → 强烈建议听听 Demo,语气和情感极为真实
| 应用 | Google Gemini 重要更新 ● Personalization 个性化、Gems 智能体、Canvas、Audio Overview
| 新闻 | 四部门联合发布《人工智能生成合成内容标识办法》,自 9 月 1 日起施行 → 国家希望对 AI 生成的内容画出一条明确的界限
3 月 15 日
| 应用 | Anuttacon(蔡浩宇)● 《Whispers From The Star》AI 游戏开启内测
| 新闻 | 315 晚会曝光 AI 外呼机器人在电话营销中的滥用乱象
3 月 16 日
| 模型 | 百度 ● 文心大模型 4.5 原生多模态大模型 && X1 深度思考模型发布
3 月 17 日
| 模型 | Mistral AI ● Mistral Small 3.1(24B)多模态理解模型(开源) → Gemma3 的竞品
| 3 D | Roblox ● Cube 3D 建模工具(开源)
3 月 18 日
| 模型 | 昆仑万维 ● Skywork R1V 多模态思维链推理模型(开源) → 比 R1 多了多模态的能力,非常实用
| 3 D | 腾讯 ● Hunyuan 3D 2.0 模型家族(开源) → 腾讯连 3D 都做,战略覆盖面应该是第一了
| 应用 | 字节跳动 ● 豆包支持 Python 代码运行和 HTML 代码实时预览 → 是不是做的有点晚了?这功能已经成为聊天机器人标配了
| 新闻 | 零一万物 ● 万智企业大模型一站式平台发布 → 正式宣布零一转型
3 月 19 日
| 模型 | OpenAI ● o1-pro 推理模型上线,目前最贵的人工智能模型 → 问个“你好”扣了十块
| 视频 | Stability AI ● Stable Virtual Camera 多视图扩散模型(开源)
| 应用 | Cursor ● Claude 3.7 Max 模式上线 → MAX 版本像是 Cursor 预置的一个工作流,而不是 Claude 的新版本模型
| 应用 | Windsurf ● Wave 5 重磅更新,Windsurf Tab 功能升级 → 终于补齐了一个大短板
| 3 D | 群核科技 ● SpatialLM 空间理解模型(开源)
| 机器人 | 宇树科技 ● G1 人形机器人完成全球首次原地侧空翻 && 首次鲤鱼打挺
3 月 20 日
| 模型 | 百川智能 X 北京儿童医院 X 小儿方健康 ● 福棠·百川(全球首个)儿科大模型发布 → 终于见到百川最新的消息了
| 视频 | 阶跃星辰 ● Step-Video-TI2V 图生视频模型(开源)
3 月 21 日
| 模型 | 腾讯 ● 混元 T1 深度思考模型发布并上线 → 速度很快,价格很便宜,智力也不错,综合性价比极高
| 音频 | OpenAI ● GPT-4o-transcribe 和 GPT-4o-mini-transcribe 语音转文本模型,gpt-4o-mini-tts 文本转语音模型
3 月 22 日
| 应用 | Anthropic ● Claude 可以联网 && Claude Code 辅助编程应用取消 WaitList 可以直接使用
3 月 23 日
| 融资 | Browser Use ● 完成 1700 万美元种子轮融资 → Browser Use 本质还是 CodeAct 的思想,通过 AI 编写 JS 代码,再去操作网页
3 月 24 日
| 应用 | 百度 ● 秒哒无代码应用开发平台上线 → 连使用代码去修改的机会都没有,是不是有点激进了
3 月 25 日
| 模型 | Google ● Gemini 2.5 Pro(实验版)多模态推理模型发布 → 对标 Claude 3.7 Sonnet
| 模型 | 阿里巴巴 ● Qwen2.5-VL-32B 多模态模型(开源) → 很适合本地部署来做 OCR 任务
| 模型 | DeepSeek ● DeepSeek-V3-0324 模型更新(开源) → 期待基于 v3-0324 训练的新版 R1(会不会叫 R2 呢)
| 模型 | RWKV 元始智能 ● RWKV-7-G1 0.4B 推理模型(开源) → Transformer 的挑战者至今还未成规模
| 图像 | Reve ● Reve Image(Halfmoon)图像生成模型
3 月 26 日
| 模型 | OpenAI ● GPT-4o 图像生成功能上线,吉卜力风格图像爆火全球 → 全面超越 Gemini 生图能力,给大众秀了一把全模态模型的能力
| 音频 | 昆仑万维 ● Mureka V6 音乐生成模型 && Mureka O1 音乐推理模型 → Suno 真正的挑战者,还支持 API 接入
| 新闻 | 智源研究院 ● 被美国商务部列入新一批「实体清单」 → 另一种“官方技术认证”
3 月 27 日
| 模型 | 阿里巴巴 ● Qwen2.5-Omni-7B 端到端全模态大模型(开源) → 猜测这个模型很快也可以生成图片
| 模型 | 蚂蚁集团 ● Ling-Coder-Lite 和 Ling-Coder-Lite-Base 代码大模型(开源) → 和传说中的 Qwen3 规格有点像
| 图像 | Ideogram AI ● Ideogram 3.0 图像生成模型发布 → 与 4o 或 Gemini 的生图相比,有种古典模型的感觉了
| 应用 | 快手 ● 可灵 AI 上线多款创意特效 && AI 音效
3 月 28 日
| 模型 | 阿里巴巴 ● QVQ-Max 视觉推理模型 → 期待 QWQ 和 QVQ 合并
| 应用 | 字节跳动 ● 豆包深度思考实现「边想边搜」 → 此功能应该是通过模型后训练达到的,而不是简单的多轮调用,字节这次领先了
| 3 D | Meshy AI(胡渊鸣)● Meshy-V5(预览版)3D 生成模型上线 → AI 3D 生成越来越精细了
3 月 29 日
| 应用 | 面壁智能 ● cpmGO 小钢炮超级助手,首个纯端侧智能助手
| 3 D | VAST ● TripoSG 和 TripoSF 两款 3D 模型发布(开源)
3 月 30 日(无)
3 月 31 日
| 模型 | 智谱 ● AutoGLM 沉思上线,沉思模型 GLM-Z1-Rumination(即将开源) → 在本地跑的“Manus”,对隐私更加友好
| 模型 | 蚂蚁集团 X 清华大学(吴翼) ● AReaL-boba 强化学习训练框架(开源) → R1 复现的门槛更低了,以后可能就是计算机系的课后作业了
| 模型 | 中国科学院青藏所 ● 洛书(全球首个)水-能-粮大模型
| 视频 | Runway ● Runway Gen-4 视频生成模型发布 → 暂时只支持图片生成视频
✦ ✦ ✦
3月1日
【新闻】
北京市
印发《北京具身智能科技创新与产业培育行动计划(2025-2027年)》
北京市科学技术委员会等部门联合发布了《北京具身智能科技创新与产业培育行动计划(2025-2027年)》,旨在推动北京成为全球具身智能科技创新策源地和产业增长极。
《计划》明确,北京将重点攻坚六大核心技术:① 突破多模态融合感知技术,② 研发具身智能「大脑」大模型,③ 提升具身智能「小脑」技能模型能力,④ 提高机器人运动控制性能,⑤ 强化核心零部件技术创新和供给能力,⑥ 研制国产高性能具身智能芯片。
锐评(by Jomy)→ 全国范围内,政策越来越多

https://www.beijing.gov.cn/zhengce/zhengcefagui/202503/t20250304_4024579.html
【新闻】
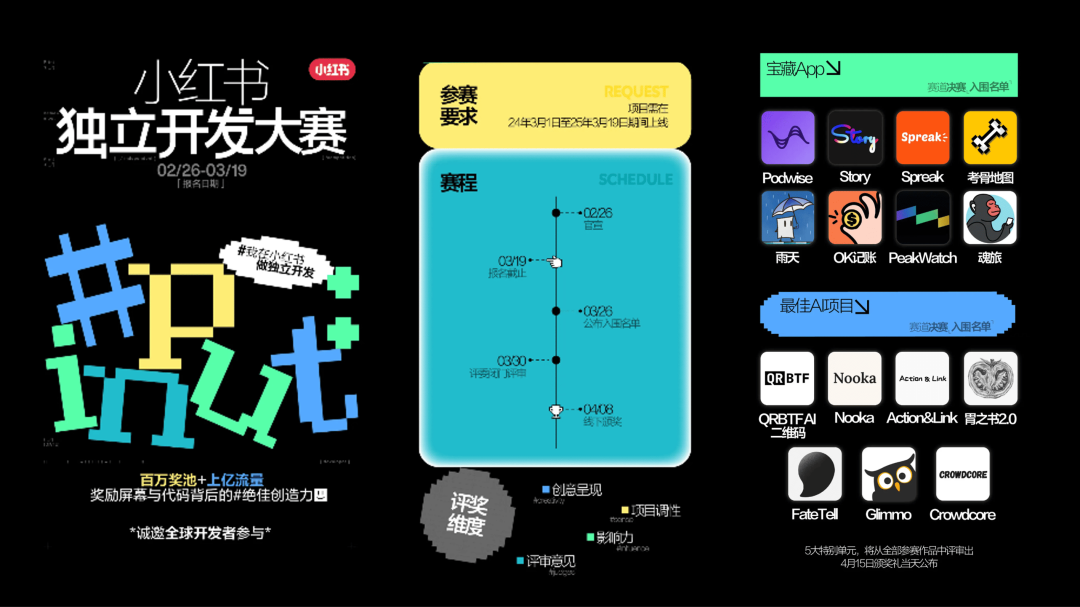
小红书
启动首届「独立开发大赛」,提供百万奖金池和上亿流量支持
本届大赛设有「宝藏App」和「最佳AI项目」两个赛道,总奖池高达 135 万元,其中「全场大奖」可以获得最高 50 万元奖金。优秀获奖团队将获得专家指导、投资机会以及海量站内曝光。
赛程:3月26日,公布入围名单;3月30日,评委闭门评审;4月15日,线下颁奖。
https://xhslink.com/dGqsV8 | 🔍官方介绍
3月3日
【模型】
科大讯飞
星火医疗大模型 X1 首发 && 「星火X1+DeepSeek」学习机首发
星火医疗大模型 X1 基于升级后的「星火 X1」深度推理大模型,大幅降低了医疗幻觉问题,在回答复杂问题时能够逐步解释循证过程,提高了医疗复杂场景推理的逻辑正确性、专业性、可解释性。
此外,首款「星火X1+DeepSeek」双引擎 AI 学习机正式发布,实现了 AI 1对1精准学、AI 1对1英语口语陪练、家长端「讯飞AI学」三大功能升级。
使用入口:星火医疗大模型 X1 已应用于讯飞晓医(App 或微信小程序)。

🔍官方介绍
【图像】
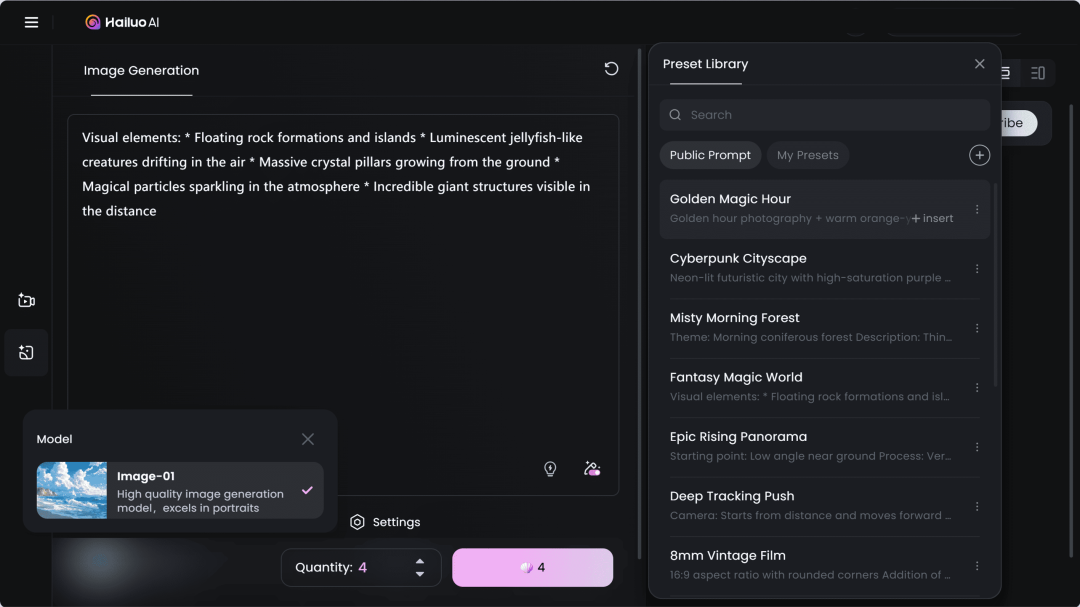
Minimax
Image-01 图像生成模型上线
Image-01 是 MiniMax 推出的首款文生图模型,凭借其在视频生成领域的深厚技术积累,在即时控制、图像质感和真实性等方面表现出色。它在高批次效率和成本控制上优势明显,用户可一次性批量生成多达 90 张图像,成本仅为市场上同类质量产品的 1/10。
使用入口:前往海螺 AI 官网(hailuoai.com/video)体验,模型新增了提示词图书馆;或者调用 API(minimaxi.com/platform_overview)。
实测图片真实性很高,可以和海外模型媲美 👍
https://minimax.io/news/image-01
【视频】
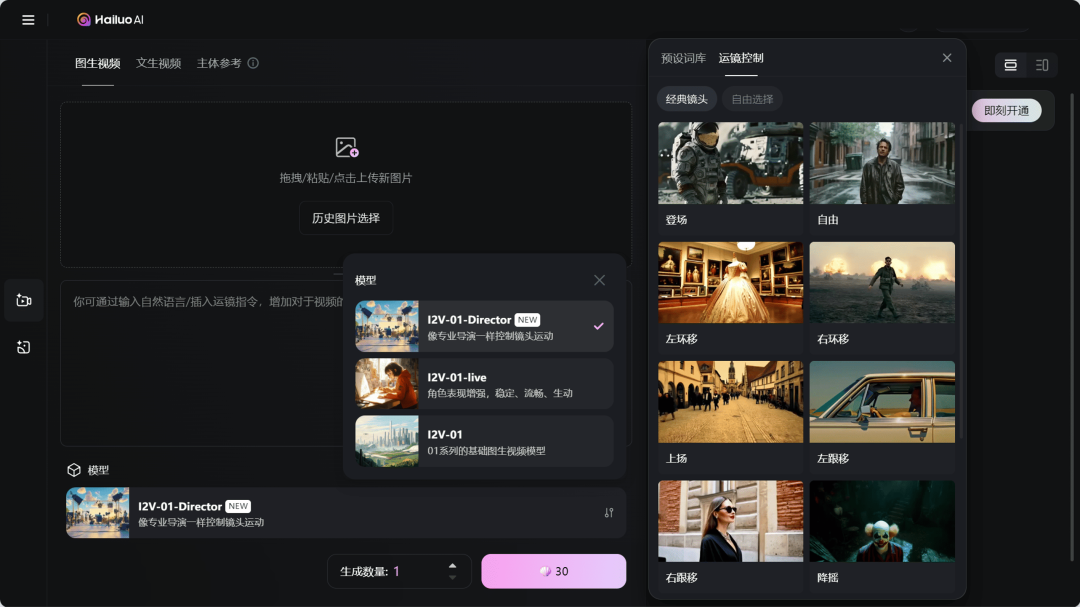
Minimax
I2V-01-Director「镜头控制」图生视频模型上线
I2V-01-Director 是一款图生视频模型,可通过提示词控制镜头语言,实现镜头移动、晃动、变焦等 15 种单一运镜及超百种运镜组合。它与此前发布的 T2V-01-Director 共同构成了 01-Director 系列。
使用入口:前往海螺 AI 官网(hailuoai.com/video/create)体验;或者调用 API。
和 Luma 类似,使用提示词来控制镜头 🎥
https://www.minimax.io/news/01-director | 🔍官方介绍
【应用】
字节跳动
辅助编程应用 Trae 国内版发布
Trae 于 1 月份发布了海外版,如今国内版也正式上线,配置了 Doubao-1.5-pro,并支持切换至满血版 DeepSeek R1、V3(最新版)等模型。本月发布了多项更新。
Trae 是一款由 AI 驱动的辅助编程工具,具备智能代码补全、实时优化、基于 Agent 的编程以及多模态交互(例如上传图片生成代码)等多项功能。
使用入口:前往官网(trae.com.cn)下载并安装。海外用户/海外版本可访问官网(trae.ai)下载并安装。
国内版 Cursor
🔍官方介绍
【应用】
字节跳动
火山引擎「大模型应用实验室」开源 6 款 AI 应用
火山引擎上线「大模型应用实验室」平台,开源了手机助手、Deep Research、DeepSeek联网版、实时视频理解、互动双语视频生成器、语音实时通话等 6 款 AI 应用,助力企业跳过行业化难题,快速搭建并落地应用。
使用入口:前往 GitHub(github.com/volcengine/ai-app-lab)下载并部署。
只有 API 不够了,要喂到开发者嘴边了 🍚

https://github.com/volcengine/ai-app-lab | 🔍官方介绍
【应用】
秘塔
视频搜索功能上线
秘塔 AI 搜索上线了「视频」搜索功能,可以帮助用户快速定位所需要的视频资源,并附有文字简介。这标志着秘塔在多模态数据覆盖范围上实现了进一步拓展。
使用入口:前往秘塔AI搜索官网(metaso.cn)体验。
测试下来,原理是对 B 站的视频字幕做了提取和总结,再进行文字的检索 📺

