

今天是2025年4月5日,星期六,清明假期第二天,北京,天气晴。
现在关于Deepresearch的复现和应用越来越多,也对大模型的规划能力有了越来越多的要求。
假设大模型能力很强,我们可以使用CoT Only,仅使用Chain-of-Thought (CoT)推理生成答案,不访问任何外部参考上下文。或者使用RAG,结合Chain-of-Thought推理和检索到的参考上下文来指导答案生成过程,进一步的,也有Search-o1融合推理模型完成搜索增强。
但是,前面几种方案都依赖于模型自身的能力,比较受限,所以,如何通过强化学习的方式,让推理大模型具备推理能力,显得很有必要。
因此,我们来看看最近的几个代表工作,包括Search-R1、R1-Searcher以及DeepResearcher。
看看具体实现思路,很有意义,代码也有开源。
抓住根本问题,做根因,专题化,体系化,会有更多深度思考。大家一起加油。
一、Search-o1融合推理模型完成搜索增强
Search-o1《Search-o1: Agentic Search-Enhanced Large Reasoning Models》(https://arxiv.org/pdf/2501.05366,https://search-o1.github.io/,https://github.com/sunnynexus/Search-o1),其认为,检索到的文档通常篇幅较长且包含冗余信息,直接将其输入到LRM可能会干扰原有的推理连贯性,甚至引入噪声。大多数LRM在预训练和微调阶段已被特别对齐,以适应复杂推理任务。这种关注导致他们在一般能力上出现了某种程度的灾难性遗忘,最终限制了他们对检索到的文档的长上下文理解。
所以,引入代理检索增强生成(RAG)机制和文档推理模块来增强大型推理模型(LRMs)的知识能力。目标是为每个问题q生成一个全面的解决方案,包括逻辑推理链R和最终答案a。
在问题解决过程中考虑三个主要输入:任务指令I、问题q以及外部检索到的文档D。推理任务中,Q是需要回答的具体复杂问题,而D 包括从相关知识库动态检索的背景知识。目标是设计一种推理机制,有效地整合 I,q 和D ,以产生一个连贯的推理链R和一个最终答案a。这可以形式化为映射(I,q,D)→(R,a)。

1、架构设计
架构包括代理RAG机制以及文档内推理模块(Reason-in-Documents)两种。
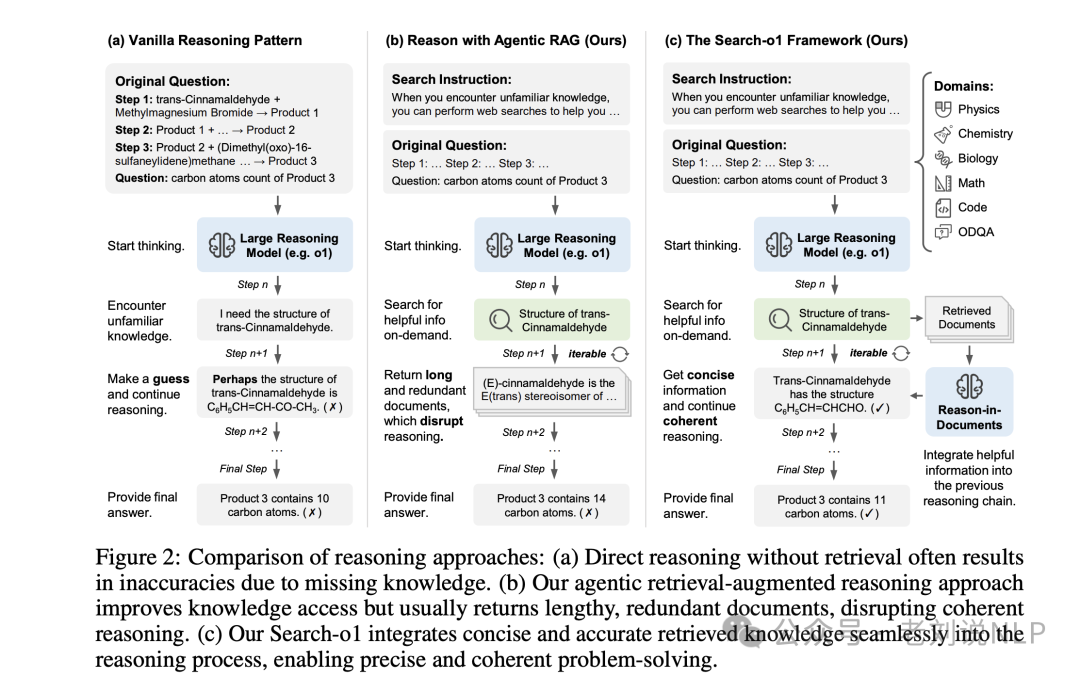
当推理模型M生成推理链R时,它可能会产生包含特殊符号<lbegin_search_queryl>和<lend_search_query|>的搜索查询。检测到<lend_search_query|>符号时,提取相应的搜索查询qsearch,触发检索函数Search获取相关外部文档D。这些检索到的文档,连同文档内推理指令Idocs和当前推理序列R,随后由“文档内推理”模块处理。

