

作为机器人领域的顶级期刊,《International Journal of Robotics Research》(IJRR)长期以来发表着机器人技术领域的高质量研究成果,以其严格的审稿标准和跨学科研究特色,成为反映机器人技术前沿趋势的重要平台。本期精选了三月份发表的六篇重磅研究,带您了解四足机器人、软体机器人、水下机器人、仿生飞行器、机器人迁移学习和位姿估计等领域的最新突破。参考文献在文章末尾。
《Contact-implicit Model Predictive Control: Controlling diverse quadruped motions without pre-planned contact modes or trajectories》– 韩国科学技术院、麻省理工学院
四足机器人在复杂环境中的运动规划一直是机器人控制领域的重大挑战。传统方法通常依赖预定义的接触模式和轨迹,这严重限制了机器人适应未知环境的能力,尤其是在面对非周期性、不对称的动态任务时表现欠佳。
韩国科学技术院和麻省理工学院的联合研究团队针对这一难题,提出了一种革命性的控制方法——接触隐式MPC(Contact-Implicit Model Predictive Control)框架。这一方法最大的突破在于,它使四足机器人能够在没有预定义接触模式的情况下,自主发现并执行最优的运动策略。

传统基于模型预测控制(MPC)的方法虽然能够进行在线优化,但通常假设固定的接触序列,主要优化地面反作用力或关节力矩轨迹,难以动态调整接触模式。而接触隐式MPC框架则采用了硬接触模型(Hard Contact Model),结合线性互补约束(Linear Complementarity Constraint),通过优化状态轨迹、控制输入和接触力,自动探索最优接触模式,实现了真正的自适应控制。
研究的一个关键创新是引入了平滑梯度方法,有效解决了传统严格互补约束(Strict Complementarity Constraints)优化中容易卡在初始接触模式的问题。团队提出的基于放松互补约束(Relaxed Complementarity Constraints)的梯度计算方法,使优化过程能够平滑地过渡到新的接触模式,大幅提升了计算稳定性和收敛性。
另一项技术创新是采用多重射击变体DDP(Multiple Shooting DDP)替代传统单射击方法。在硬接触动力学系统中,单射击方法容易因初始状态偏差导致优化失败,而多重射击DDP显著增强了优化稳定性,确保接触模式在不同初始状态下保持一致性。
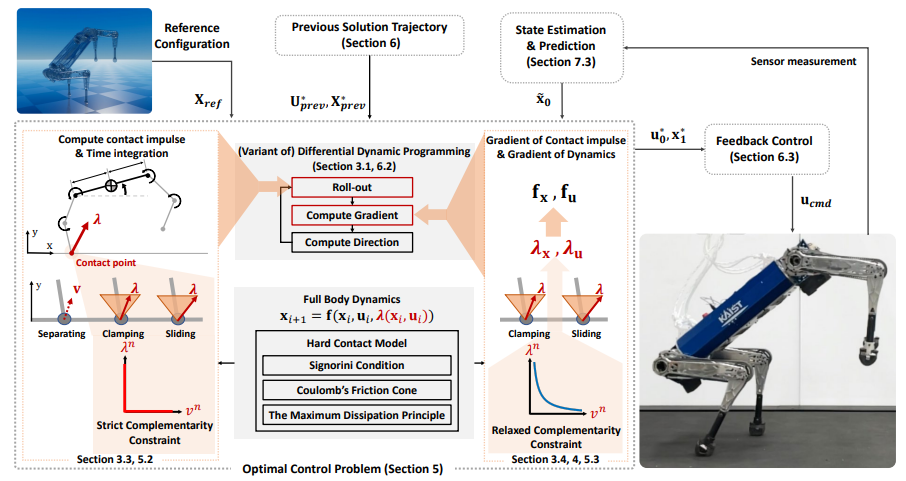
