
一招缓解LLM偏科!调整训练集组成,“秘方”在此上交大&上海AILab等
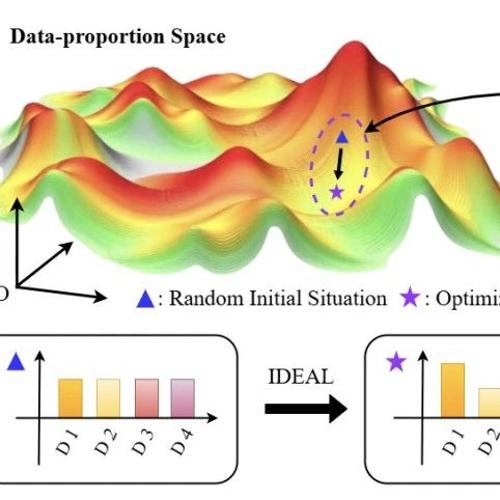
MLNLP社区发布了一项创新方法IDEAL,用于解决大型语言模型(LLM)在多任务场景下可能出现的偏科现象。通过调整监督微调(SFT)训练集组成,研究团队发现优化后的模型在多种领域上的综合性能显著提升。
MLNLP社区发布了一项创新方法IDEAL,用于解决大型语言模型(LLM)在多任务场景下可能出现的偏科现象。通过调整监督微调(SFT)训练集组成,研究团队发现优化后的模型在多种领域上的综合性能显著提升。

上海交通大学及上海AI Lab联合团队提出IDEAL方法,通过调整SFT训练集的组成来提升LLM在多种领域上的综合性能。研究发现增加训练数据数量并不一定提高模型整体表现,反而可能导致“偏科”。

上海AI实验室提出GraphGen,通过知识图谱引导和双模型协同机制提升垂域大模型训练中的问答数据质量。研究团队在OpenXLab平台上推出Web应用,方便用户生成适应LLaMA-Factory和XTuner的高质量训练数据。

上海AI实验室升级并开源了通用多模态大模型书生·万象 3.0 (InternVL3),在多模态能力方面取得显著突破,成为开源模型中的性能新标杆。

Lumina-mGPT 2.0发布,支持多种图像生成任务;AnimeGamer模拟动漫生活互动,基于MLM预测游戏状态;DeepResearcher通过强化学习训练LLMs;Mobile Next简化移动自动化测试;Zola免费开源AI聊天应用,支持多模型和文件上传。

上海AI实验室展示了自主生成高智力密度数据的’模型’并开放了强推理模型’书生·InternThinker’。该模型能进行长思维、自我反思和修正,显著提升复杂任务处理能力。研究团队采用了元动作思考范式和通专融合的数据合成方法来增强推理策略的学习效率。
上海AI实验室展示了自主生成高智力密度数据的进展,并开放了具备长思维能力的InternThinker模型。该模型能在多种复杂推理任务上取得更优结果,采用了接近人类学习方式的设计,强化了元动作和元认知能力,从而提升其学习效率和解题优势。

国产o1新选手登场,上海AI实验室版o1——书生InternThinker能快速解决数学、代码编程等任务,并能在推理过程中进行自我反思和纠正。其长思维能力提升显著,已在数学、代码及逻辑谜题等多种场景中展现优势。

