



-
论文标题:DeepRetrieval: Hacking Real Search Engines and Retrievers with Large Language Models via Reinforcement Learning -
论文地址:https://arxiv.org/pdf/2503.00223 -
开源代码:https://github.com/pat-jj/DeepRetrieval -
开源模型:https://huggingface.co/DeepRetrieval
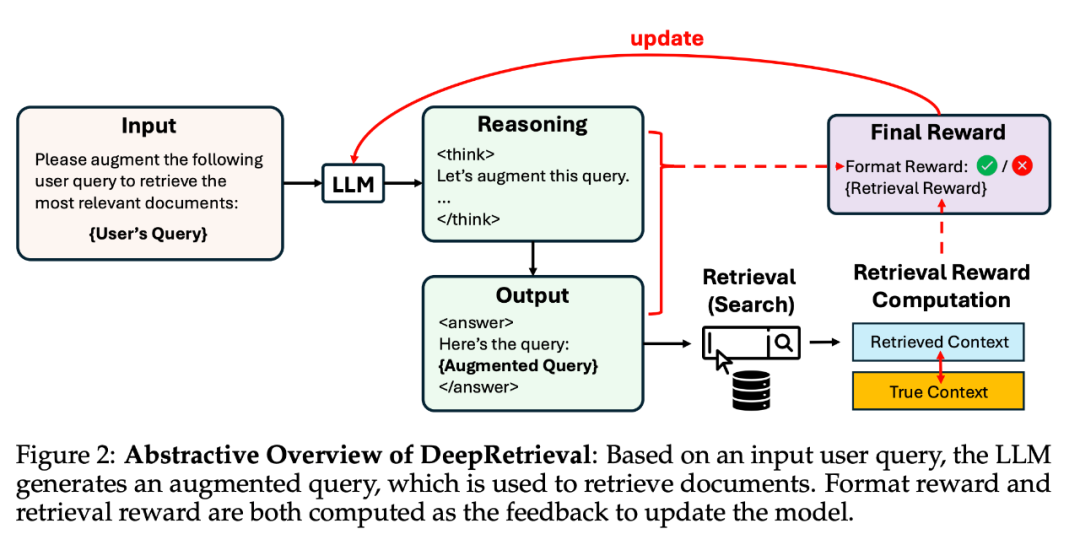
-
输入:原始查询 q -
输出:改写后的查询 q′(自然语言、布尔表达式或 SQL) -
环境反馈:使用 q′ 去检索系统中查询 → 返回结果 → 与 groundtruth 对比,计算 reward,reward 为 task-specific 检索表现(如 Recall@K、NDCG@K、SQL accuracy)使用 PPO 进行训练,并加入格式奖励(format correctness)与 KL-regularization 保证训练稳定,优化目标如下:
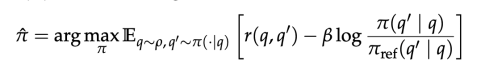
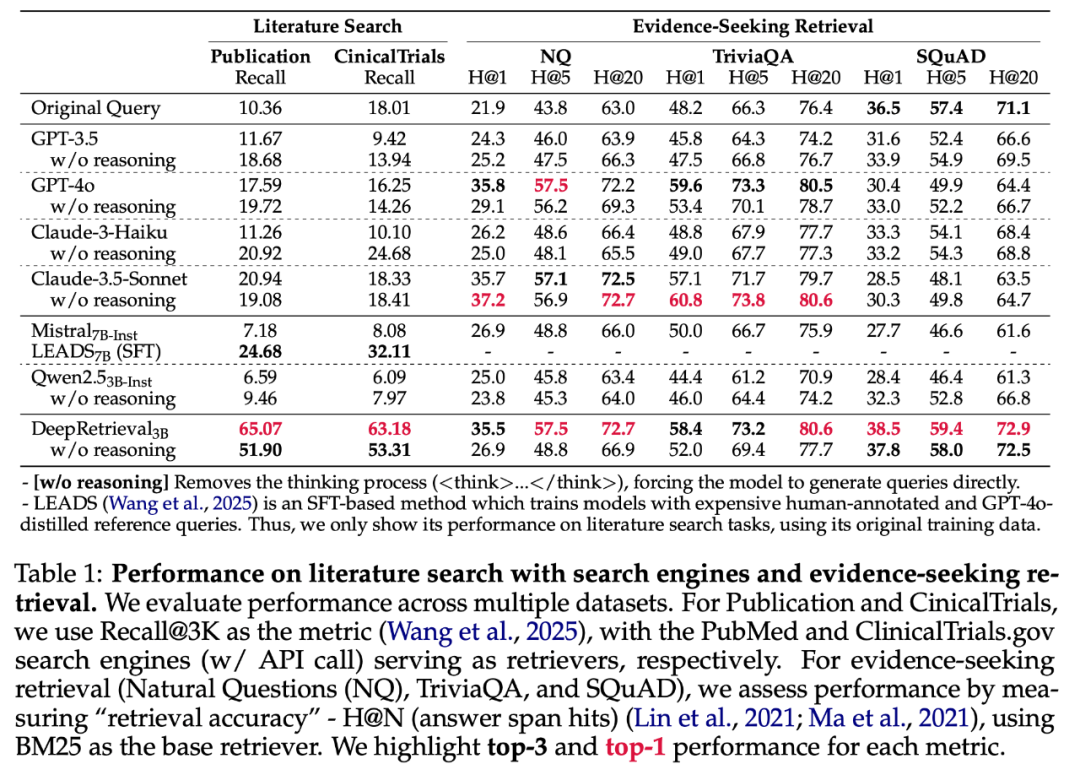
