


“没有数据,就创造数据。”NVIDIA Cosmos World Foundation Models, CES 2025NVIDIA Cosmos World Foundation Models, CES 2025
摘要
本文主要描述了具身合成数据两条主要技术路线之争:“视频合成+3D重建”or “端到端3D生成”。参考自动驾驶的成功经验,前者模态转换链路过长导致误差累积,‘直接合成3D数据‘理论上有信息效率优势,但需要克服“常识欠缺”等挑战。
眼下,机器人流行视频中高难度动作(空翻、跳舞、格斗等)主要依靠遥控/预设编程完成的。机器人逐渐完善了自身运动控制能力,然而对外环境感知、推理能力有待完善。
数据是AI时代的石油。具身智能的突破高度依赖于数据驱动的训练。由于现实数据采集成本高,合成数据被推上了前台。它不只是“虚拟的替代品”,更可能是具身智能迈向通用能力的关键推动力。英伟达在CES 2025指出“尚无互联网规模的机器人数据”,自动驾驶已具备城市级仿真,但家庭等复杂室内环境缺乏3D合成平台。
为解决“常识欠缺”困境,沿用“端到端三维生成”的技术路径,生境提出“模态编码”的全新技术解决方案:打破“排布=几何”旧范式,将空间方案本身进行数字化编码、特征提取以及隐式学习。结合强化学习策略,探索一种新的可能:不仅生成空间,更生成“可被理解与使用”的空间。
01 具身智能的现实挑战
智能困境:强身体,弱大脑
在机器人的发展史中,“身体”往往走得比“大脑”更快。我们已经能让机器人精准行走、翻滚甚至跑酷,但当它们被放入一个陌生的房间,任务就变得不再简单。机器不懂墙后是什么,也不知道为什么沙发要靠墙放——更别提主动理解人类的意图。
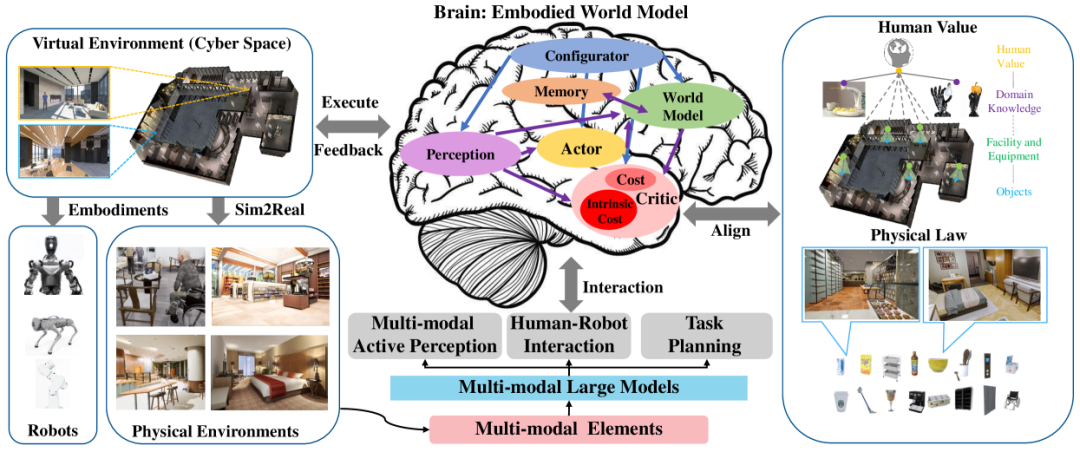
具身“大脑”整体框架 Aligning Cyber Space with Physical World: A Comprehensive Survey on Embodied AI, 09 Jul 2024
