

今天是2025年4月10日,星期四,北京,天气晴。
我们先谈一个问题,关于开源框架的一个思考。不要过度依赖开源,开源大多数只能赶凑合,能快速上线,但是带来的风险是会黑盒化,不可控。我们如果要开发自己的东西,能定位问题,有能力的还要手搓,做到可控,可改,能定位。
第二个问题,我们来看看MOE多模态推理模型的有趣尝试,看起具体的实现方案,尤其是训练数据。
而说到多模态的数据,那么一定会说到图文对,那么图文对该怎么挖,尤其是针对不同类型的图片?尤其是在多模态RAG这个场景,这个很重要,可以用来做召回。对于大模型推理训练。比如R1用来做多模态推理,都是需要基于这个caption,所以来看一个OMNICAPTIONER-为不同视觉数据生成文本描述的方案。
抓住根本问题,做根因,专题化,体系化,会有更多深度思考。大家一起加油。
一、OMNICAPTIONER-为不同视觉数据生成文本描述的方案
目前多模态模型其实走的是缝合路线,而大模型理解图片等模态,其实大多都是走的caption的路线,caption起来了一个桥梁的作用,尤其是在多模态RAG场景中,怎么生成这个caption很重要,用来做图文召回。
那么就可以搞个框架,例如,最近的工作《OMNICAPTIONER: One Captioner to Rule Them All》(https://arxiv.org/pdf/2504.07089, https://alpha-innovator.github.io/OmniCaptioner-project-page,https://github.com/Alpha-Innovator/OmniCaptioner,https://huggingface.co/U4R/OmniCaptioner),这个工作也蛮有趣的,之前的现有的方法通常局限于特定类型的图像(如自然图像或几何图像),为了解决这个多样性的问题,为自然图像、视觉文本(如海报、UI、教科书)和结构化视觉(如文档、表格、图表)生成细粒度的文本描述。