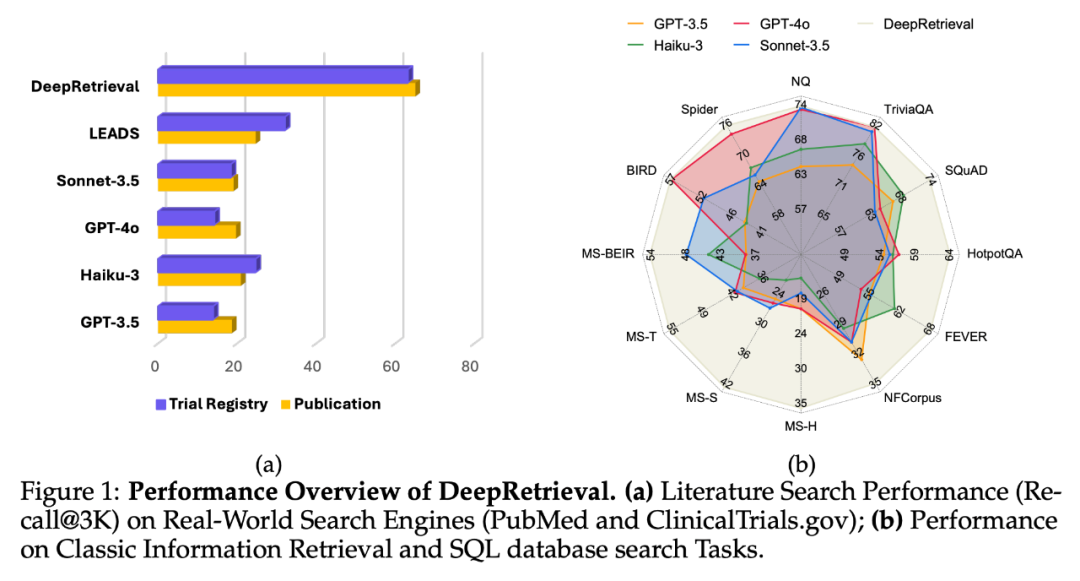
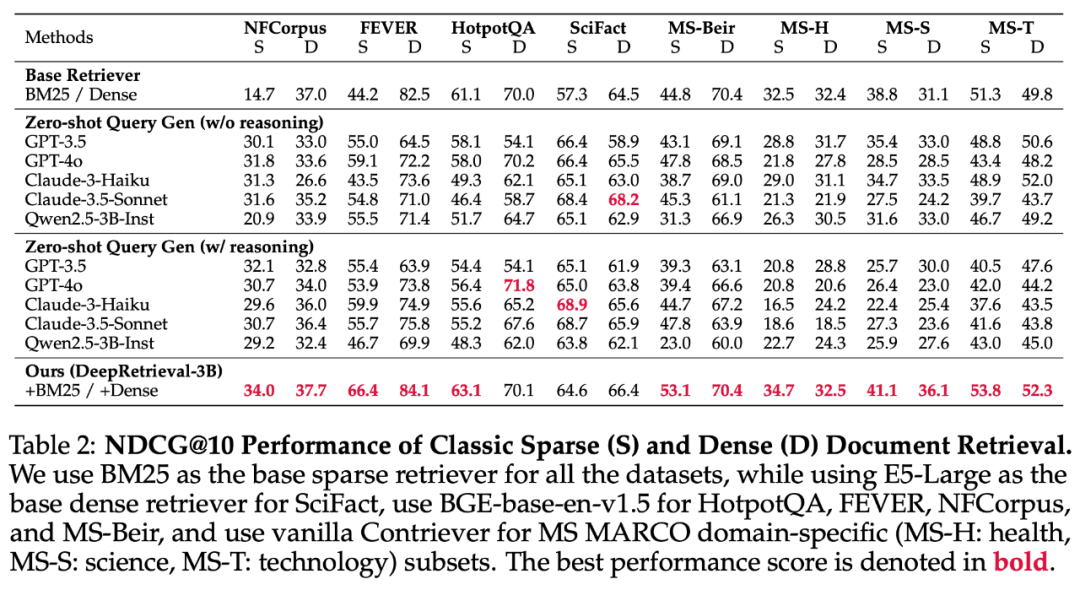
DeepRetrieval 在 Evidence-Seeking 检索任务上的优异表现令人瞩目。如表 1 所示,结合简单 BM25,这个仅有 3B 参数的模型在 SQuAD、TriviaQA 和 NQ 数据集上超越了 GPT-4o 和 Claude-3.5 等大型商业模型。
Evidence-Seeking 任务的核心是找到支持特定事实性问题答案的确切文档证据,在通用搜索引擎环境中,这一能力尤为关键。作者团队指出,将 DeepRetrieval 应用到 Google、Bing 等通用搜索引擎的 Evidence-Seeking 场景将带来显著优势:
-
精准定位事实文档:通用搜索引擎包含海量信息,用户难以构建能精确定位证据段落的查询。DeepRetrieval 可将简单问题转化为包含关键术语、同义词和限定符的复杂查询,显著提高找到权威证据的概率。
-
克服知识时效性限制:模型能够将「2024 年奥运会金牌榜前三名」等超出 LLM 知识截止日期的问题转化为精确搜索表达,使检索系统能够找到最新事实证据。
-
多源验证能力:通过优化查询帮助搜索引擎找到多个独立来源的事实证据,从而交叉验证信息准确性,这是纯 LLM 问答无法实现的关键优势。
