


新智元报道
新智元报道
【新智元导读】DeepSeek新论文来了!在清华研究者共同发布的研究中,他们发现了奖励模型推理时Scaling的全新方法。
DeepSeek R2,果然近了。
最近,DeepSeek和清华的研究者发表的这篇论文,探讨了奖励模型的推理时Scaling方法。

论文地址:
https://arxiv.org/abs/2504.02495
现在,强化学习(RL)已广泛应用于LLM的大规模后训练阶段。
通过RL激励LLMs的推理能力表明,采用合适的学习方法,就有望实现有效的推理时可扩展性。
然而,RL面临的一个关键挑战,就是在可验证问题或人工规则之外的多种领域中,为LLMs获得准确的奖励信号。
是否有可能通过增加推理计算资源,来提升通用查询场景下奖励建模(RM)的能力,即通用RM在推理阶段的可扩展性呢?
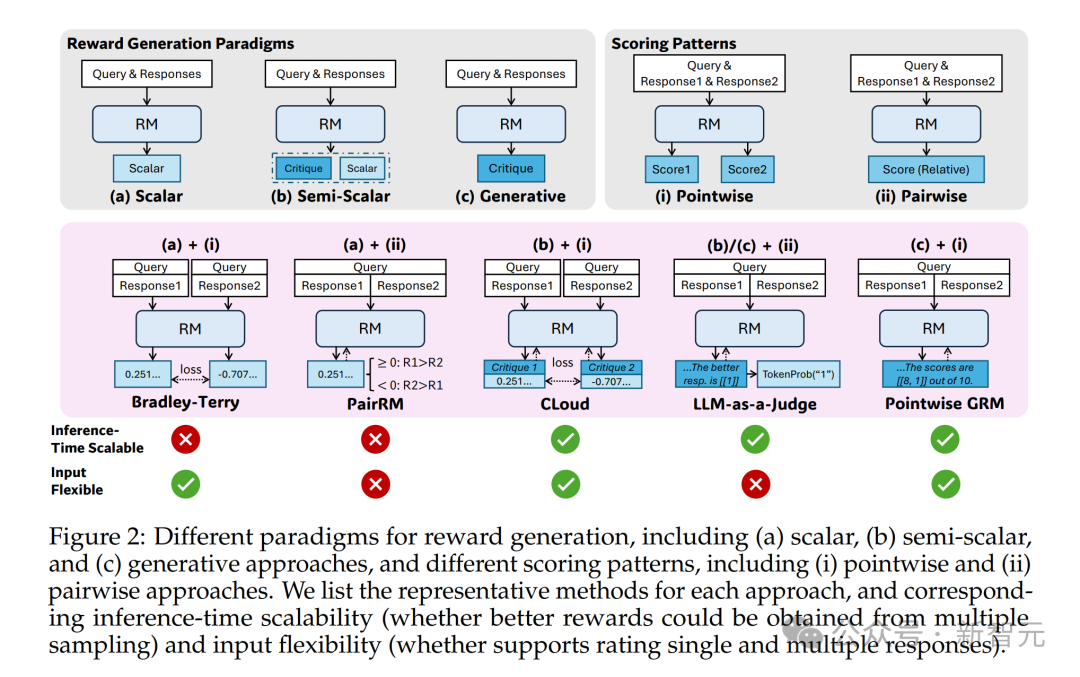
DeepSeek和清华的研究者发现,在RM方法上采用点式生成式奖励建模(Pointwise Generative Reward Modeling, GRM),就能提升模型对不同输入类型的灵活适应能力,并具备推理阶段可扩展的潜力。
为此,他们提出一种自我原则点评调优(Self-Principled Critique Tuning, SPCT)的学习方法。
通过在线RL训练促进GRM生成具备可扩展奖励能力的行为,即能够自适应生成评判原则并准确生成点评内容,从而得到DeepSeek-GRM模型。
