


来自DeepSeek和清华的一篇新研究《通用奖励模型的推理时扩展》(Inference-Time Scaling for Generalist Reward Modeling)找到强化学习新方法

以下是详细解读
DeepSeek的解法:Pointwise GRM + SPCT + Meta RM
他们提出了一套组合拳:
基础架构:Pointwise Generative Reward Model (GRM)
是什么:这是一种生成式的奖励模型,它不直接输出分数,而是生成评价性的文本(Critique),比如“回答1在逻辑上更清晰,但细节不足…最终得分[[8, 6]]分(满分10)”。分数是从这些文本里提取出来的
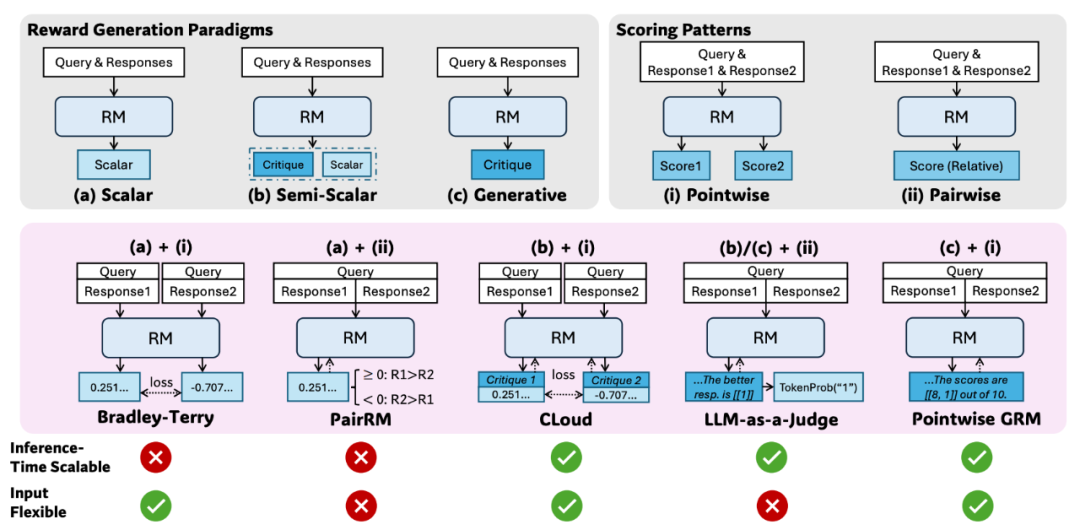
为什么选它:因为它天然灵活,既能评判单个回答,也能同时评判多个回答(Pointwise);而且生成的评价文本本身就有多样性,为推理时扩展提供了可能
核心训练方法:Self-Principled Critique Tuning (SPCT)
灵感来源:研究人员发现,如果给奖励模型提供一些好的评价原则(Principles),比如“评分原则1:逻辑连贯性(权重35%);原则2:信息完整性(权重20%)…”,奖励模型的评分质量能显著提升
SPCT怎么做:这是一种结合了拒绝采样微调(Rejective Fine-Tuning, RFT)和基于规则的在线强化学习(Rule-based Online RL的方法