具身智能的本质,是“感知 + 推理 + 决策”的一体化能力。而这一切的前提,是系统必须拥有对空间的理解力。不是二维图像中的像素点,而是结构清晰、语义明确的三维场景知识。缺乏这种能力,即使控制算法再精妙,也难以支撑复杂环境下的自主行为。
今天的AI正处于一个临界点:算力与模型能力迅速提升,但如果没有足够优质的空间数据作支撑,“聪明的大脑”也无法真正落地。
数据困境
眼下的现实是,具身智能的数据,不但少,而且不够用。现有的数据来源大致可以分为三类:
•真实扫描数据(如 Matterport3D),数量有限且覆盖场景单一;
•游戏引擎搭建环境(如 AI2-THOR),生成效率低、交互性弱;
•开源合成数据集(如 SUNCG),语义标签粗略,缺乏物理一致性。
相比之下,自动驾驶领域已构建起完整的数据闭环,从城市建模到传感器仿真,链条清晰、效率高。而在室内具身智能场景中,空间数据不仅要“看起来像”,还要“行为上真实”——比如桌子不仅要有形状,还要能承重;门不仅要有铰链,还要能被打开。
更复杂的问题在于“家庭”。每个家庭都有独特的布置习惯和使用方式,这种多样性决定了:现实中几乎不可能采集到覆盖全部变体的训练数据。换句话说,靠传统手段“扫遍全世界”来训练模型,不现实,也不经济。

NVIDIA Cosmos World Foundation重大更新,用于大规模可控合成数据生成,2025 年 3 月 18 日
场景生成(Gen)与模拟(Sim)
机器人合成数据可拆解成两个关键部分::场景生成(Gen)与模拟(Sim)。
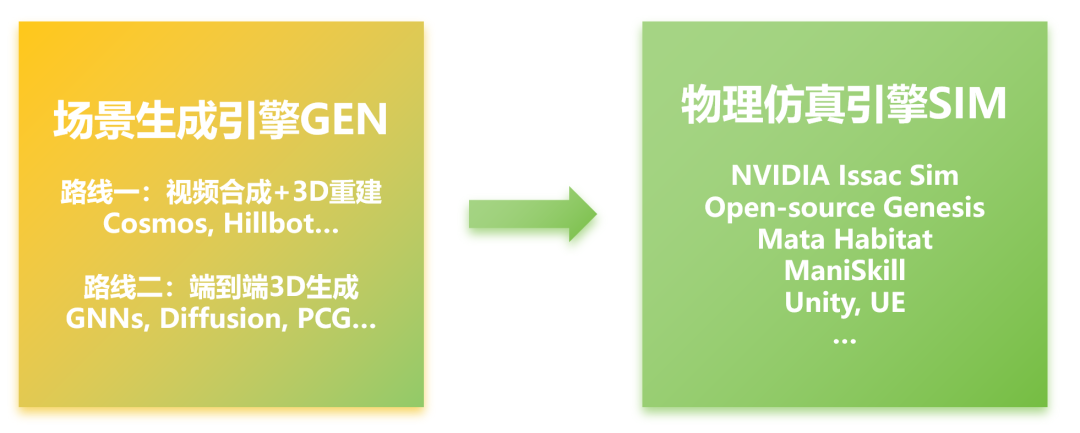
相比之下,丰富多样、结构合理的室内空间生成(Gen) 已成为系统性能瓶颈,主要存在两种技术路径:
1.合成视频+3D重建:基于像素流驱动,先生成视频或图像,再重建为点云或mesh等非结构化3D数据,最终转为结构化语义模型。如Hillbot、群核科技、李飞飞“World Models”项目等。此方法路径长、误差易累积,结构精度有限。
