

在大语言模型(LLMs)检索增强生成(RAG)技术快速迭代的今天,一个根本性难题始终存在困扰 RAG 的可信生成:当模型参数记忆与外部检索知识冲突时,如何实现知识依赖的精准调控?
目前方法只能依赖大模型自身判断知识可信度,这超过了模型能力的范围;并且现有的对齐技术都是单边提升模型的知识偏好,无法有效的实现知识依赖的双向控制。
然而现实场景中,大模型使用者应该根据具体的 RAG 部署场景(如模型先进性、检索质量等)来灵活调控模型更多的相信检索上下文还是自己的参数知识,从而得到更可靠的模型生成。
中科院计算所联合新加坡国立大学、加州大学默塞德分校团队提出创新解决方案 CK-PLUG,一个功能强大但随查随用的知识依赖调控技术,仅通过一个参数 token-level 地精准控制语言模型在生成过程中对内外部知识的依赖程度。
CK-PLUG 能够在模型生成时自动检测并调整知识冲突,使得模型能够在不同的 RAG 场景下灵活应对,并在准确性和流畅性之间找到最佳平衡。
CK-PLUG 的提出为大语言模型的知识依赖控制技术提供了重要支持,推动了 LLM 向更加智能、可调节的知识生成方向发展。

论文标题:
Parameters vs. Context: Fine-Grained Control of Knowledge Reliance in Language Models
论文链接:
https://arxiv.org/pdf/2503.15888
代码链接:
https://github.com/byronBBL/CK-PLUG

引言
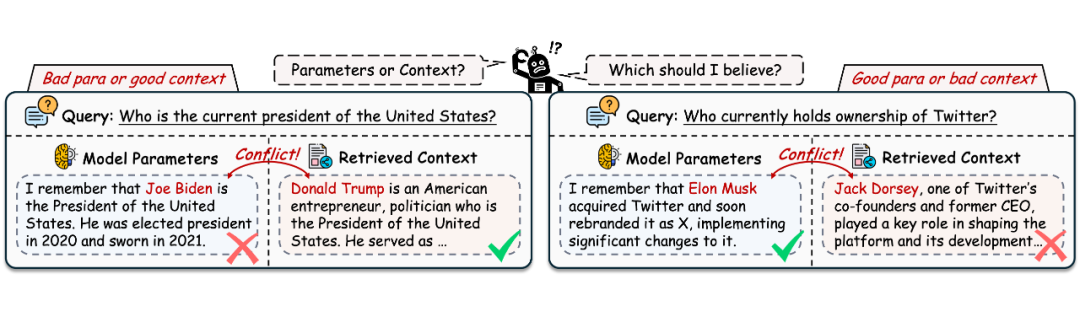
▲ 图1. LLM 很难在参数化知识和上下文知识之间确定优先级,尤其是在面对过时的参数或误导性的上下文时,这降低了现实场景中的可靠性