-
• RFT (冷启动):先用一些有标注的数据微调GRM,让它学会生成符合格式的原则和评价,并过滤掉明显错误的评价。 -
• Online RL (核心):让GRM自己实时生成评价原则和对应的评价文本,然后根据预设规则(比如生成的评价结果是否与真实偏好一致)给予奖励信号,通过RL不断优化GRM,让它学会动态地、针对性地生成高质量的原则和准确的评价。这很关键,模型不再依赖固定的原则,而是学会了“自己思考该怎么评” -
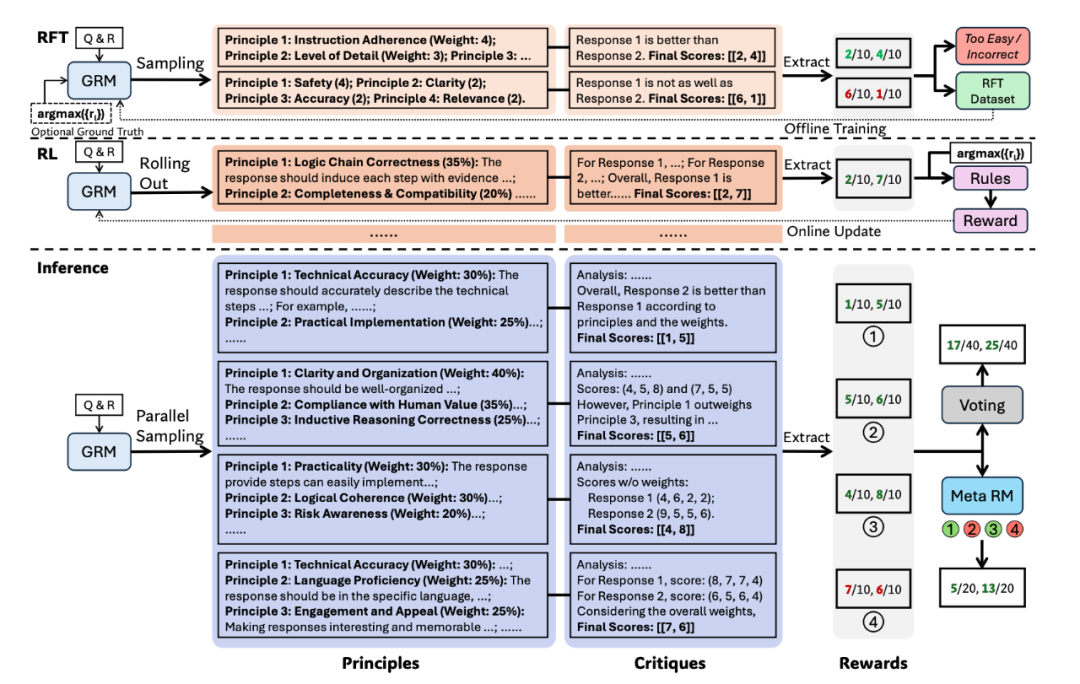
推理时扩展策略:并行采样 + 投票/Meta RM
并行采样与投票:推理时,让GRM对同一个问题和若干回答,并行生成 k 份不同的“原则+评价+分数”。因为每次生成的原则可能不同,评价角度也不同,最后把这 k 次评分(比如通过简单投票或加总)综合起来,得到一个更鲁棒、更精细的最终奖励。采样次数 k 越多,相当于考虑的评价维度越丰富,结果越好
Meta RM (裁判的裁判):为了解决并行采样中可能出现的低质量评价干扰结果的问题,他们还训练了一个元奖励模型(Meta RM)。这个Meta RM专门用来判断GRM生成的某一份“原则+评价”的质量高低。在最终投票时,可以用Meta RM筛选掉低质量的评价,或者给高质量的评价更高的权重,进一步提升扩展的效果
效果炸裂:推理扩展 > 训练扩展?
说了这么多,效果如何?