该模块将原始文档精简为简洁、相关的信息rfinal,并将其无缝整合回推理链R内,使用符号<lbegin_search_resultl>和<lend_search_resultl>。这一迭代过程确保推理模型在保持连贯性和逻辑一致性的同时,融入必要的外部知识,从而生成全面的推理链R和最终答案a。
2、代理RAG机制
代理式RAG机制是搜索-o1框架的关键组成部分,使推理模型能够在推理过程中自主决定何时检索外部知识。该机制允许模型自行决定是否继续生成推理步骤或开始检索步骤。主要依靠prompt实现,如下:

首先,在每个推理步骤中,模型根据当前推理状态和之前检索到的知识生成搜索查询。每个搜索查询被封装在特殊符号之间,表示需要检索的外部知识。
其次,一旦生成了搜索查询,模型会触发检索机制,使用Bing Web Search API获取相关文档。
最后,检索到的文档在推理链中插入,允许模型继续推理。
3、文档内推理模块(Reason-in-Documents)
代理RAG机制解决了推理中的知识空白,但直接插入完整文档可能会因它们的长度和冗余性而破坏连贯性。为了克服这一点,采用独立于主推理链的Reason-in-Documents模块,该模块通过使用原始推理模型进行单独的生成过程,选择性地仅将相关且简洁的信息整合到推理链中。该模块处理检索到的文档,以符合模型的特定推理需求,将原始信息转化为精炼、相关的知识,同时保持主推理链的连贯性和逻辑一致性,也是使用prompt实现,如下:

首先,对检索到的文档进行分析,识别与当前搜索查询和先前推理步骤相关的事实信息。这一步骤确保检索到的文档内容与当前推理任务紧密相关。
然后,从分析后的文档中提取有助于推进原始问题的相关信息,确保信息的准确性和相关性。这一步骤通过精确的信息筛选,去除了冗余和不必要的文档内容。
最后,将精炼后的知识与原始推理链整合,生成连贯的推理步骤。这一步骤通过在推理链中插入精炼后的信息,保持推理的连贯性和逻辑一致性。
在模型选型上,使用QwQ-32B-Preview。
4、看结果
一个完整的流程如下:

二、Search-R1基于GRPO与PPO实现搜索强化
Search-r1《Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning》(https://arxiv.org/pdf/2503.09516, https://github.com/PeterGriffinJin/Search-R1),核心创新在于它允许LLM在推理过程中自主决定何时以及如何进行搜索。

1、训练数据
训练数据模版设计上,该模板以迭代的方式将模型的输出结构化为三个部分:首先是推理过程,然后是搜索引擎调用功能,最后是答案。通过特殊token<search>和</search>触发搜索,<information>和</information>包含检索到的内容,<think>和</think>包含推理步骤,<answer>和</answer>包含最终答案。