🔍官方介绍
【机器人】
灵初智能
Psi R0.5 端到端 VLA 模型发布
Psi R0.5 是一款基于强化学习的 VLA 模型,相较于之前的 Psi R0 版本,其在复杂场景的泛化能力、灵巧性、思维链(CoT)以及长程任务能力上都有显著提升。
更值得一提的是,团队提出的 DexGraspVLA 框架,能够通过少量数据(仅需约2小时)在上千种物体、位置、光照变化下实现灵巧抓取,数据利用效率大幅提升。

https://dexgraspvla.github.io | 🔍官方介绍
【融资】
智谱
完成多笔战略融资,杭州、珠海、成都等城市参与
智谱在 3 月份完成多笔战略融资。
第一笔来自杭州。3 月 3 日,杭州城投产业基金、上城资本等联合宣布,对智谱进行超 10 亿元人民币的投资。
第二笔来自珠海。3 月 13 日,珠海龙头国企华发集团宣布,对智谱进行 5 亿元的战略投资,以推进智谱基座 GLM 大模型的技术创新与生态发展。
第三笔来自成都。3月19日,成都高新区宣布,对智谱进行 3 亿元的战略投资,合作打造四川省基座大模型「智谱诸葛大模型」,同步建设大模型训练中心、研发中心及西部赋能平台三位一体的 AI 基础设施。
各地政府纷纷上了智谱的车 🚄
🔍杭州 | 珠海 | 成都
【融资】
Anthropic(Claude)
完成 35 亿美元 E 轮融资
Anthropic 宣布完成 35 亿美元融资,公司估值达到 615 亿美元。融资将用于推动下一代 AI 系统的开发,扩大计算能力,深化机制可解释性与对齐研究,并加速国际扩展。
此轮融资由 Lightspeed Venture Partners 主导,其他参与者包括 Bessemer Venture Partners、Cisco Investments、D1 Capital Partners、Fidelity Management & Research Company、General Catalyst、Jane Street、Menlo Ventures 以及 Salesforce Ventures。
与 OpenAI 的 3400 亿估值差了很多 💰

https://www.anthropic.com/news/anthropic-raises-series-e-at-usd61-5b-post-money-valuation
【新闻】
MWC25
世界移动通信大会在西班牙巴塞罗那举行
2025 年世界移动通信大会(MWC25)于 3 月 3 日至 6 日在西班牙巴塞罗那 Fira Gran Via 展览中心举行。大会主题为「Converge. Connect. Create.(融合、连接、创造)」,聚焦人工智能、5G、物联网、量子计算和数字技术演变等前沿科技领域。
大会吸引了来自全球 205 个国家和地区的 2700 多家参展商,包括 344 家中国科技企业。其中,小米的 SU7 Ultra 成为焦点,Google Cloud 展台 Gemini 自研大模型非常受欢迎,宇树则凭借机器狗的表演吸引了大量观众驻足围观。

https://www.mwcbarcelona.com | 🔍媒体报道
【新闻】
深圳市
一天之内连出 4 项行动计划,「四箭齐发」打造创新之城与产业高地
🔍《深圳市加快打造人工智能先锋城市行动计划(2025—2026年)》绘制出未来两年城市人工智能发展的全景图。到 2026 年,全市人工智能企业数量超 3000 家,独角兽企业超 10 家,产业规模年均增长超 20%,推出 10 个以上产业集聚效应明显的人工智能和具身智能机器人创新孵化器。
🔍《深圳市加快推进人工智能终端产业发展行动计划(2025—2026年)》聚焦智能终端产业升级,以人工智能技术赋能产业高质量发展。到 2026 年,全市人工智能终端产业规模达 8000 亿元以上,集聚不少于 10 家现象级人工智能终端企业,人工智能终端产品产量突破 1.5 亿台,推出 50 款以上爆款人工智能终端产品,打造 60 个以上人工智能终端典型应用场景。
🔍《深圳市具身智能机器人技术创新与产业发展行动计划(2025-2027年)》推动具身智能机器人产业跨越式发展。到 2027 年,新增培育估值过百亿企业 10 家以上、营收超十亿企业 20 家以上,实现十亿级应用场景落地 50 个以上,关联产业规模达到 1000 亿元以上,具身智能机器人产业集群相关企业超过 1200 家。
🔍《深圳市有力有效支持发展瞪羚企业、独角兽企业行动计划(2025—2027年)》重点关注微观市场主体。到 2027 年,累计培育瞪羚企业 1000 家、独角兽企业 80 家,将深圳建设成为具有国际影响力的瞪羚企业、独角兽企业集聚高地。
深圳政策加码,因为这一次 AI 浪潮,珠三角的存在感太低了

3月4日
【模型】
字节跳动
SuperGPQA 知识推理基准测试集(开源)
SuperGPQA 是一个领域全面且具备高区分度的知识推理基准测试,覆盖 285 个研究生级学科、包含 26529 道专业问题,不仅涵盖主流学科,更将轻工业、农业、服务科学等长尾学科纳入其中,填补了长尾知识评估领域的空白。
使用入口:前往官方站点获取数据(huggingface.co/datasets/m-a-p/SuperGPQA)和代码(github.com/SuperGPQA/SuperGPQA)。
更严格的测试集,可以看到各家模型的真实水准 🥇
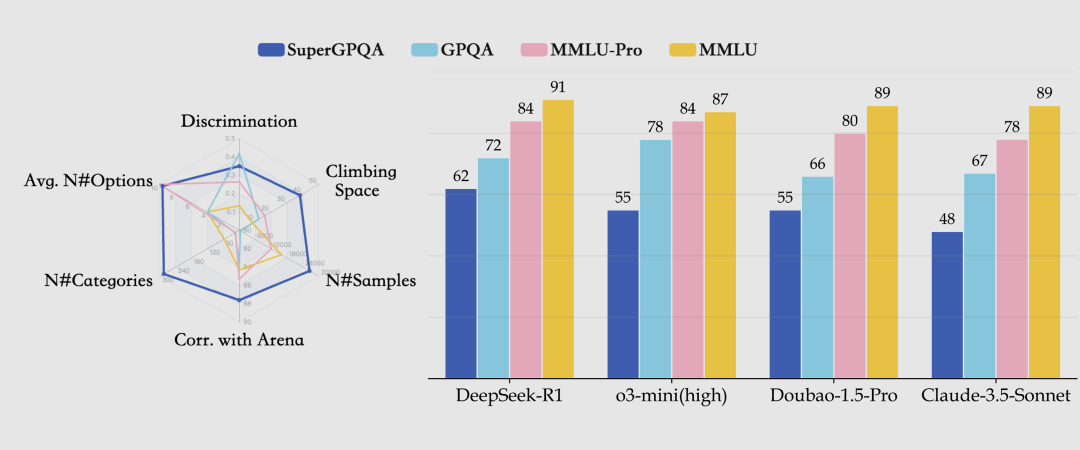
🔍官方介绍
【图像】
智谱
CogView4 图像生成模型,支持中英文字符生成(开源)
CogView4 文生图模型有两大技术领先性:一是支持中英双语提示词输入,擅长理解和遵循中文提示词,能够将中英文字符自然地融入画面;二是支持输入任意长度提示词,如几百字的超复杂提示词,生成范围内任意分辨率图像。
使用入口:开源;可以前往智谱清言官网(chatglm.cn)体验。
图片 AI 味挺重,有点 Dalle 的味道,但是优势是中文渲染

🔍官方介绍
3月5日
【音频】
SparkAudio
Spark-TTS 文本转语音模型
Spark-TTS 是一款基于 LLM 架构的文本转语音(TTS)模型,完全基于 Qwen2.5 构建,直接从 LLM 预测的代码中重建音频,简化了语音合成的流程。
Spark-TTS 仅需几秒钟的语音样本,就能精准地复制任何人的声音特征,还可以通过文本直接控制音高、语速和说话风格,并在跨语言和代码切换时保持自然。
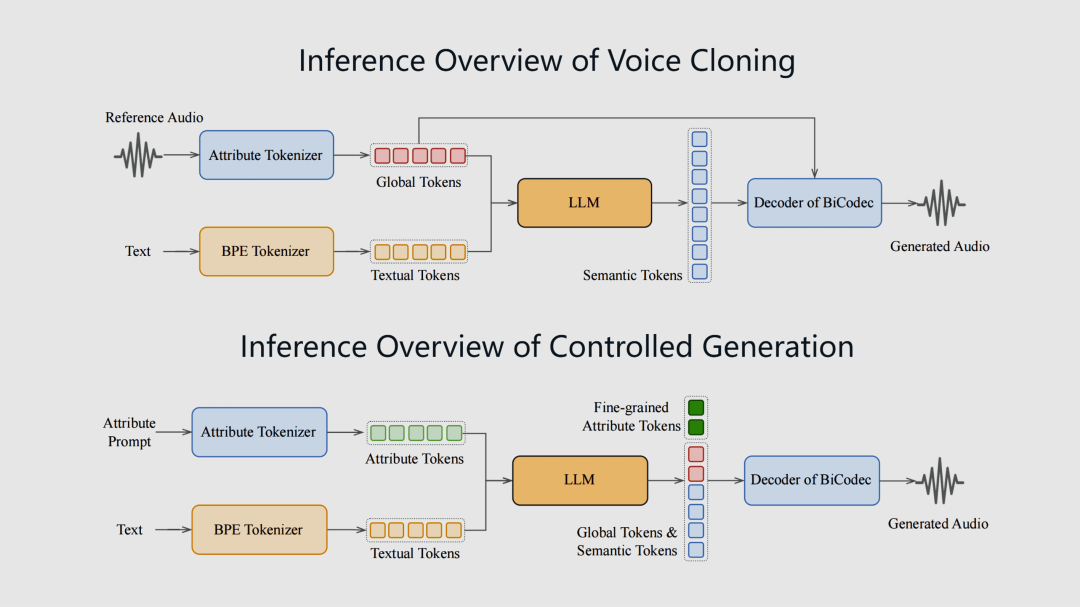
https://sparkaudio.github.io/spark-tts
【应用】
蝴蝶效应
Manus 通用 AI Agent 上线并开启邀测
Manus 是一款适用范围广泛的 AI Agent,它具备强大的任务规划、执行和交付能力,能够独立思考、自主学习并调用多种工具完成复杂任务,如撰写报告、分析股票、规划旅行、编写代码等。官方视频称,在 GAIA 基准测试中,Manus 表现卓越,取得了 SOTA 成绩,超越了 OpenAI 的 Deep Research 等同类产品。
3 月 11 日,Manus 官方宣布其中文版与通义千问达成战略合作,双方将基于通义千问系列开源模型,致力于在国产模型和算力平台上实现 Manus 的全部功能。
使用入口:前往官网(manus.im)申请。
Manus 的爆火引领了 AI Agent 的开发热潮 🔥
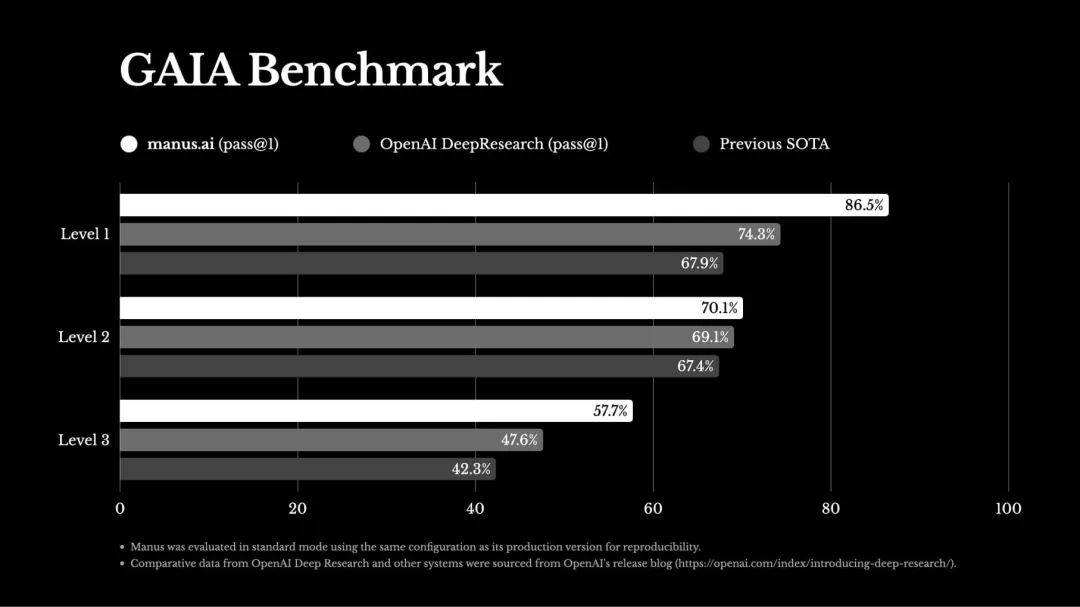
https://x.com/ManusAI_HQ/status/1897294098945728752
【融资】
爱诗科技 AIsphere
完成 A5 轮融资 && PixVerse 月活突破 1500 万
爱诗科技宣布完成 A5 轮融资,本轮融资由靖亚资本独家投资。至此,爱诗科技 A 轮融资整体规模已超 4 亿人民币。此次融资资金将用于持续优化底层模型、加速产品研发以及引进顶尖人才。
爱诗科技旗下的视频生成平台 PixVerse 全球累计用户量已突破 4000 万,月活跃用户达 1500 万。此外,PixVerse 国内版网页端及 App 产品近期即将上线。
继续在 2C 的路上越做越好 👍

🔍官方介绍 | 🔍融资详情
【新闻】
图灵奖
Richard Sutton 和 Andrew Barto
2024 年图灵奖授予了强化学习领域的两位先驱—— Richard Sutton 和 Andrew Barto。他们自 1980 年代起就开始合作,在一系列论文中提出了强化学习的主要思想,构建了强化学习的数学基础,并开发了强化学习的重要算法。两人合著的《Reinforcement Learning: An Introduction》一直是强化学习领域最经典的教材之一。
图灵奖被誉为「计算机界的诺贝尔奖」,奖金高达 100 万美元,由 Google 公司提供资金支持。
RL的始祖!没有他们就没有今天的推理模型

https://awards.acm.org/about/2024-turing
3月6日
【模型】
阿里巴巴
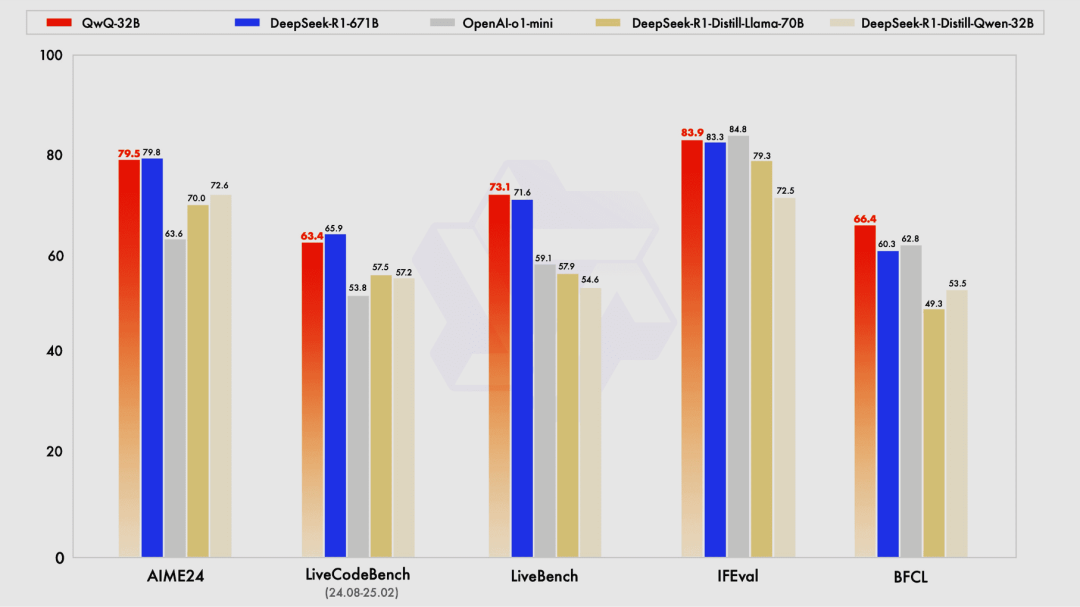
QwQ-32B 推理模型发布(开源)
QwQ-32B 推理模型在数学推理(AIME24)、编程能力(LiveCodeBench)、通用能力(LiveBench)等多个基准测试中表现优秀,几乎直逼满血版 DeepSeek R1,远超 o1-mini 及其他同尺寸模型。
最重要的是,QwQ-32B 不仅性能强大,还体积小、推理快,支持消费级显卡部署,是目前单机能部署最具性价比的模型。
使用入口:开源;前往 QwenChat(chat.qwen.ai)官网体验。
第一个可轻松本地部署的真推理模型,利好小企业
https://qwenlm.github.io/zh/blog/qwq-32b | 🔍官方介绍
【模型】
Mistral AI
Mistral OCR 模型开放 API
Mistral OCR 是一款智能文档识别与处理模型,能精准识别文本、图像、表格、数学公式等复杂元素,并以结构化的 Markdown 或 JSON 格式输出。它支持多语言,处理速度高达每分钟 2000 页,总体准确率超 94.89%
使用入口:前往 Le Chat 官网(chat.mistral.ai/chat)试用;调用 API(每 1000 页 1 美元)。
实测速度真的很快 ⚡