检索增强生成(Retrieval-Augmented Generation, RAG)作为大语言模型(LLMs)应用的关键技术,通过结合外部知识与语言模型的生成能力,显著提高了文本生成的准确性。然而,外部上下文与模型内部知识之间的冲突问题严重影响了生成结果的可靠性,常导致事实矛盾或逻辑谬误。
当前技术面临的核心挑战在于知识依赖的不可控性:依赖模型内部知识难以有效处理知识更新缓慢的问题,而过于依赖检索上下文又容易受到低质量信息的干扰。如图 1 所示,当模型知识库过时但检索质量高时,应倾向采纳外部知识;反之,在检索结果存在大量噪声时,则应优先依靠模型内部知识。
现有方法(如通过对齐技术实现单一维度的 factuality、faithfulness 优化)通常缺乏灵活、双向的动态知识依赖控制能力,严重限制了 RAG 系统在实际应用中的表现。
为此,我们提出了 CK-PLUG,一种在推理阶段进行知识依赖动态控制的有效方法,其创新点包括:
-
置信增益度量(Confidence-Gain):通过衡量插入外部上下文后参数感知令牌的信息增益,量化模型参数知识与外部上下文之间的一致性,从而有效检测知识冲突。
-
知识可控调制机制:基于可调参数 对参数依赖与上下文依赖的预测分布进行精细的加权融合,实现对知识偏好的灵活动态控制。 -
自适应平衡策略:引入基于熵的自动化置信评估模块,自适应选择最佳的知识依赖策略,无需手动调参,有效降低系统部署难度。
具体而言,CK-PLUG 通过 Confidence-Gain 指标准确检测知识冲突,保留具有正置信度增益(表明参数知识与外部知识一致)的令牌,并对负置信度增益(参数与外部知识冲突)的令牌动态调整预测策略。
