

 关注我,记得标星⭐️不迷路哦~
关注我,记得标星⭐️不迷路哦~
✨ 1: Lumina-mGPT 2.0
Lumina-mGPT 2.0是上海AI实验室等机构发布的自回归图像生成模型,支持多种图像生成任务。
Lumina-mGPT 2.0 是一个独立的、仅解码器的自回归图像生成模型,从头开始训练,能够统一处理多种图像生成任务,包括:
- 文本到图像生成
- 图像对生成
- 主题驱动生成
- 多轮图像编辑
- 可控生成
- 密集预测
地址:https://github.com/Alpha-VLLM/Lumina-mGPT-2.0
✨ 2: AnimeGamer
AnimeGamer是一个动漫生活模拟器,它能根据指令生成动态动画和角色状态,预测游戏状态。
AnimeGamer 是一个无限动漫生活模拟器,它使用多模态大型语言模型(MLLM)来模拟一个动漫世界,并预测下一时刻的游戏状态。用户可以通过开放式的语言指令与这个动态世界互动,就像扮演动漫角色一样,例如《悬崖上的金鱼姬》里的宗介。
主要功能和特点:
- 生成连贯的多回合游戏状态:
包括动态的动画镜头(视频),以及角色状态的更新,例如体力、社交和娱乐值。 - 跨动漫角色互动:
允许来自不同动漫的角色(如《魔女宅急便》的琪琪和《天空之城》的巴鲁)相遇并互动。 - 基于动作的多模态表示:
使用编码器模拟动画镜头,训练基于扩散的解码器来重建视频,并附加动作范围指示动作强度。 - 使用MLLM进行游戏状态预测:
训练MLLM通过历史指令和游戏状态来预测下一个游戏状态。 - 动画镜头质量提升:
通过微调解码器,提升MLLM预测的动画镜头的质量。
地址:https://github.com/TencentARC/AnimeGamer
✨ 3: DeepResearcher
DeepResearcher是一个基于强化学习的LLM研究框架,通过真实网络环境训练,涌现认知能力,性能显著提升。

DeepResearcher是一个基于强化学习的框架,旨在端到端地训练基于LLM(大型语言模型)的深度研究代理,使其能够通过真实的Web搜索交互在现实世界环境中进行研究。
核心特性:
- 端到端强化学习训练:
这是DeepResearcher的核心,通过强化学习直接优化LLM的研究能力。 - 真实的Web搜索交互:
代理直接与真实的网络搜索环境交互,而不是使用模拟数据。 - 涌现的认知行为:
通过训练,代理展现出规划、交叉验证信息、自我反思和诚实等认知行为。
地址:https://github.com/GAIR-NLP/DeepResearcher
✨ 4: Mobile Next
Mobile Next是一个MCP服务器,通过平台无关的界面,实现可扩展的移动自动化,无需特定iOS或Android知识。
Mobile Next 是一款基于 Model Context Protocol (MCP) 的服务器,旨在简化和扩展移动自动化测试和交互。它提供了一个平台无关的接口,使 Agent 和 LLM (大型语言模型) 能够与原生 iOS 和 Android 应用进行交互,而无需深入了解特定的操作系统细节。Mobile Next 主要通过两种方式实现交互:一是利用结构化的可访问性快照 (Accessibility Snapshot),二是基于屏幕截图的坐标点击。
Mobile Next 的主要特点:
- 快速轻量级:
优先使用原生可访问性树进行交互,在没有可访问性标签时才使用屏幕截图坐标。 - 对 LLM 友好:
在使用 Accessibility Snapshot 时,无需计算机视觉模型。 - 视觉感知:
分析屏幕上的实际渲染内容,以确定下一步操作。 - 确定性工具应用:
尽可能依赖结构化数据,减少纯粹基于屏幕截图方法的不确定性。 - 结构化数据提取:
能够从屏幕上可见的任何内容中提取结构化数据。
地址:https://github.com/mobile-next/mobile-mcp
✨ 5: Zola
Zola是一款免费开源AI聊天应用,支持多模型,提供文件上传等功能,正处于Beta测试阶段。
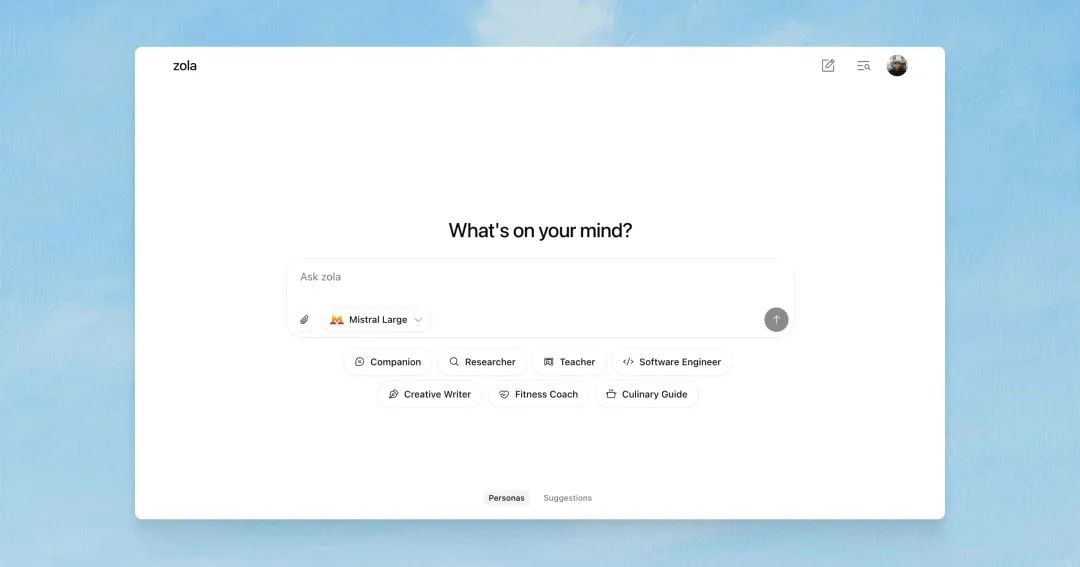
Zola 是一个免费、开源的 AI 聊天应用程序,它支持多模型,例如 OpenAI 和 Mistral。它拥有轻量级和暗黑模式,提供 prompt 建议,支持文件上传,并且布局针对移动设备进行了优化。
地址:https://github.com/ibelick/zola
(文:每日AI新工具)