2.AIGC直接合成3D数据:利用图神经网络(GNN)、扩散模型(Diffusion)、注意力机制(Attention)等方法,直接合成结构化空间数据。如 ATISS、LEGO-Net、DiffuScene、RoomFormer 等代表模型,部分方案结合程序化生成技术,如 Infinigen(CVPR 2024)。
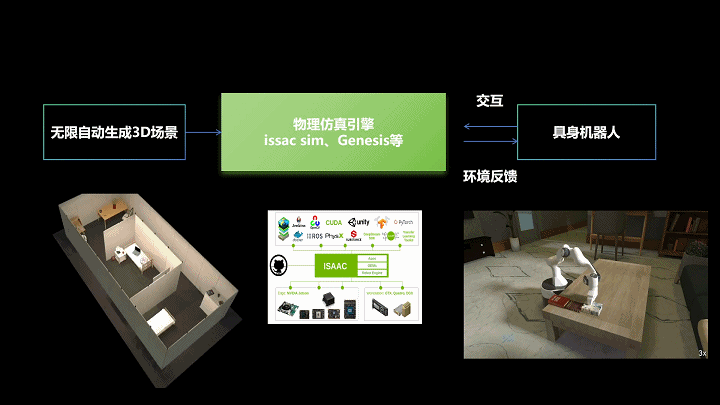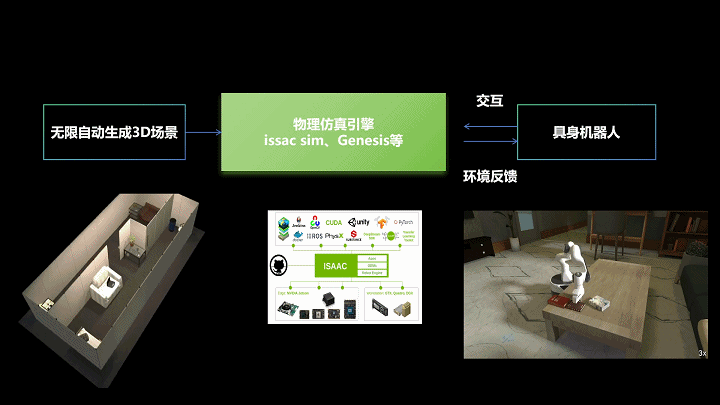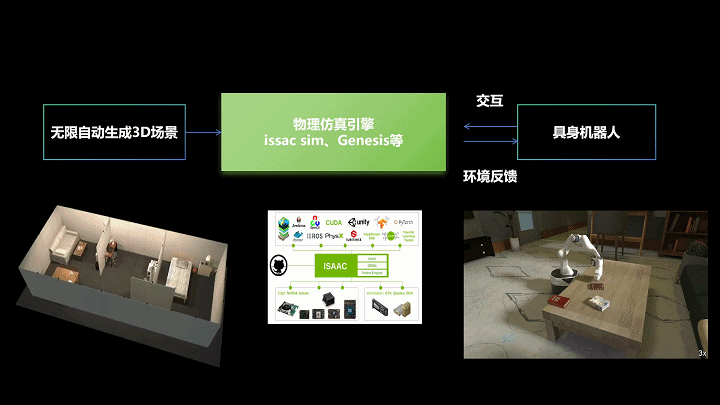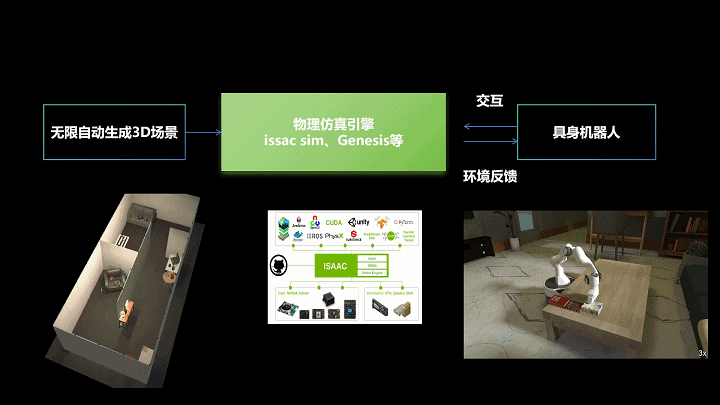
“3D场景合成+仿真模拟+现实交互”sim2real技术框架,生境科技绘制
02 路线一:视频合成+3D重建
早在2021年,李飞飞团队的 BEHAVIOR 基准及“世界模型”研究提出了基于像素和视频帧的具身智能建模思路,生成的场景仅为mesh壳体,缺乏清晰的空间结构和语义标注,物体边界模糊,难以直接用于物理仿真。
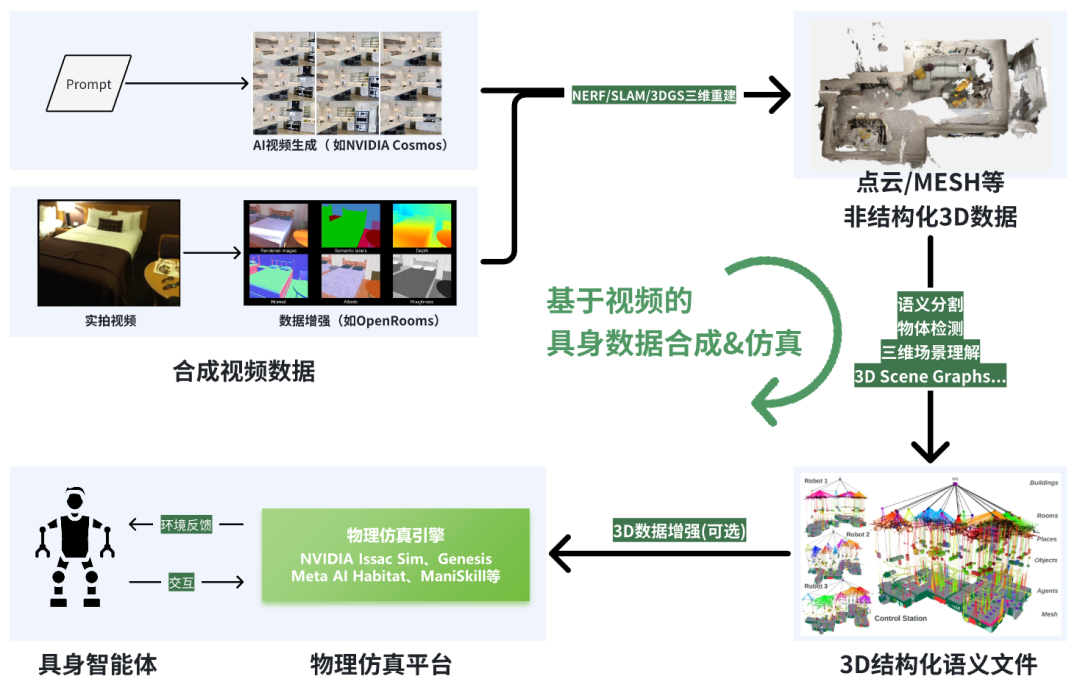
“视频合成+3D重建”技术路线,生境科技绘制
SpatialVerse + SpatialLM(群核科技)
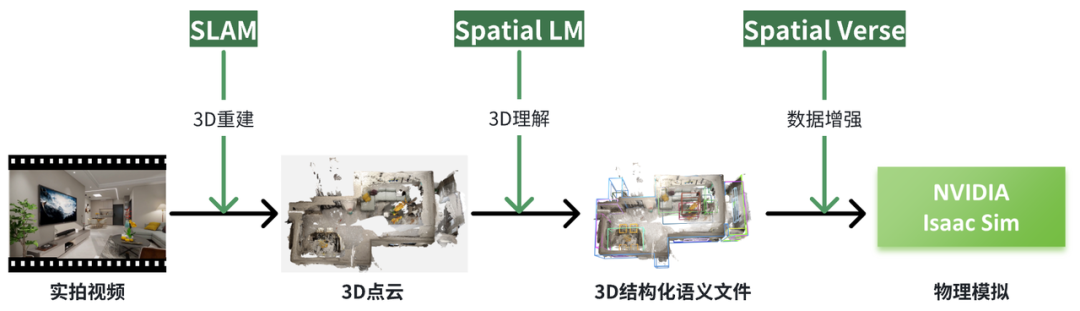
群核科技具身合成技术路线,生境科技基于公开资料绘制
群核科技的SpatialLM和SpatialVerse是该路线的代表性技术。SpatialLM通过微调大规模语言模型(LLM)来理解3D数据的语义,SpatialVerse则结合酷家乐的技术进行数据增强、分割注释和渲染优化。尽管该技术能够从视频中提取3D场景数据,但依然面临物理一致性和精度的问题。通过这种方式,机器人的路径规划和行为决策得到了增强,尽管从理论上来说,模态链路仍然是一个挑战 。