https://mistral.ai/news/mistral-ocr
【视频】
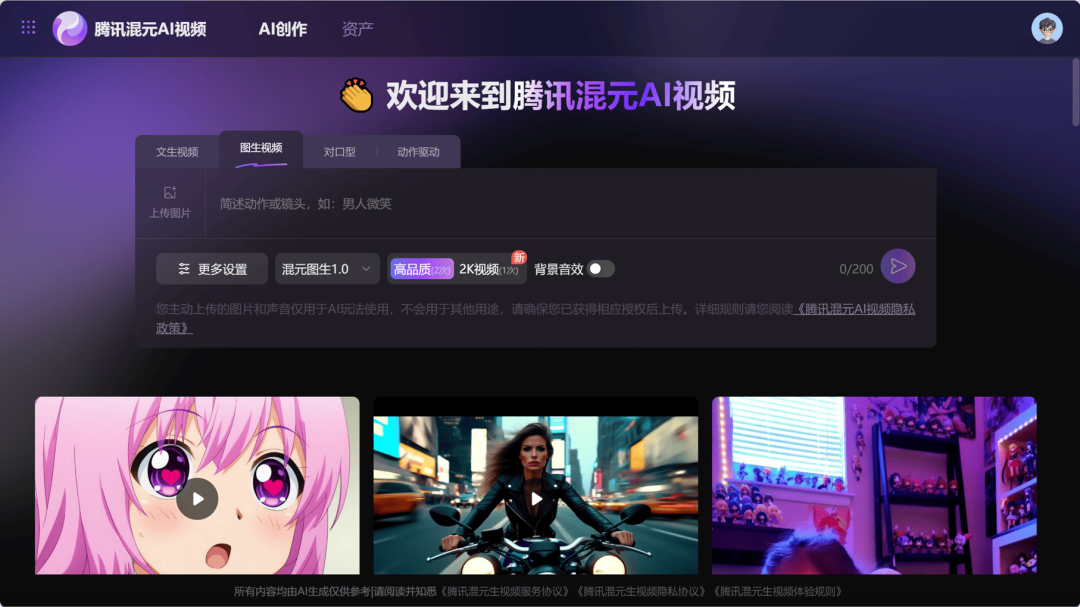
腾讯
HunyuanVideo-I2V 图生视频模型发布(开源)
HunyuanVideo-I2V 是一款强大的图生视频模型。用户只需上传一张图片,并简要描述画面动作或镜头调度,它就能让图片动起来,生成 5 秒短视频,还能自动配上背景音效。
此外,上传一张人物图片并输入希望「对口型」的文字或音频,图片中的人物即可「说话」或「唱歌」。使用「动作驱动」能力,还能一键生成同款跳舞视频。
使用入口:开源;前往混元 AI 视频官网(video.hunyuan.tencent.com)体验;在腾讯云申请使用 API 接口。
腾讯模型也全方位覆盖了
https://video.hunyuan.tencent.com | 🔍官方介绍
【应用】
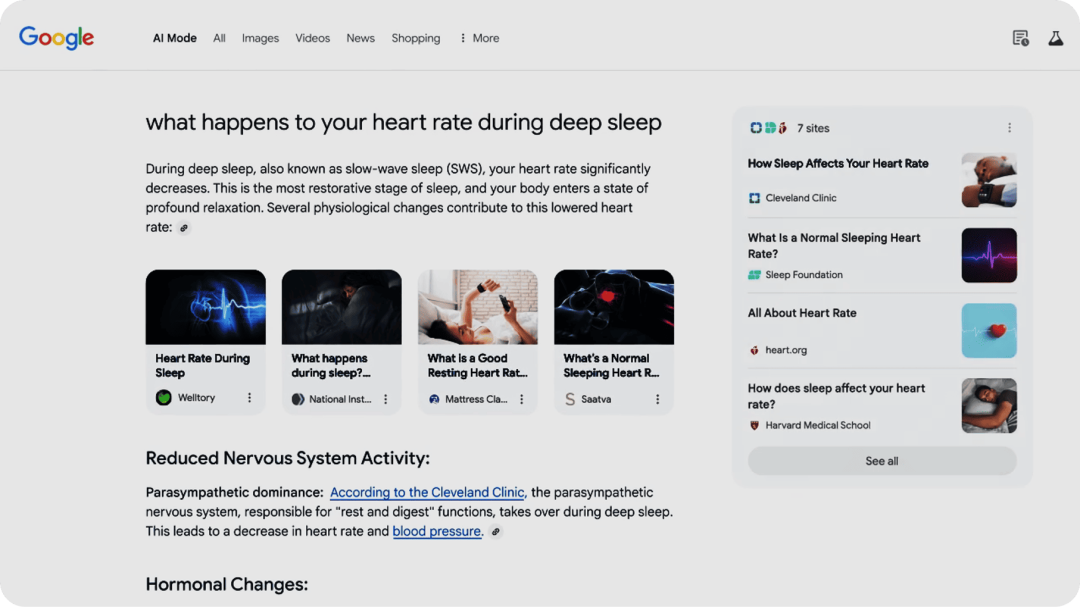
AI Mode 搜索新功能开始测试
谷歌搜索开始测试一种全新的搜索模式—— AI Mode。以往用户在处理复杂问题时,往往需要多次搜索才能解决,而 AI Mode 能够通过更高级的推理、思考和多模态能力,解决这个痛点。搜索体验与呈现结果类似 Gemini Deep Research。
使用入口:AI Mode 还在实验阶段,可以前往 Google Lab(labs.google.com/search/experiment/22)申请体验。
https://blog.google/products/search/ai-mode-search
【应用】
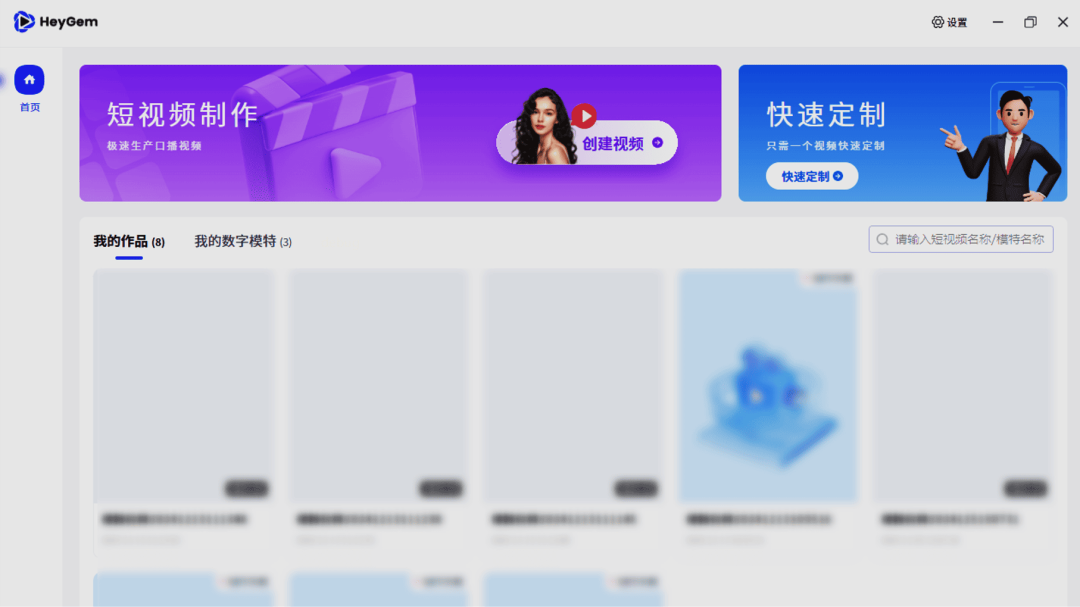
硅基智能
HeyGem 数字人合成工具(HeyGen 开源替代品)
Heygem 是一款专为 Windows 系统设计的全离线视频合成工具。它可以通过 1s 视频或者一张照片,轻松地克隆出逼真的数字人的形象和声音。用户可以使用文字或者语音来控制视频中的虚拟形象,并且口型和语音确保自然流畅。
使用入口:开源,前往官网(heygem.ai)了解更多。
https://github.com/GuijiAI/HeyGem.ai | 🔍官方介绍
3月7日
【模型】
Gemini Embedding 文本嵌入模型发布并上线
Gemini Embedding 是一款实验性文本嵌入模型,可将文本转换为数值向量,广泛应用于语义搜索、推荐系统和文档检索等场景。该模型支持超 100 种语言,能处理长达 8K token 的输入,擅长处理复杂文本块和多语言任务。在多语言文本嵌入基准测试(MTEB)中超越了 Mistral、Cohere 和 Qwen 等主流模型,成为当前性能最强的文本嵌入模型。
使用入口:通过 Gemini API 提供服务。
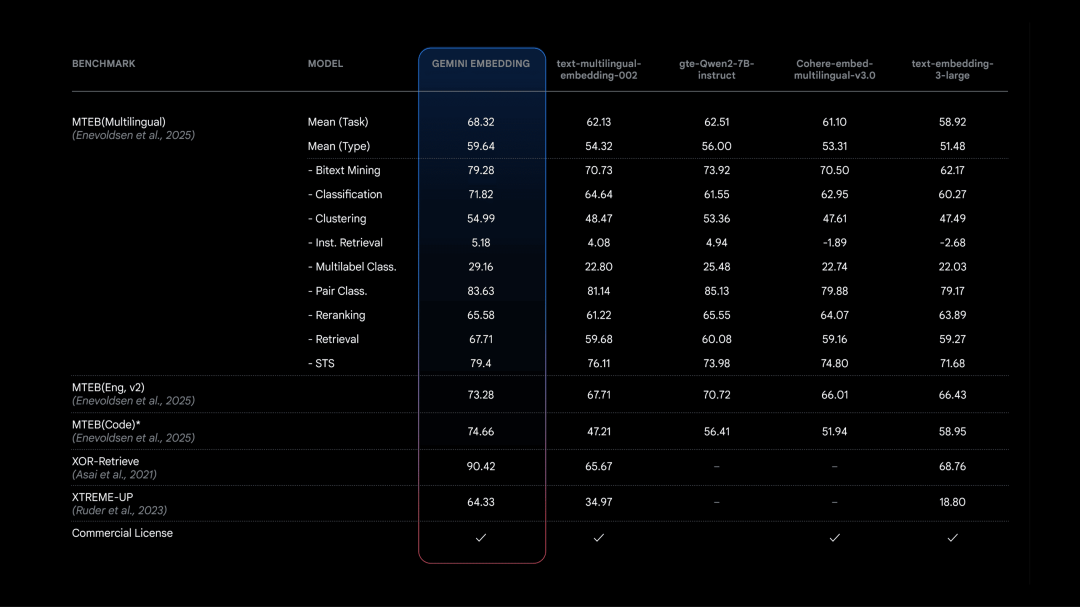
https://developers.googleblog.com/en/gemini-embedding-text-model-now-available-gemini-api
【应用】
Hedra Labs
Character-3 多模态 AI 数字人视频生成模型
Character-3 是一款全模态 AI 数字人视频生成模型,可以同步处理图像、文本和音频输入,通过联合推理生成高质量动态视频,角色能说话、唱歌甚至说唱。它支持人类、动漫、动物等多类角色,具备全身动作捕捉与精细情感控制功能,能精准匹配唇形、表情、动作与语音内容。
使用入口:前往 Hedra 官网(hedra.com)试用。
期待尽快开放 API 接入 🧭

https://x.com/hedra_labs/status/1897699010632466469
3月10日
【模型】
字节跳动
COMET 通信优化系统(开源)
COMET 通信优化系统旨在解决分布式训练中通信开销过大的问题。它显著提升了大规模 MoE 模型的训练效率,单层加速可达 1.96 倍,端到端加速 1.71 倍,且在不同并行策略、输入规模及硬件环境下均表现稳定。目前已实际应用于万卡级生产集群,已累计节省了数百万 GPU 小时资源。
使用入口:核心代码已开源。
自从 DeepSeek 爆火后,MoE 架构也被越来越多模型公司选择

https://github.com/bytedance/flux | 🔍官方介绍
【机器人】
智元机器人
Genie Operator-1 通用具身基座大模型
Genie Operator-1(智元启元大模型)是一款通用具身基座模型,采用 ViLLA 架构,具备人类视频学习、小样本快速泛化、一脑多形跨本体应用、持续进化和高效动作执行等核心功能。官方称其可以降低具身智能门槛,并成功部署到智元多款机器人本体。

https://agibot-world.com/blog/agibot_go1.pdf | 🔍官方介绍
【新闻】
OpenAI 与微软关系紧张
OpenAI 转投 CoreWeave,微软自研大模型
CoreWeave 由 Nvidia 支持,专注于 AI 云服务,旗下有 32 个数据中心。3月10日,OpenAI 与 CoreWeave 达成了一项为期 5 年、价值 119 亿美元的协议。此前它的最大客户是微软。
而微软也被爆出正在推进自研模型,计划替代 OpenAI 的 o1、o3-mini 等核心模型,同时还积极测试 xAI、Meta、Anthropic 和 DeepSeek 等模型,以提升 Copilot 的技术实力。
这对昔日的「黄金搭档」正在走向技术竞争的新阶段。

https://techcrunch.com/2025/03/10/in-another-chess-move-with-microsoft-openai-is-pouring-12b-into-coreweave
https://www.theinformation.com/articles/microsofts-ai-guru-wants-independence-from-openai-thats-easier-said-than-done
3月11日
【模型】
阿里巴巴
R1-Omni 全模态大语言模型(开源)
R1-Omni 是一款全模态大语言模型,借助强化学习与可验证奖励机制,显著增强了视觉与音频模态融合的推理能力,让情感识别更精准且更具可解释性。与传统监督微调方法相比,R1-Omni 在情感识别任务中表现出色,尤其在处理分布外数据时,展现出强大的泛化能力。
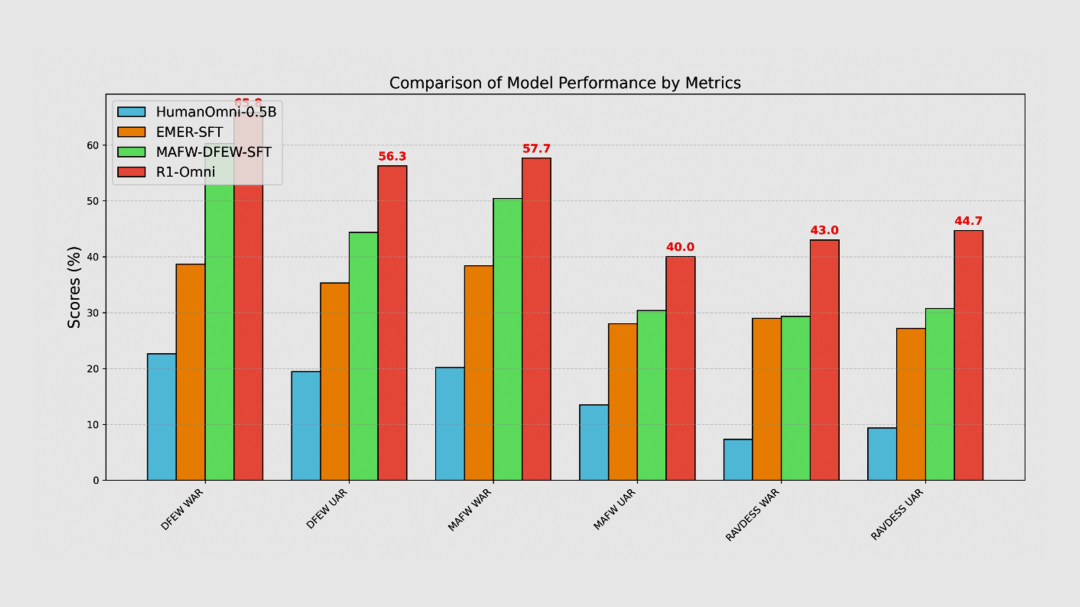
https://github.com/HumanMLLM/R1-Omni | 🔍官方介绍
3月12日
【模型】
OpenAI
Responses API 和 Agents SDK 发布
Responses API 和 Agents SDK 两项新技术,可以提高开发者的工作效率和应用的智能化水平。
Responses API 结合了现有 Chat Completions API 的简洁性和 Assistants API 的工具调用能力,开发者可通过一次 API 调用集成多种工具和模型,简化开发流程。它内置了三个工具:Web Search(网络搜索)、File Search(文件搜索)和 Computer Use(计算机使用)。
Agents SDK 是一个开源的智能体框架,基于去年的实验项目 Swarm 发展而来,于简化多智能体的开发、协调与优化流程。它兼容符合 Chat Completions 标准的模型,目前支持 Python,Node.js 版本即将推出。
3 月 27日,Sam Altman 宣布已经在 Agent SDK 中支持 MCP,对 ChatGPT 桌面应用以及 Responses API 的支持也即将到来!
此次升级,全部都是为了 Agent 生态而准备的 🧐