研究团队在仿真环境和真实四足机器人平台上进行了全面验证。在仿真实验中,接触隐式MPC在前肢抬起(front-leg rearing)任务中展现出色表现,机器人能够自主发现最佳接触模式,无需人为设定前肢接触状态。在向前小跑(forward trot)任务中,机器人在无预定义步态的情况下,自然学会了交替抬腿的步态模式,并能自动调整步态以适应不同地形。
最具说服力的是真实机器人测试结果。研究团队使用重达45公斤的HOUND四足机器人(KAIST研发)进行实验,在40Hz的控制频率下实现了接触隐式MPC的在线优化。在前肢抬起测试中,机器人能够自动调整姿态,使重心保持在支撑面内,采用平滑梯度优化的成功率比传统刚性优化提高了30%。在步态发现测试中,机器人能够从随机初始步态自动调整到最优步态,包括对角步态(trot)和交替步态(pacing)。引入步态对称性成本后,步态稳定性提高了50%,证明了该方法在动态环境中的适应能力。
这项研究为四足机器人控制开辟了全新范式,突破了传统控制方法对预定义接触模式的依赖,实现了真正的自适应动态控制。未来,研究团队计划将该方法应用于更复杂的环境,如崎岖地形和楼梯攀爬;优化实时计算性能,提高控制频率;并探索将接触隐式优化与深度强化学习相结合,进一步提升机器人的环境适应能力和任务执行能力。
《A Koopman-based residual modeling approach for the control of a soft robot arm》– 密歇根大学、哈佛大学

软体机器人因其柔性材料特性,在安全性和适应性方面优于传统刚性机器人,特别适合在不确定环境中操作及与人类进行物理交互。然而,这种优势也带来了建模与控制的极大挑战——软体机器人的无限维变形特性使得传统基于刚性体动力学的控制策略难以适用。
密歇根大学和哈佛大学的研究团队直面这一挑战,提出了一种基于残差建模(Residual Modeling)的Koopman方法。Koopman算子理论允许将非线性系统投影到高维线性空间,但现有基于数据驱动的Koopman方法需要大量实验数据,且难以泛化。该团队的创新在于巧妙融合了物理建模与数据驱动方法:首先使用物理建模构建理想化的Koopman模型,然后通过数据驱动方法学习物理模型未能准确描述的动态残差,最终形成一个更精准且计算高效的综合模型。
这种混合方法既保留了物理模型的泛化能力,又利用数据驱动方法弥补了物理模型的不足。通过Koopman算子将非线性动力学转换为有限维线性表示,研究者们成功实现了线性控制方法(如模型预测控制MPC)在软体系统中的应用。
研究团队在多个系统上验证了该方法的有效性。在Van der Pol振子系统中,残差Koopman模型的误差比物理模型降低了8%,比纯数据驱动模型低28%。在倒立摆推车系统中,残差模型的误差为0.33,比纯数据驱动模型的0.41降低了18%。