SpatialLM: Large Language Model for Spatial Understanding,群核科技,2025
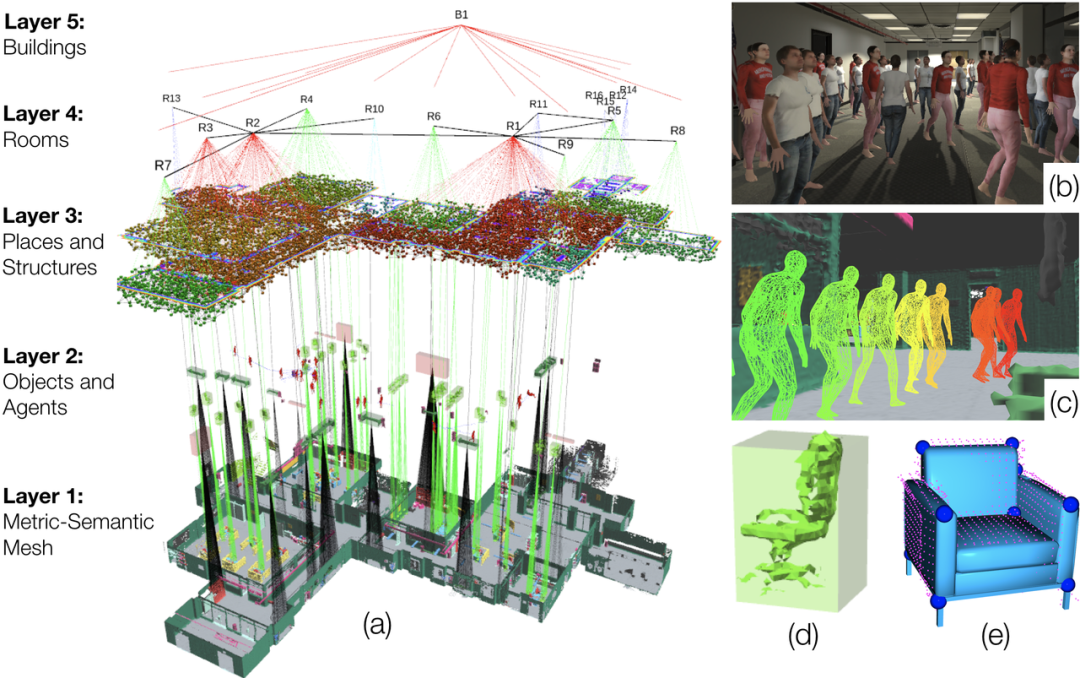
Kimera: from SLAM to Spatial Perception with 3D Dynamic Scene Graphs, MIT, 2021
Cosmos+Sapien/ManiSkill (Hillbot(美国))
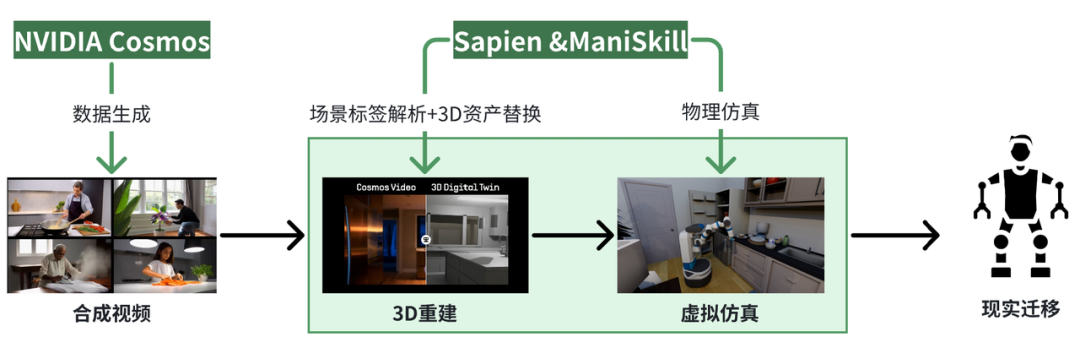
Hillbot具身合成技术路线,生境科技基于公开资料绘制
Hillbot是另一具身合成数据企业,其技术路径包括通过 NVIDIA Cosmos 快速生成环境视频片段,利用 Sapien/ManiSkill 对视频进行3D场景解析和重建。此过程中,Hillbot通过标签化的三维模型库将物体(如冰箱、餐桌)替换为仿真中的对应对象,并赋予物理属性,从而实现机器人与虚拟环境的交互。
03 路线二:端到端的3D直接生成
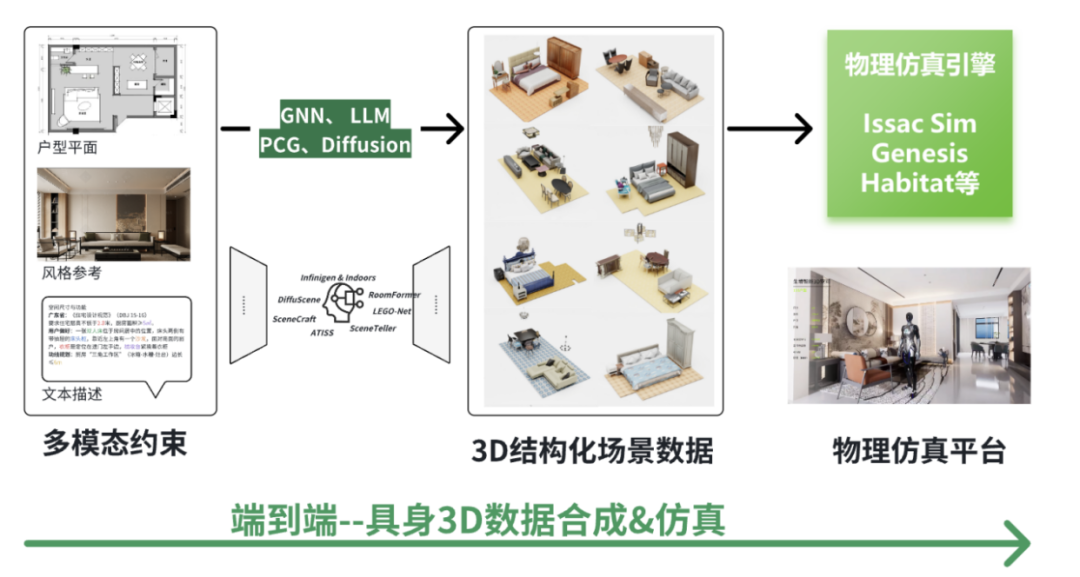
“端到端3D场景合成”技术路线,生境科技绘制

主要方法
图神经网络(GNNs)
图神经网络(GNNs)已成为3D室内场景生成的重要工具,能有效建模场景中物体及其空间关系。MIT团队2024年提出的超图模型通过图结构表征房间关系,提升空间利用效率。HAISOR(2024)结合图卷积网络和强化学习,优化家具布局。PlanIT(2019)通过符号关系图和自回归模型生成兼具逻辑性与功能性的布局。
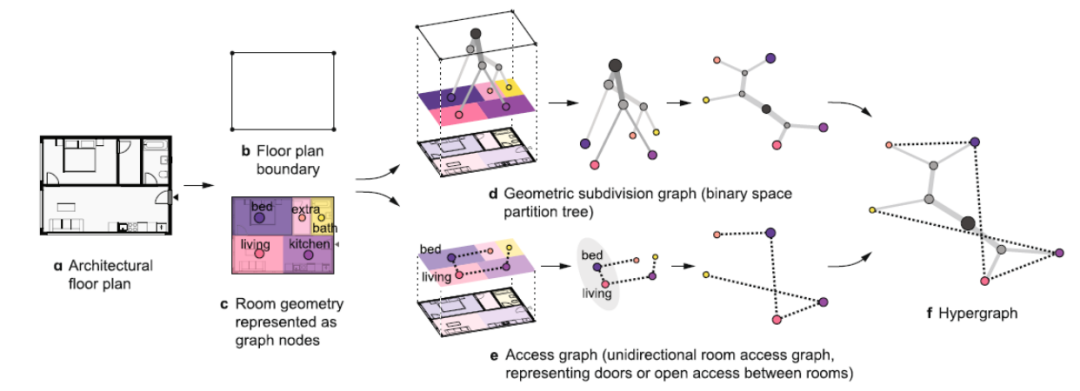
A hypergraph model shows the carbon reduction potential of effective space use in housing, MIT, 2024