他们提出了DeepSeek-GRM-27B,它是基于Gemma-2-27B经过SPCT后训练的。
可以发现,SPCT显著提高了GRM的质量和可扩展性,在多个综合RM基准测试中优于现有方法和模型。
研究者还比较了DeepSeek-GRM-27B与671B的更大模型的推理时间扩展性能,发现它在模型大小上的训练时间扩展性能更好。
另外,他们还引入一个元奖励模型(meta RM)来引导投票过程,以提升扩展性能。
总体来说,研究者的三个贡献如下。
1.提出了一种新方法——自我原则点评调优(SPCT),用于推动通用奖励建模在推理阶段实现有效的可扩展性,最终构建出DeepSeek-GRM系列模型。同时引入了元奖励模型(meta RM),进一步提升推理扩展性能。
2.SPCT显著提升了GRM在奖励质量和推理扩展性能方面的表现,超过了现有方法及多个强劲的公开模型。
3.将SPCT的训练流程应用于更大规模的LLM,并发现相比于训练阶段扩大模型参数量,推理阶段的扩展策略在性能上更具优势。
SPCT
受到初步实验结果的启发,研究者为点式生成式奖励模型(pointwise GRM)开发了一种新颖的方法,使其能够学习生成具有适应性和高质量的原则,以有效指导点评内容的生成。
这一方法被称为自我原则点评调优(Self-Principled Critique Tuning,SPCT)。
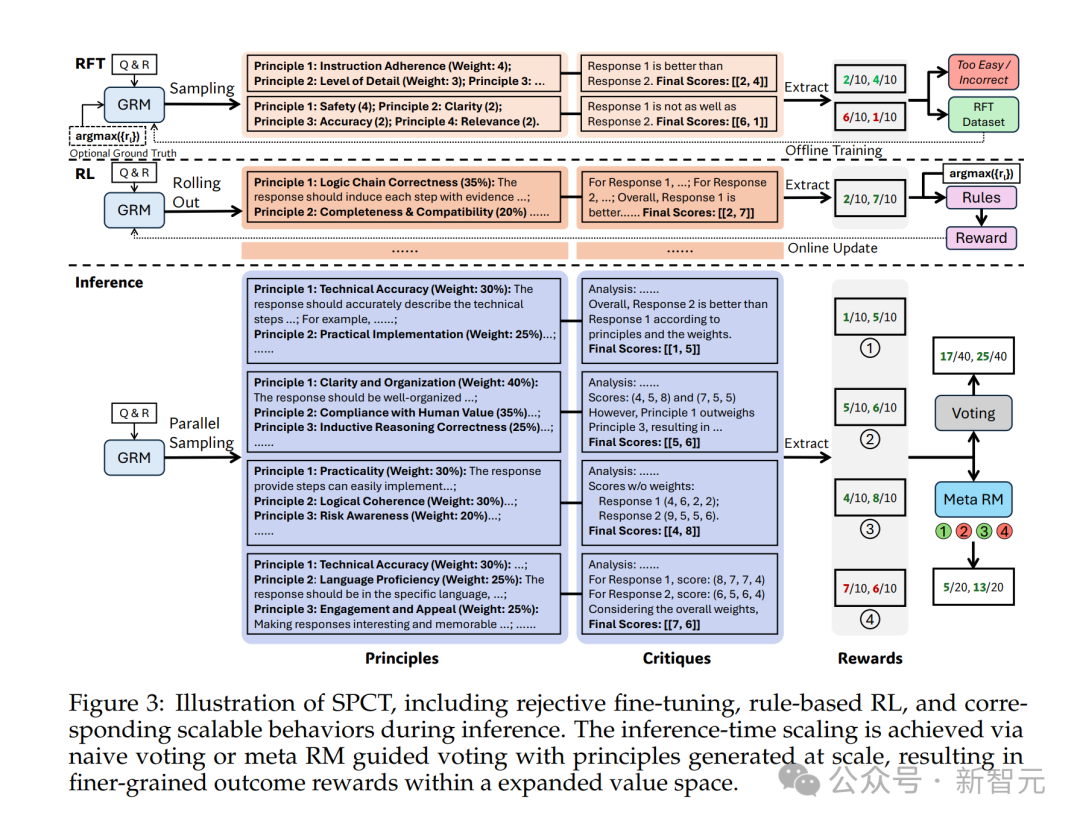