最精彩的部分是在真实软体机械臂上的验证实验。在训练数据较少的情况下,残差Koopman模型的误差仅为0.07m,比物理模型的0.14m和数据驱动模型的0.21m分别降低了52%和67%。在轨迹跟踪任务中,残差Koopman结合MPC控制器的表现远超其他方法——数据驱动MPC完全失效,物理模型MPC表现尚可但误差较大,而残差Koopman MPC的误差最小,平均降低了2.5倍。
研究团队还进行了功能性测试,展示了软体机器人在抓取与放置任务中的能力。机械臂能够将螺丝刀、胶带、废纸等物品正确放入指定位置,即使遭遇障碍物仍能调整姿态完成任务。在书写任务中,机械臂在不同位置的白板上成功书写字母“H”,展现了软体机器人柔性与先进控制技术结合的强大潜力。
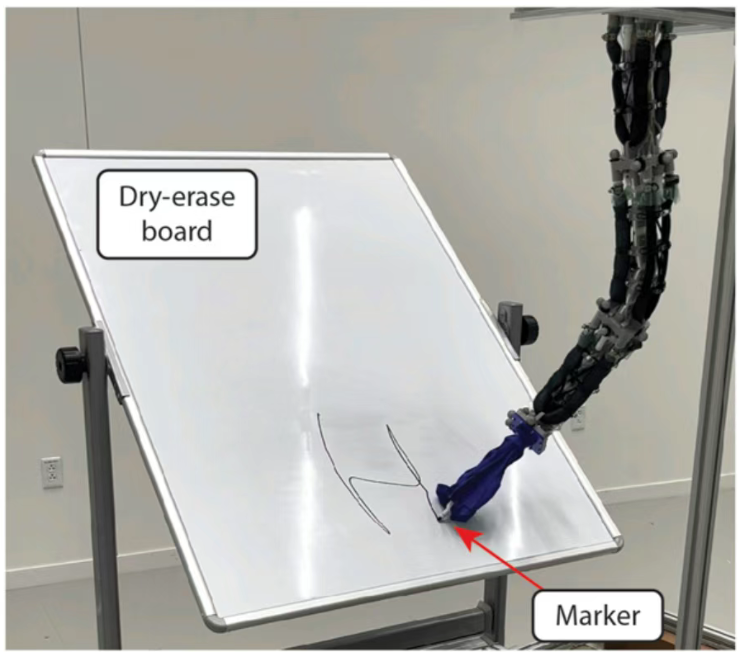
这项研究为软体机器人控制开辟了新途径,未来有望应用于在线学习实现实时模型优化,并与非线性控制策略(如强化学习)结合,进一步提高软体机器人在复杂环境中的适应能力。研究成果也可能扩展至水下软体机器人、仿生机器人和医疗康复机器人等广泛应用领域。
《Sim-to-real transfer of adaptive control parameters for AUV stabilisation under current disturbance》– 弗林德斯大学、CNRS

自主水下机器人(AUVs)在海洋探索、目标跟踪和管道检测等任务中应用广泛,但在实际海洋环境中,复杂多变的海流扰动严重影响其控制精度和稳定性。传统基于模型的控制方法(如PID控制)在面对非线性海流干扰时表现有限,难以动态适应变化的水下环境。
弗林德斯大学与CNRS的研究团队针对这一挑战,提出了一种创新的控制方案——结合最大熵深度强化学习(Maximum Entropy DRL)与经典模型控制的自适应控制架构。深度强化学习为AUV控制提供了新思路,能够通过学习自主适应海流扰动,但DRL方法通常在模拟环境中训练,直接迁移到真实环境时会遇到分布偏移(distribution shift)问题。
研究的最大创新在于解决了“仿真到现实“(Sim-to-Real Transfer)迁移的难题。团队采用了生物启发经验回放机制(BIER)和增强域随机化(Domain Randomisation)技术。BIER使用双记忆缓冲区存储高质量的状态–动作对,提高训练稳定性;增强域随机化则通过在不同海流环境中训练,使AUV策略具备更好的泛化能力。这些方法结合起来,显著提高了控制策略在真实环境中的适应能力。
控制架构方面,研究团队将深度强化学习与传统PID控制巧妙融合,通过自适应极点配置(Adaptive Pole-Placement)优化PID控制器的增益参数。DRL模块负责学习最优的控制参数调整策略,使AUV能够根据当前海流状况实时优化控制效果。