2、奖励函数设计
采用了一个基于规则的奖励系统,该系统仅由最终结果奖励组成,这些奖励评估模型响应的正确性。例如,在事实推理任务中,正确性可以使用基于规则的标准来评估,如精确字符串匹配。不纳入格式奖励。
强化学习算法上,兼容PPO和GRPO等多种RL算法。

在训练时,使用检索token掩码(retrievedtokenmasking)来保证训练的稳定性,仅对LLM生成的token计算损失,排除检索内容。
3、训练模型
训练模型上,使用三种类型的模型:Qwen-2.5-3B(Base/Instruct)和Qwen-2.5-7B(Base/Instruct)以及Llama-3.2-3B(Base/Instruct)。检索使用2018年维基百科转储作为知识源和E5作为检索器。训练时,将所有检索方法的检索段落数设置为三个。
4、实现效果
实现效果上如下:

使用PPO和GRPO作为基础强化学习方法评估SEARCH-R1,在LLaMA3.2-3B和Qwen2.5-3B模型上进行实验,得到了几个有趣的现象:
1)在所有情况下,GRPO比PPO收敛得更快。这是因为PPO依赖于一个评论家模型,该模型需要在有效训练开始之前进行几个热身步骤。
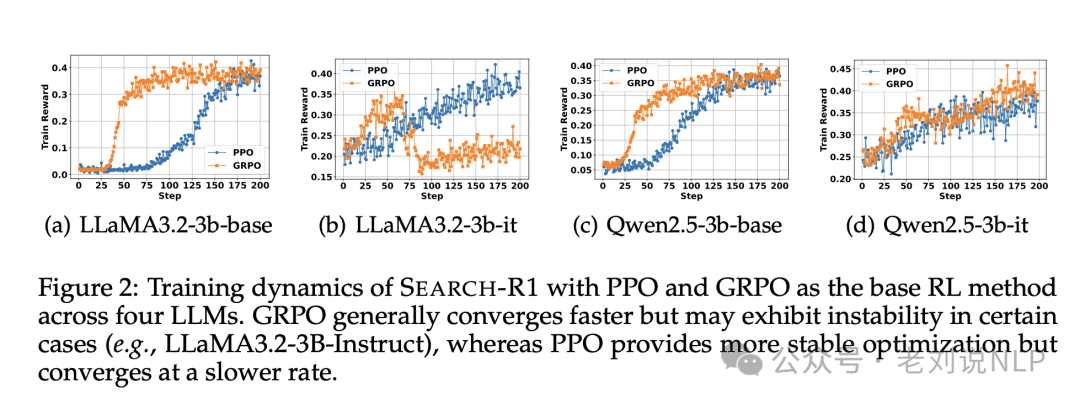
2)PPO表现出更强的训练稳定性。当应用于LLaMA3.2-3B-Instruct模型时,GRPO导致奖励崩溃,而PPO在不同LLM架构中保持稳定。
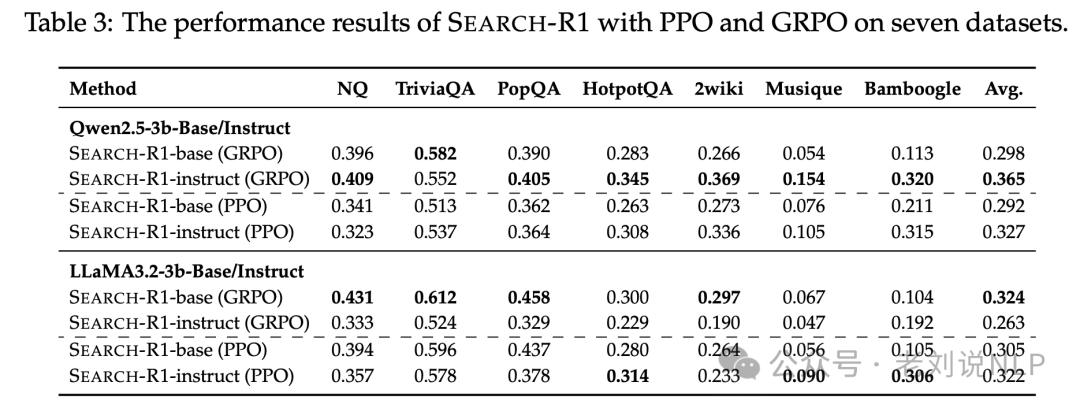
3)PPO和GRPO的最终训练奖励相当。尽管收敛速度和稳定性存在差异,但两种方法都达到了相似的最终奖励值,表明两者均可用于优化SEARCH-R1。
4)GRPO通常优于PPO。在Qwen2.5-3B和LLaMA3.2-3B上,GRPO获得了更高的平均表现,证明了其在优化检索增强推理方面的有效性。