https://openai.com/index/new-tools-for-building-agents
【模型】
Gemma 3 多模态系列模型(开源)
Gemma 3 基于 Gemini 2.0 构建,是一组轻量级、高性能的模型,可在单个 GPU 或 TPU 主机上运行,谷歌称其为「全球最佳单加速器模型」。
Gemma 3 提供 1B、4B、12B 和 27B 四种尺寸版本。除 1B 版本外,其他版本支持理解 140 多种语言,其中 35 种语言可「开箱即用」。它还支持文本、图像、短视频混合输入,能处理图像问答、视频内容分析等复杂多模态任务,提供 128k tokens 的上下文窗口,支持函数调用和结构化输出。
使用入口:开源;也可以前往 Google AI Studio 使用。
一个很适合本地部署的多模态小模型
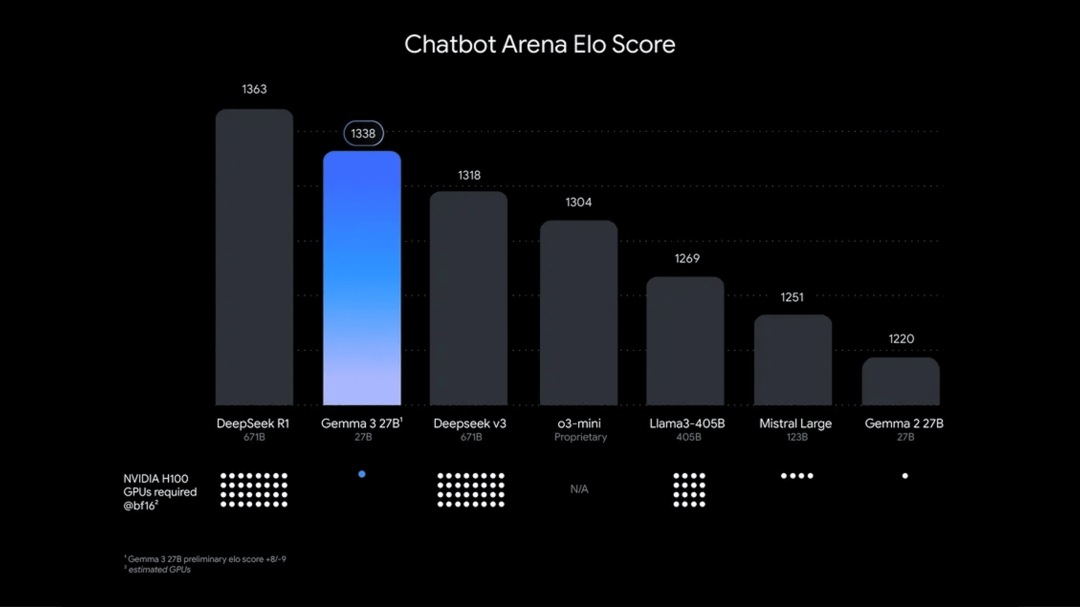
https://blog.google/technology/developers/gemma-3
【模型】
Google DeepMind
Gemini Robotics 和 Gemini Robotics-ER 模型发布
Gemini Robotics 和 Gemini Robotics-ER 模型能够使机器人更直观地操作物理世界,无需人类监督或预编程即可完成多种任务。
Gemini Robotics 是一款视觉语言动作(VLA)模型,能让机器人在未经专门训练的情况下理解新的情境,执行复杂的物理任务,如折纸或打开瓶盖等。
Gemini Robotics-ER(具象推理)是一款增强版视觉语言模型(VLM),专注于空间推理,帮助机器人更好地理解复杂动态环境。
DeepMind 已与 Apptronik 合作打造下一代人形机器人,并宣布与多家机器人公司合作测试 Gemini Robotics-ER 模型。

https://deepmind.google/discover/blog/gemini-robotics-brings-ai-into-the-physical-world
【图像】
Gemini 2.0 Flash 原生图像生成功能开放
Gemini 2.0 Flash 原生图像生成功能已正式上线。开发者可通过 API 或 AI Studio 界面测试该模型的图像生成与编辑功能。与 Stable Diffusion、Flux 等不同,Gemini 2.0 Flash EXP 模型既能用自然语言生成图片,还能将图像与文本融合输出,并支持多轮对话,逐步调整和优化图像。
使用入口:前往Google AI Studio(aistudio.google.com)试用;调用官方 API。
开启了 3 月通过 LLM 生成图片的浪潮,对传统图片生成模型形成了降维打击 💣
https://developers.googleblog.com/zh-hans/experiment-with-gemini-20-flash-native-image-generation
【图像】
字节跳动
Seedream 2.0 文生图模型技术报告发布
豆包大模型团队首次公开了 Seedream 2.0 图像生成模型的技术细节,涵盖数据构建、预训练框架以及后训练的 RLHF 全流程。
Seedream 2.0 文生图模型具备原生中英双语理解、文字渲染、高美感、分辨率与画幅变换等特性。自 2024 年 12 月初在豆包和即梦上线以来,已服务上亿 C 端用户。
字节很愿意分享技术细节,对行业是个大好事 👍
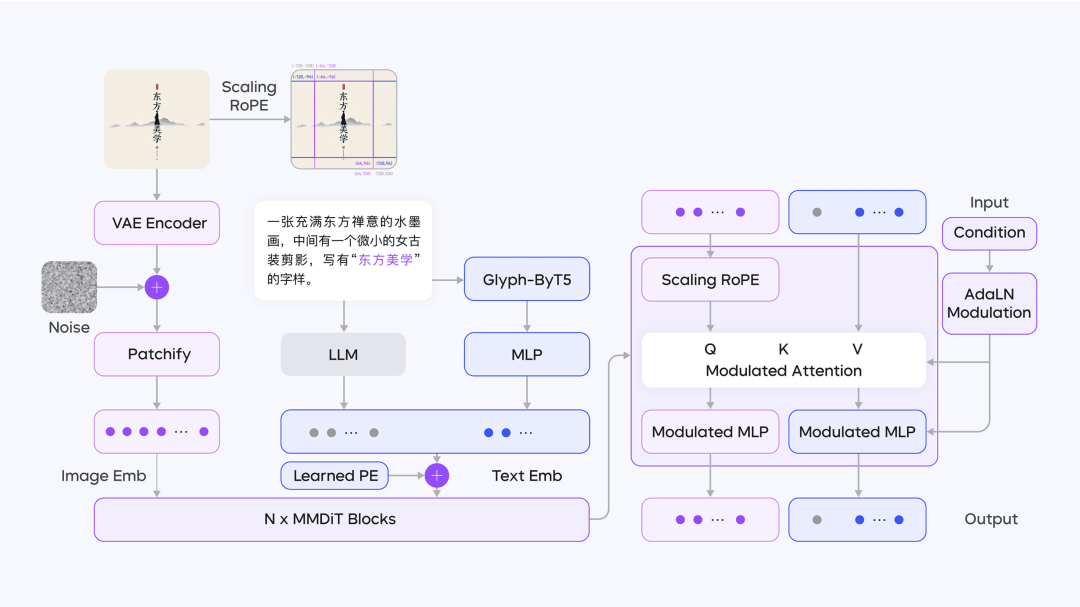
https://team.doubao.com/tech/seedream | 🔍官方介绍
3月13日
【模型】
Cohere
Command A 极致性能极低算力的企业级模型(开源)
Command A 是一款为企业应用场景量身打造的大模型,支持长达 256K 的上下文长度,涵盖 23 种语言,还能与企业工具无缝集成,助力复杂工作流程。
此外,Command A 仅需两块英伟达 A100 或 H100 GPU 即可高效运行,相比于 GPT-4o 和 DeepSeek-V3 等同类模型,大幅降低了硬件成本。
使用入口:开源;可以调用 API。
111B 的参数量,比传统的 32B 或 70B 门槛还是高了不少,所以热度不高

https://cohere.com/blog/command-a
【应用】
阿里巴巴
夸克升级为 AI 旗舰应用,推出「AI 超级框」概念
夸克宣布基于通义推理及多模态大模型,全面升级为无边界的「AI超级框」。用户输入指令后,夸克智能中枢系统将自动识别意图并完成 AI 搜索、AI 写作、AI 生图等各场景任务。未来,通义系列最新模型也将第一时间接入夸克。
使用入口:下载夸克客户端、移动App 进行体验。
夸克想成为阿里 AI 的超级 App
https://www.quark.cn | 🔍官方介绍
3月14日
【音频】
Sesame
CSM 1B 语音合成模型(开源)
CSM(Conversational Speech Model)语音合成模型最大的特点是「真实」,其生成的语音带有真人般的语气和音调变化。该模型可直接从文本或音频输入生成语音,推理速度远超传统TTS,能够实现实时语音生成。模型上线后引发了广泛关注,被多位投资人评价为「目前最好的 AI 语音应用」。
使用入口:开源;前往官网与演示角色 Maya(女声)和 Miles(男声)互动;查看在线演示(huggingface.co/spaces/sesame/csm-1b)。
强烈建议听听 Demo,语气和情感极为真实 ❗❗❗
https://www.sesame.com/research/crossing_the_uncanny_valley_of_voice
【应用】
Google Gemini 重要更新
Personalization 个性化
开启个性化功能后,Gemini 即可连接你的谷歌应用(可以随时关闭),基于搜索历史提供更贴合个人需求的回答。比如,询问餐厅推荐时,Gemini 会参考你近期与食物有关的搜索记录;询问旅行建议时,Gemini 会参考你之前搜索过的目的地。
使用入口:在模型下拉菜单中选择 Personalization (experimental)。
给模型提供更好的上下文,是提升模型效果的捷径
https://blog.google/products/gemini/gemini-personalization
Gems 智能体
Gems 就是国内应用常见的「智能体」功能。Gemini 用户可以使用官方发布的 Gems(智能体),也可以通过提示词快速创建自己的专属智能体,更好地完成特定任务,比如翻译、旅行规划、膳食指导、数学辅导等等。
使用入口:已经向 Gemini 所有用户开放。
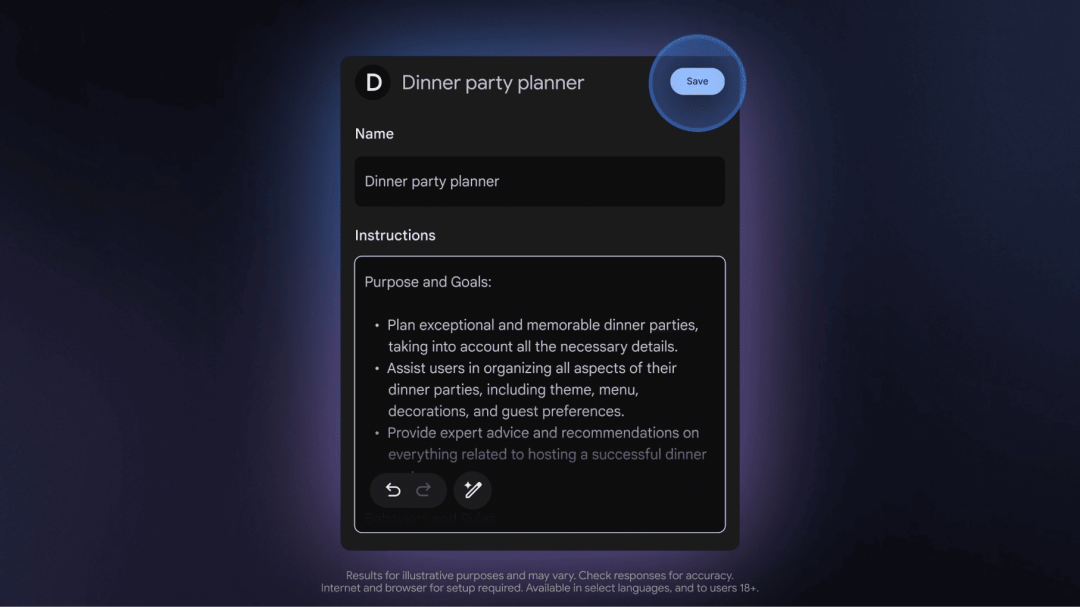
https://blog.google/products/gemini/google-gems-tips
Canvas
Canvas 互动空间可以完成文稿创建和编辑、并且可以基于 Gemini 模型的反馈进行优化,快速完善作品,还可以一键导出到 Google Docs。此外,Canvas 进一步简化了编程任务,覆盖代码生成/调试/解释各个环节,还可以生成并预览 HTML / React 代码。
使用入口:面向所有 Gemini 用户推出。
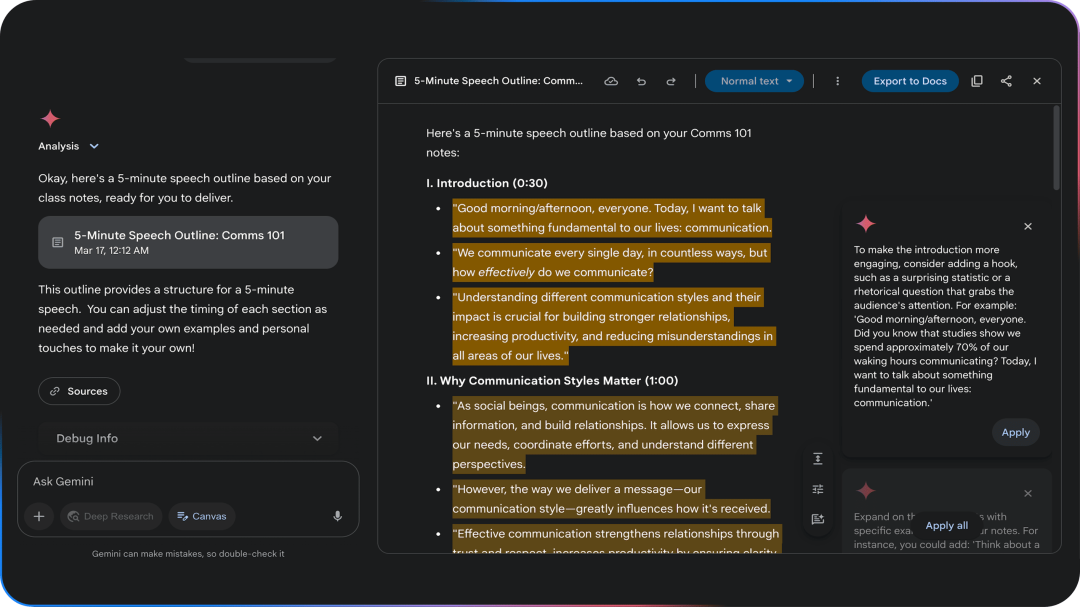
https://gemini.google/overview/canvas
Audio Overview
Audio Overview 可以把上传的文件转化为播客式的音频讨论,相当于把 NotebookLM 内置到 Gemni 里了。
使用入口:面向所有 Gemini 用户推出。
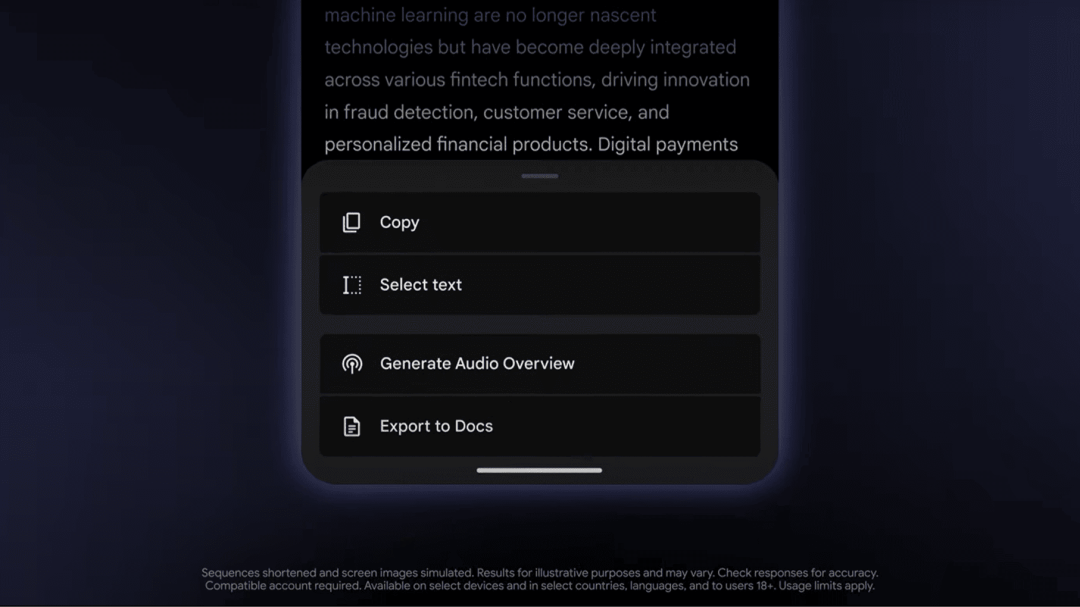
https://blog.google/products/gemini/gemini-collaboration-features
【新闻】
四部门联合发布
《人工智能生成合成内容标识办法》
国家互联网信息办公室、工业和信息化部、公安部、国家广播电视总局联合发布《人工智能生成合成内容标识办法》。《办法》要求自 2025 年 9 月 1 日起,所有 AI 生成的文本、图片、音频、视频等内容必须添加显式标识或隐式标识。
其中,显式标识需以文字、语音等可感知方式呈现,隐式标识则通过元数据或数字水印嵌入文件。传播平台需核验内容标识状态,对无标识或疑似AI生成内容进行标注提醒。
国家希望对 AI 生成的内容画出一条明确的界限

https://www.cac.gov.cn/2025-03/14/c_1743654685899683.htm
3月15日
【应用】
Anuttacon(蔡浩宇)
《Whispers From The Star》AI 游戏开启内测
《Whispers From The Star(群星低语)》是一款科幻背景的沉浸式互动叙事游戏:天体物理系学生 Stella 意外坠落到外星星球「盖亚」,玩家需要通过文字、语音或视频与她互动,帮助她生存并逃离险境。
2024 年 8 月,蔡浩宇卸任米哈游国内职务后创立了 Anuttacon,目标是通过 AI 技术突破互动娱乐的界限。
使用入口:游戏已开放内测(wfts.anuttacon.com),仅支持 iOS 12 以上的设备。

https://wfts.anuttacon.com
【新闻】
315 晚会
曝光 AI 外呼机器人在电话营销中的滥用乱象
2025 年 315 晚会曝光了 AI 外呼机器人在电话营销中的滥用行为及其对消费者权益的侵害。涉事公司利用 AI 外呼机器人拨打大量电话,其声音逼真,效率极高,且能够通过关键词触发话术,精准定位目标客户,严重侵犯了消费者的隐私权和生活安宁权。
根据《中华人民共和国民法典》第一千零三十三条,未经消费者同意,任何组织或个人不得通过电话、短信等方式侵扰他人的私人生活安宁。因此,无论是AI外呼机器人还是人工电话营销,未经用户同意的电话营销行为均属违法行为。