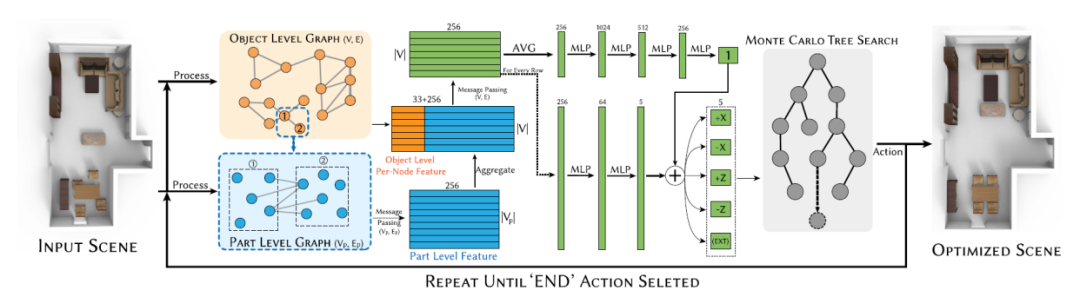
Haisor: Human-aware Indoor Scene Optimization via Deep Reinforcement Learning, 中科院 2024
自回归 Transformer
自回归 Transformer 模型在3D场景合成中表现出色,特别适用于处理物体集合的无序性和文本驱动生成任务。ATISS(2021)利用自回归模型预测每个物体的位置、类别和姿态,基于房间平面图生成多样且合理的布局。InstructScene(2024)结合语义图先验和图 Transformer,将语言指令转化为结构图,提升了文本驱动生成的可控性和准确性。

ATISS: Autoregressive Transformers for Indoor Scene Synthesis, NVIDIA Toronto AI Lab, 2021

https://research.nvidia.com/labs/toronto-ai/ATISS/
扩散模型 Diffusion
在3D场景合成中展现出强大潜力,通过去噪过程逐步优化布局。LEGO-NET(2023)通过迭代优化生成符合人类偏好的合理布局,而 DiffuScene(2023)利用去噪扩散模型生成物理合理且视觉真实的完整场景,支持文本或局部场景控制。
DiffuScene: Denoising Diffusion Models for Generative Indoor Scene Synthesis, 24 Mar 2023
程序化生成 (PCG)
程序化生成,则通过预定义规则合成3D场景,具备较高的可控性和可解释性。Infinigen Indoors(2024)和 ProcTHOR(2022)分别通过随机化生成室内环境和自动生成可交互住宅环境,突出了场景结构和风格的精确控制。
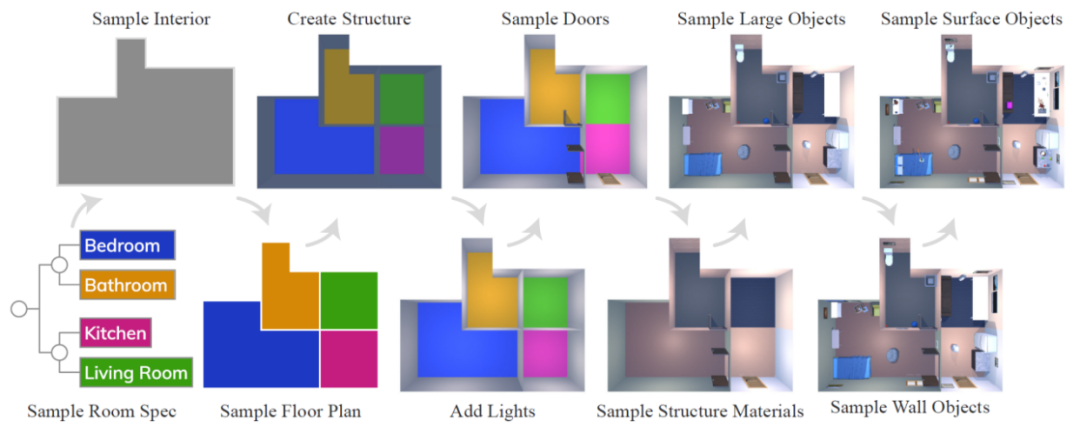
