

编辑:Panda、+0
字节跳动豆包团队今天发布了自家新推理模型 Seed-Thinking-v1.5 的技术报告。从报告中可以看到,这是一个拥有 200B 总参数的 MoE 模型,每次工作时会激活其中 20B 参数。其表现非常惊艳,在各个领域的基准上都超过了拥有 671B 总参数的 DeepSeek-R1。有人猜测,这就是字节豆包目前正在使用的深度思考模型。
字节近期官宣的「2025 火山引擎 Force Link AI 创新巡展」活动推文中提到,4 月 17 日首发站杭州站时,豆包全新模型将重磅亮相,这会是 Seed-Thinking-v1.5 的正式发布吗?

-
报告标题:Seed-Thinking-v1.5: Advancing Superb Reasoning Models with Reinforcement Learning
-
项目地址:https://github.com/ByteDance-Seed/Seed-Thinking-v1.5
-
报告地址:https://github.com/ByteDance-Seed/Seed-Thinking-v1.5/blob/main/seed-thinking-v1.5.pdf
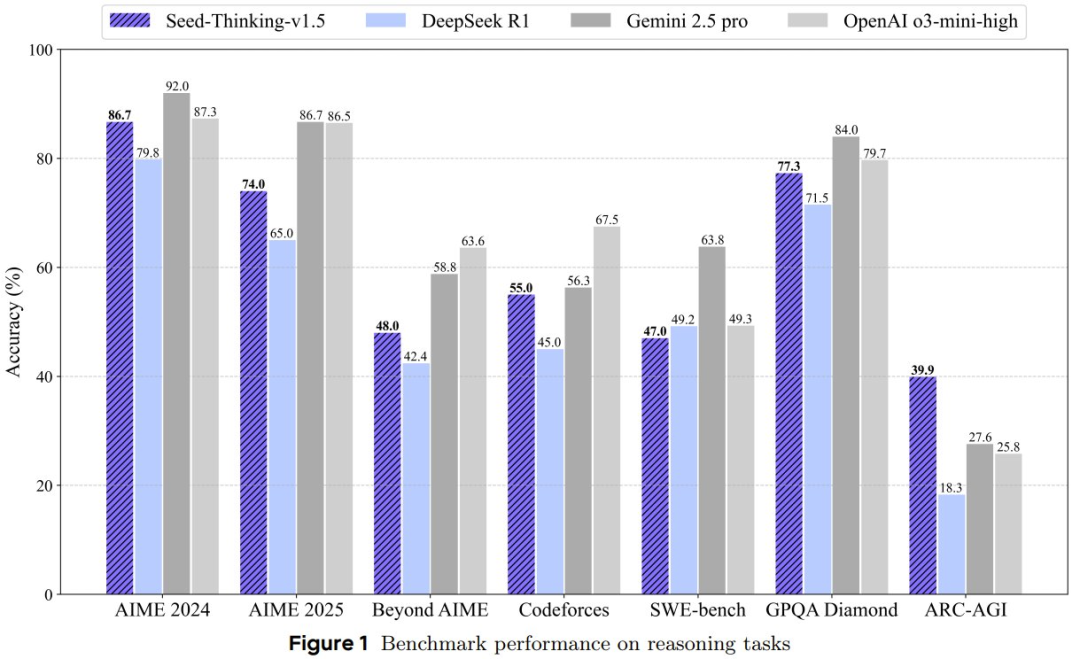
Seed-Thinking-v1.5 是一款通过深度思考提升推理能力的模型,在多个权威基准测试中展现出卓越性能。在具体评测中,该模型在 AIME 2024 测试中获得 86.7 分,Codeforces 评测达到 55.0 分,GPQA 测试达到 77.3 分,充分证明了其在 STEM(科学、技术、工程和数学)领域以及编程方面的出色推理能力。
除推理任务外,该方法在不同领域都表现出显著的泛化能力。例如,在非推理任务中,其胜率比 DeepSeek R1 高出 8%,这表明了其更广泛的应用潜力。
从技术架构看,Seed-Thinking-v1.5 采用了混合专家模型(Mixture-of-Experts,MoE)设计,总参数量为 200B,实际激活参数仅为 20B,相比同等性能的其他最先进推理模型,规模相对紧凑高效。
为全面评估模型的泛化推理能力,团队开发了 BeyondAIME 和 Codeforces 两个内部基准测试,这些测试工具将向公众开放,以促进相关领域的未来研究与发展。
先来看看其具体表现。
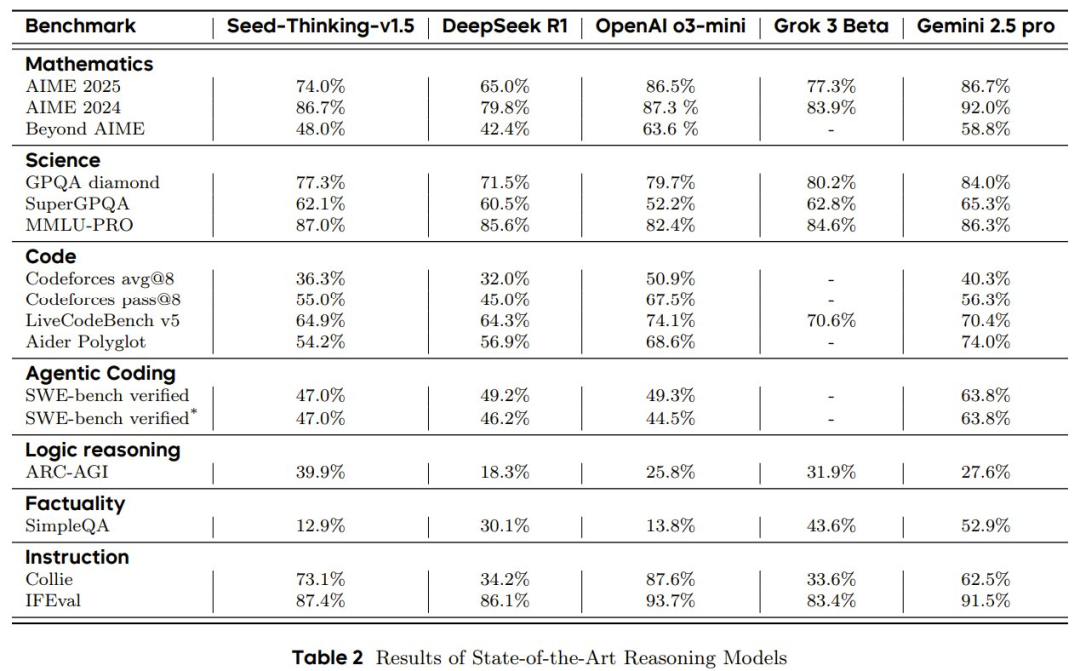
在数学推理方面,在 AIME 2024 基准上,Seed-Thinking-v1.5 取得了 86.7 的高分,与高计算量的 o3-mini-high 差不多。