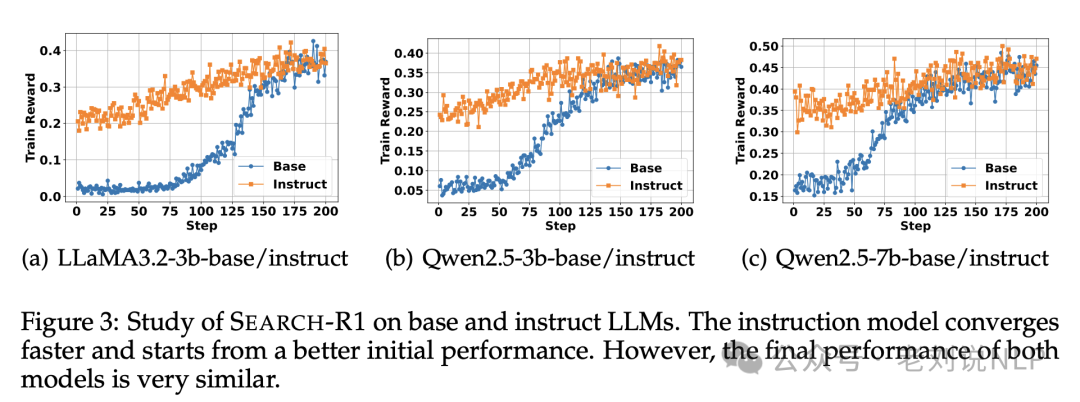
5)与base模型相比,instruct模型收敛得更快,并且从更好的初始性能开始。然而,两种模型的最终性能非常相似。
6)响应长度在训练过程中呈现出先减少后增加并趋于稳定的趋势,与大模型的整体性能轨迹一致。
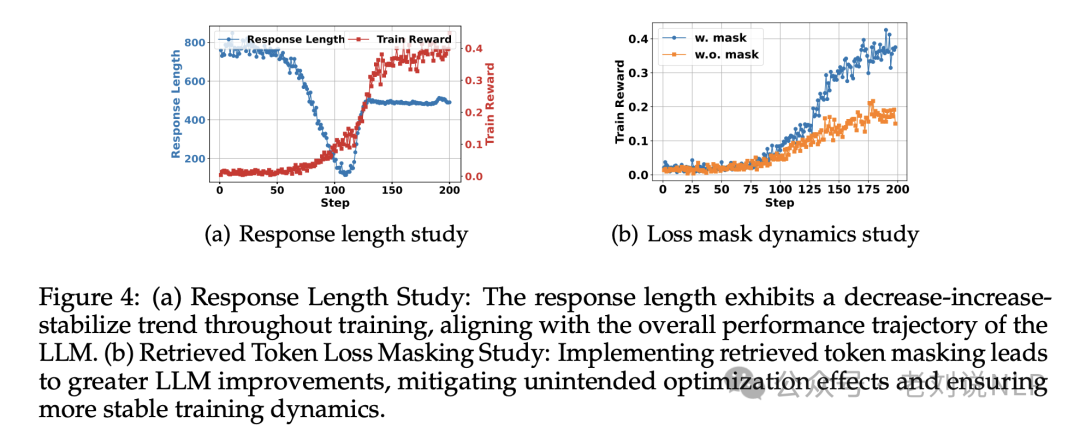
早期阶段(前100步):响应长度急剧下降,而训练奖励略有增加。在这一阶段,基础模型学会消除过多的填充词,并开始适应任务要求。中期阶段(100-130步):响应长度和训练奖励显著增加。此时,大型语言模型学会调用搜索引擎,由于检索到的段落导致响应变长。随着模型更有效地利用搜索结果,训练奖励大幅提升。后期阶段(130步之后):响应长度趋于稳定,训练奖励继续小幅上升。在这一阶段,模型已学会有效使用搜索引擎,并专注于完善其搜索查询。鉴于NQ是一个相对简单的任务,响应长度稳定在大约500个标记,表明收敛。
7)实施检索到的标记掩蔽能够带来更大的大模型改进效果,减轻非预期的优化效应,确保训练动态更加稳定。
三、R1-Searcher两阶段强化学习方案
关于两阶段的强化学习方案,R1-Searcher《R1-Searcher: Incentivizing the Search Capability in LLMs via Reinforcement Learning》,https://arxiv.org/pdf/2503.05592,第一阶段专注于让模型学会如何正确地发起检索请求;第二阶段则让模型学会在真正回答问题时有效利用检索结果。
1、训练数据
在训练数据集上,选用多跳问答数据集HotpotQA 和2WikiMultiHopQA进行训练。

