
在当今信息爆炸的时代,构建高效、全面的知识库对于企业和个人而言至关重要。然而,如何快速、高效地从海量网络数据中提取有价值的信息,一直是个挑战。幸运的是,FireCrawl 的出现为我们提供了全新的解决方案。
FireCrawl:AI驱动的智能爬虫工具
FireCrawl 是由 Mendable.ai 开发的开源项目,旨在将网站内容转换为适用于大型语言模型(LLM)的结构化数据。它无需站点地图即可抓取任何网站的所有可访问子页面,并将这些内容转换为干净、格式化的 Markdown 文档。
你也可以本地部署,可以按照READEME.md来进行本地部署 项目地址:https://github.com/mendableai/firecrawl 本例中使用的是Cloud版本的FireCrawl()
核心优势
- 系统性智能抓取:FireCrawl 能够智能发现并追踪网站内部链接,确保内容的完整性和连贯性。
- 精准内容识别与过滤:它能智能识别并提取网页中的主要内容,自动过滤广告、导航栏等无关元素,确保保留对 AI 系统有用的核心信息。
- 语义化结构转换:FireCrawl 将抓取的网页内容转换为清晰、格式化的 Markdown 文档,保留标题、段落、列表等元素的层级关系,方便后续处理和分析。
- 用户友好的操作体验:无需编程知识,只需输入目标 URL,即可完成 Web 知识库的一键式生成。
本地部署 FireCrawl 的步骤
为了满足对数据隐私和安全性的需求,您可以选择在本地环境中部署 FireCrawl。以下是简要的部署步骤:
克隆代码仓库:在终端中执行以下命令,将 FireCrawl 的代码克隆到本地:
git clone https://github.com/mendableai/firecrawl.git
- 设置环境参数:进入克隆的目录,复制环境变量模板文件,并进行必要的配置:
cd firecrawlcp .env.example .env