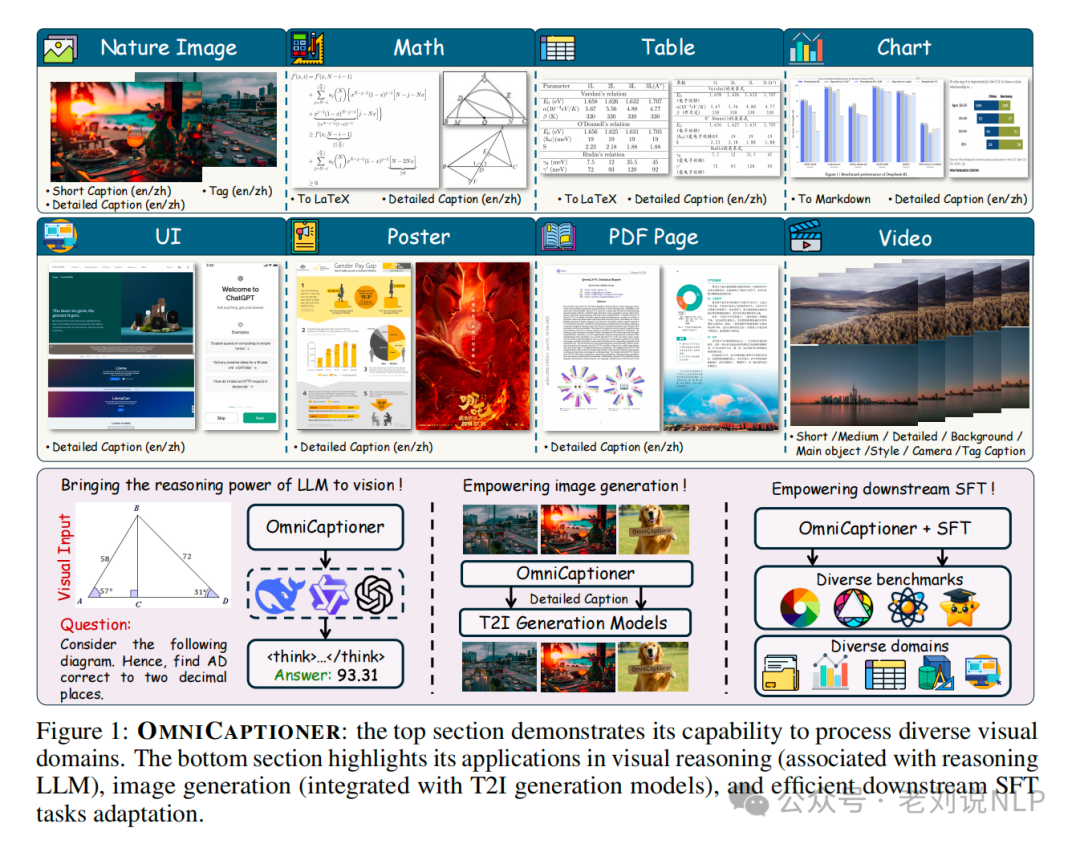
来看几个核心点:
1、数据怎么搞?
在数据上,这个很重要,怎么搞数据,通过两个主要措施来构建多样化的视觉caption数据集,领域多样性和caption公式多样性。
一个是领域多样性,数据集涵盖了自然图像、结构化图像、视觉文本图像和视频。具体来源包括内部收藏、BLIP3Kale、DenseFusion、arXiv网站、开源的MMTab数据集、TinyChart、MAVIS和AutoGeo等。
一个是caption 公式多样性,对于同一视觉输入,可能需要不同类型的caption。定义了多种caption格式,包括多语言(中文和英文)描述、不同粒度级别(从详细到简洁)和标签式caption。
那么,怎么做的这个caption生成,是有个流程。
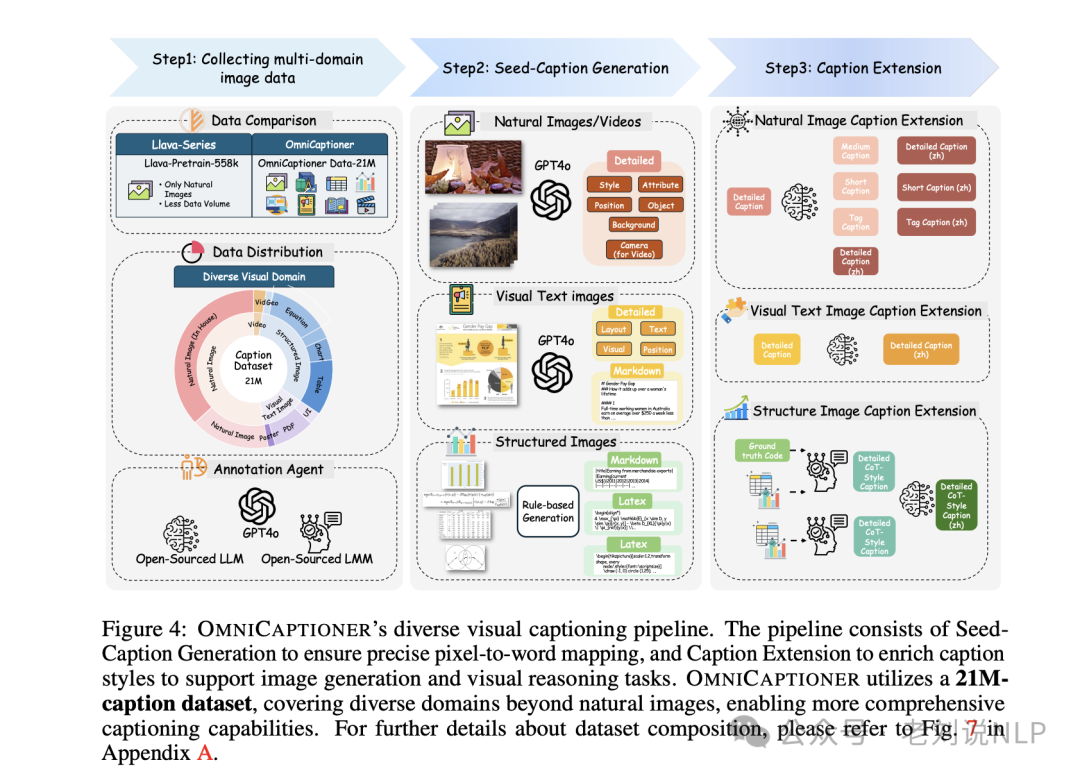
首先是种子caption生成,在这个阶段,目标是生成一个尽可能准确的初始caption,涵盖图像中所有相关的视觉元素。
该阶段利用强闭源多模态模型GPT-4o,通过精心设计的提示引导其描述自然图像和视觉文本图像中的所有可能视觉元素,确保准确的像素到词映射。对于通过代码生成的结构化图像,使用预定义的代码规则生成描述。生成的种子caption作为后续细化阶段的基础。
其次是caption扩展,在这个阶段,重点是增强和多样化生成的caption。
通过引入双语输出(中文和英文)、不同长度(从详细到简短和标签式)以及注入与特定领域相关的推理知识,丰富caption的语义深度。例如,对于自然图像,使用Qwen2.5-32B模型通过不同提示调整caption长度;对于视觉文本图像,使用Qwen2.5-32B模型将详细caption翻译成中文;对于结构化图像,优先保证种子caption的准确性,然后输入到Qwen2-VL-76B模型进行链式思维(CoT)风格的caption生成。
对应的prompt:

