
“ 随着大语言模型(LLM)的广泛应用,如何高效部署和推理模型成为开发者关注的核心问题。”
随着大模型的成本越来越低,以及企业生产中对大模型的定制化需求,越来越多的企业选择在本地部署大模型;这样既满足了数据安全性需求,同样也增加了企业定制化的选择。
但由于大模型是资源大户,再加上并发性需求,因此选择一个好的高性能的大模型部署框架是很多企业都要面临的主要问题。
所以,今天就来介绍几种部署大模型的方式和框架。
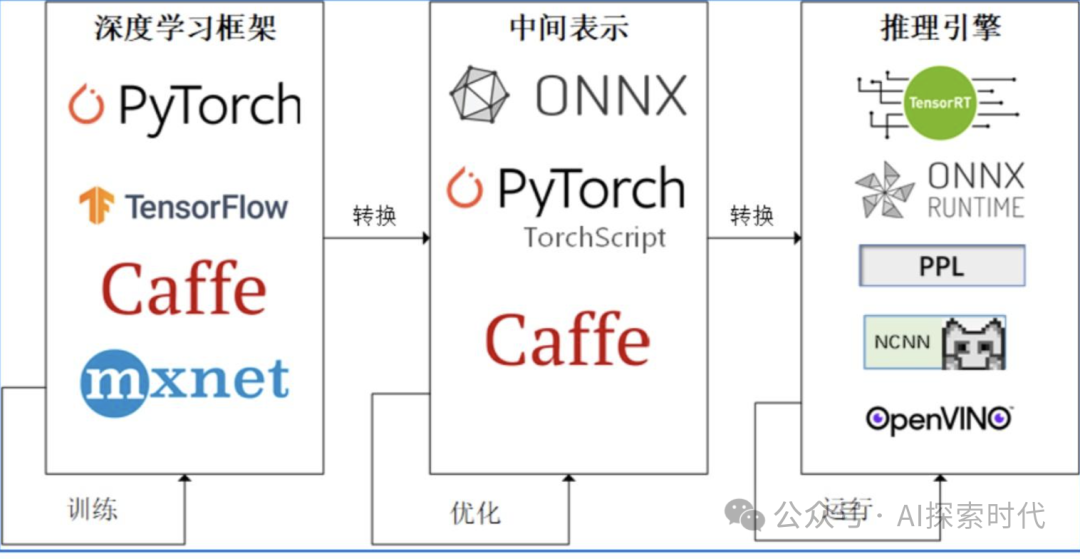
企业级大模型部署方案
很多人在学习大模型技术的过程中,可能都尝试过在本地下载和部署一些小模型;比如说使用ollama,gpt4all,LM Studio等。
但在企业级应用中和自己学习有着本质的差别,在企业场景中对大模型的性能,并发,容错,以及成本(包括技术成本和资金成本)都有着更高的要求;因此,本地部署大模型是一项专业的技术领域,而技术人员对不同平台和框架的选择,会直接影响到大模型的效果。
本文将对主流的大模型部署前端框架进行对比,包括Transformers、ModelScope、vLLM、LMDeploy、Ollama、SGLang和DeepSpeed
Transformers(Hugging Face)
技术架构:基于PyTorch/TensorFlow/JAX,提供统一的模型加载、微调和推理接口,支持动态批处理和量化。
优点:模型生态丰富,灵活性强。
缺点:原生推理效率低,多GPU支持复杂。
适用场景:快速原型验证、小规模推理任务。
ModelScope(阿里云)
官网:https://modelscope.cn
技术架构:集成模型开发全生命周期工具链,支持多模态模型。
优点:一站式服务,性能优化。
缺点:生态封闭,灵活性受限。
适用场景:企业级云原生部署、多模态应用。
vLLM
官网: https://vllm.readthedocs.io
技术架构:PagedAttention和Continuous Batching,显存利用率高,支持高并发请求。
优点:吞吐量极高,兼容性广。
缺点:依赖Linux/CUDA,模型转换成本高。
适用场景:高并发在线服务。
LMDeploy(零一万物)
官网: https://github.com/InternLM/lmdeploy
技术架构:Turbomind引擎和W4A16量化,优化短文本多并发。
优点:低延迟,轻量化部署。
缺点:社区生态较小,长上下文支持弱。
适用场景:实时对话系统、边缘计算。
Ollama
官网: https://ollama.ai
技术架构:基于llama.cpp的轻量级封装,支持CPU/GPU混合推理。
优点:极简部署,跨平台支持。
缺点:性能有限,功能单一。
适用场景:个人开发者测试、教育场景。
SGLang
官网: https://github.com/sgl-project/sglang
技术架构:RadixAttention和结构化输出优化,支持JSON/XML格式生成加速。
优点:企业级性能,多模态支持。
缺点:学习成本高,硬件要求高。
适用场景:企业级高并发服务、需结构化输出的应用。
DeepSpeed
官网:https://www.deepspeed.ai/inference
技术架构:ZeRO-Inference和Tensor Parallelism,支持超大规模模型推理。
优点:分布式优化,无缝衔接训练。
缺点:配置复杂,延迟较高。
适用场景:大规模分布式推理、与训练流程集成的场景。
总结与选型建议
-
个人开发者:优先使用Ollama(零配置)或Transformers(灵活)。
-
企业高并发场景:选择vLLM(吞吐量)或SGLang(结构化输出)。
-
边缘计算/实时交互:LMDeploy的低延迟特性最佳。
-
分布式需求:DeepSpeed和ModelScope支持多节点扩展。
通过合理选择框架,开发者可最大化发挥大模型的性能潜力。建议结合业务需求参考官方文档调整参数,并监控GPU显存与吞吐量指标。
(文:AI探索时代)