https://tv.cctv.com/2025/03/15/VIDEVvHrOCTeWbuYYHKd9beZ250315.shtml
3月16日
【模型】
百度
文心大模型 4.5 原生多模态大模型 && X1 深度思考模型发布
文心大模型 4.5 是百度首款原生多模态大模型,在多模态理解能力上显著提升。文心大模型 X1 是一款深度思考模型,性能对标 DeepSeek-R1,API调用价格约为 R1 的一半。
使用入口:前往文心一言官网(yiyan.baidu.com)免费使用;前往百度智能云千帆大模型平台调用 API。
🔍官方介绍
3月17日
【模型】
Mistral AI
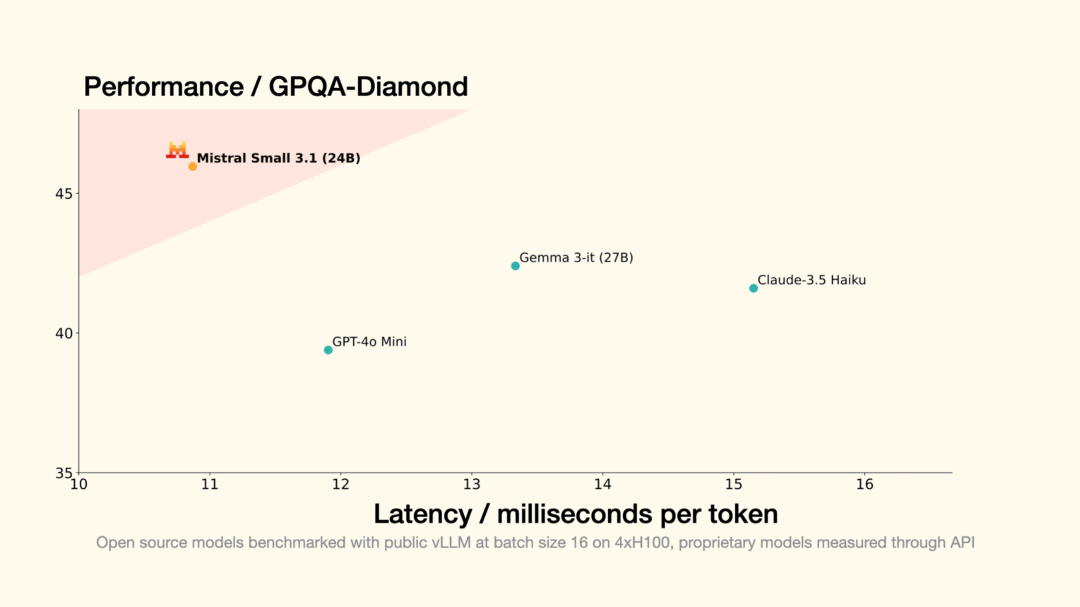
Mistral Small 3.1(24B)多模态理解模型(开源)
Mistral Small 3.1 是 Mistral Small 3 的升级版,新增了图像理解能力,上下文长度也提升至 128K,能在单张 RTX 4090 显卡或配备 32GB 内存的 Mac 上运行。模型在多个基准测试中击败了 Gemma 3 和 GPT-4o Mini 等同类模型。
使用入口:开源;前往官方开发者平台 La Plateforme(console.mistral.ai)调用 API;已上线谷歌云 Vertex AI 平台。
Gemma3 的竞品
https://mistral.ai/news/mistral-small-3-1
【3D】
Roblox
Cube 3D 建模工具(开源)
Cube 是一款基于生成式 AI 技术的 3D 建模工具,可以通过简单的文本提示词生成 3D 物体,并允许创作者在 Roblox Studio 中进一步调整和优化。
Roblox 还推出了三项 AI 新工具:文本生成、文本转语音、语音转文本,分别用于增强游戏中的文字交互、语音旁白、语音指令功能。未来还将推出更复杂的物体网格生成工具以及全新的场景生成工具。
使用入口:开源,官方 GitHub(github.com/Roblox/cube)和 HuggingFace(huggingface.co/Roblox/cube3d-v0.1)已发布。

https://corp.roblox.com/newsroom/2025/03/introducing-roblox-cube
3月18日
【模型】
昆仑万维
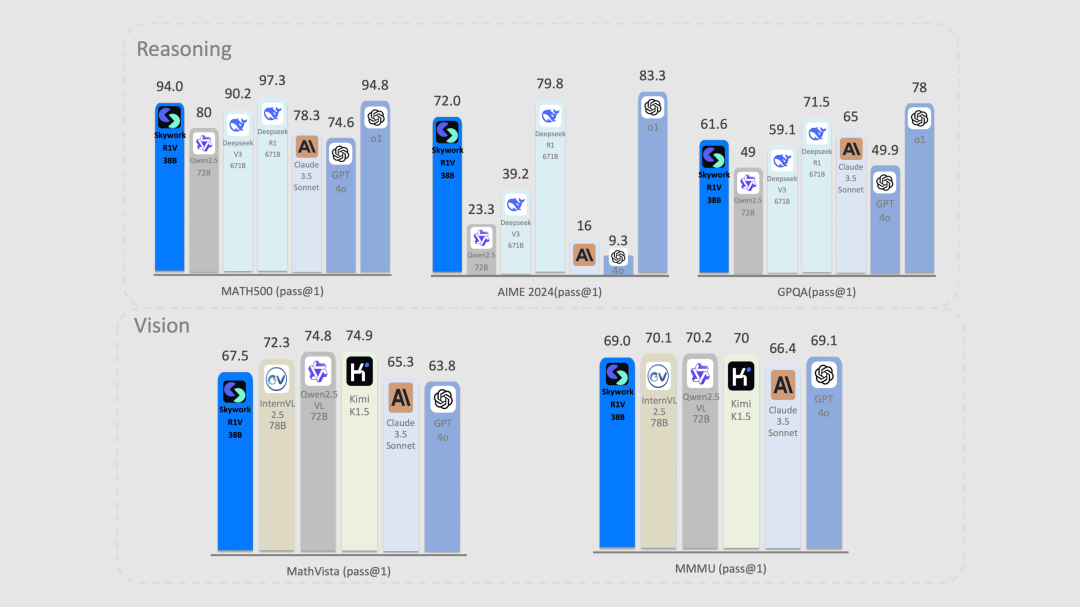
Skywork R1V 多模态思维链推理模型(开源)
Skywork R1V 是一款多模态思维链推理模型,能够对复杂视觉任务进行多步骤逻辑推理,逐步分析并得出结论。
官方称其为「全球·首个·工业级·开源」多模态推理模型,是因为其通过 Skywork-VL 视觉投影器,将文本推理能力高效迁移到视觉任务中,无需重新训练语言模型和视觉编码器,在工业界缺失视觉数据库的情况下也能够实现视觉推理能力。
使用入口:开源了模型权重和技术报告。
名字 R1V 非常直白,比 R1 多了多模态的能力,非常实用
https://github.com/SkyworkAI/Skywork-R1V | 🔍官方介绍
【3D】
腾讯
Hunyuan 3D 2.0 模型家族(开源)
Turbo 系列模型 在保证高精度和高质量的基础上,对几何生成模型进行了数十倍的加速,确保整个生成过程能够在 30 秒内完成。
多视图版本模型(例如 Hunyuan3D-2-MV)通过结合多个视图的输入信息,能够更好地捕捉细节并生成符合用户预期的 3D 资产。
轻量级 mini 系列模型 通过模型架构优化与运行效率提升,可进一步降低算力成本,其几何模型可以部署在 4080 显卡甚至苹果 M1 Pro 芯片上,为模型的应用扩展了场景。
使用入口:开源;前往3D创作引擎(3d.hunyuan.tencent.com)体验。
腾讯连 3D 都做,战略覆盖面应该是第一了 🥇

🔍官方介绍
【应用】
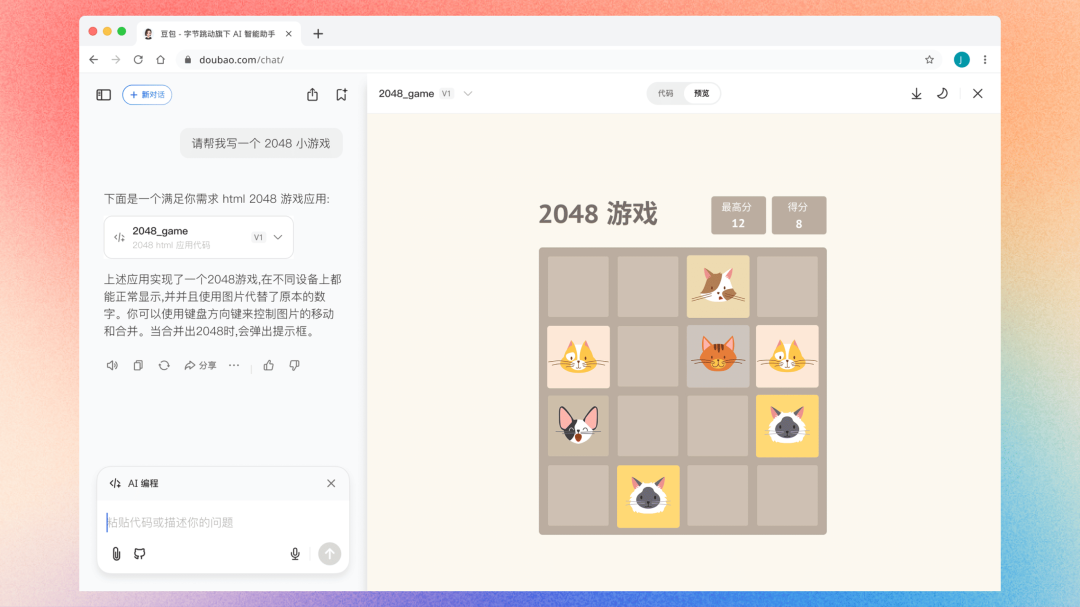
字节跳动
豆包支持 Python 代码运行和 HTML 代码实时预览
豆包「AI 编程」支持 Python 代码运行及 HTML 代码预览,实时验证生成代码的可用性。其中,Python 代码运行目前只支持部分常见库,HTML 代码支持实时预览和交互(也就是 Artifacts 功能)。
使用入口:前往豆包官网(doubao.com/chat/coding)免费使用。
是不是做的有点晚了?这功能已经成为聊天机器人标配了
https://www.doubao.com/chat/update
【新闻】
零一万物
万智企业大模型一站式平台发布
零一万物宣布推出万智企业大模型一站式平台,为企业级 DeepSeek 部署定制解决方案。零一万物创始人、CEO 李开复向媒体透露,公司已经全面转向应用阶段。
正式宣布零一转型了
https://b.01.ai | 🔍官方介绍
3月19日
【模型】
OpenAI
o1-pro 推理模型上线API,目前最贵的人工智能模型
o1-pro 是 OpenAI 目前最昂贵的人工智能模型,其定价为每百万输入 token 150 美元,每百万输出 token 600 美元,是常规 o1 模型生成价格的十倍。
o1-pro 价格之所以如此之高,主要是因为其投入了更多的计算资源,能够提供更一致且优质的回应,并支持视觉处理、函数调用、结构化输出等功能。此外,o1-pro 还兼容 Responses API 和 Batch API,使其在复杂任务处理上具有显著优势。
使用入口:目前仅向特定开发者开放。
问个“你好”扣了十块 💢

https://platform.openai.com/docs/models/o1-pro
【视频】
Stability AI
Stable Virtual Camera 多视图扩散模型(开源)
Stable Virtual Camera 模型可以把将静态图像(最多 32 张)转为沉浸式 3D 视频,生成的视频具备真实深度和透视效果,帧数可长达 1000 帧。
该模型结合了传统虚拟相机的控制能力与生成式 AI 的创造力,支持用户自定义相机轨迹及多种动态路径(如螺旋、推拉变焦、平移等)。不过,在处理包含人类、动物或动态纹理(如水面)的图像时,模型可能会出现质量下降的情况。
使用入口:前往观看在线演示(huggingface.co/spaces/stabilityai/stable-virtual-camera)。

https://stable-virtual-camera.github.io
【应用】
Cursor
Claude 3.7 Max 模式上线
Claude 3.7 Max 是基于 Claude 3.7 Thinking 模型开发的高级版本,专为解决复杂代码难题而设计。它拥有 200K 的超大上下文窗口,可一次性加载并处理大量代码,适合复杂项目和大规模代码编辑。此外,单次链式操作中工具调用次数上限提升至 200 次,让开发者能更高效地进行大规模代码编辑和上下文分析。
不过,Claude 3.7 Max 采用按用量付费模式,每次请求(prompt)和每次工具调用(tool call)均收费 0.05 美元。
从实现逻辑上来看,这个 MAX 版本像是 Cursor 预置的一个工作流,而不是 Claude 的新版本模型
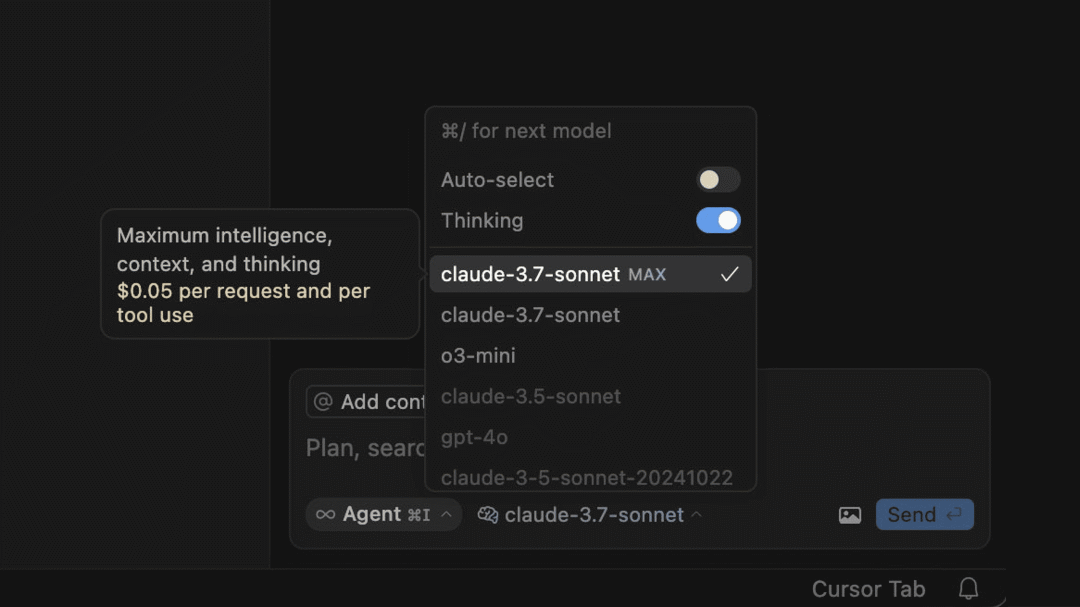
https://forum.cursor.com/t/max-mode-for-claude-3-7-out-now/65698
【应用】
Windsurf
Wave 5 重磅更新,Windsurf Tab 功能升级
Windsurf Wave 5 的更新带来了全新的 Windsurf Tab 功能,支持类 Cursor 的 tab 补全、导入、跳转和多行补全,并且提升了上下文感知能力、质量和速度。
终于补齐了一个大短板

https://codeium.com/blog/windsurf-wave-5
【3D】
群核科技
SpatialLM 空间理解模型(开源)
SpatialLM 是一款空间理解模型,能够将手机拍摄的视频转化为三维空间布局信息,且支持自然语言交互。用户无需借助专业设备,仅用手机拍摄家中布局,便可生成包含三维坐标、尺寸参数、类别信息等在内的结构化 3D 场景数据。
群核科技属于「杭州六小龙」之一,因此本次开源也收获了更多关注。杭州六小龙是指总部位于杭州的六家科技创新企业,包括云深处科技、宇树科技、深度求索、游戏科学、强脑科技和群核科技。
使用入口:前往 HuggingFace 、Github、魔搭社区等平台下载部署。

https://manycore-research.github.io/SpatialLM | 🔍官方介绍
【机器人】
宇树科技
G1 人形机器人完成全球首次原地侧空翻 && 首次鲤鱼打挺
3月19日,宇树科技人形机器人 G1 成功完成全球首次原地侧空翻动作。G1 轻松完成原地侧空翻动作落地后仍保持平衡,在站立稳定性上表现亮眼。

https://www.bilibili.com/video/BV1v8QdYHEB4
3 月 21 日,G1 成功完成全球首次鲤鱼打挺动作,展示了 G1 在平衡控制、动力系统和机械结构上的高度技术突破。

https://www.bilibili.com/video/BV1nkXkYfEBX
3月20日
【模型】
百川智能 X 北京儿童医院 X 小儿方健康
福棠·百川(全球首个)儿科大模型发布
福棠·百川是全球首个儿科大模型,不仅覆盖了儿童常见病与疑难病症的立体化知识体系,还首创了儿科「循证模式」,能像专业儿科医生一样整合最佳医学证据,为患儿制定科学、个性化的诊疗方案。
此外,三家合作伙伴还共同打造了「福棠·百川」AI 儿科医生专家版、基层版两款应用,以更好提升基层医院的儿科服务能力,缓解基层优质儿科医疗资源不足的难题。
终于见到百川最新的消息了 👀