仿真训练采用基于Gazebo的UUV模拟器,考虑真实水动力学效应,使用最大熵SAC算法(Soft Actor-Critic with Automatic Temperature Adjustment)结合自适应参数噪声探索策略。控制策略经过5000个仿真训练回合后稳定收敛,控制效果的均方根误差(RMSE)相较于传统PID控制降低了28%。
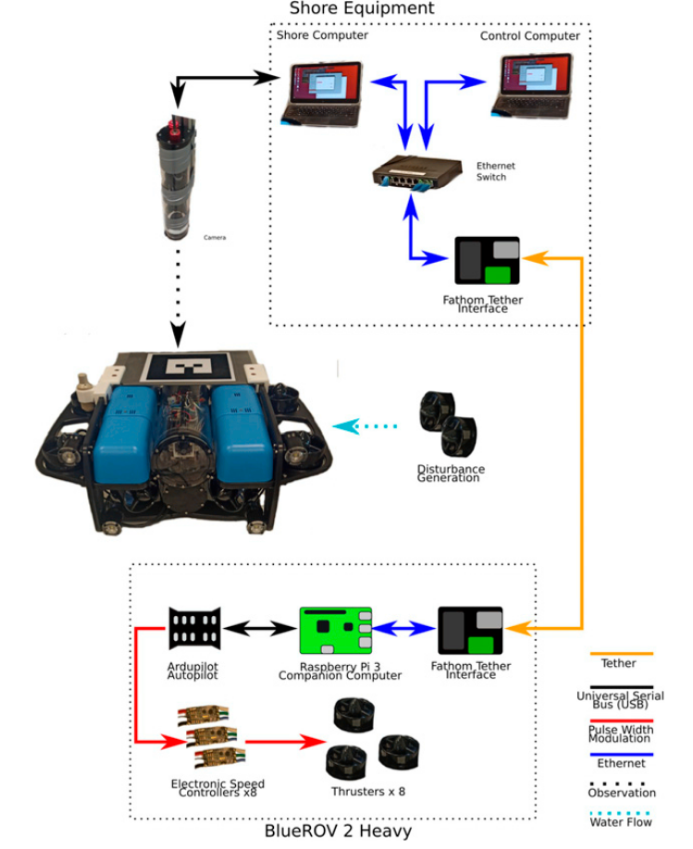
在真实环境测试中,研究团队使用BlueROV 2 Heavy平台在水池环境中进行实验,通过水流推进器模拟不同强度和方向的海流扰动。在无海流干扰的基础测试中,DRL自适应控制与传统PID控制表现相当,但在变速海流环境和随机海流扰动测试中,差距显著扩大——最大熵DRL控制方法比传统PID控制提高了3倍的控制精度!即使在极端扰动条件下,DRL控制策略仍能保持较好的控制性能,而传统PID方法则表现出较大误差。
这项研究不仅提供了一种水下机器人控制的新思路,也为其他受环境扰动影响的机器人系统提供了借鉴。未来,研究团队计划进一步优化SAC算法提高控制稳定性,将该方法扩展到更多AUV任务如自主探测、目标跟踪和协同控制,并结合视觉或声呐传感器,提高AUV对环境的感知能力,实现更智能的海洋探索和监测。
《A morphology-centered view towards describing bats dynamically versatile wing conformations》– 加州理工学院、东北大学
蝙蝠的飞行能力一直是仿生机器人研究的圣杯之一。这些夜行哺乳动物能够通过高度灵活的翼膜执行令人惊叹的空中机动,产生周期性空气射流,形成脉动尾迹结构,从而实现卓越的敏捷性和飞行效率。然而,将这种动态翼变形能力迁移到微型飞行器(MAVs)上一直面临巨大挑战。
加州理工学院和东北大学的研究团队针对这一困境,提出了一种革命性的设计理念——”以形态为中心“(Morphology-Centered)的飞行器设计方法。与传统设计思路不同,该方法将硬件结构本身视为一种计算资源,通过拓扑优化和执行器分布优化,使飞行器结构不仅承载组件,还能执行计算任务。这一理念被称为“计算结构“(Computational Structures),它巧妙地减少了对高功率执行器和传感器的依赖。
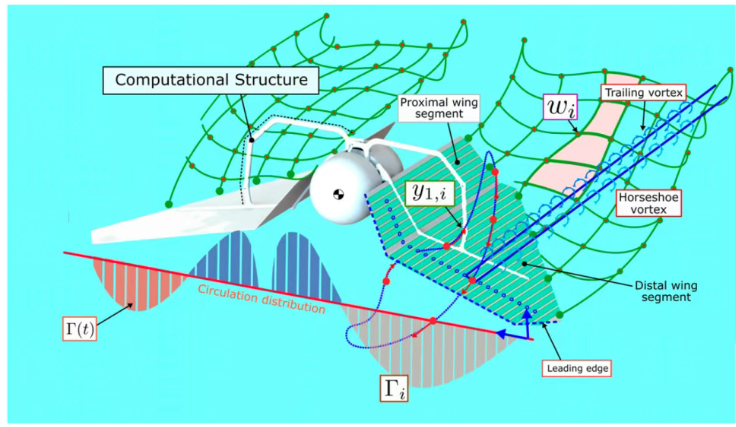
研究团队基于这一理念开发了名为“Aerobat”的原型机,其核心设计目标包括两个方面:使用有限的高功率执行器生成基础飞行动作模式(Gait Generation),同时利用低功率执行器进行微调(Gait Regulation)。这种多层级控制架构使得Aerobat能够在结构层面实现类似蝙蝠的动态翼变形。