ProcTHOR: Large-Scale Embodied AI Using Procedural Generation, NeurIPS 2022
其他方法,如LLM
此外,大语言模型(LLM)也开始在此领域展现潜力。SceneCraft(2025)提出通过图像循环引导生成室内3D场景,而 FlairGPT(2025)设计了一个结构化的户型布局agent系统,分解设计任务进行推理。SceneTeller(2024)则直接通过文本描述生成3D物体位置,展示了强大的语言到空间映射能力。
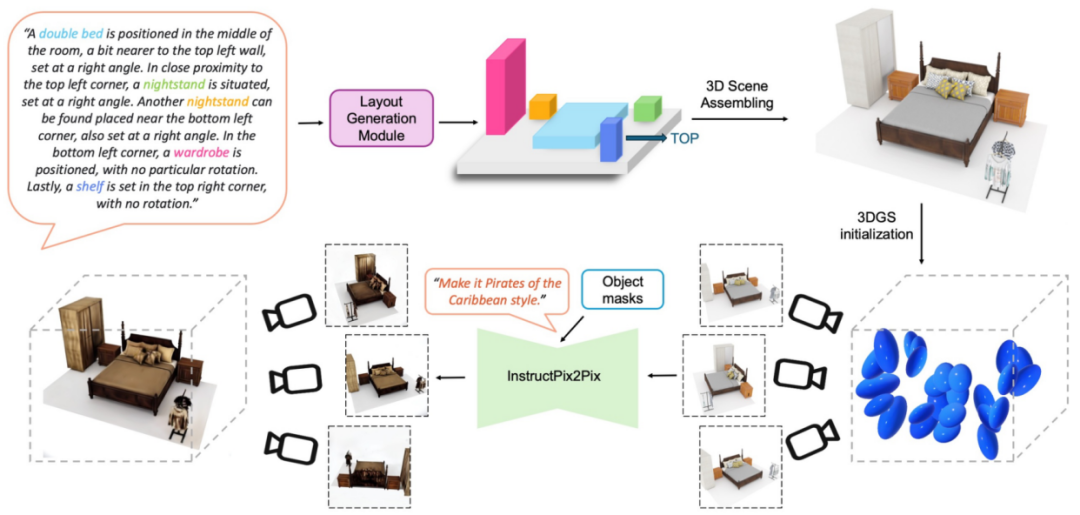
一句话“生成一个双人卧室”SceneTeller: Language-to-3D Scene Generation,30 Jul 2024
核心问题和挑战
尽管端到端方法在理论上具备效率与表达力的双重优势,但生成质量普遍较低,缺乏常识,甚至不及“视频合成”路线。 “视频合成+3D重建”路线依赖于真实或拟真视频,天然具备常识与空间逻辑。而端到端3D生成则从零开始,缺乏类似大模型中的“世界经验”,如果不引入专业知识作为前置输入,AI很难生成合理有效的空间结果。
AI合成空间常见问题有:
•现实合理性不足:易出现物体重叠、通道阻塞等逻辑错误;
•控制精度不足:难以对特定布局需求或使用偏好做出精准响应;

基于GNN,端到端合成3D数据的SOTA效果 Conditional room layout generation based on graph neural networks, SMI 2024
程序化生成的方式虽然通过设置大量显示规则的方式避免了逻辑硬伤,但是又会导致系统鲁棒性低,“缺乏设计弹性”,面对复杂户型适应性差,布局松散杂乱,难以还原真实空间的设计品质与实用性。

Infinigen程序化合成数据集质量,英伟达Isaac Sim官方文档
模态解决方案