如图3所示,SPCT包括两个阶段。
1.拒绝式微调(rejective fine-tuning)作为冷启动阶段
2.基于规则的在线强化学习(rule-based online RL),通过提升生成的原则和点评内容来强化通用奖励的生成过程。
另外,SPCT还可以促进GRM在推理阶段的可扩展行为。
将「原则」从理解转向生成
研究者发现,适当的原则可以在一定标准下引导奖励生成,这对于生成高质量奖励至关重要。
然而,在大规模通用奖励建模中,如何有效生成这些原则仍是一个挑战。
为此,他们提出将「原则」从一种理解过程解耦出来,转变为奖励生成的一部分,也就是说,不再将原则视为预处理步骤,而是纳入奖励生成流程中。
形式化地说,当原则是预定义时,原则可用于引导奖励生成。
研究者让GRM自行生成原则,并基于这些原则生成点评内容,形式化表达如下:
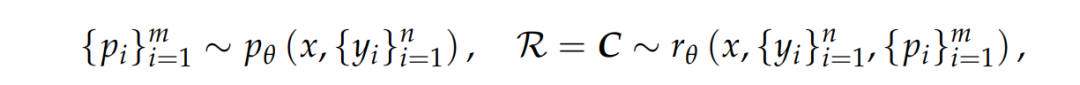
其中,p_θ是用于生成原则的函数,由参数θ表示,且与奖励生成函数r_θ共享同一个模型架构。
这一转变使原则能够根据输入问题及其回答内容进行动态生成,从而使奖励生成过程更加自适应。
此外,通过对GRM进行后训练,可进一步提升所生成原则与对应点评内容的质量与细致程度。
当GRM能够在大规模条件下生成多样化、高质量的原则时,其输出的奖励将更加合理且具备更高的细粒度,而这一能力正是推理阶段可扩展性的关键所在。
基于规则的强化学习