研究者们还提出了一种约束动力学模型(Constrained Dynamics),在有限执行器条件下实现翼展调节,极大提高了飞行稳定性。最令人印象深刻的是,团队开发了基于翼表面积最大化和翼升时间最小化的气动力增强机制:通过优化下挥拍(downstroke)阶段的翼表面积,最大化升力输出;通过减少上挥拍(upstroke)时间,最小化负升力对飞行效率的影响。
在模拟实验中,研究团队采用非稳态升力线理论(Unsteady Lifting Line Theory)和瓦格纳函数(Wagner Function)构建了高精度的空气动力学模型,系统性地优化了翼形结构参数,包括翼展、翼弦长和扫掠角,在提升升力和降低阻力之间找到了最佳平衡点。
真实环境测试表明,Aerobat在无绳状态下(Untethered)成功实现了稳定悬停,即使在狭小空间内也能保持精确的位置控制。飞行模式验证实验展示了Aerobat利用少量高功率执行器生成基础飞行动作,并通过多个低功率执行器实现精细调节的能力。空气动力学增强实验则验证了优化翼形在下挥拍阶段提升气动力输出,在上挥拍阶段减少阻力的预期效果。
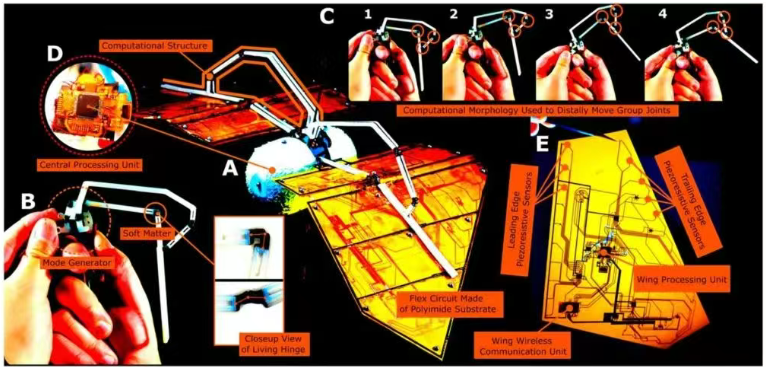
这项研究不仅推进了仿生飞行领域的技术边界,更为未来微型飞行器设计提供了全新思路。“计算结构“的概念打破了传统飞行器设计中结构与控制分离的思维定式,开创了一种硬件层面的智能控制范式。未来,研究团队计划进一步优化控制策略,提高复杂环境适应能力,探索多飞行器协同飞行模式,并将这种设计理念拓展至其他仿生飞行器,如鸟类启发的可变翼MAV。
《Transfer learning in robotics: An upcoming breakthrough? A review of promises and challenges》– 卡尔斯鲁厄理工学院等多机构合作研究
人类能够轻松将认知和运动技能迁移到新环境和任务中,而机器人系统的迁移能力却相对薄弱,这严重限制了其在真实世界中的应用范围。迁移学习(Transfer Learning, TL)作为解决这一问题的关键技术,近年来在机器人领域引起了广泛关注。
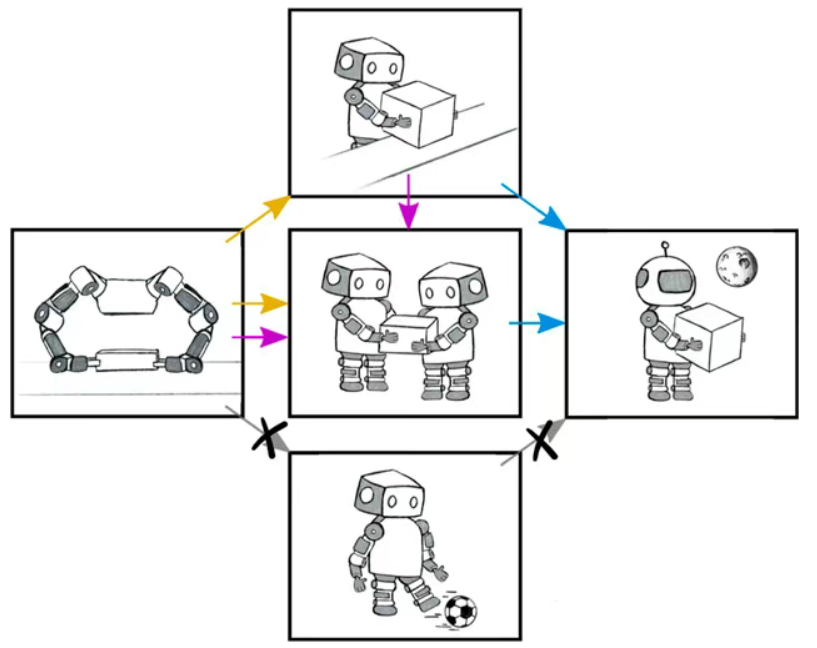
来自卡尔斯鲁厄理工学院、瑞典皇家理工学院、约瑟夫·斯特凡研究所、洛桑联邦理工学院和卢布尔雅那大学的研究团队合作完成了这项全面综述研究,首次为机器人迁移学习领域建立了统一的定义和分类框架。研究团队以机器人(Robot)、任务(Task)和环境(Environment)作为三大关键维度,提出了五种基本迁移模式:
1. 机器人迁移(Robot Transfer):将同一任务在不同机器人之间迁移,如将抓取技能从一个机械臂迁移到另一个不同结构的机械臂。
2. 环境迁移(Environment Transfer):将同一任务在不同环境中迁移,最典型的例子是从模拟环境迁移到现实世界(Sim-to-Real)。