3、最终数据长啥样?
不同的数据有不同的caption格式,可以看下:
1)Math image captioning

2)Visual-Text image captioning

3) Table/Chart image captioning

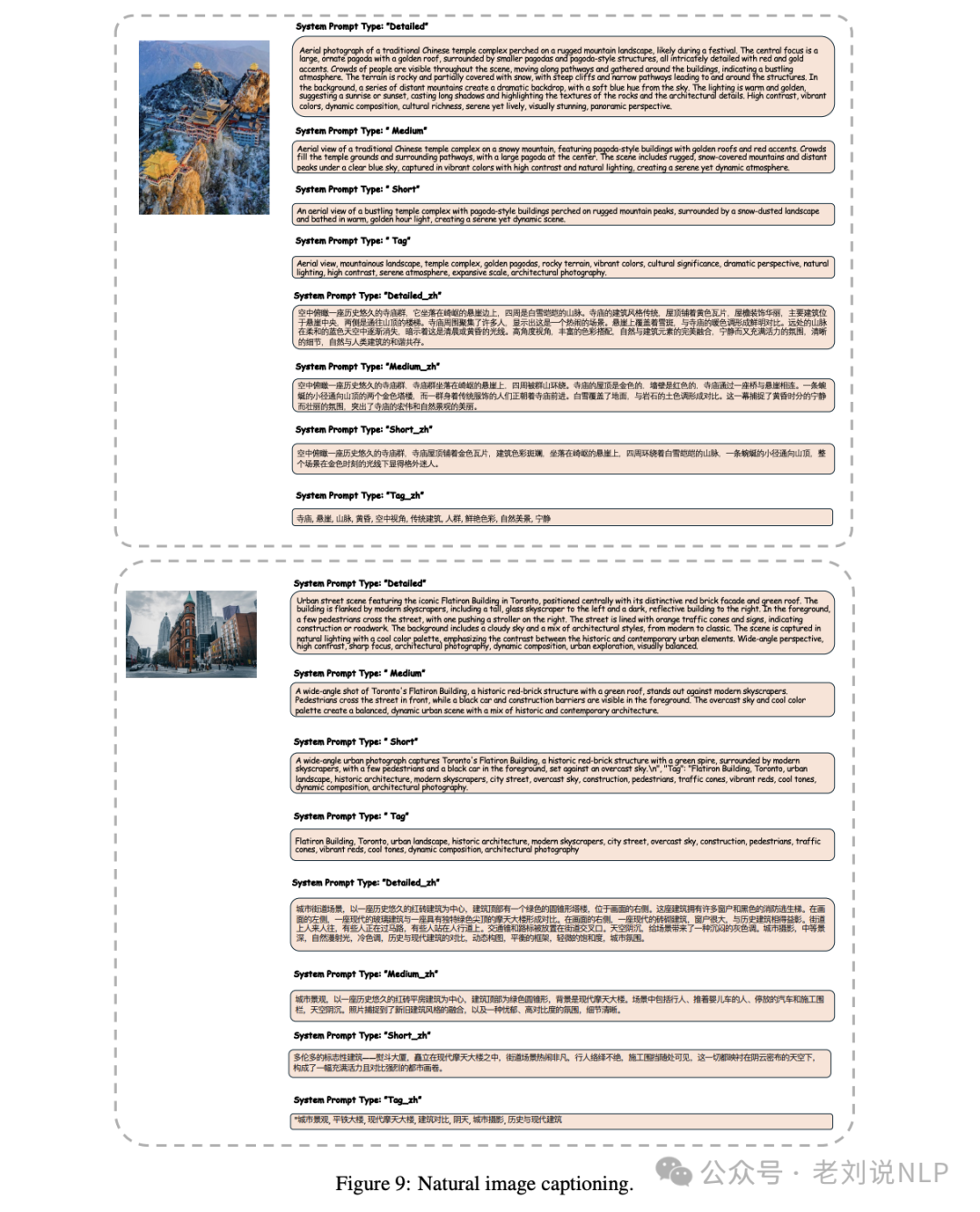
4)Natural image captioning
2、能用来干啥?
经过统一的预训练过程,OmniCaptioner可以有效地适应各种下游任务,包括使用LLM改进的视觉推理任务、(ii)增强的图像生成和转换,以及(iii)高效的SFT过程。