为了同时优化GRM中的原则与点评内容的生成,研究者提出了SPCT方法,它结合了拒绝式微调(rejective fine-tuning)与基于规则的强化学习(rule-based RL)。
其中,拒绝式微调作为冷启动阶段。
拒绝式微调(Rejective Fine-Tuning,冷启动)
这一阶段的核心思想是让GRM适应不同输入类型,并以正确的格式生成原则与点评内容。
与以往工作混合使用单个、成对和多个回答的RM数据并使用不同格式不同,研究者采用了点式GRM(pointwise GRM),以在相同格式下灵活地对任意数量的回答进行奖励生成。
在数据构建方面,除了通用指令数据外,研究者还从具有不同回答数量的RM数据中采样预训练GRM在给定查询与回答下的轨迹。
对于每个查询及其对应的回答,研究者执行了N_RFT次采样。
他们统一了拒绝策略:若模型预测的奖励与真实奖励不一致(错误),或该组查询与回答在所有N_RFT次采样中全部预测正确(太简单),则拒绝该轨迹。
形式化地,令r_i表示第i个回答y_i对查询x的真实奖励,预测得到的点式奖励
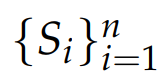
被认为是正确的,当且仅当:
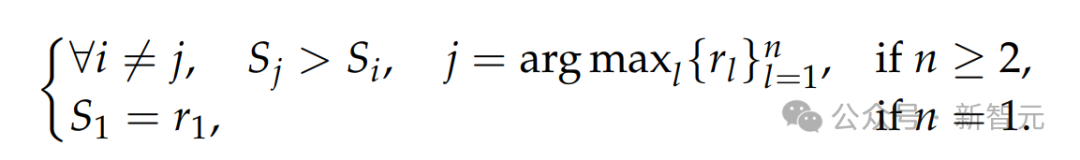
该条件保证真实奖励中只有一个最大值。
然而,正如以往研究所指出的,预训练的GRM在有限采样次数下,往往难以为部分查询及其回答生成正确的奖励。
因此,研究者引入了提示式采样(hinted sampling):将
