







在动作引导方面,研究人员设计了一种混合控制信号,其中包括用于对面部表情进行细粒度控制的隐式面部潜在表征、用于控制头部大小和旋转的显式头部球体模型,以及用于控制躯干动作和骨骼长度调整的三维人体骨骼模型,这些信号能够在形状发生显著变化时实现稳健的自适应。
对于信息有限的场景(例如,多次旋转动作或局部身体参考),引入了互补的外观引导方法。首先从目标动作中采样不同的姿势,然后生成多帧参考图像来提供未显示区域的纹理信息,最后在视频片段之间传播这些参考信息,以便在长期的合成过程中保持细节的一致性。
为了实现多尺度自适应,研究人员采用渐进式训练策略,在包含不同类型场景(如人像表演、上半身说话和全身跳舞)的多样化数据集上对模型进行训练。
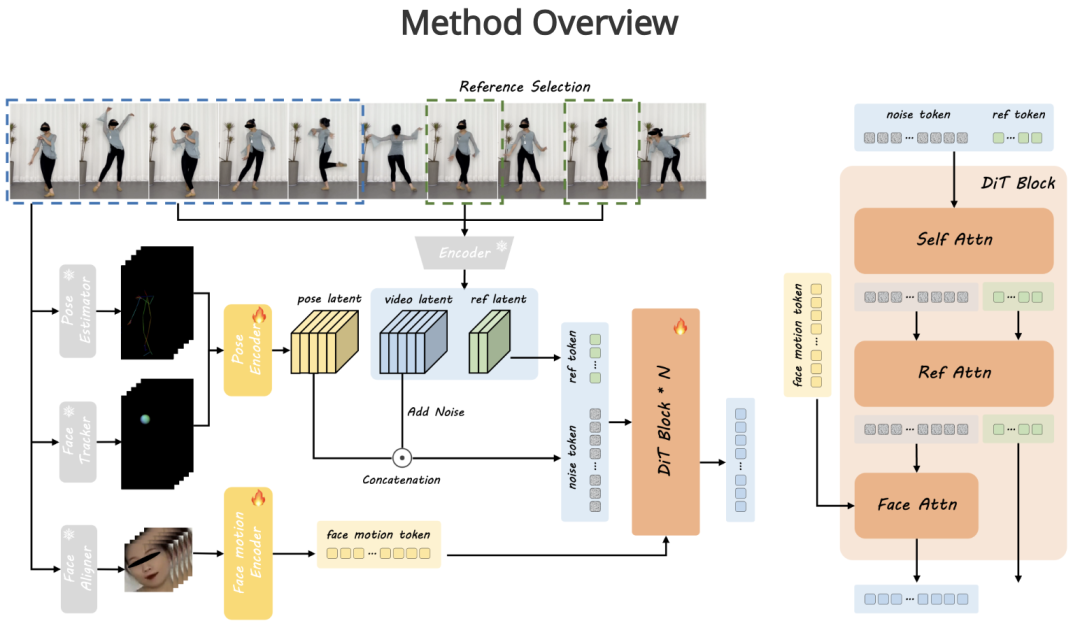
在训练阶段,首先从驱动帧中提取人体骨骼和头部球体模型,然后使用姿态编码器将它们编码为姿态潜在表征。
生成的姿态潜在表征会沿着通道维度与添加了噪声的视频潜在表征相结合。视频潜在表征是通过使用三维变分自动编码器(3D VAE)对输入的完整视频中的一个片段进行编码得到的。
此外,面部表情由面部动作编码器进行编码,以生成隐式的面部表征。需要注意的是,参考图像可以是从输入视频中采样得到的一帧或多帧图像,以便在训练过程中提供额外的外观细节,并且参考标记分支与扩散变换器(DiT)模型中的噪声标记分支共享权重。
最后,去噪后的视频潜在表征由编码后的视频潜在表征进行监督。在每个扩散变换器(DiT)模块中,面部动作标记通过交叉注意力机制(面部注意力,Face Attn)整合到噪声标记分支中,而参考标记的外观信息则通过拼接自注意力机制(自注意力,Self Attn)以及后续的交叉注意力机制(参考注意力,Ref Attn)注入到噪声标记中,完成更高质量的视频输出。
只要给定参考图像和视频,DreamActor-M1就可以从视频中捕捉人类行为动作,制作出跨多个尺度(从肖像到全身动画)的极具表现力和逼真的人体视频,而且生成的视频具有时间一致性、身份保留性和高保真度。




这种方法还有非常灵活的可控性和稳健性,可以扩展到音频驱动的面部动画,提供多种语言的口型同步结果,也支持仅传输部分动作,例如面部表情和头部动作,还能够通过骨骼长度调整技术来适配具有形状感知能力的动画效果。


研究人员在论文中指出,目前DreamActor-M1框架仍存在的一些局限性,例如在控制动态相机移动方面存在固有的困难,目前无法生成与环境物体的物理交互效果,此外就是进行骨骼长度调整时,在极端情况下表现出不稳定性,需要进行多次迭代并通过手动选择来确定最佳情况。
图生视频在很多领域都有广泛的商业应用潜力。
例如,电商商家可以利用图生视频技术将商品图片快速转化为展示视频,无需真实模特和复杂的拍摄过程,就能生成具有电影级光影效果的视频;
在影视前期创意阶段,导演和编剧可以通过图生视频快速将分镜脚本的图片转化为动态视频,直观地感受剧情节奏和画面效果,及时调整创意和拍摄计划,节省后期制作的成本与时间等;
在游戏开发领域,图生视频技术将游戏场景、角色等静态设计图片转化为动态视频,生成无尽变化的可玩(动作可控)世界,为游戏开发提供新思路和方法;

在社交媒体领域,用户可以将自己的照片制作成视频,添加音乐、特效等增加内容的趣味性和吸引力,让静态的照片 “动” 起来,可以传达更丰富的情感和信息。

(文:头部科技)