进一步的看,
将字幕集成到增强推理能力的LLMs(如DeepSeek-R1系列)中,无需额外的微调即可在多个推理基准(如MathVision、MathVerse、MMMU和Olympiad bench)上达到较好效果。
插入的LLMs在多个模型大小上显著优于现有模型,特别是在复杂的视觉和数学任务中。例如,在MathVision基准上,OMNICAPTIONER+DS-R1-Distill-Qwen-7B和OMNICAPTIONER+DS-Distill-Qwen-32B分别达到了36.2和40.5的准确率,显著高于其他模型;通过详细的字幕,OMNICAPTIONER框架使LLMs能够在文本空间中进行视觉推理,包括几何问题求解和空间分析,可以提高推理的准确性和有效性。
但是最根本的,可以用来做多模态RAG呀。
二、MOE多模态推理模型的有趣尝试Kimi-VL
多模态推理模型进展,现有的开源大型视觉语言模型在可扩展性、计算效率和高级推理能力方面显著落后于纯文本语言模型。此外,早期的基于MoE的视觉语言模型在架构和能力上存在局限,无法处理长上下文和高分辨率视觉输入。
OpenAI的GPT-4o和Google的Gemini等模型能够无缝感知和解释视觉输入,但不开源,DeepSeek-R1等模型虽然采用了MoE架构,但在长上下文推理和多模态任务上仍有不足。
所以,可以看最近的工作,基于MoE架构的高效多模态模型Kimi-VL,模型总参数为16B,推理时激活参数2.8B【这就很奇怪,16B,还做moe???】,地址在:https://github.com/MoonshotAI/Kimi-VL/blob/main/Kimi-VL.pdf,https://huggingface.co/collections/moonshotai/kimi-vl-a3b-67f67b6ac91d3b03d382dd85,一句话总结就是,预训练总共包括4个阶段,总4.4Ttokens:首先,独立进行ViT训练,以建立一个健壮的原生分辨率视觉编码器,随后是三个联合训练阶段(预训练、冷却和长上下文激活)。在Kimi-VL基础上,得到支持推理的多模态模型Kimi-VL-Thinking,两者后训练阶段包括在32K和128K上下文中进行的两个阶段的联合监督微调(SFT),以及进一步的长链推理(CoT)监督微调和强化学习(RL)阶段,以激活和增强思考能力。