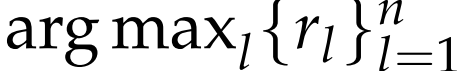
作为提示,附加到GRM的提示语中,以期提高预测奖励与真实奖励的一致性。
可以发现,与之前的研究不同,提示采样的轨迹在某些情况下会捷径式简化点评生成,特别是在推理任务中。
这表明:在线强化学习对于GRM仍是必要的,并具有潜在优势。
基于规则的强化学习
在SPCT的第二阶段,研究者使用基于规则的在线强化学习对GRM进一步微调。
具体而言,我们采用了GRPO的原始设定,并使用基于规则的结果奖励(rule-based outcome rewards)。
在rollout过程中,GRM根据输入查询与回答生成原则与点评,然后提取预测奖励并通过准确性规则与真实奖励进行对比。
与DeepSeek-AI不同的是,研究者不再使用格式奖励,而是采用更高的KL惩罚系数,以确保输出格式正确并避免产生严重偏差。
形式化地,对于第i个输出o_i(给定查询x和回答
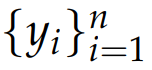
),其奖励定义为
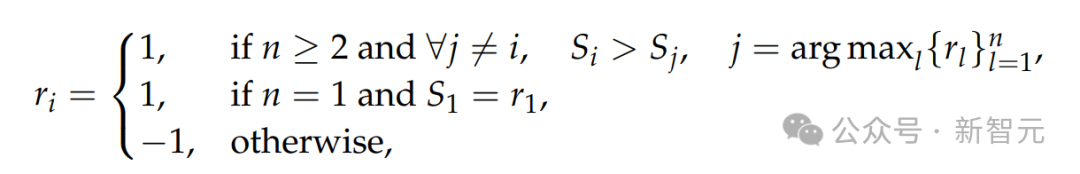
其中,点式奖励
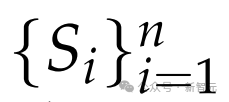
是从o_i中提取的。
该奖励函数鼓励GRM通过在线优化生成的原则与点评内容,正确地区分最优回答,从而提升推理阶段的可扩展性。
此外,这种奖励信号可无缝对接任何偏好数据集与标注的LLM回答。