性能超越:基于Gemma-2-27B训练的DeepSeek-GRM-27B,在多个RM基准测试上,显著优于之前的同类方法(包括LLM-as-a-Judge、PairRM等),并且和Nemotron-4-340B、GPT-40这些强大的闭源模型表现相当
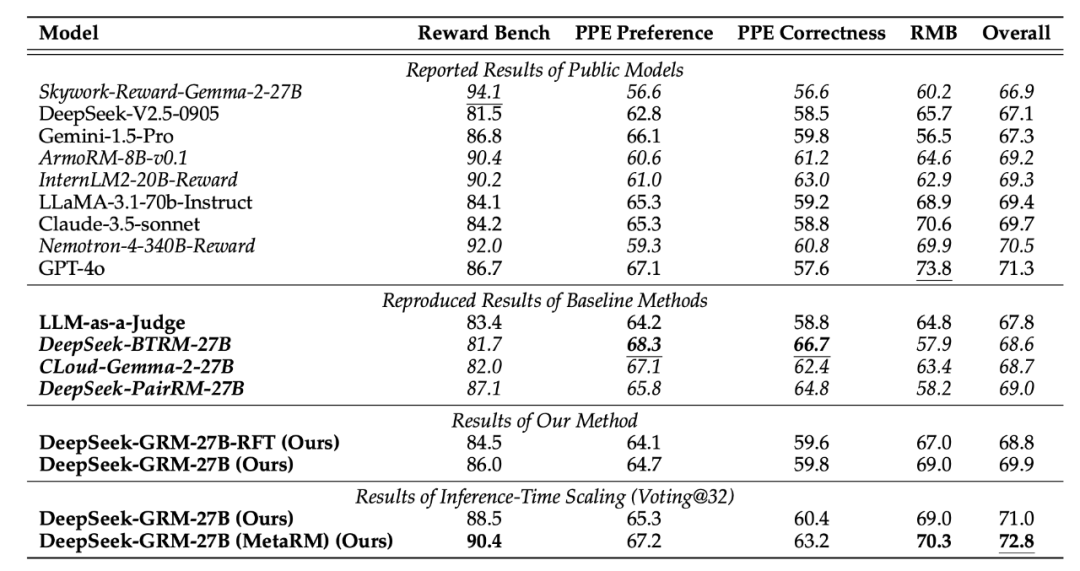
推理时扩展性超强:
通过增加采样次数 k,DeepSeek-GRM的性能持续提升,效果远超其他模型
最惊人的是:在Reward Bench测试集上,DeepSeek-GRM-27B通过推理时扩展(k=32采样+Meta RM引导投票),其性能竟然可以媲美甚至超过DeepSeek自家训练的671B MoE模型的零样本推理性能!这意味着,用增加推理计算量的方式,可以在小模型上达到甚至超越巨大模型的性能,这在成本和效率上意义重大!
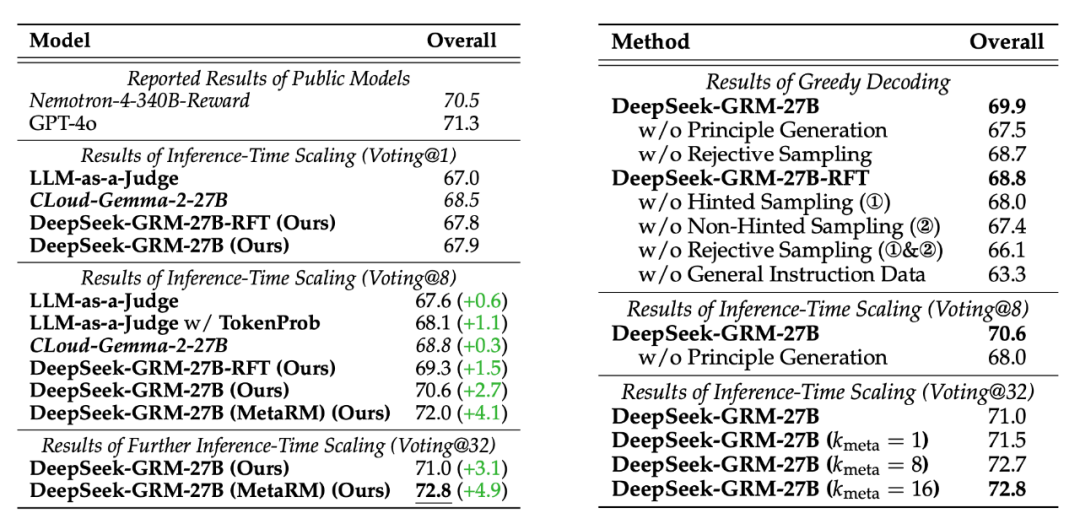
偏见更少:相比Scalar或Semi-scalar RM,GRM在不同类型的任务上表现更均衡,偏见更小
SPCT很关键:消融实验证明,SPCT中的原则生成和在线RL部分都至关重要。即使没有RFT冷启动,在线RL也能大幅提升性能
写在最后
给大家用deepseek来个可视化总结

参考:
https://arxiv.org/abs/2504.02495
⭐
(文:AI寒武纪)