通过初步的推理尝试把问题按解题难度(需要检索次数)分为轻松、中等、困难三类。

2、训练方法
在训练方法上,分成两个阶段。两阶段的奖励设计,在第一阶段快速让模型学会正确地调用检索接口并遵循输出格式,第二阶段再综合考察答案准确度,使得模型对检索信息的使用更有效,从而提升整体问答质量。
拆开来看:
阶段一只关注检索行为,给检索次数和输出格式设定正奖励或零奖励。

检索奖励上,令n表示推理过程中检索调用(即发起检索请求)的次数,如果模型在一次完整推理中至少调用了1次检索接口,则奖励为0.5,否则奖励为0。
格式奖励上,为了确保输出格式符合要求(例如正确使用
此阶段并不评价答案本身是否正确,因此在阶段一中没有针对答案准确度的奖励项。最终的阶段一总奖励为以上两项之和。
第二阶段的目标是让模型有效利用检索结果来回答问题。
此时的奖励包括答案奖励和格式奖励。

其中,答案奖励,使用答案与标注答案的F1分数作为奖励,若预测答案与真实答案越吻合,F1得分越高,模型获得的奖励也越高。格式奖励也是奖励格式是否满足要求。
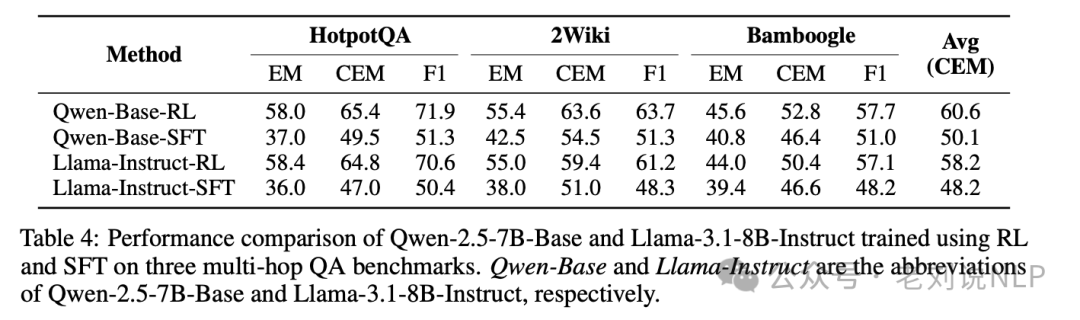
实现效果如下:

在各个数据集上的表现:
四、DeepResearcher使用纯RL实现
DeepResearcher开源模型,《DeepResearcher: Scaling Deep Research via Reinforcement Learning in Real-world Environments》,https://github.com/GAIR-NLP/DeepResearcher/blob/main/resources/DeepResearcher.pdf,通过在真实环境中扩展强化学习(RL,GRPO)来实现基于LLM的DeepResearcher的端到端训练。代码地址在https://github.com/GAIR-NLP/DeepResearcher,模型地址在https://huggingface.co/GAIR/DeepResearcher-7b。考虑到与受控的RAG(检索增强生成)环境不同,实际的网络搜索呈现出嘈杂、非结构化且异构的信息源,需要复杂的过滤和相关性评估能力。所以,与基于提示和SFT的方法不同,仅使用结果奖励直接扩展深度研究的强化学习训练。
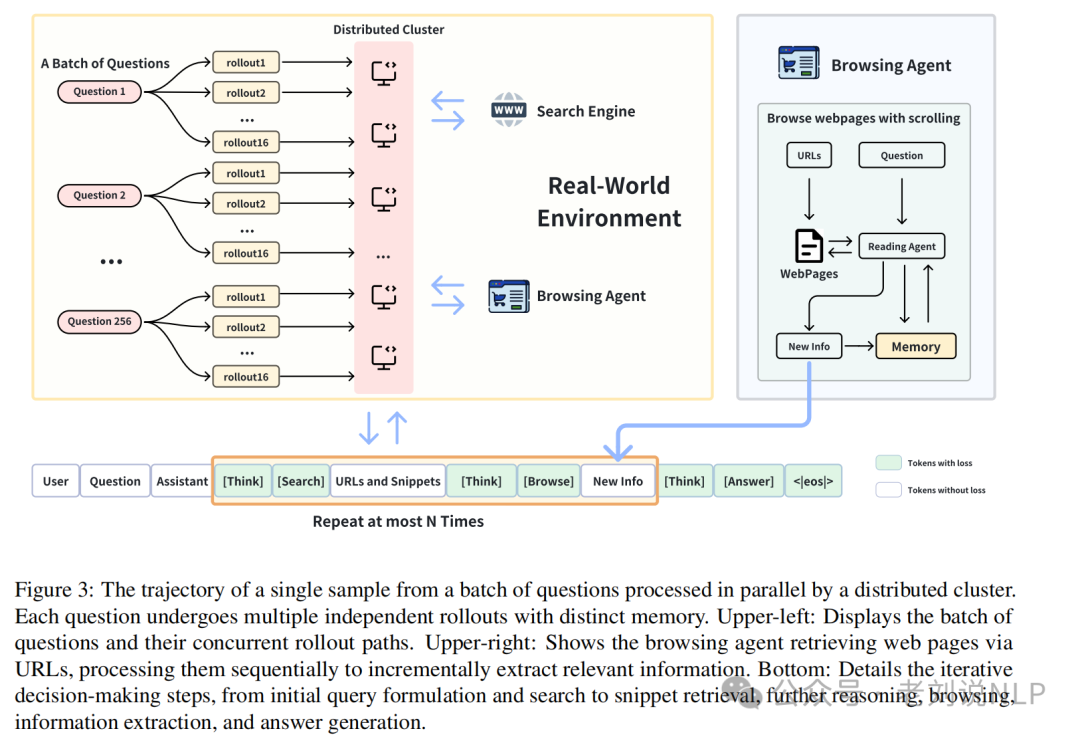
1、关于训练架构
在整体架构上,包括三个部分。