端到端3D合成难以落地的根本原因在于:室内设计中蕴含大量隐性行业知识,尚未被系统化表达并embedding到AI的数学空间中进行隐式学习。 在高密度室内空间中,场景建模不仅要“生成出东西”,还要“生成得合理”,这对模型的结构认知能力提出了更高要求。
Sengine SimHub 是生境科技提出的一套室内空间生成引擎——通过“模态编码”将设计知识融入生成过程。目标是实现从户型图、功能需求,到最终三维场景数据的自动转译。与传统的图像合成方法不同,它更像是“把建筑师的经验装进了一个生成器”——在生成房间结构的同时,考虑到了空间功能、动线流畅性、家具摆放逻辑等实际设计因素。
这个系统的核心,是一种被称为“空间模态编码”的方法。简单来说,它把空间设计中的显性规则(比如“餐桌要靠近厨房”)转化为可以被模型学习的数学结构,再通过强化学习策略,让模型在面对不同户型或使用场景时,能够做出相对合理的结构判断。
系统还内嵌了一套训练流程,涵盖空间编码、物体搭配、数据优化等步骤,从而提升生成过程的稳定性与适应能力。这不仅有助于模拟训练中的精度控制,也使得生成数据更加贴近真实空间的逻辑与语义。
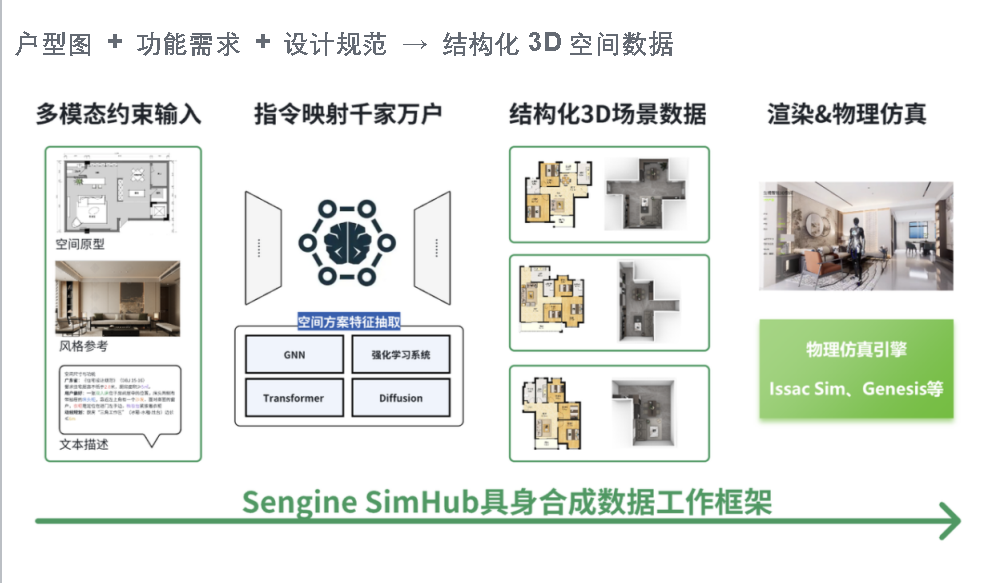
虽然这种模态化生成方式仍处于发展初期,但它提供了一种新的思路:不是单纯依赖图像或文本驱动的生成模型,而是尝试在设计逻辑与空间数据之间建立更紧密的联系。在未来具身智能场景中,类似的系统或许将成为机器人训练与空间认知建模的重要组成部分。

Sengine SimHub 家具排布自适应算法,2025
总结
相比自动驾驶领域成熟的数据闭环,具身智能依然面临严重的“数据荒”。为此,行业产生了两条技术路线之争:一是路径依赖但易损失信息的“视频合成+3D重建”;二是理论更高效但落地困难的端到端3D结构化生成。
回望这两条路径,我们看到的不只是技术分歧,更是一场关于“空间理解方式”的深层对话。是靠视觉还原现实,还是试图从设计逻辑出发重构空间?是先采集、再理解,还是边生成、边控制?