SPCT的推理时Scaling
为了进一步提升DeepSeek-GRM在生成通用奖励上的性能,研究团队探索了如何利用更多的推理计算,通过基于采样的策略来实现有效的推理时扩展。
通过生成奖励进行投票
逐点GRM(pointwise GRMs)投票过程被定义为将奖励求和:
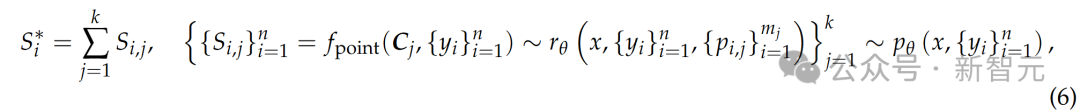
因为S_(i,j)通常被设定在一个小的离散范围内(比如{1,…,10}),所以投票过程实际上将奖励空间扩大了k倍,让GRM能生成大量原则(principles),从而提升最终奖励的质量和细腻度。
直观来说,如果把每个原则看作一种判断视角的代表,那么更多的原则就能更准确地反映真实分布,从而带来扩展的有效性。
值得一提的是,为了避免位置偏差并增加多样性,研究人员在采样前会对回答进行随机打乱。
元奖励模型引导投票
DeepSeek-GRM的投票过程需要多次采样,但由于随机性或模型本身的局限性,生成的某些原则和评论可能会出现偏见或者质量不高。
因此,研究团队训练了一个元奖励模型(meta RM)来引导投票过程。
这个meta RM是一个逐点标量模型,训练目标是判断DeepSeek-GRM生成的原则和评论是否正确。
引导投票的实现很简单:meta RM为k个采样奖励输出元奖励(meta rewards),然后从这些奖励中选出前k_meta(k_meta ≤ k)个高质量的奖励进行最终投票,从而过滤掉低质量样本。
奖励模型结果