推理部分,限制深度研究者在采取行动之前进行推理。每个推理过程都用一个<思考>标签包裹起来,遵循DeepSeek-R1的设置。
网络搜索部分,通过生成一个JSON格式的请求来调用网络搜索工具,该请求包含工具名称web_search和作为参数的搜索查询。搜索结果以结构化格式返回,包括每个网页的标题、URL和内容摘要。当前实现采用固定的前K个(例如,10个)值来检索搜索结果。
网页浏览代理部分,代理为每个查询维护一个短期记忆库。在接收到网页浏览请求后,它会处理请求中URL的第一页段。随后,网页浏览代理根据查询、历史记忆和新获取的网页内容采取两个行动:(1)确定是继续阅读下一个URL/段还是停止,(2)将相关信息追加到短期记忆中。一旦代理决定停止进一步浏览,它会将所有新添加的信息从短期记忆中编译并返回。
2、关于训练数据
在训练数据上,利用现有的开放领域问答数据集,这些数据集包含从单跳到多跳的问题,这些问题本质上需要在线搜索以找到准确的答案。训练语料库包括一系列需要不同。所以,具体使用NaturalQuestions(NQ)和TriviaQA(TQ)来处理单跳场景,通常答案可以在单个网页文档中找到。对于需要跨多个来源整合信息的更复杂的多跳场景,纳入了HotpotQA和2WikiMultiHopQA(2Wiki)的例子,这两个例子都是专门设计来评估多步骤推理能力的。
此外,在做数据上,有2个点做的不错。
为了防止污染,先进行低质量问题过滤Low-Quality Question Filtering,具体提示DeepSeek-R1排除那些可能产生不可靠或有问题搜索结果的问题,如剔除:时效性问题(例如,“苹果公司现任CEO是谁?”)、高度主观的问题(例如,“最好的智能手机是什么?”)以及潜在有害或违反政策的内容。
为了确保模型真正学会使用搜索工具而不是死记硬背答案,采用了污染检测Contamination Detection。对于每个候选问题,从训练中将使用的基模型中随机抽取10个响应,并检查是否有任何响应包含正确答案(即,准确率@10)。如果模型在未经搜索的情况下就表现出先验知识(即,直接给出正确答案),则将其排除在训练集之外。

3、关于训练选型及方方法
训练选型方面,采用Qwen2.5-7B-Instruct作为训练流程的主干模型。训练使用Verl框架进行。在每个训练步骤中,采样256个提示,并对每个提示采样16次展开。每次展开包括最多10次工具调用,然后是最终答案步骤。
训练方法上,利用强化学习(RL)来训练智能体,具体采用群体相对策略优化(GRPO)算法,由于使用的是包含短答案真实标签的开放领域问答数据集,所以在奖励函数上包括格式惩罚和F1奖励。