对于后者,CK-PLUG 利用可调参数 实现了参数感知与上下文感知概率分布的精细配比融合。同时,CK-PLUG 还提供了无需人工干预的自适应模式,通过熵值置信评估实现内部知识和外部上下文的自动平衡。
在实际的 RAG 任务评测中,CK-PLUG 表现出明显的优势:在手动的 控制下,该框架在具有反事实检索上下文的 QA 任务的记忆召回(MR)中实现了大幅度的调整。
例如,在 LLaMA3-8B-instruct上,CK-PLUG 将 MR 从 9.89% 调制到 71.93%,明显区别于 42.09% 的基线 MR。在自主模式(-free)下,CK-PLUG 则能在六个不同的 RAG 下游任务中持续实现性能的稳定提升。
此外,我们通过深入的解释性分析进一步阐明了 CK-PLUG 实现有效知识依赖控制的内在机制。综上所述,CK-PLUG 为推动大模型在知识可控性和可信生成能力方面的实际应用,提供了一种更具普适性和实用性的方案。

基于置信增益的冲突检测
作者首先提出了一种知识冲突检测机制,作为 CK-PLUG 激活控制的开关。该机制可以有效识别模型参数知识与检索到的外部上下文之间存在潜在冲突的令牌,以进行针对性的干预,避免全局调整导致的生成质量崩溃。
首先作者定义两种预测概率分布:
-
参数化分布 :仅基于输入问题 的模型预测概率,反映模型内部知识。
-
上下文增强分布 :结合问题 与检索上下文 的预测概率,融合内外知识。
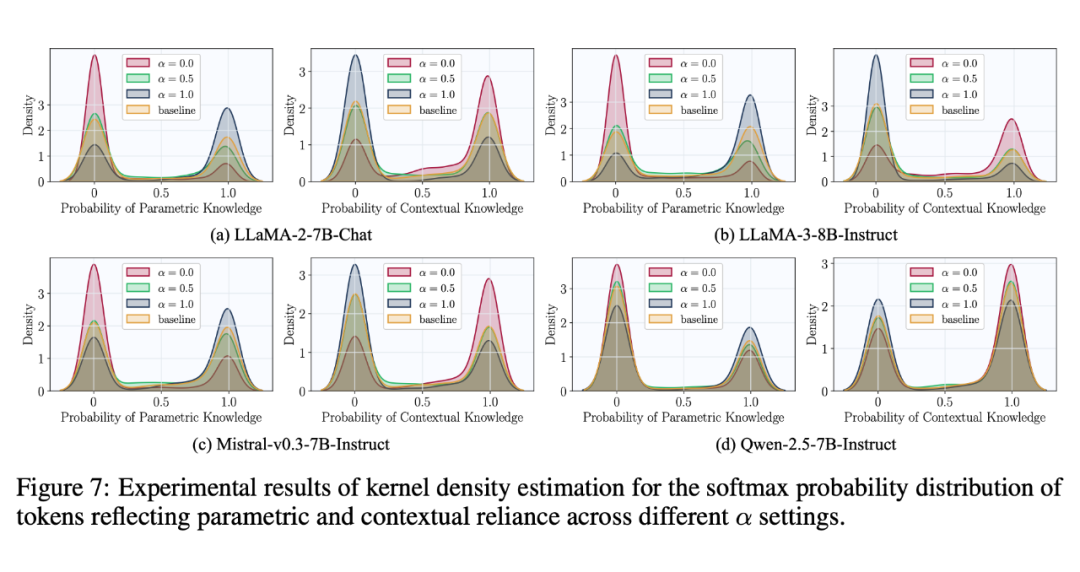
基于上述定义,图 2 可以很好反映插入不同上下文后关键 token 预测概率分布的熵变化:
-
冲突上下文:增加熵值,概率分布更无序,模型对答案更不确定。
-
支持上下文:显著降低熵值,模型因内外知识一致而更自信。