不同方法和模型在RM基准测试上的总体结果如表2所示。
结果显示,DeepSeek-GRM-27B在整体性能上超过了基线方法,并且与一些强大的公开RM(如Nemotron-4-340B-Reward和GPT-4o)表现相当。
如果通过推理时扩展(inference-time scaling),DeepSeek-GRM-27B还能进一步提升,达到最佳整体结果。
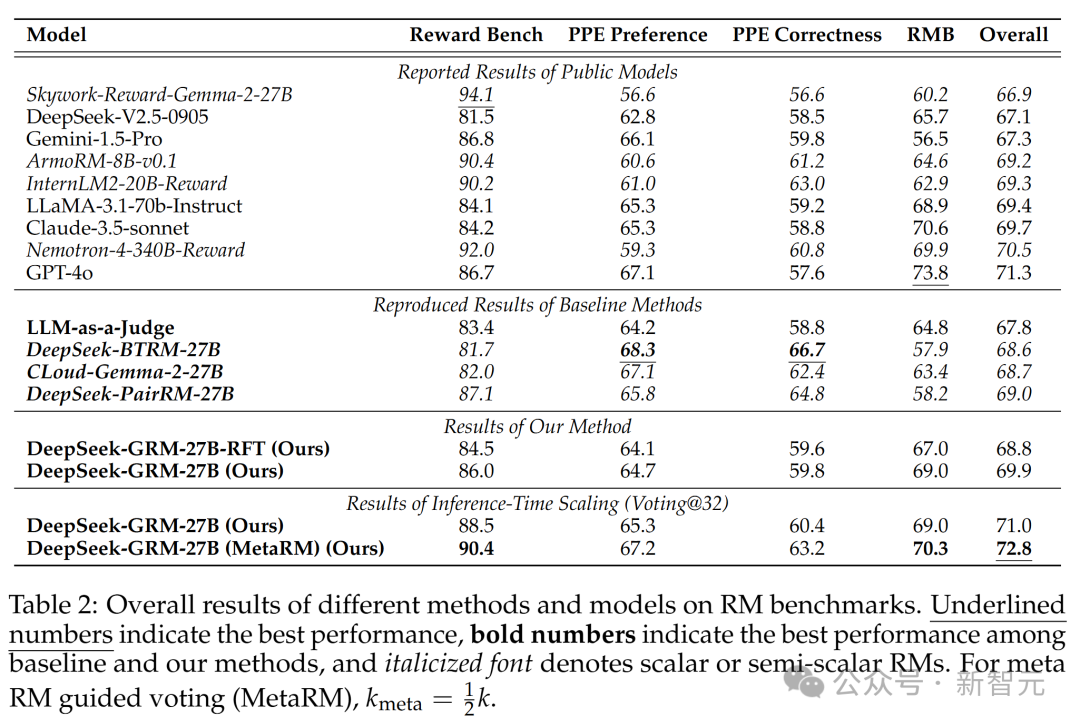
不同方法和模型在RM基准测试上的总体结果。下划线数字表示最佳性能,粗体数字表示基线方法和本文方法中的最佳性能,斜体字表示标量或半标量RM。对于meta RM指导的投票,k_meta = 1/2k
推理时扩展性
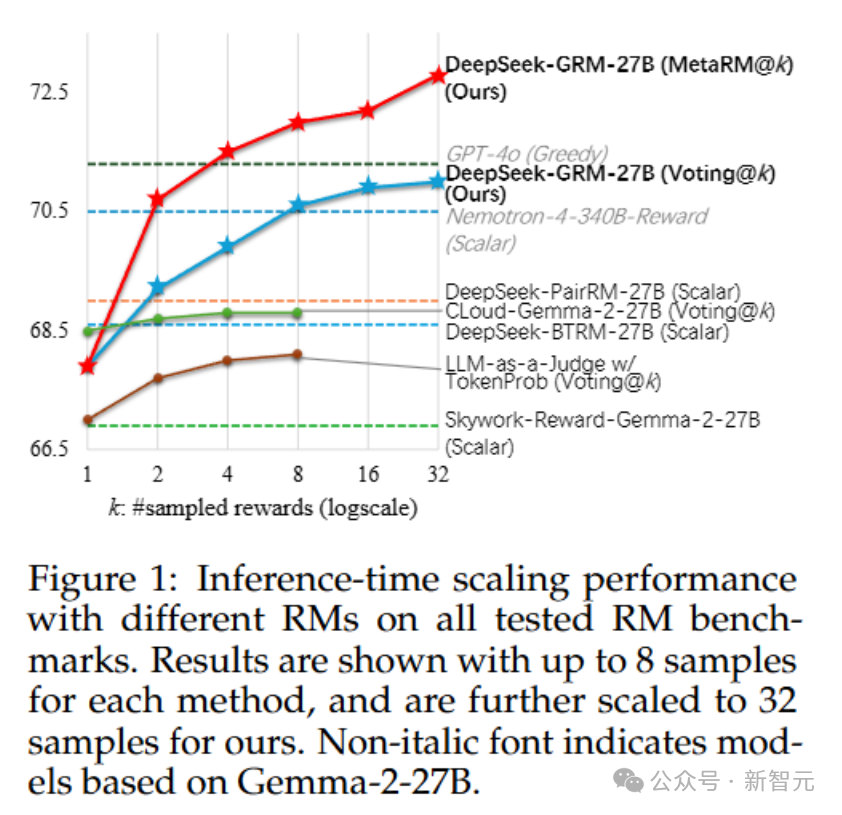
不同方法的推理时扩展结果如表3所示,整体趋势见图1。
研究人员发现,在最多8个样本的情况下,DeepSeek-GRM-27B的性能提升最高,超越了贪婪解码和采样结果。
随着推理计算量增加(最多32个样本),DeepSeek-GRM-27B展现出进一步提升性能的潜力。meta RM也在每个基准测试中证明了其过滤低质量轨迹的有效性。
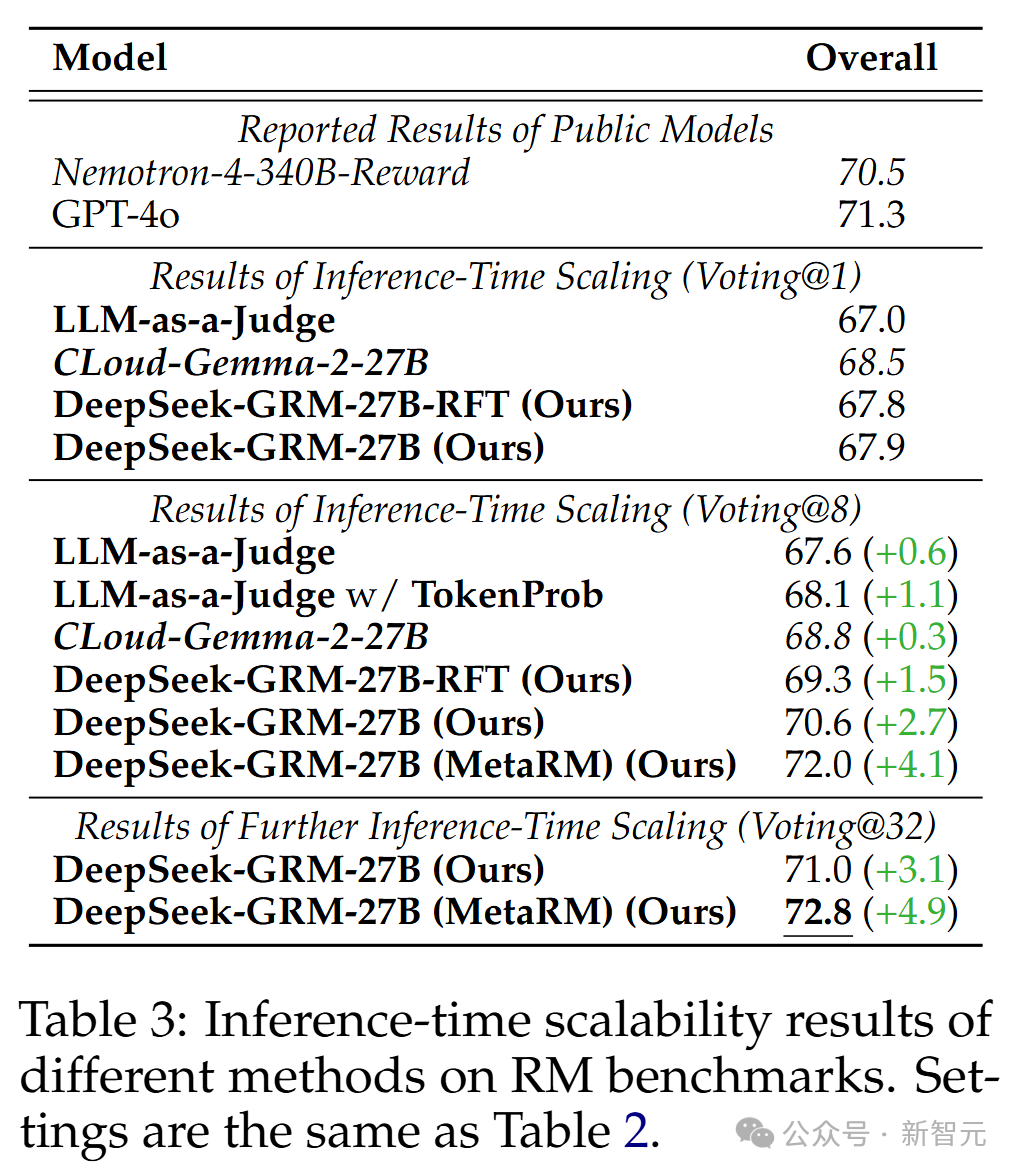
总之,SPCT提升了GRM的推理时扩展性,而meta RM进一步增强了整体扩展性能。
消融研究
表4展示了所提SPCT不同组件的消融研究结果。