使用文本编辑器打开 .env 文件,修改以下参数:
USEDBAUTHENTICATION:设置为 false,表示不使用数据库认证。
TESTAPIKEY:设置一个自定义的 API 密钥,例如 yourapikey。
启动 FireCrawl:在终端中执行以下命令,使用 Docker Compose 启动 FireCrawl:
docker-compose up -d
配置 Dify 与 FireCrawl 的集成:在 Dify 的设置中,添加 FireCrawl 的 API 配置,确保 Base URL 设置为 http://host.docker.internal:3002,并输入之前设置的 API 密钥。
应用场景
- 技术文档的知识库构建:利用 FireCrawl,您可以快速爬取官方文档,构建全面的知识库,方便技术学习和查询。
- 市场调研与竞争分析:通过爬取目标公司发布的市场调研和商业洞见,获取最新的行业动态和竞争情报。
Dify FireCrawl插件
在dify的插件市场已经封装了FireCrawl调用
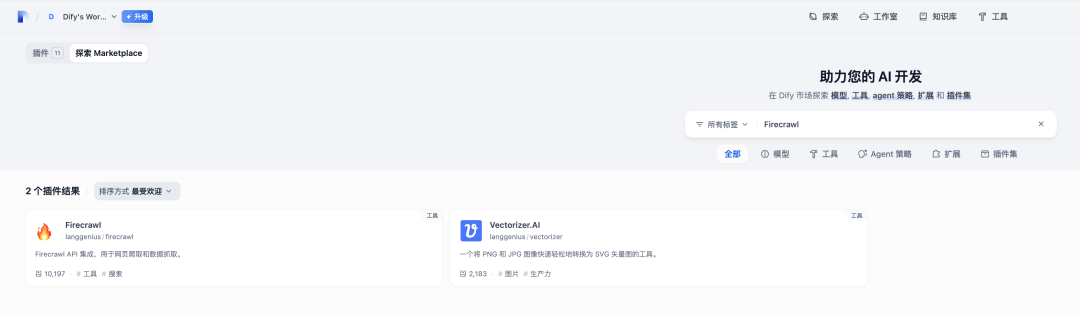
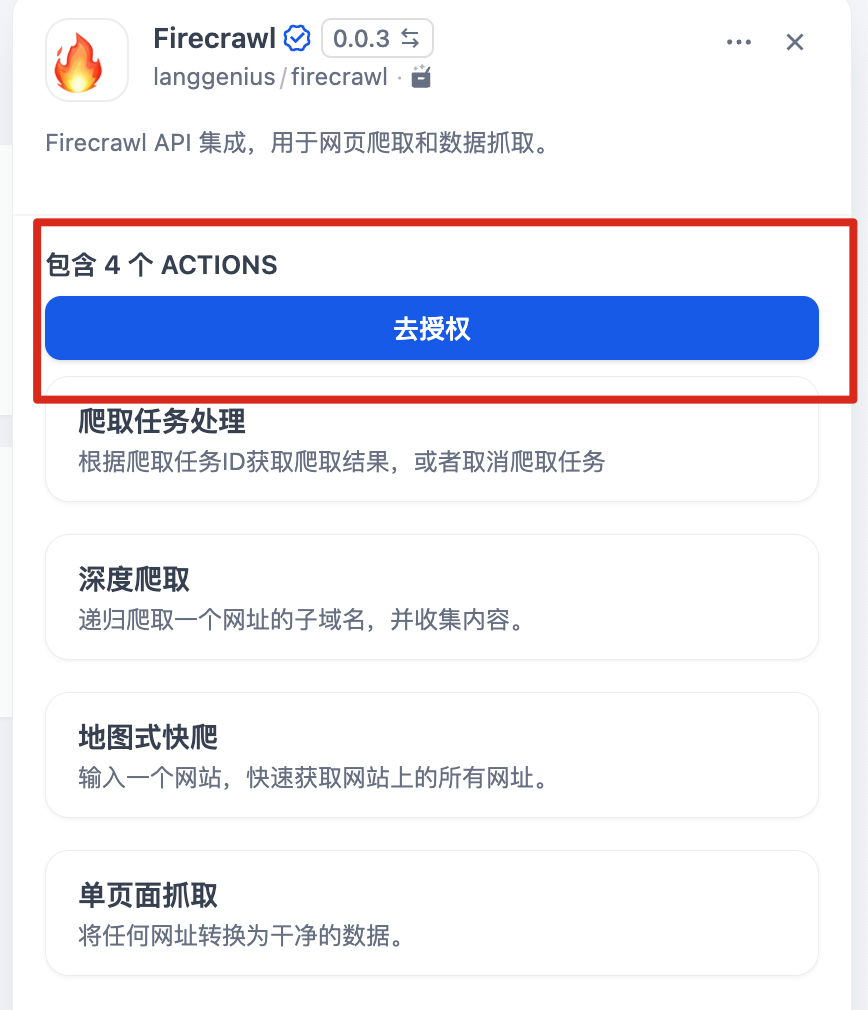

Dify平台构建知识库
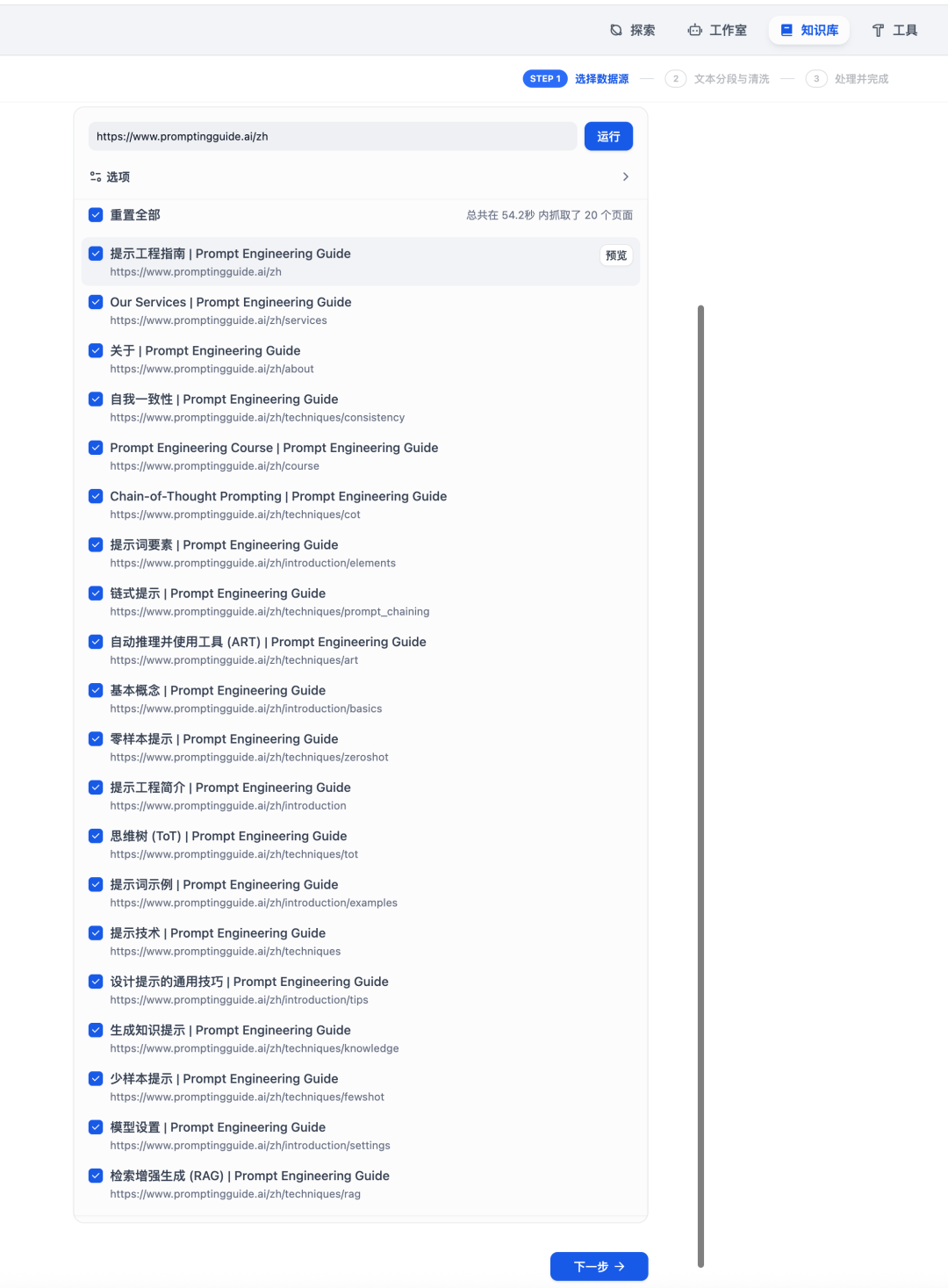
Dify和FireCrawl集成已经很好了,在Dify创建知识库可以直接通过FireCrawl生成,不用你再去粘贴复制,生成文件这么麻烦




总结
FireCrawl 通过其强大的功能和简便的操作,为构建高质量的 AI 知识库提供了一站式解决方案。无论是企业还是个人,都可以利用 FireCrawl 高效地从网络中提取有价值的信息,助力 AI 应用的开发和优化。
如果您对 FireCrawl 的部署和使用有任何疑问,欢迎在评论区留言讨论。
🚀🚀🚀🚀🚀
(文:PyTorch研习社)