作者团队表示会将这部分的延伸作为 DeepRetrieval 未来主要的探索方向之一。
探索胜于模仿:RL 为何超越 SFT
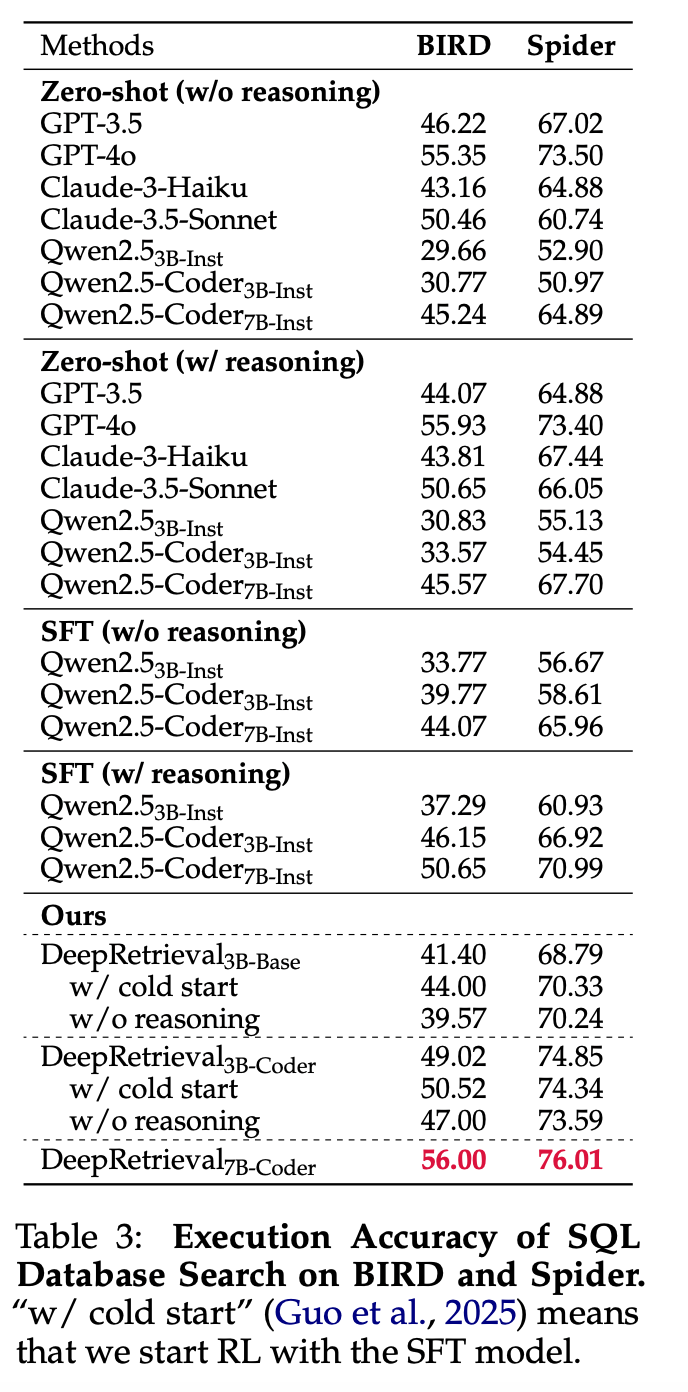
DeepRetrieval 的实验揭示了强化学习(RL)在搜索优化上相比监督微调(SFT)的独特优势。实验数据令人信服:在文献搜索上,RL 方法的 DeepRetrieval(65.07%)超过 SFT 方法 LEADS(24.68%)近三倍;在 SQL 任务上,从零开始的 RL 训练(无需任何 gold SQL 语句的监督)也优于使用 GPT-4o 蒸馏数据的 SFT 模型。
这种显著差异源于两种方法的本质区别:SFT 是「模仿学习」,试图复制参考查询,而 RL 是「直接优化」,通过环境反馈学习最优查询策略。SFT 方法的局限在于参考查询本身可能不是最优的,即使是人类专家或大模型也难以直观设计出最适合特定搜索引擎的查询表达。
论文中的案例分析进一步证实了这一点。例如,在 PubMed 搜索中,DeepRetrieval 生成的查询如「((DDAVP) AND (Perioperative Procedures OR Blood Transfusion OR Desmopressin OR Anticoagulant)) AND (Randomized Controlled Trial)」融合了医学领域的专业术语和 PubMed 搜索引擎偏好的布尔结构,这种组合很难通过简单模仿预定义的查询模板获得。