格式惩罚(如果格式不正确(例如,缺少标签或结构错误),代理将受到-1的惩罚)和F1奖励(如果格式正确,奖励基于词级F1分数,该分数衡量生成的答案与参考答案相比的准确性。更高的F1分数带来更高的奖励)。
但是呢,在训练过程中遇到了一些挑战,这些可以看看实现措施。
针对高并发请求问题,由于GRPO算法导致大量采样迭代,产生了大量搜索查询和网页抓取操作,导致长时间延迟。解决方案是创建一个分布式CPU服务器集群,每个服务器处理一部分请求,以提高处理效率。
针对管理网络爬取和API限制问题,在抓取阶段,系统经常遇到反爬虫措施,返回无关内容或完全无响应。解决方案是实施强大的重试机制和缓存策略,以减少API调用频率并管理相关成本。
针对信息提取问题,采用多代理框架,专门的阅读代理从抓取的网页中提取相关信息。通过将长网页分割成小段,代理顺序处理内容,从而提高资源分配和信息提取的准确性。
4、关于训练结果
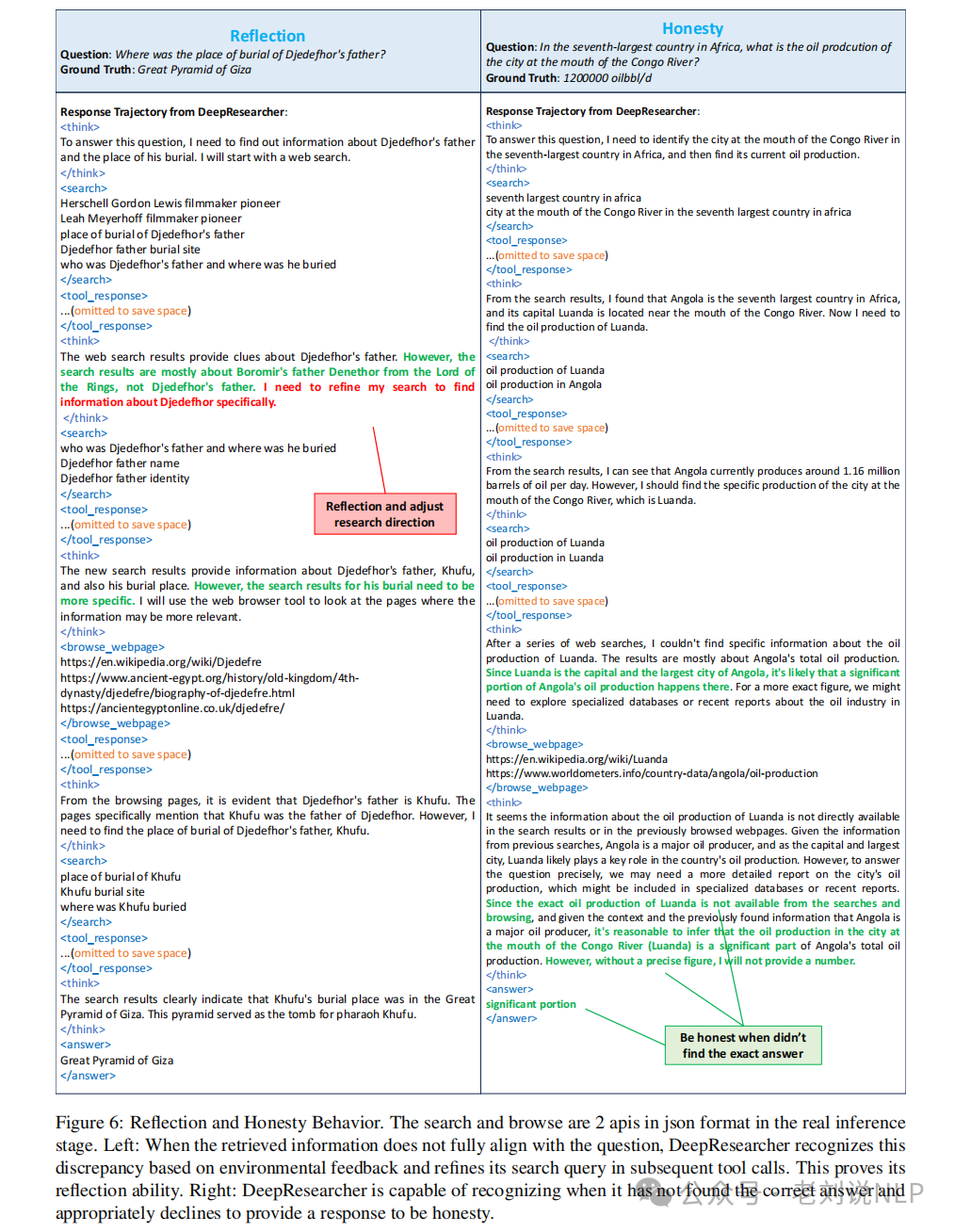
这种训练过程也很有趣。

其一,随着强化学习的进行,性能逐渐提升,F1分数从0.375开始,逐渐提升至约0.55,显示出一致的上行趋势。这一结果表明模型在强化学习中的表现逐步提升。
其二,训练使难题推理步骤增加,随着训练的进行,不同难度级别所需的工具调用次数也相应增加。与其他三种设置不同,即使在34步之后,4跳设置仍表现出上升趋势。这表明模型在处理更难题目时仍在学习如何检索更多信息。
其三,持续学习使长响应不饱和响应长度也随推理复杂度的增加而增加。然而,四种设置均显示出持续上升的趋势,表明模型在训练过程中继续扩展其推理过程。这进一步支持了模型通过生成更多详细输出(如复查、完善、规划等)来适应日益复杂的查询的想法。
最后看下效果:
参考文献
1、https://arxiv.org/pdf/2501.05366
2、https://github.com/GAIR-NLP/DeepResearcher/blob/main/resources/DeepResearcher.pdf
3、https://arxiv.org/pdf/2503.09516
4、https://arxiv.org/pdf/2503.05592
(文:老刘说NLP)