🔍官方介绍
【视频】
阶跃星辰
Step-Video-TI2V 图生视频模型(开源)
Step-Video-TI2V 图生视频模型,支持生成 102 帧、5 秒、540P 分辨率的视频,具备运动幅度可控和镜头运动可控两大核心特点,同时天生具备一定的特效生成能力,在动漫类任务上的效果尤其优异。
使用入口:开源;前往跃问视频官网(yuewen.cn/videos)或 跃问App 使用。
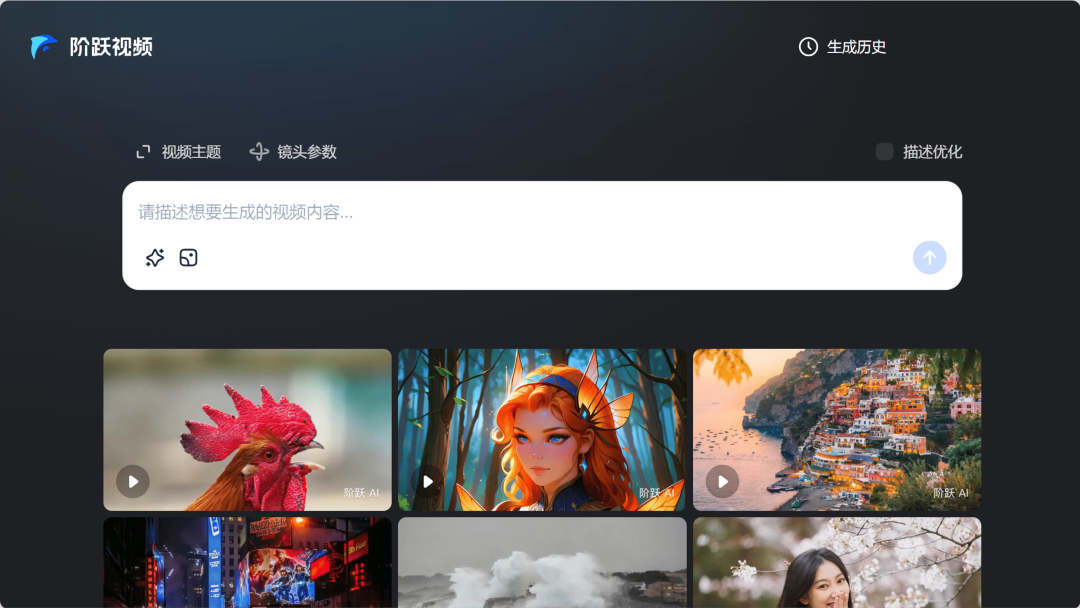
https://github.com/stepfun-ai/Step-Video-TI2V | 🔍官方介绍
3月21日
【模型】
腾讯
混元 T1 深度思考模型发布并上线
混元 T1 是一款能秒回、吐字快、擅长超长文处理的推理模型。它采用了 Hybrid-Mamba-Transformer 融合模式,是工业界首次将混合 Mamba 架构无损应用于超大型推理模型,显著降低了训练和推理成本。
使用入口:前往元宝 App 和 ima App 体验;前往腾讯云调用 API。
速度很快,价格很便宜,智力也不错,综合性价比极高 👍
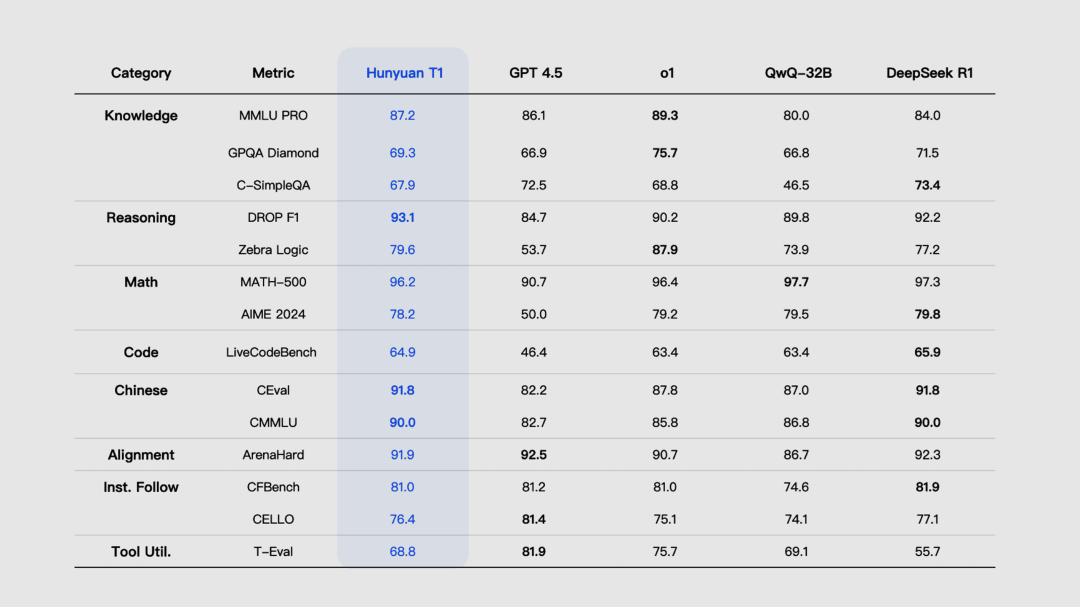
https://llm.hunyuan.tencent.com/#/blog/hy-t1 | 🔍官方介绍
【音频】
OpenAI
GPT-4o-transcribe 和 GPT-4o-mini-transcribe 语音转文本模型
GPT-4o-Transcribe 和 GPT-4o-Mini-Transcribe 是 GPT-4O 模型的升级版,语音转录性能出色。与之前的 Whisper 模型相比,它们在多种行业基准测试中词错误率更低,能更精准地捕捉语音细节。
GPT-4o-mini-tts 文本转语音模型
GPT-4o-Mini-TTS 模型可通过文本提示精准控制生成语音的情感、口音、音调、语气等。感兴趣的用户可前往演示网站 OpenAI FM(OpenAI.fm)进行测试。
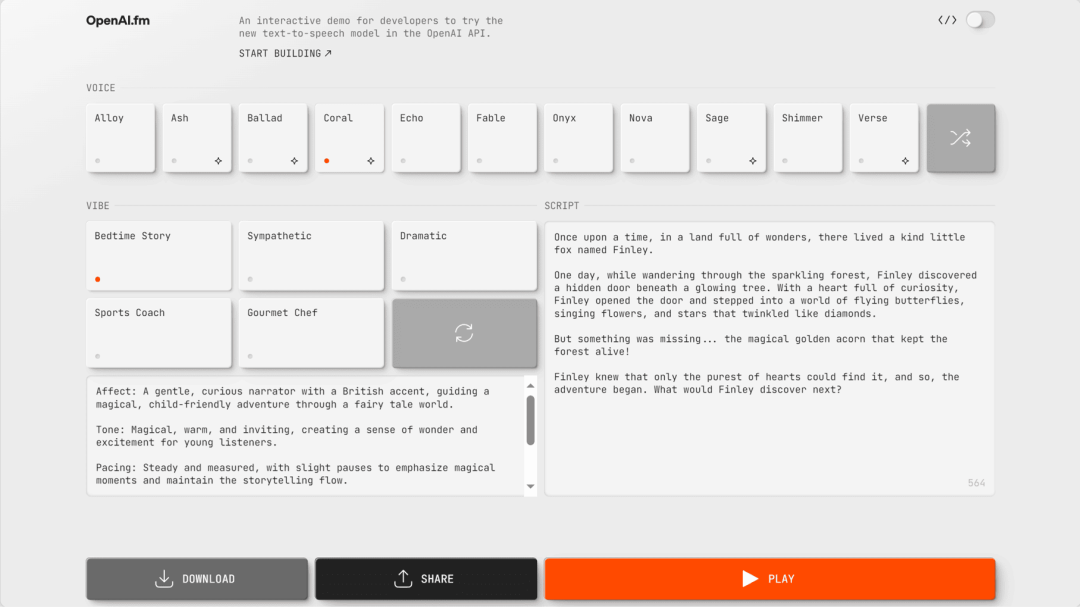
https://openai.com/index/introducing-our-next-generation-audio-models
3月22日
【应用】
Anthropic
Claude 可以联网
用户在个人设置中开启网页浏览功能后,Claude 会自动启用联网搜索能力。它会为从互联网获取的信息提供引用,方便用户核实来源,确保信息的准确性和透明度。目前,该功能仅向美国地区的付费用户开放,未来将逐步向免费用户开放。
相比国产产品,这个功能来的有点太迟了 🧭

https://www.anthropic.com/news/web-search
Claude Code 辅助编程应用取消 WaitList 可以直接使用
Claude Code 是一款智能编码工具,可在终端运行,无缝集成到开发环境,无需额外服务器或复杂设置,能有效简化工作流程。3 月 22 日起,Claude Code 辅助编程应用取消等待名单,可直接使用。
https://docs.anthropic.com/en/docs/agents-and-tools/claude-code/overview
3月23日
【融资】
Browser Use
完成 1700 万美元种子轮融资
Browser Use 完成 1700 万美元种子轮融资,资金将主要用于巩固其在 Web 自动化领域的技术优势。本轮融资由 Felicis Ventures 领投,Paul Graham、A Capital、Nexus Venture Partners 等知名投资方参投。
自开源以来,Browser Use 广受开发者欢迎,其 GitHub 仓库迅速收获超 5 万星标。目前,包括大热产品 Manus 在内的多家企业已采用其解决方案。
本质还是 CodeAct 的思想,通过 AI 编写 JS 代码,再去操作网页