相反,RL 允许模型通过尝试与错误来探索查询空间,发现人类甚至未考虑的有效模式,并直接针对最终目标(如 Recall 或执行准确率)进行优化。这使 DeepRetrieval 能够生成高度适合特定搜索引擎特性的查询,适应不同检索环境的独特需求。
这一发现具有重要启示:在追求最佳检索性能时,让模型通过反馈学习如何与检索系统「对话」,比简单模仿既定模式更为有效,这也解释了为何参数量较小的 DeepRetrieval 能在多项任务上超越拥有更多参数的商业模型。
模型 Think&Query 长度分析
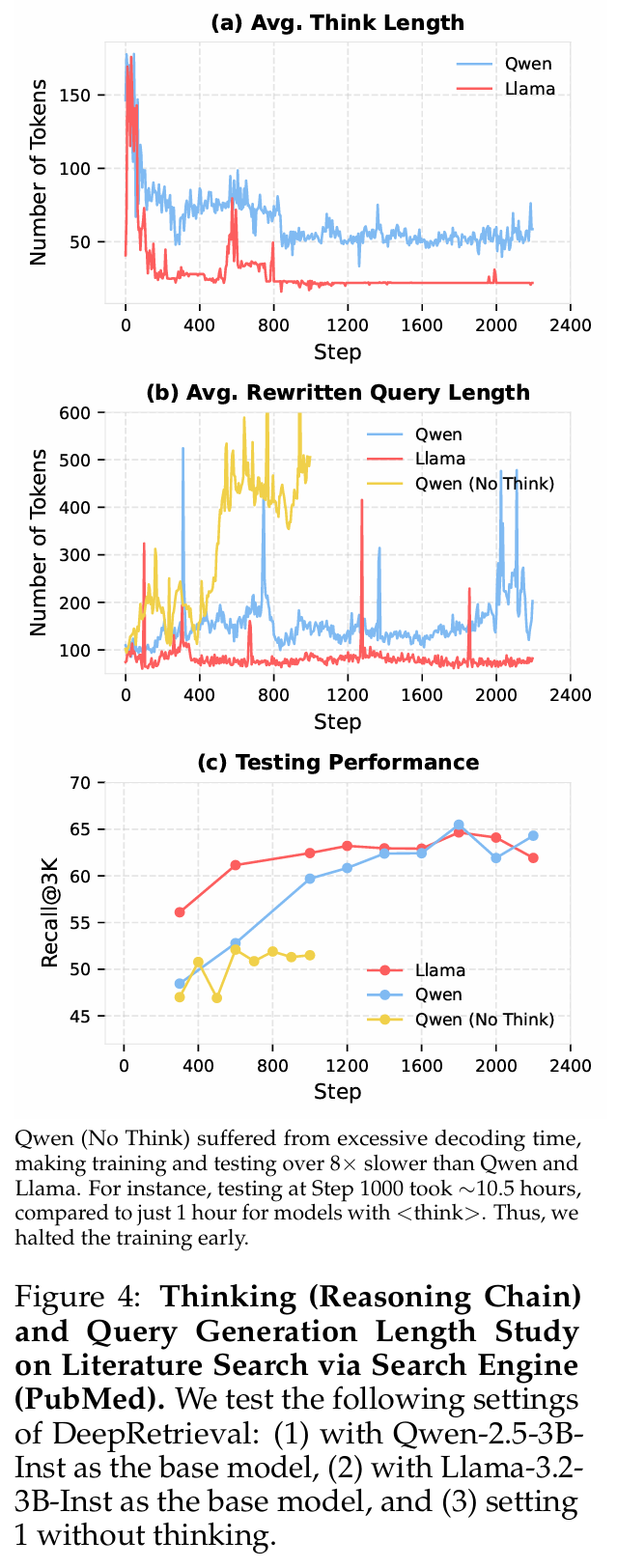
通过分析 DeepRetrieval 在训练过程中模型思考链和查询长度的变化,可以发现以下关键洞见:
思考链长度演变
与「aha moment」相反,DeepRetrieval 的思考链长度随训练呈下降趋势,而非增长。这与 DeepSeek-R1 报告的「aha moment」现象形成鲜明对比,后者的思考链会随训练进展变得更长。图 4(a) 清晰地展示了 Qwen 模型思考链从初始约 150 tokens 逐渐降至稳定的 50 tokens 左右,而 Llama 模型的思考链更短,甚至降至接近 25 tokens。
查询长度特征