3. 任务迁移(Task Transfer):同一机器人在不同任务之间迁移技能,如将抓取技能迁移到组装任务。
4. 双模式迁移(Dual-Mode Transfer):同时跨越两个维度,如机器人和任务或任务和环境同时变化。
5. 三模式迁移(Triple-Mode Transfer):最复杂的情况,机器人、任务和环境三者都不同的情况下进行迁移。
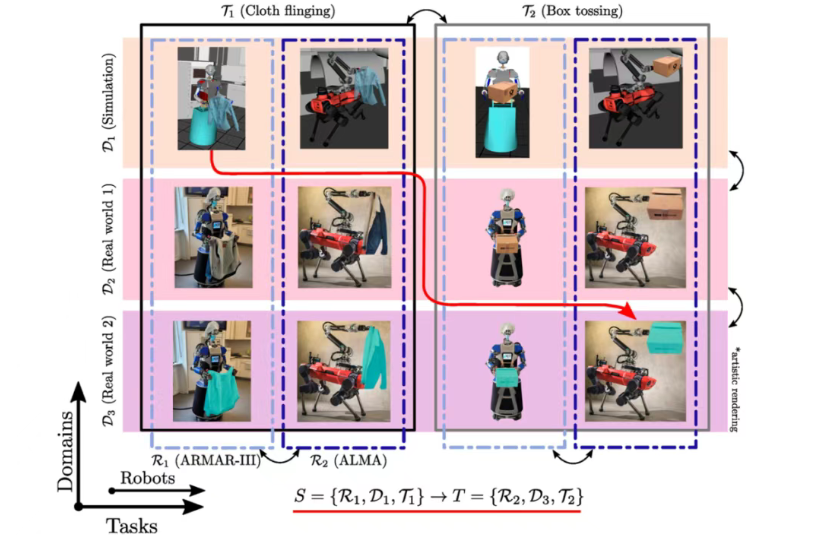
研究团队通过分析近年ICRA和IROS会议上的论文发现,迁移学习相关研究呈现爆发式增长趋势。其中,模仿学习和行为克隆研究最早兴起并已广泛应用;Sim-to-Real迁移和域适应近年来获得更多关注;而任务迁移仍是研究的薄弱环节,表明跨任务泛化仍是一个待解决的重大挑战。
论文详细分析了当前机器人迁移学习的成功案例。在Sim-to-Real迁移中,域随机化(Domain Randomization)方法使机器人在模拟环境中的训练成果能够泛化到现实世界,例如四足机器人控制和机械臂抓取任务中取得了显著成功。在任务迁移方面,研究表明机器人可以在投掷任务和抓取任务之间部分共享策略,但仍需要任务调整机制来适应新任务的特殊要求。跨机器人迁移则展示了人形机器人和机械臂可以通过运动重定向(Motion Retargeting)共享操作策略,尽管形态差异带来了运动学约束上的挑战。
研究团队特别强调了负迁移(Negative Transfer)的风险。当两个任务、环境或机器人之间的相似性不足时,迁移可能会降低而非提高性能。例如,将双臂机器人操作策略直接应用于单臂机器人时,可能导致执行失败。为应对这一挑战,团队提出了量化迁移质量和迁移误差的标准体系。
未来研究方向方面,论文指出了三个关键挑战:建立跨抽象层级的通用表示方法,从低级控制(如关节角度)到高级任务(如自然语言指令);开发通用的迁移评估标准,包括迁移误差度量和迁移成功率;探索大规模预训练模型在机器人迁移学习中的应用潜力,如基于Transformer的机器人控制模型。
这篇综述性研究不仅梳理了机器人迁移学习的研究现状,更为该领域的未来发展提供了清晰路线图,展现了未来机器人系统可能实现的灵活学习和适应能力。
《Certifiably optimal rotation and pose estimation based on the Cayley map》– 多伦多大学
在机器人导航、计算机视觉和传感融合领域,准确估计物体旋转和位姿一直是个核心挑战。传统方法往往陷入局部最优解,在噪声数据面前显得脆弱不堪。多伦多大学的研究团队针对这一问题,带来了一场算法突破。