https://browser-use.com/posts/seed-round
3月24日
【应用】
百度
秒哒 无代码应用开发平台上线
秒哒是一款智能无代码开发工具,只需用自然语言描述需求,就能自动生成完整功能代码,并支持多轮迭代修改。平台内置了策划、设计、开发等十余个专业领域的 AI 智能体,可根据项目需求灵活组建虚拟开发团队,实现高效协同。
使用入口:前往秒哒官网(miaoda.baidu.com)体验。
测试了一下,发现连使用代码去修改的机会都没有,是不是有点激进了 ❓
🔍官方介绍
3月25日
【模型】
Gemini 2.5 Pro(实验版)多模态推理模型发布
Gemini 2.5 Pro Experimental 推理模型,支持文本、图像、音频、视频及代码的多模态输入,上下文窗口已达 100 万 token,并计划未来拓展至 200 万 token,以更好地应对复杂跨模态任务。
该模型具备独特的「思维链推理」能力,在处理数学、科学等多步逻辑推导任务时,能通过系统化思考生成解决方案,显著提升准确性。在多项权威测试中,它均展现出领先优势,堪称谷歌目前最智能的模型。
使用入口:已上线 Google AI Studio 和 Vertex AI 云平台。
对标 Claude 3.7 Sonnet
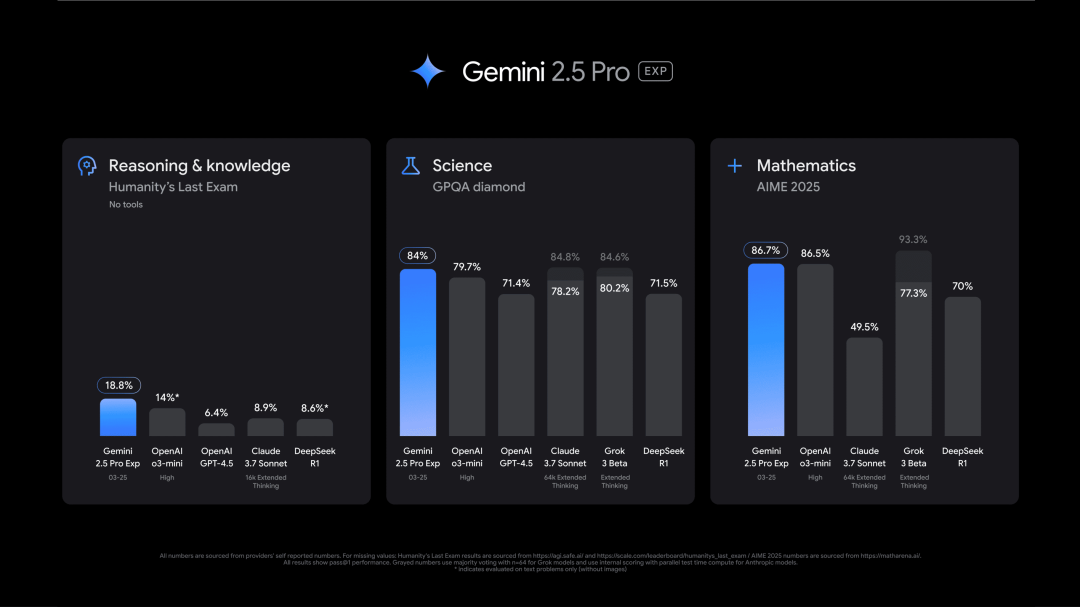
https://blog.google/technology/google-deepmind/gemini-model-thinking-updates-march-2025
【模型】
阿里巴巴
Qwen2.5-VL-32B 多模态模型(开源)
Qwen2.5-VL-32B-Instruct 在视觉语言理解和数学推理方面表现卓越,不仅能精准解析复杂图像,还能高效处理几何分析和数学难题。与同规模的 Mistral-Small-3.1-24B 和 Gemma-3-27B-IT 相比,其性能优势明显,甚至在某些领域超越了更大规模的 Qwen2-VL-72B 模型。
使用入口:开源;前往 Qwen Chat 官网(chat.qwen.ai)使用。
很适合本地部署来做 OCR 任务
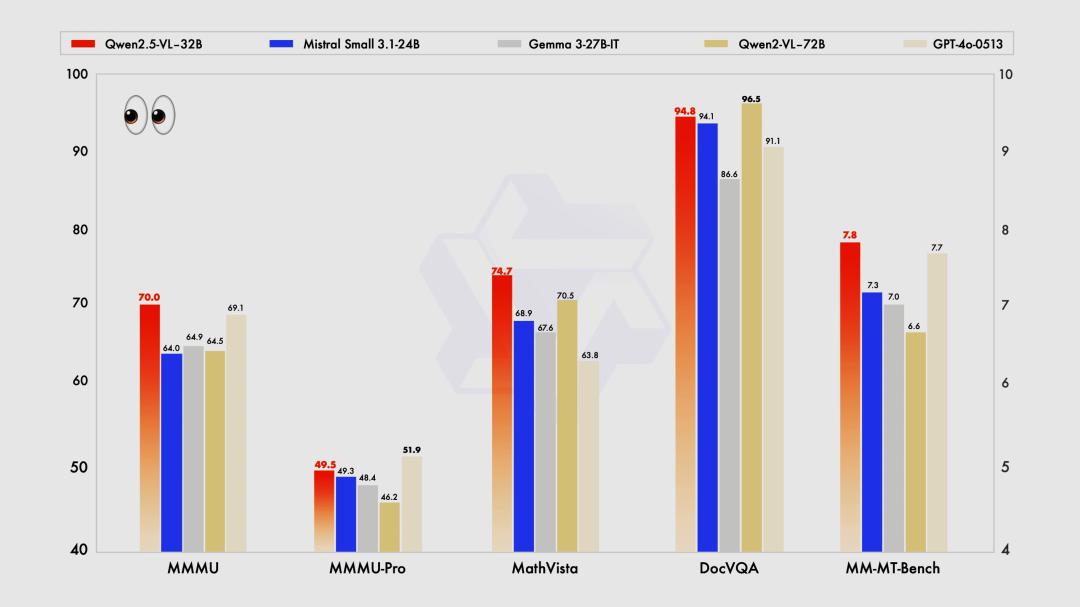
https://qwenlm.github.io/blog/qwen2.5-vl-32b
【模型】
DeepSeek
DeepSeek-V3-0324 模型更新(开源)
DeepSeek-V3-0324 模型在训练过程中借鉴了 DeepSeek-R1 的强化学习技术,显著提升了推理能力,在数学和代码类评测中的表现已超越 GPT-4.5。开源非推理模型新的里程碑时刻。
使用入口:登录官方网站(chat.deepseek.com)、App、小程序进入对话界面后,关闭「深度思考」即可体验;API 接口和使用方式保持不变。
期待基于 v3-0324 训练的新版 R1(会不会叫 R2 呢)
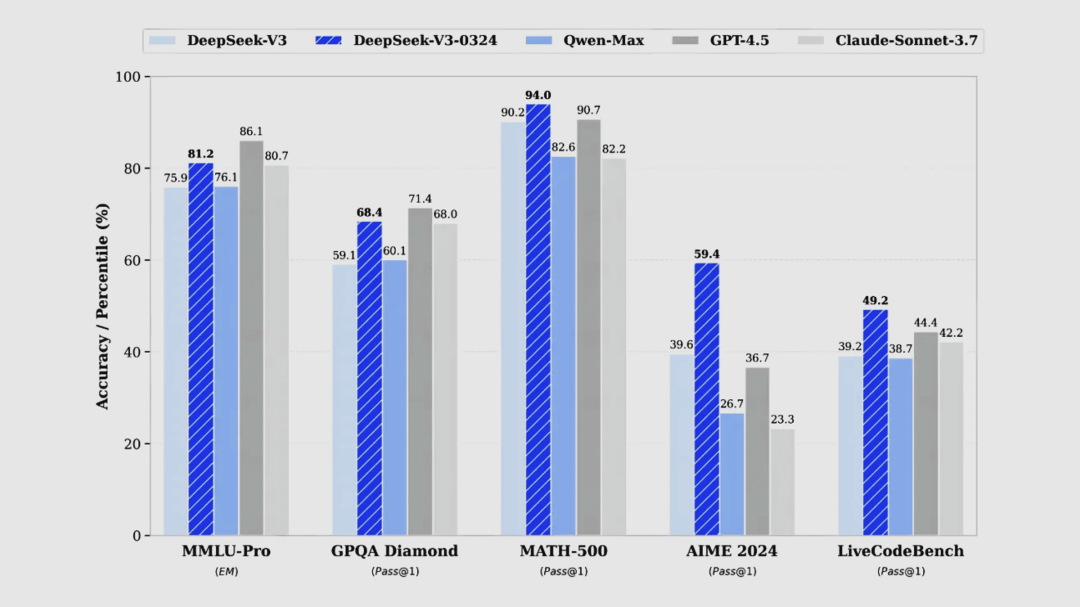
https://api-docs.deepseek.com/zh-cn/news/news250325 | 🔍官方介绍
【模型】
RWKV 元始智能
RWKV-7-G1 0.4B 推理模型(开源)
RWKV-7-G1 0.4B 是一款轻量级推理模型,参数仅 0.4B,可流畅运行于中低端设备。它支持超过 100 种语言和长文本处理,专为边缘计算优化,具有内存占用低、计算高效的特点,非常适合本地 AI 应用、物联网设备及多模态场景部署。
使用入口:开源;可以 Hugging Face 或者魔搭试用 Demo,或者下载 App(内测阶段)。
Transformer 的挑战者至今还未成规模
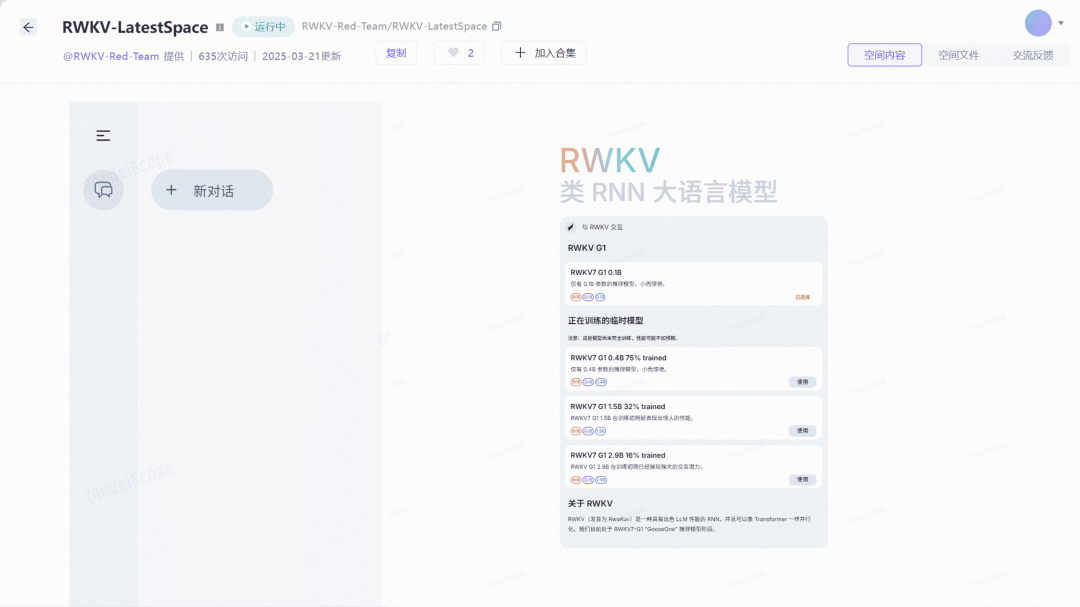
🔍官方介绍
【图像】
Reve
Reve Image(Halfmoon)图像生成模型
Halfmoon 模型登顶 Artificial Analysis 图像生成模型排行榜,超越此前大热的 Recraft v3。3 月 25 日,Reve 公司正式发布该模型,定名为 Reve Image。
Reve Image 支持文生图与图生图功能,不仅能精准理解复杂文本描述,还能通过简单指令修改图像。 其生成的图像色彩鲜明、光影细腻、细节丰富,并具备出色的文字融合能力,可精准控制字体、大小和颜色等样式。
使用入口:前往 Reve 官网(preview.reve.art)体验。
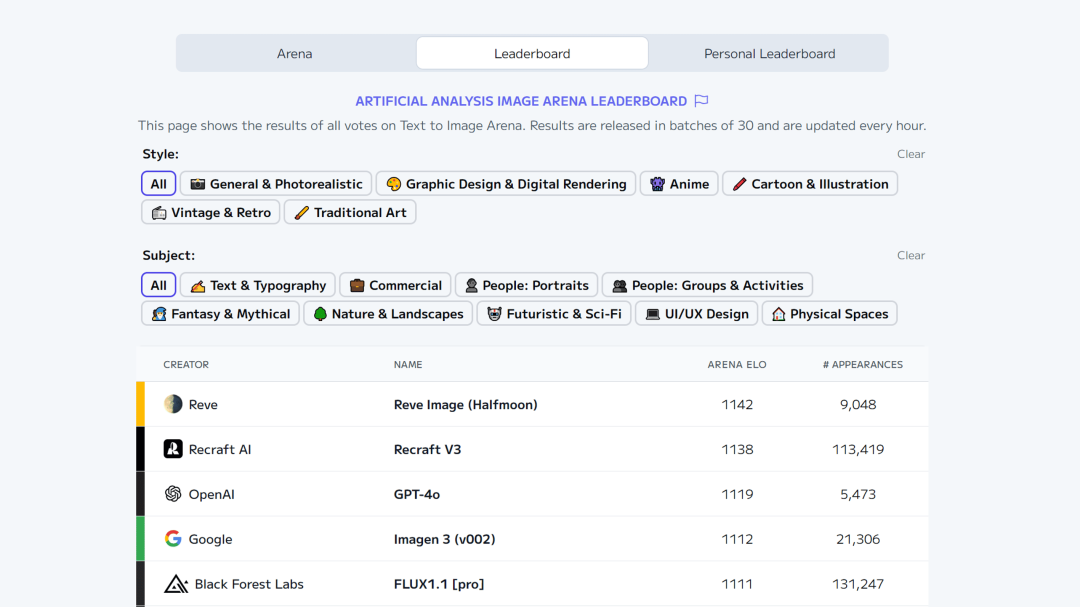
https://artificialanalysis.ai/text-to-image/arena?tab=Arena
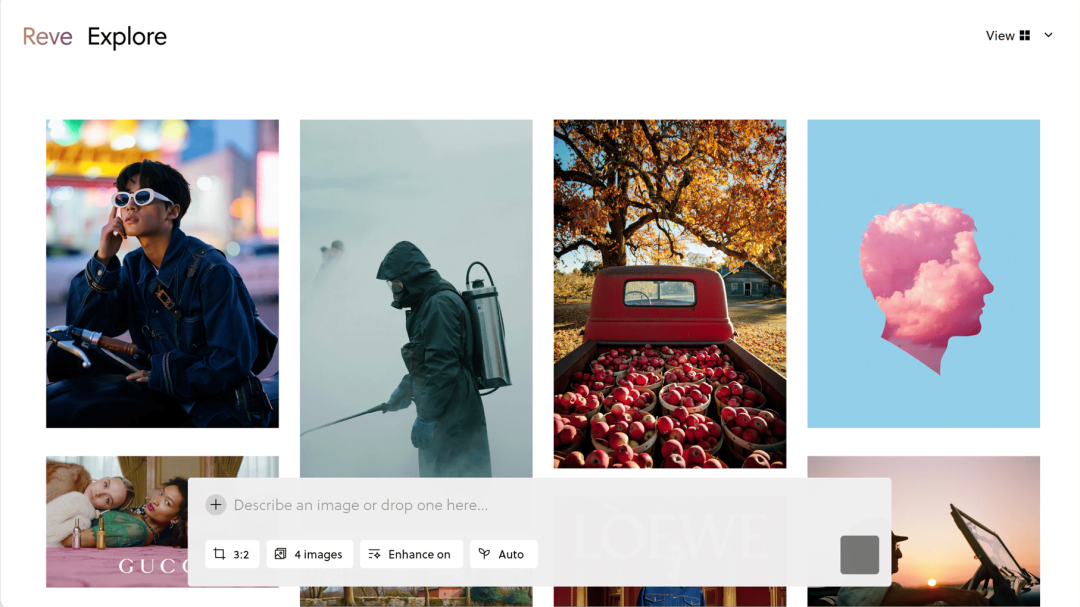
https://x.com/reveimage/status/1904211082870456824
3月26日
【模型】
OpenAI
GPT-4o 图像生成功能上线,吉卜力风格图像爆火全球
GPT-4o 基于原生的多模态能力,能够精准生成包含复杂文本的图像,支持从写实风格到艺术插图的多种风格,能处理复杂的用户指令,并保持一致性,还能通过多轮对话逐步调整和完善图像。
使用入口:该功能已集成到 ChatGPT 中,用户在对话中输入生图请求即可使用这一功能。API 将在未来几周内提供。
全面超越 Gemini 生图能力,给大众秀了一把全模态模型的能力 👏

https://openai.com/index/introducing-4o-image-generation | 🔍测评
【音频】
昆仑万维
Mureka V6 音乐生成模型 && Mureka O1 音乐推理模型
Mureka V6 是基座模型最新版本,支持纯音乐生成和 10 种语言的 AI 音乐创作。该模型采用自研的 ICL(上下文学习)技术,优化了声场和人声质感,使混音更加专业。
Mureka O1 是基于 V6 的推理优化版本,首次在 AI 音乐领域引入思维链(CoT)技术,通过「生成-批判-优化」的多轮推理机制,大幅提升音乐的结构连贯性和乐器编排精准度。
使用入口:登录Mureka(mureka.ai)体验。
Suno 真正的挑战者,还支持 API 接入 👍
🔍官方介绍
【新闻】
智源研究院
被美国商务部列入新一批「实体清单」
美国商务部工业与安全局(BIS)近日宣布将 50 余家中国科技企业和机构列入「实体清单(Entity List)」,其中包括北京智源人工智能研究院(BAAI)。这一决定已于 2025 年 3 月 28 日正式生效。
对此,智源研究院发布声明称,对作为民办非营利科研机构被加入实体清单表示震惊,强烈反对这一毫无事实依据的错误决定,并要求美国相关部门予以撤回。
另一种“官方技术认证”
https://www.federalregister.gov/documents/2025/03/28/2025-05427/additions-to-the-entity-list | 🔍智源回应
3月27日
【模型】
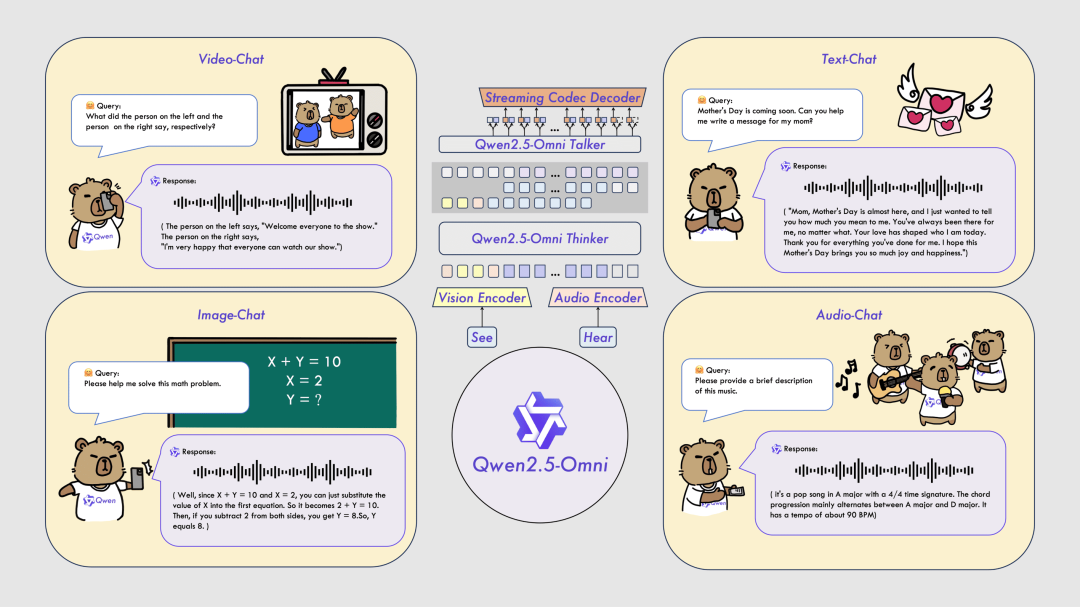
阿里巴巴
Qwen2.5-Omni-7B 端到端全模态大模型(开源)
Qwen2.5-Omni-7B 是一款轻量级全模态大模型,仅 7B 参数却性能卓越,在全模态任务评测中多项指标刷新纪录。它支持文本、图像、音频、视频等多模态输入,并能实时输出文本与自然语音。该模型体量小巧,易于部署,家用电脑即可流畅运行。
使用入口:开源;可以前往Qwen Chat(chat.qwenlm.ai)发起语音/视频聊天感受模型能力。
猜测这个模型很快也可以生成图片 🧐
https://qwenlm.github.io/zh/blog/qwen2.5-omni | 🔍官方介绍
【模型】
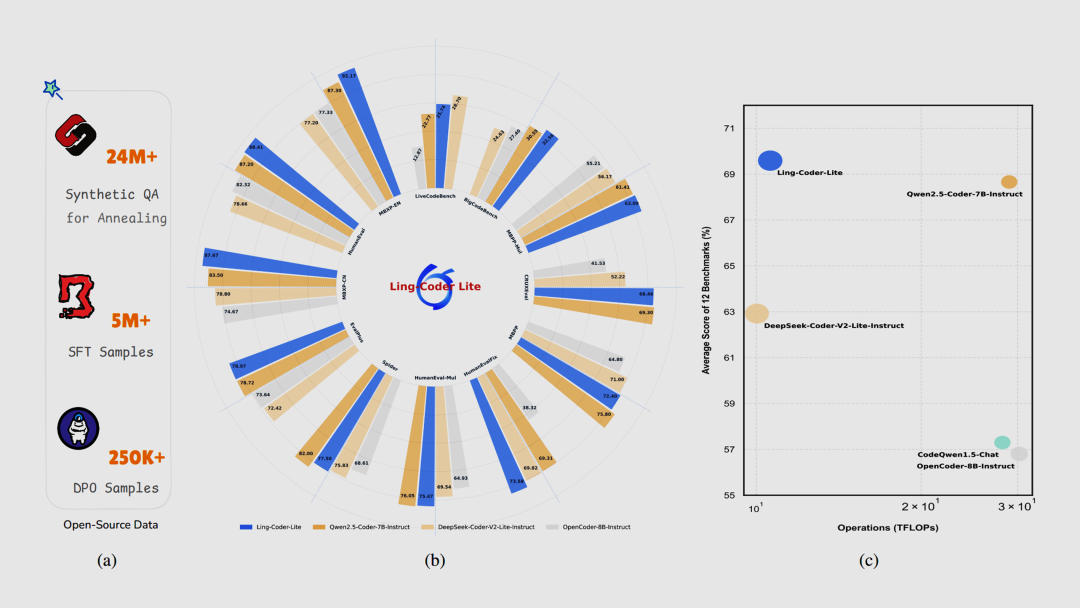
蚂蚁集团
Ling-Coder-Lite 和 Ling-Coder-Lite-Base 代码大模型(开源)
Ling-Coder 最新开源了 Ling-Coder-Lite 和 Ling-Coder-Lite-Base 两款模型。其中 Ling-Coder-Lite 总参数量达 16.8B,推理时激活参数仅需 2.75B,在保证更高效率的同时实现了更优效果。代码基准测试显示,其性能与同尺寸最佳模型(Qwen2.5-Coder-7B)相当。
使用入口:开源并同步发布技术报告;一并开源用于退火训练的 SyntheticQA、用于后训练 SFT 和 DPO 共计约 3000 万条数据。
和传说中的 Qwen3 规格有点像
https://github.com/codefuse-ai/Ling-Coder-Lite | 🔍官方介绍
【图像】
Ideogram AI
Ideogram 3.0 图像生成模型发布
Ideogram 3.0 模型在照片级真实感、文本渲染准确性、风格一致性等方面均有显著提升。其中,新增的「Style Reference」功能允许用户上传最多 3 张参考图像来指导生成内容的风格,同时「Random Style」功能则可让用户从 43 亿种预设风格库中随机探索独特风格。
使用入口:可以前往 Ideogram 官网(ideogram.ai)或 iOS App 应用体验。
与 4o 或 Gemini 的生图相比,有种古典模型的感觉了