实验揭示了思考过程对查询长度的显著影响。无思考过程的模型容易陷入次优解,如图 4(b) 所示,Qwen 无思考版本生成极长查询(500-600 tokens),表现出过度扩展的倾向。相比之下,有思考过程的模型保持更为适中的查询长度,Qwen 约 150 tokens,Llama 约 100 tokens。有趣的是,不同模型采用不同长度策略,但能达到相似性能,表明查询生成存在多样有效路径。
性能与思考过程关系
思考过程对检索性能有决定性影响。图 4(c) 表明,具备思考能力的模型性能显著提升,有思考的模型 Recall@3K 能达到 65%,而无思考模型仅 50% 左右。此外,训练效率也明显提高,有思考的模型更快达到高性能并保持稳定。论文附录 D.1 的分析表明,思考过程帮助模型避免简单地通过增加查询长度和重复术语来提升性能,而是引导模型学习更有效的语义组织策略。
关键结论
DeepRetrieval 展示了思考过程在信息检索中扮演「探索促进器」的关键角色。与数学或编程问题不同,检索任务不需要像「aha moment」那样的突然顿悟现象。相反,检索优化遵循「先详细思考,后逐渐精简」的模式,模型在内化有效策略后,不再需要冗长思考。这表明检索任务中思考链的主要功能是探索,一旦策略稳定便可简化。
这种分析表明,适当的思考过程设计对于构建高效的检索优化系统至关重要,能够在不增加模型参数的情况下显著提升性能,为未来的 LLM 应用于搜索任务提供了重要设计思路。
©
(文:机器之心)