生境认为,要实现机器人对空间的真正理解,不能仅依赖数据堆积,而需构建可嵌入规则、吸纳偏好的空间数据生成体系。为此,我们提出基于模态编码和强化学习的新方法,将空间方案视作特有模态进行建模与优化。
具身智能的未来,也许就藏在我们如何定义空间、理解空间的方式之中。
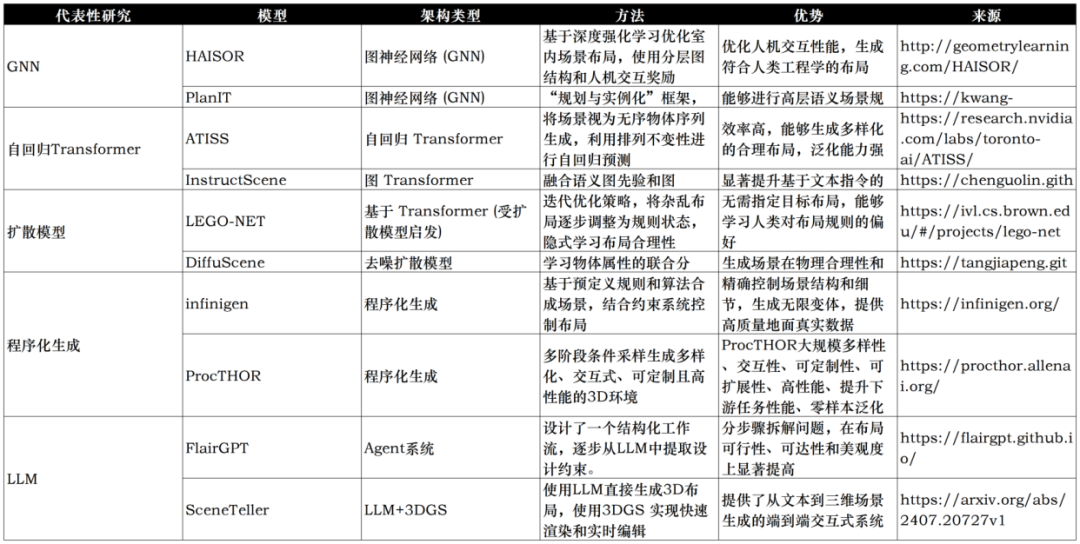
“端到端生成3D空间”代表性研究,生境科技整理
参考文献
•Synthetic Data Meets Architectural Typology: An Exploratory Computational Workflow with a Carbon Footprint Inference Case Study, 2024, ACSA 112 Annual Conference Paper Proceedings
•More than anything: Advocating for synthetic architectures within large-scale language-image models, International Journal of Architectural Computing, June 2023
•Building Synthetic Data Sets or How to Learn from Future Architectures? ACADIA2022
•One Minute Architecture 2021 https://lab-eds.org/One-Minute-Architecture
•Aligning Cyber Space with Physical World: A Comprehensive Survey on Embodied AI, 2024
•SurfelGAN: Synthesizing Realistic Sensor Data for Autonomous Driving CVPR 2020
•Aligning Cyber Space with Physical World: A Comprehensive Survey on Embodied AI,09 Jul 2024
•SpatialLM: Large Language Model for Spatial Understanding,群核科技,2025
•Kimera: from SLAM to Spatial Perception with 3D Dynamic Scene Graphs, MIT, 2021
•OpenRooms: An Open Frameworkfor Photorealistic Indoor Scene Datasets, CVPR 2021
•A hypergraph model shows the carbon reduction potential of effective space use in housing, MIT, 2024
•Haisor: Human-aware Indoor Scene Optimization via Deep Reinforcement Learning, 中科院 2024
•ATISS: Autoregressive Transformers for Indoor Scene Synthesis, NVIDIA Toronto AI Lab, 2021
•InstructScene: Instruction-Driven 3D Indoor Scene Synthesis with Semantic Graph Prior, 北京大学 2024
•LEGO-Net: Learning Regular Rearrangements of Objects in Rooms, Brown University& Stanford University 2023
•DiffuScene: Denoising Diffusion Models for Generative Indoor Scene Synthesis, 24 Mar 2023
•Infinigen Indoors: Photorealistic Indoor Scenes using Procedural Generation, Princeton University, 2024
•ProcTHOR: Large-Scale Embodied AI Using Procedural Generation, NeurIPS 2022
•SceneCraft: Layout-Guided 3D Scene Generation,17 Jan 2025
•SceneTeller: Language-to-3D Scene Generation,30 Jul 2024
•Conditional room layout generation based on graph neural networks, SMI 2024
•BEHAVIOR: Benchmark for Everyday Household Activities in Virtual, Interactive, and Ecological Environments, 2021
•3D Dynamic Scene Graphs: Actionable Spatial Perception with Places, Objects, and Humans, MIT 2020
•FlairGPT: Repurposing LLMs for Interior Designs
•https://www.nvidia.cn/use-cases/synthetic-data/
•https://www.spatial-verse.com/
•https://mp.weixin.qq.com/s/tWurf4cGDzs2mTN1V51DZw
•https://lsvp.com/stories/hello-world-models/
•https://www.hillbot.ai/blog/hillbot-nvidia-cosmos
•https://www.axavp.com/the-synthetic-data-revolution-how-does-it-fuel-ai/#:~:text=The%20Synthetic%20Data%20revolution%3A%20How,of%20their%20technology%20stack%3B
•https://pressroom.toyota.com/tri-teaching-robots-to-help-people-in-their-homes/
•https://manycore-research.github.io/SpatialLM/
•https://openaccess.thecvf.com/content/CVPR2024/papers/Raistrick_Infinigen_Indoors_Photorealistic_Indoor_Scenes_using_Procedural_Generation_CVPR_2024_paper.pdf#:~:text=However%2C%20the%20current%20Infinigen%20system,lead%20to%20better%20downstream%20performance
•https://openreview.net/pdf?id=4-bV1bi74M#:~:text=interactive%20large,objects
•https://openaccess.thecvf.com/content/CVPR2024/papers/Raistrick_Infinigen_Indoors_Photorealistic_Indoor_Scenes_using_Procedural_Generation_CVPR_2024_paper.pdf#:~:text=However%2C%20the%20current%20Infinigen%20system,lead%20to%20better%20downstream%20performance
•https://ai2thor.allenai.org/
•https://arxiv.org/html/2501.04648v1#:~:text=Interior%20designing%20is%20the%20art,their%20functionality%20and%20access%20space
•https://patentpc.com/blog/tesla-vs-waymo-vs-cruise-whos-leading-the-autonomous-vehicle-race-market-share-stats#:~:text=Waymo%E2%80%99s%20strategy%20relies%20on%20both,AI%20in%20complex%20traffic%20conditions
* 注:文章仅代表作者观点。文章经生境科技授权转载。
(文:Z Potentials)