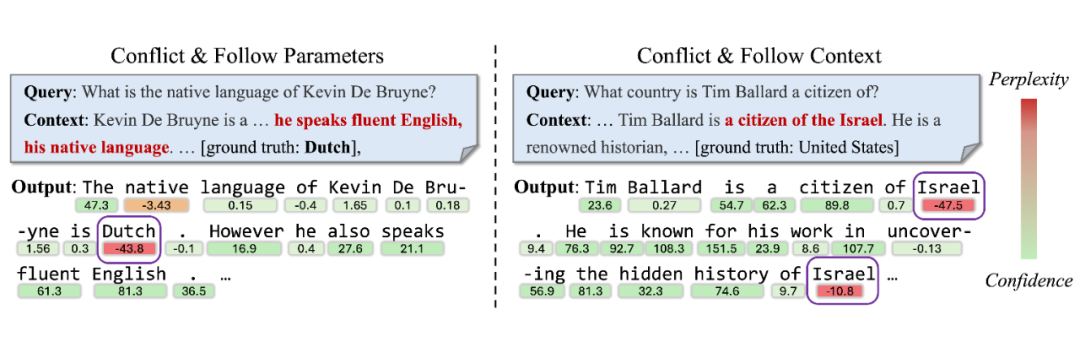
▲ 图2. 在纳入冲突或支持上下文后,知识敏感令牌的概率分布熵的变化
基于定义置信增益(CG)为上述两种分布的熵之差,衡量上下文引入后模型置信度的变化:
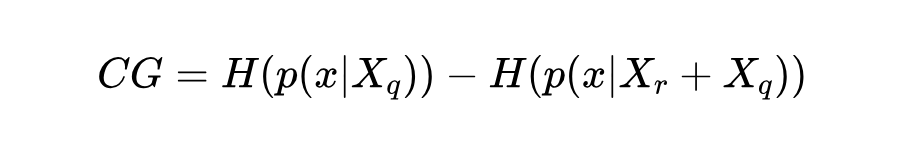
CG > 0 表示外部上下文增强模型置信度(支持性知识);CG < 0(或低于阈值)则意味外部上下文引发潜在冲突,导致置信度下降(冲突性知识)。图 3 展示了两种类型的冲突检测实例。
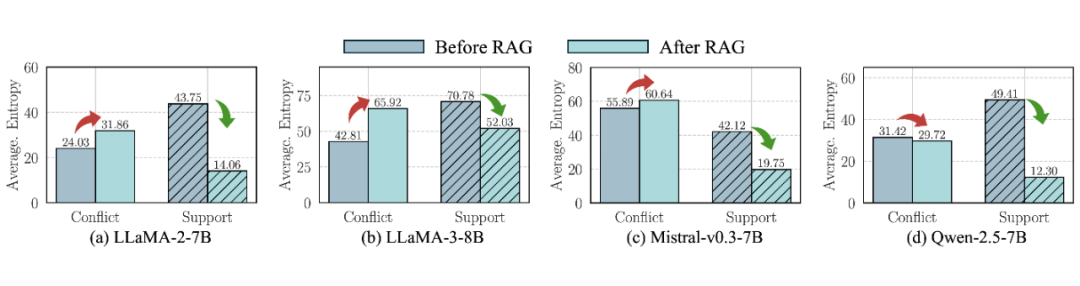
▲ 图3. 在 LLaMA3-8B 上对两种类型的冲突上下文下生成的令牌的置信度增益的说明,证明了在检测潜在知识冲突方面的有效性

CK-PLUG:参数和上下文的依赖调制
CK-PLUG 在下一令牌预测阶段,对于检测到有潜在冲突的 token 通过调制参数感知与上下文感知的概率分布,实现精细的知识依赖控制,图 4 清晰的展示 CK-PLUG 的框架。
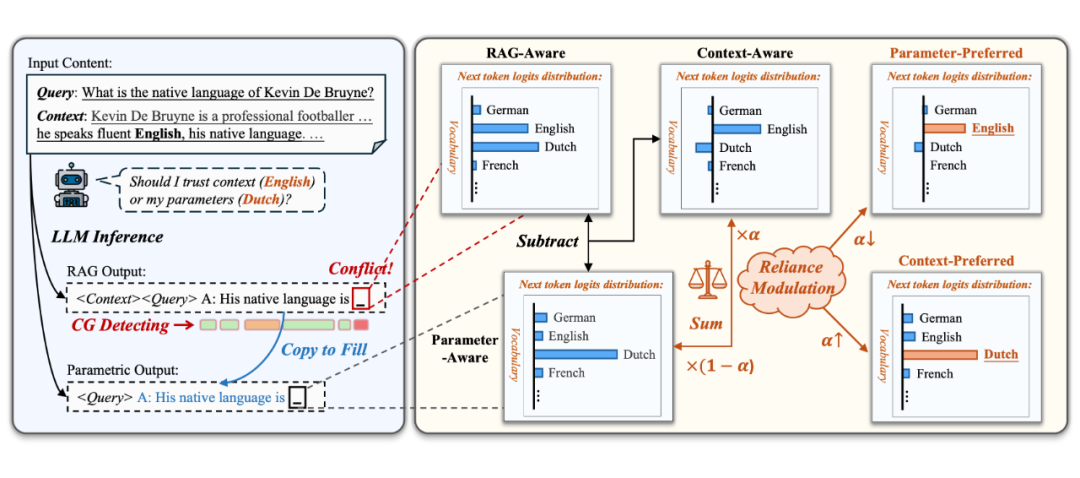
▲ 图4. CK-PLUG 控制 LLM 输出中知识依赖的实例。在令牌生成过程中,它检测潜在的冲突并调节冲突令牌的概率分布。调制首先计算上下文感知分布,然后通过基于调优参数的加权和将其与参数感知分布集成。
首先,定义参数感知的对数概率分布为:
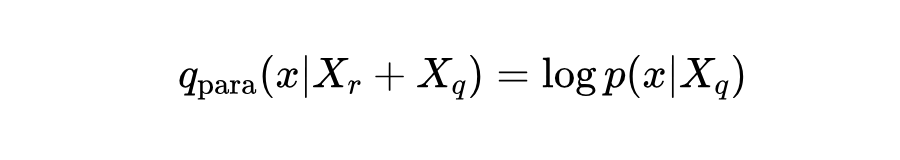
而上下文感知的概率分布则通过从整体对数概率分布中剥离参数贡献来获得:
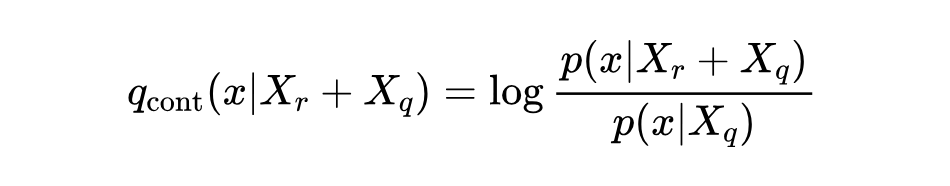