研究者们注意到,现有凸松弛方法大多基于矩阵von Mises-Fisher分布,假设旋转误差是各向同性的,这种假设在许多应用场景下并不成立。为突破这一限制,团队提出了基于Cayley映射的全局优化框架,这一方法巧妙地将非凸的旋转估计问题转化为二次约束二次规划(QCQP),再松弛为半定规划(SDP),从而实现全局最优求解。
Cayley映射相比传统使用的指数映射有何优势?研究表明,Cayley Map具有更简单的代数结构,在计算上比指数映射更高效,并且在小角度误差情况下表现与指数映射相近。这种数学技巧使得优化问题更易于转换并求解,同时保持了几何意义的完整性。
最令人印象深刻的是该方法的广泛适用性,包括:旋转平均(多个旋转测量的最优合成)、位姿平均(多个位姿测量的最优合成)、离散时间轨迹估计(基于多个测量点重建刚体轨迹)和连续时间轨迹估计(结合高斯过程进行轨迹平滑)。研究团队还通过引入冗余约束提高了SDP松弛的紧致性,确保解的全局最优性。
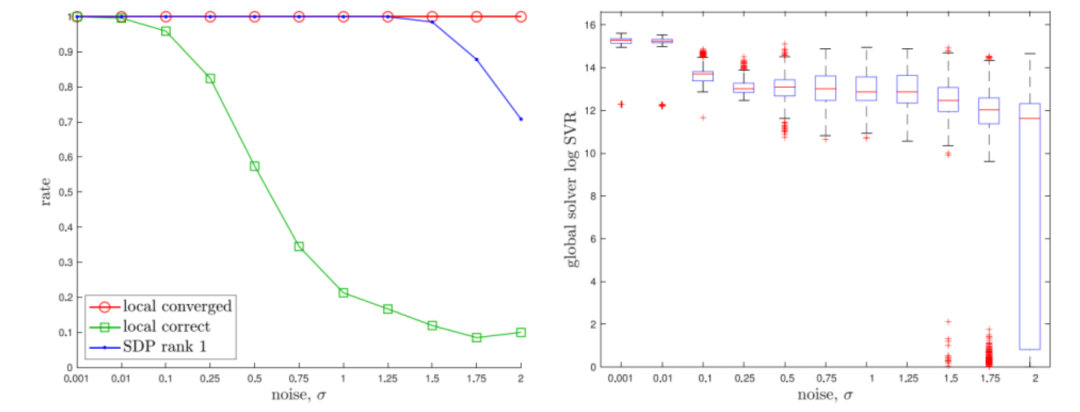
实验结果表明,在旋转平均任务中,SDP方法在98%的情况下找到全局最优解,而传统局部方法在高噪声环境下频繁陷入局部最优。在位姿平均实验中,SDP求解的最优解误差比局部方法降低了40%以上。对于离散时间轨迹估计,局部方法在45%的情况下陷入局部最优,而SDP方法在100%试验中找到全局最优解。
计算成本是这种方法的挑战——SDP在10个旋转变量时的求解时间为0.35秒,而局部方法约为0.0012秒。在轨迹估计任务中,SDP约需14.32秒,远高于局部方法的0.1574秒。但在精度至关重要的应用中,这种“确保全局最优“的特性弥足珍贵。
未来,该团队计划进一步优化SDP计算效率,使其适用于更大规模的位姿估计问题,并探索在实时SLAM系统中的应用,实现高精度、全局最优的地图构建。结合深度学习或强化学习优化Cayley映射模型,提升旋转和位姿估计的适应性,也是一个充满潜力的方向。
IJRR三月份的这六篇重磅论文充分展示了机器人技术在多个前沿领域的最新突破。从全局最优的位姿估计到软体机器人的混合建模,从水下机器人的自适应控制到仿生飞行器的形态优化,从机器人迁移学习的系统框架到四足机器人的接触隐式控制,这些研究不仅推动了理论创新,更为实际应用提供了可靠解决方案。
这些技术的共同特点是跨学科融合和技术创新,包括将先进数学理论应用于工程实践、结合物理模型与数据驱动方法、引入生物启发机制、建立系统化的知识迁移框架、以及开发不依赖预定义规则的自适应控制策略。这些创新共同推动着机器人技术向更加智能、灵活和自适应的方向发展。
如果您对这些研究感兴趣,欢迎深入阅读原论文(下方为相关信息),探索机器人技术的更多可能!
[1] Kim, Gijeong, et al. “Contact-implicit Model Predictive Control: Controlling diverse quadruped motions without pre-planned contact modes or trajectories.” The International Journal of Robotics Research (2024): 02783649241273645
[2] Bruder, Daniel, David Bombara, and Robert J. Wood. “A Koopman-based residual modeling approach for the control of a soft robot arm.” The International Journal of Robotics Research (2024): 02783649241272114.
[3] Chaffre, Thomas, et al. “Sim-to-real transfer of adaptive control parameters for AUV stabilisation under current disturbance.” The International Journal of Robotics Research (2024): 02783649241272115.
[4] Sihite, Eric, and Alireza Ramezani. “A morphology-centered view towards describing bats dynamically versatile wing conformations.” The International Journal of Robotics Research (2024): 02783649241272132.
[5] Jaquier, Noémie, et al. “Transfer learning in robotics: An upcoming breakthrough? A review of promises and challenges.” The International Journal of Robotics Research (2023): 02783649241273565.
[6] Barfoot, Timothy D., Connor Holmes, and Frederike Dümbgen. “Certifiably optimal rotation and pose estimation based on the Cayley map.” The International Journal of Robotics Research (2024): 02783649241269337.
(文:机器人大讲堂)