https://about.ideogram.ai/3.0
【应用】
快手 – 可灵 AI
上线多款创意特效 && AI 音效
可灵上线了多款创意特效,如花花世界、魔力转圈圈、快来惹毛我、捏捏乐、万物膨胀等。上传图片即可生成 5 秒钟的动效视频。
AI 音效功能,可以基于文字提示词创作特定音效,可以从预置的多款音效中选择,也可以给指定视频进行配音。
使用入口:前往可灵 AI 官网(app.klingai.com)或手机 App 体验。
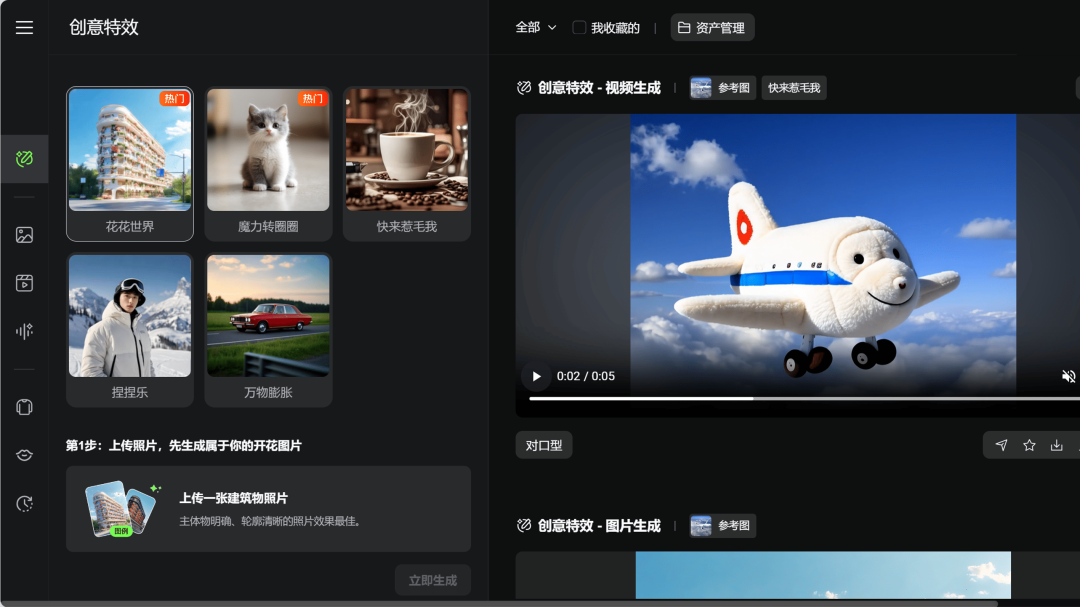
https://klingai.kuaishou.com/image-to-video/special-effects/new | 🔍官方介绍
3月28日
【模型】
阿里巴巴
QVQ-Max 视觉推理模型
QVQ-Max 视觉推理模型是 QVQ-72B-Preview 预览版(2024年12月发布)的首个正式版本。这款多模态模型具备强大的图像与视频理解能力,不仅能准确识别图片和视频里的视觉内容,还能进行深度分析、逻辑推理,并提供解决方案。
使用入口:前往 Qwen Chat 官网(qwen.ai) 体验。
期待 QWQ 和 QVQ 合并 ➕
https://qwenlm.github.io/blog/qvq-max-preview | 🔍官方介绍
【应用】
字节跳动
豆包深度思考实现「边想边搜」
豆包的「深度思考」功能将推理过程的思维链与搜索相结合,在思考过程中可根据推理多次调用工具、搜索信息。面对复杂问题或模糊条件时,它能进行多轮搜索,显著提升回复质量。
使用入口:前往豆包官网(doubao.com)或 App 体验。
此功能应该是通过模型后训练达到的,而不是简单的多轮调用,字节这次领先了 👍
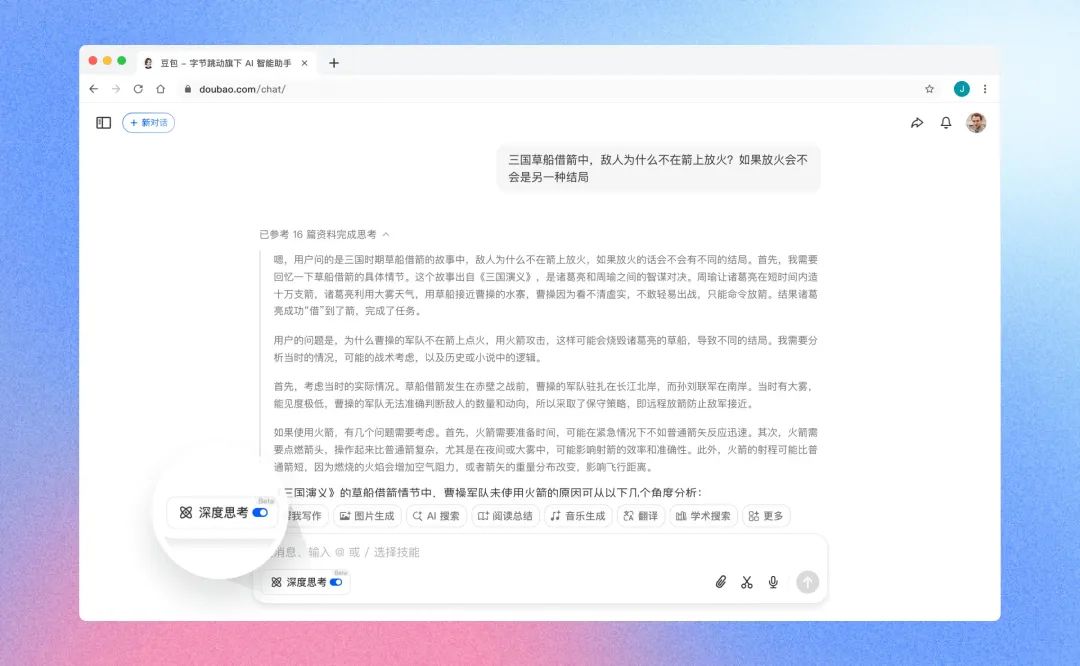
https://www.doubao.com/chat/update | 🔍官方介绍
【3D】
Meshy AI(胡渊鸣)
Meshy-V5(预览版)3D 生成模型上线
Meshy.ai 是一个 AI 驱动的 3D 建模工具,其核心功能包括从文本/图片生成高质量的 3D 模型,并能为这些模型快速添加高质量纹理。
升级后的 Meshy-5 可以适配任意光照环境,细节更高清,贴图与几何结构匹配更精准,可广泛应用于游戏开发、3D打印、影视动画、AR/VR/XR 等领域,帮助用户快速创建逼真的 3D 资产。
使用入口:前往官网(meshy.ai)试用。
AI 3D 生成越来越精细了 👍

https://x.com/MeshyAI/status/1905445314892628325
3月29日
【应用】
面壁智能
cpmGO 小钢炮超级助手 ,首个纯端侧智能助手
小钢炮超级助手 cpmGO 是首款纯端侧汽车助手,采用端云协同架构,实现舱内外全链路感知、决策与执行能力。它支持视觉、语音及多模态交互,提供端到端智能服务,涵盖泛化语音车控、GUI Agent、智能哨兵等全场景功能。其创新的端侧设计不仅突破弱网限制,更兼顾数据安全与低功耗高性能表现。

🔍官方介绍
【3D】
VAST
TripoSG 和 TripoSF 两款 3D 模型发布(开源)
TripoSG 和 TripoSF 两款模型在性能、细节表现、可控性上均有显著突破,进一步巩固了 VAST 在 AI 3D 生成领域的领先地位。
TripoSG 模型能将单张图片(草图/卡通/照片)转化为细节丰富的 3D 网格模型。TripoSF 模型专注于处理任意拓扑结构和高分辨率(最高可达 1024³)的 3D 建模任务。
使用入口:开源;访问 TripoSG 1.5B 参数版本的模型 Demo(huggingface.co/spaces/VAST-AI/TripoSG)。

https://github.com/VAST-AI-Research/TripoSF
3月31日
【模型】
智谱
AutoGLM 沉思上线,沉思模型 GLM-Z1-Rumination(即将开源)
AutoGLM 沉思是一项融合深度思考与自主操作的 AI Agent 功能。它能够进行复杂推理、实时检索信息,并协同使用多种工具(如网页浏览、数据整理、报告生成等),实现「边想边干」的智能化操作。
当前预览版主要支持 Research 场景,两周后即将推出的「虚拟机」版本将进一步提升 AI Agent 的实用能力。
使用入口:AutoGLM 沉思已经上线智谱清言 PC 客户端(autoglm-research.zhipuai.cn)。
在本地跑的“Manus”,对隐私更加友好
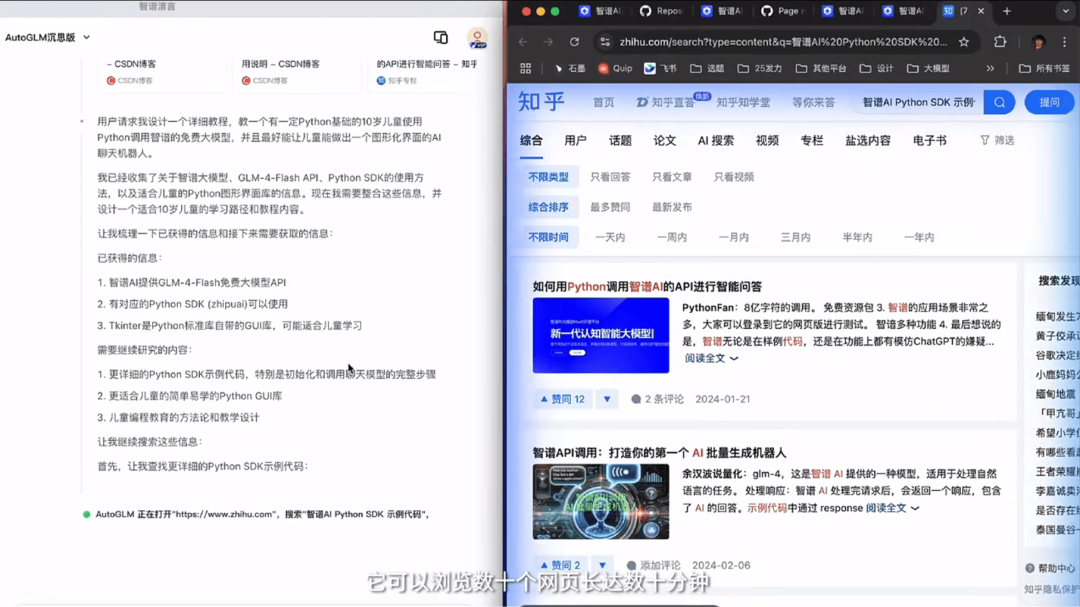
GLM-Z1-Rumination(沉思模型)是 AutoGLM 沉思功能的核心支撑,创新性地融合了实时搜索、动态工具调用、深度分析和自我验证,形成完整的自主研究流程,突破了传统 AI 仅依赖内部知识的局限。
使用入口:4 月 14 日正式开源。
据说只有 32B,可以本地部署,非常期待 👀

🔍官方介绍
【模型】
蚂蚁集团 X 清华大学(吴翼)
AReaL-boba 强化学习训练框架(开源)
AReaL-boba 是 AReaL(Ant Reasoning RL)项目的最新版本(0.2版本),其主要目标是提升训练效率和推理能力,同时大幅降低训练成本。例如,在数学推理任务中,该框架仅需 200 美元和 200 条数据即可复现 QwQ-32B 模型的顶尖性能。
使用入口:AReaL-boba 的框架代码、训练数据、模型权重及技术文档已经全部开源。
R1 复现的门槛更低了,以后可能就是计算机系的课后作业了
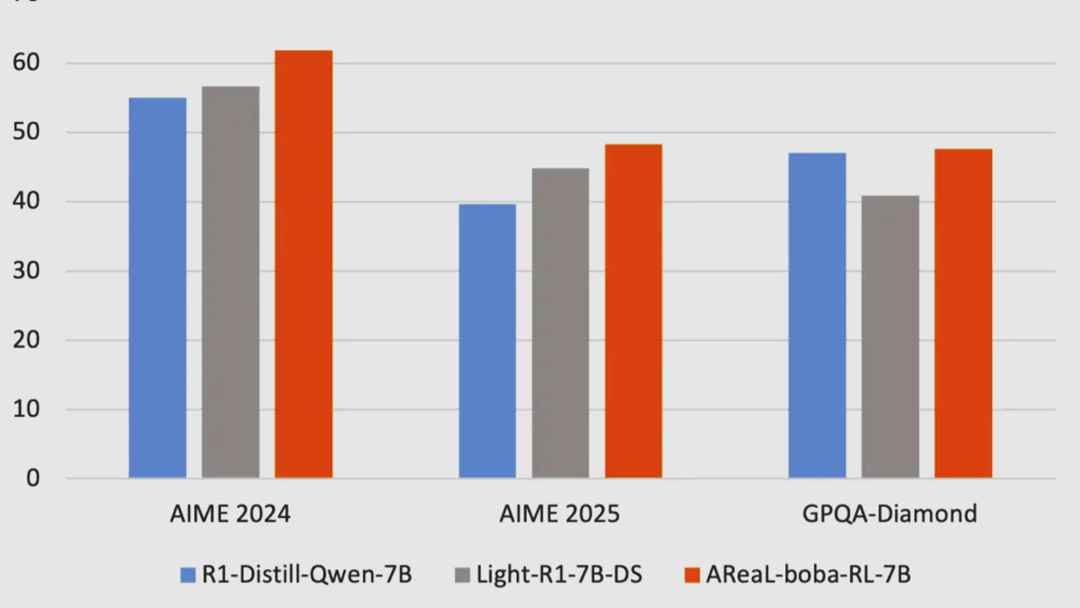
https://github.com/inclusionAI/AReaL | 🔍官方介绍
【模型】
中国科学院青藏所
洛书(全球首个)水-能-粮大模型
洛书大模型集成了科学模型「思源(Hydro Trace)」、通义千问推理模型 QwQ-32B、多模态模型 Qwen2.5-VL,可对特定区域在不同时间尺度的来水量和来源进行精准分析和预测。目前洛书大模型已在青藏高原及部分能源企业开展测试工作。
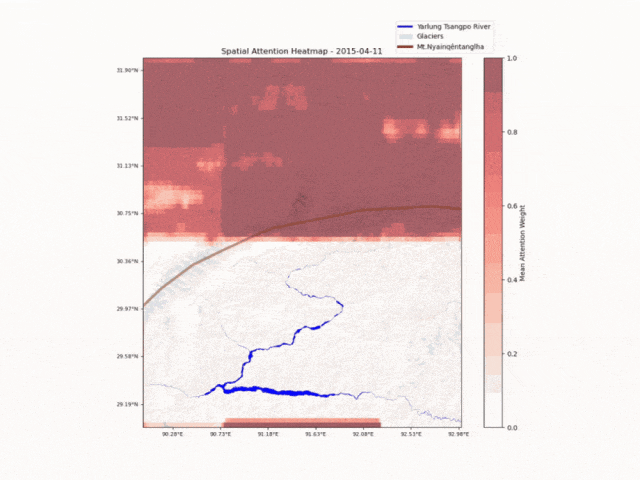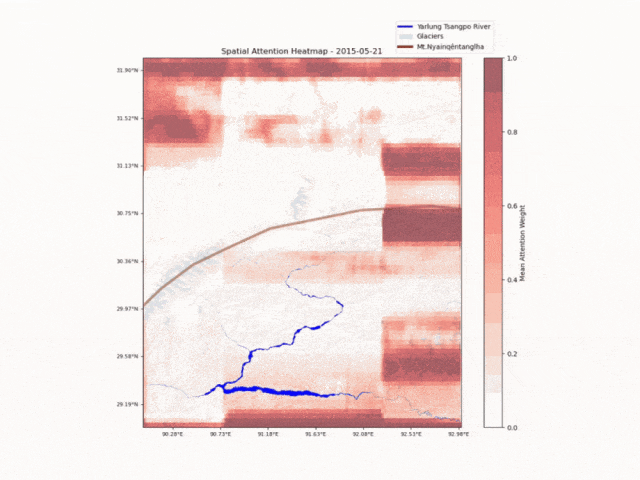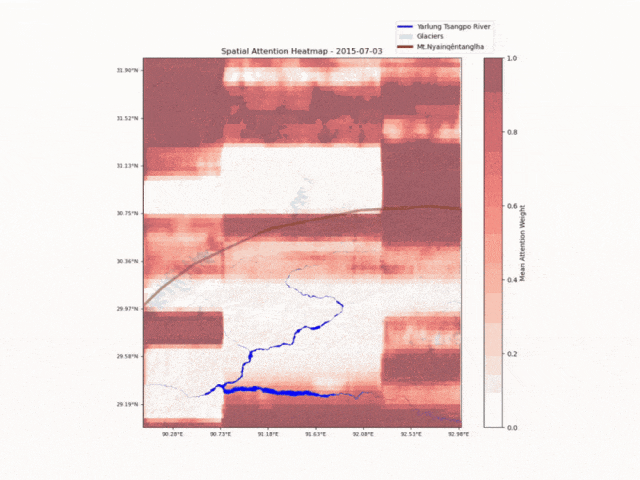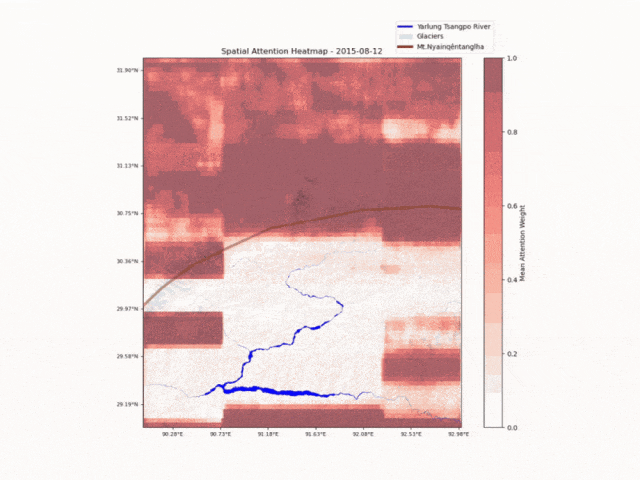
洛书大模型监测水文时空变化 | 🔍官方介绍
【视频】
Runway
Runway Gen-4 视频生成模型发布
Runway Gen-4 声称是目前最高保真的 AI 视频生成器之一,其核心优势在于能够生成主体、物体和风格一致且运动效果逼真的视频内容。
模型能够确保在不同镜头中保持角色、场景和物体的高度一致性,还可以能够精准模拟真实世界的物理规律,使得生成的视频不仅具有逼真的动作效果,还能展现复杂的场景交互。
使用入口:优先向公司的付费用户和企业客户推出。
暂时只支持图片生成视频

https://runwayml.com/research/introducing-runway-gen-4
(文:赛博禅心)