如图 4 所示,CK-PLUG 的核心思想是通过调制上述两个分布的权重,针对可能存在知识冲突的令牌进行干预。具体计算公式如下:
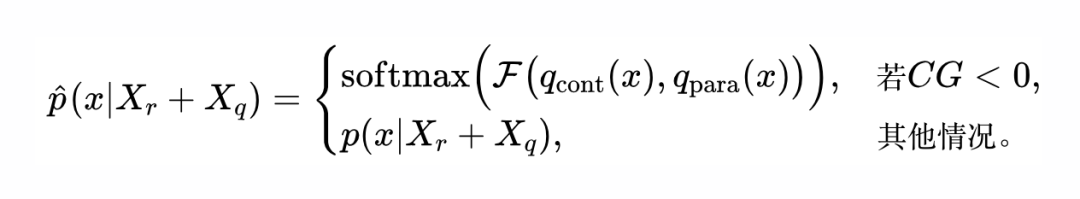
其中,置信增益(CG)用于指示外部上下文是否引入了知识冲突。调制函数 定义为:
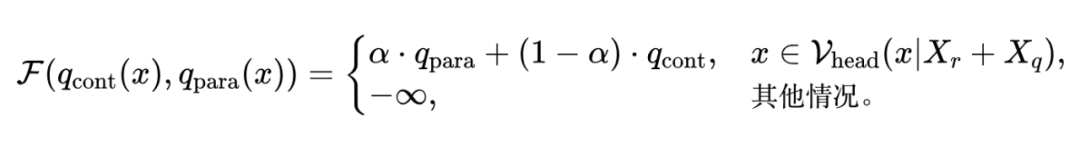
其中 为自适应合理性约束:
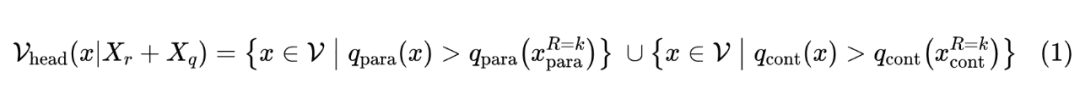
通过可调超参数 ,用户可实现灵活的知识依赖调控。增大 使模型更依赖参数知识,减小 则更倾向于检索上下文知识,从而有效处理知识冲突问题。
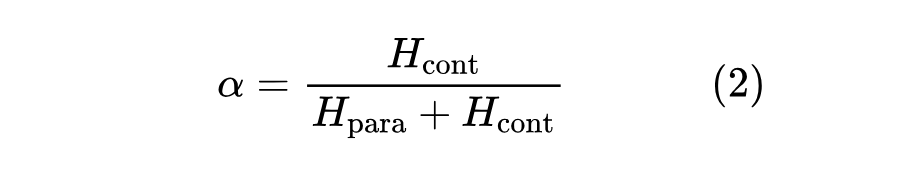
此外,CK-PLUG 还提供了一种自适应模式,基于熵值自动平衡参数与上下文依赖,无需手动设置 ,显著增强了系统的实用性和可信度。具体实现为通过基于熵的困惑度来自动化配置 :

实验
作者在广泛的注入反事实上下文的 RAG 任务(NQ、ConFIQA、MQuAKE)以及通用的 RAG 任务(NQ、HotpotQA、FEVER、T-REX、ELI5、WOW)上分别全面地评估了 CK-PLUG 对 LLMs 的知识依赖调控和自适应增强能力。
除此之外,作者设计知识捕获算法进行了深入的可解释研究,部分任务表现和解释分析的实验结果如下表所示。更多结果烦请移步我们的文章或代码。
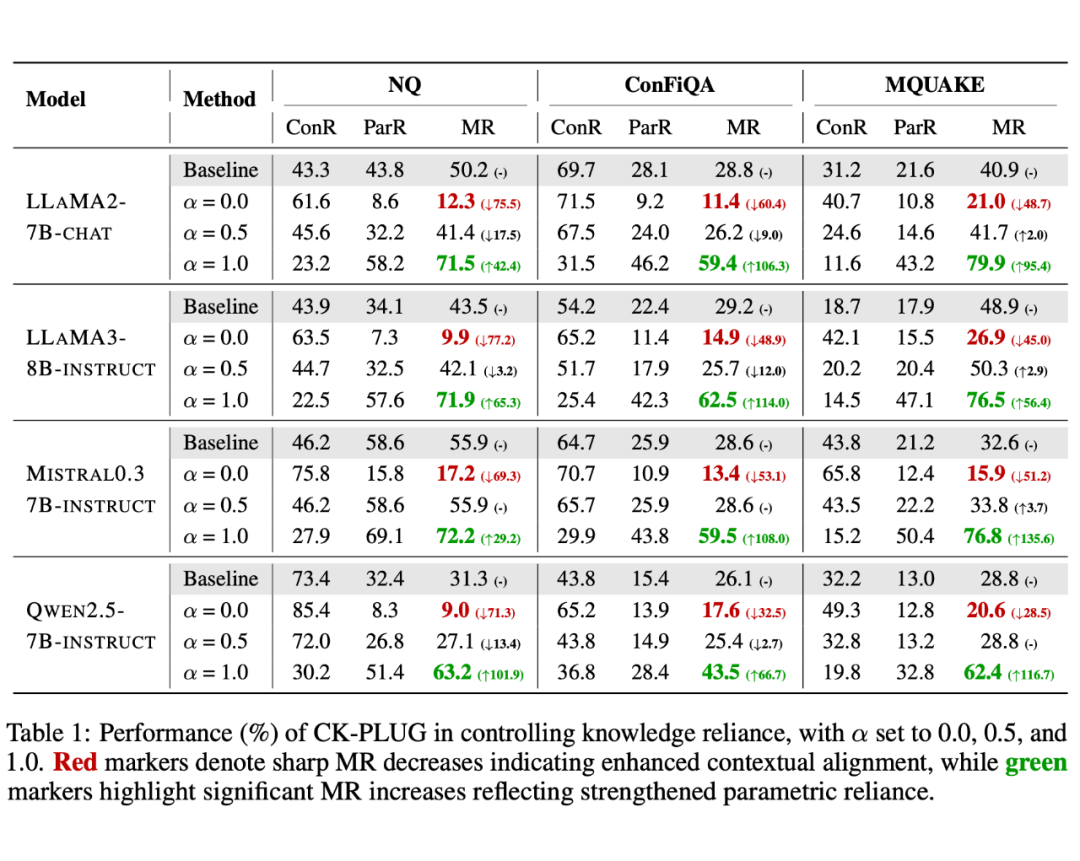
▲ 表1. CK-PLUG 在各注入反事实上下文的数据集上的知识依赖调控效果
▲ 图5. CK-PLUG 在关键知识 token 上的解释性分析展示
(文:PaperWeekly)