依旧从技术角度上来看下训练架构,训练数据以及训练阶段。
1、训练架构
三个部分组成:原生分辨率视觉编码器(MoonViT)、MLP投影器和MoE语言模型。
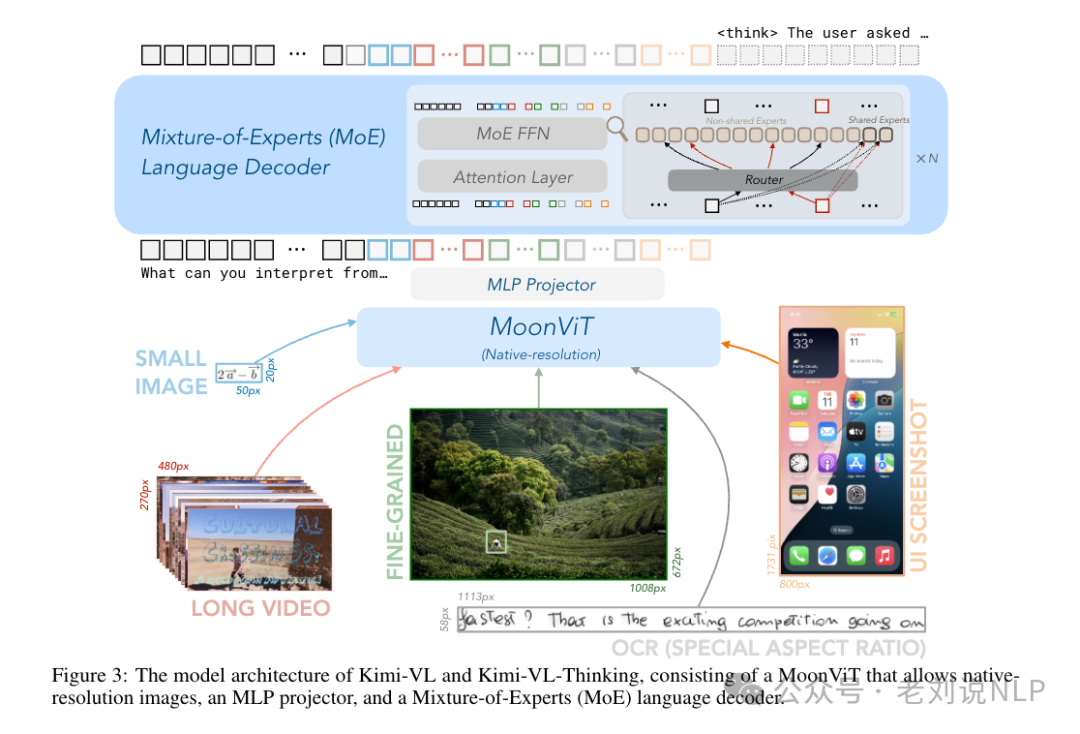
MoonViT上,设计用于原生处理不同分辨率的图像,采用NaViT的打包方法和2D旋转位置嵌入(RoPE)来提高高分辨率图像的处理能力。在不同分辨率下,不像LLaVA-OneVision进行复杂的子图像分割和拼接操作,采用NaViT中的打包方法,将图像划分为块,展平后依次连接成一维序列。具体在SigLIP-SO-400M上进行初始化并持续预训练,该模型最初采用可学习的固定大小绝对位置嵌入来编码空间信息MLP投影器上,使用两层MLP将MoonViT提取的图像特征投影到LLM嵌入维度。MoE语言模型上,基于Moonlight模型,采用MoE架构,激活参数为2.8B,总参数为16B。优化器上,使用增强的Muon优化器进行模型优化,增加了权重衰减和调整了每参数更新规模,并开发了分布式实现以优化内存效率和减少通信开销。
2、训练阶段及训练数据
预训练阶段包括四个阶段,总共消耗4.4Ttoken,这个数据集比较重要,看看具体适用的训练阶段。

具体的数据如下:
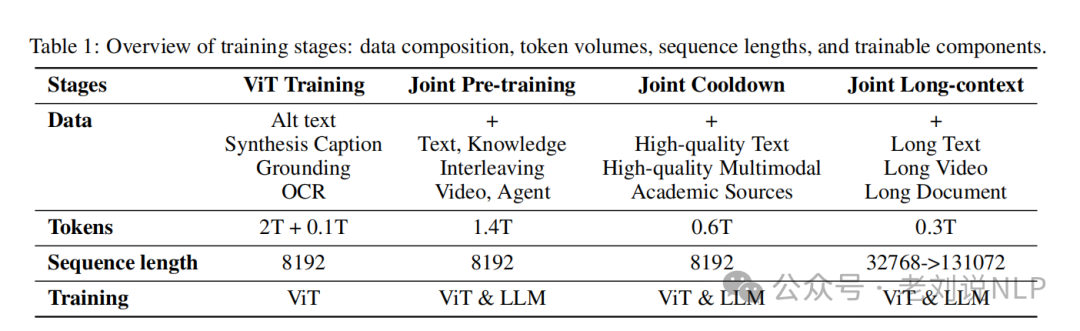
其中对于推理数据,首先收集一批带有真实答案注释的问答数据,这些数据需要进行多步推理,例如解决数学问题和特定领域的视觉问答。随后,通过利用一个强大的长上下文连贯性Transformer(CoT)模型,为每个问题抽取多个详细的推理轨迹。

在具体训练阶段,
ViT训练阶段训练MoonViT以建立稳健的原生分辨率视觉编码器;联合预训练阶段结合纯文本数据和多种模态数据进行训练;联合冷却阶段使用高质量的语言和多模态数据继续训练;联合长上下文激活阶段将模型的上下文长度从8192扩展到131072,使用长文本、长视频和长文档数据进行训练。

后训练阶段包括联合监督微调和长上下文激活的微调,使用ChatML格式进行指令优化,并通过强化学习进一步提高推理能力。
参考文献
1、https://github.com/MoonshotAI/Kimi-VL
2、https://arxiv.org/pdf/2504.07089
(文:老刘说NLP)