令人惊讶的是,即使没有使用拒绝采样的评论数据进行冷启动,经过在线强化学习(online RL)后,通用指令调整的GRM仍然显著提升(66.1 → 68.7)。
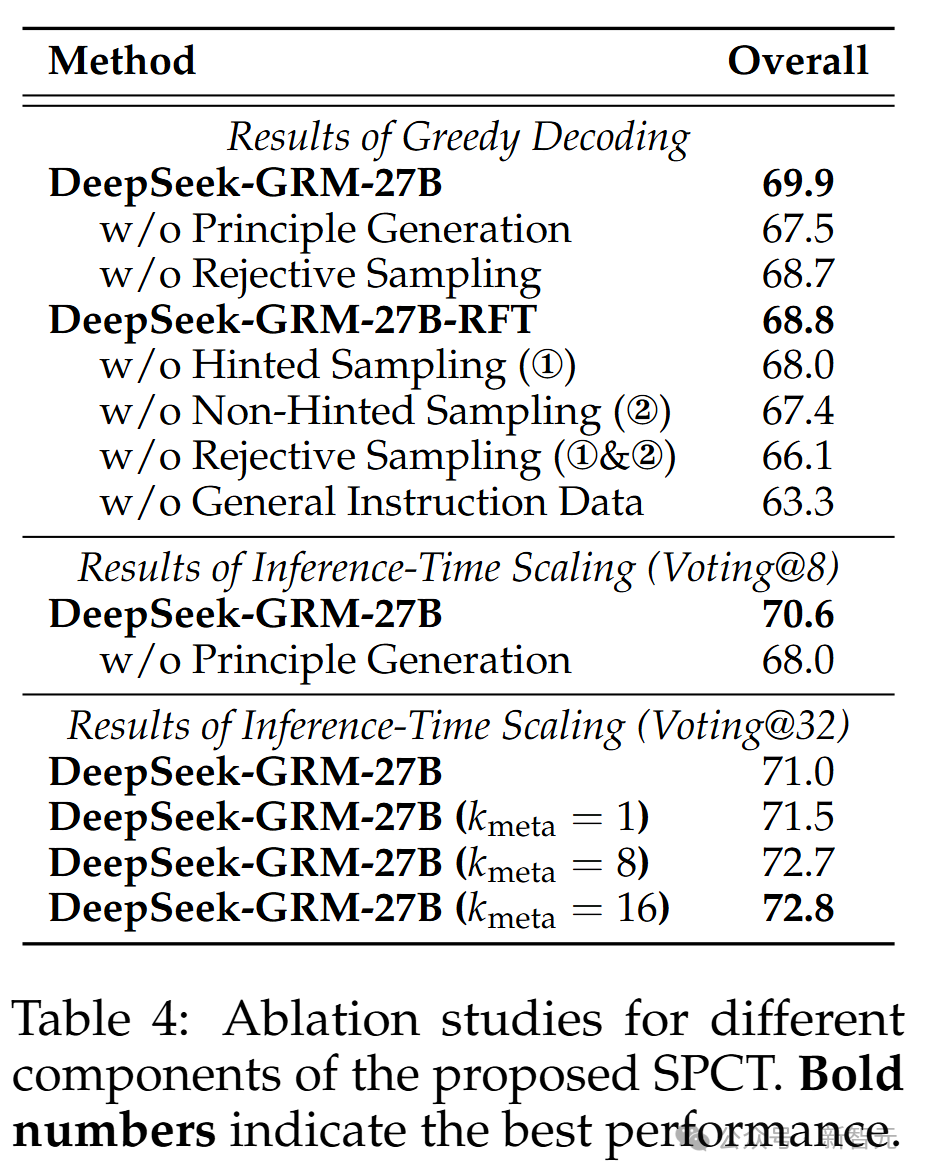
此外,非提示采样似乎比提示采样更重要,可能是因为提示采样轨迹中出现了捷径。这表明在线训练对GRM的重要性。
与之前研究一致,研究团队确认通用指令数据对GRM性能至关重要。他们发现,原则生成对DeepSeek-GRM-27B的贪婪解码和推理时扩展性能都至关重要。
在推理时扩展中,meta RM指导的投票在不同k_meta下表现出鲁棒性。
推理与训练成本扩展
研究团队进一步研究了DeepSeek-GRM-27B在不同规模LLM后训练下的推理时和训练时扩展性能。
模型在Reward Bench上测试,结果如图4所示。
他们发现,使用32个样本直接投票的DeepSeek-GRM-27B可以达到与671B MoE模型相当的性能,而meta RM指导的投票仅用8个样本就能取得最佳结果,证明了DeepSeek-GRM-27B在推理时扩展上的有效性,优于单纯扩大模型规模。
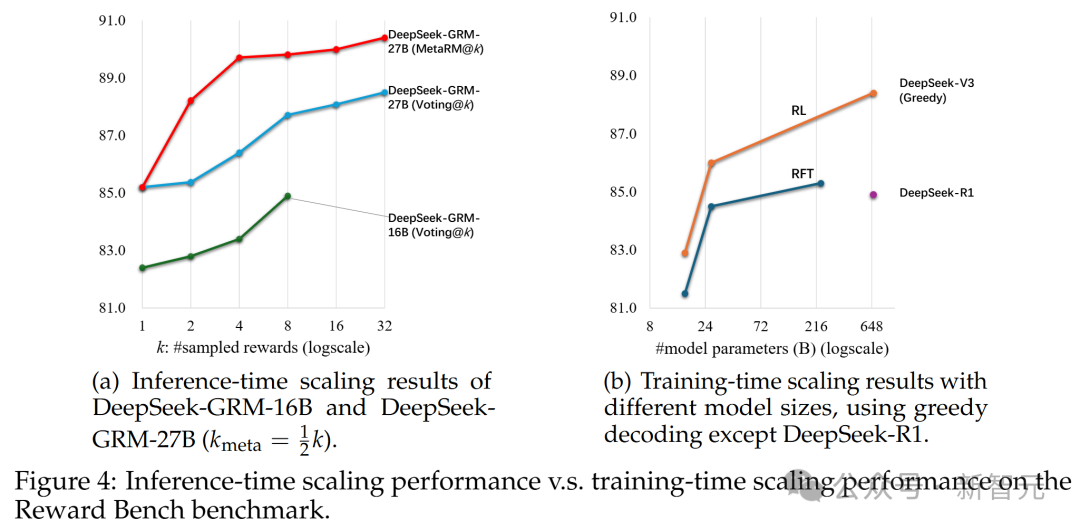
此外,他们用包含300个样本的降采样测试集测试了DeepSeek-R1,发现其性能甚至不如236B MoE RFT模型,这表明延长推理任务的思维链并不能显著提升通用RM的性能。


(文:新智元)