由于 AIME 2024 已经不足以彰显前沿模型的差异,豆包团队还使用了另一个更具挑战性的评估基准 BeyondAIME,其中所有问题都是人类专家新整理编写的。结果可以看到,虽然 Seed-Thinking-v1.5 的成绩超过了 R1 和 o1,但相比于 o3 和 Gemini 2.5 pro 还有所差距。
在竞赛编程方面,在 Codeforces 基准上,该团队没有采用之前的依赖 Elo 分数的评估策略,而是采用了基于最新的 12 场 Codeforces 竞赛的具体评估方案。
具体来说,他们报告的是 pass@1 和 pass@8 指标,其中 pass@k 表示模型能否在 k 次尝试内解决问题,即从 k 次生成的提交中选择最佳结果。之所以选择报告 pass@8,是因为能提供更稳定的结果,并且更接近实际用户提交模式。
结果来看,Seed-Thinking-v1.5 在这两个指标上均超过 DeepSeek-R1,不过与 o3 的差距仍旧比较明显。该团队表示未来将公开发布这个评估集。
在科学问题上,Seed-Thinking-v1.5 在 GPQA 基准上得分为 77.3,接近 o3 的表现。该团队表示,这一提升主要归功于数学训练带来的泛化能力的提升,而非增加了特定领域的科学数据。
豆包也测试了 Seed-Thinking-v1.5 在非推理任务上的表现。这里他们使用的测试集尽力复现了真实的用户需求。通过人类对 Seed-Thinking-v1.5 与 DeepSeek-R1 输出结果的比较评估,结果发现,Seed-Thinking-v1.5 获得的用户积极反馈总体高出 8.0%,凸显了其在复杂用户场景处理能力方面的能力。
下面我们就来简单看看豆包是如何创造出 Seed-Thinking-v1.5 的。
开发高质量推理模型有三大关键:数据、强化学习算法和基础设施。为了打造出 Seed-Thinking-v1.5,该团队在这三个方面都进行了创新。
数据
推理模型主要依赖思维链(CoT)数据,这种数据展示逐步推理过程。该团队的初步研究表明,过多非思维链数据会削弱模型探索能力。
研究团队在强化学习训练中整合了 STEM 问题、代码任务、逻辑推理和非推理数据。其中逻辑推理数据提升了 ARC-AGI 测试表现。而数学数据则展现除了优秀的泛化能力。
另外,他们还构建了一个新的高级数学基准 BeyondAIME,其中包含 100 道题,每道题的难度等于或高于 AIME 中最难的题目。与 AIME 类似,所有答案都保证为整数(不受特定数值范围的限制),这能简化并稳定评估过程。
强化学习算法
推理模型的强化学习训练常出现不稳定性,尤其对未经监督微调的模型。为解决这一问题,研究团队提出了 VAPO 和 DAPO 框架,分别针对基于价值和无价值的强化学习范式。两种方法均能提供稳健的训练轨迹,有效优化推理模型。参阅机器之心报道《超越 DeepSeek GRPO 的关键 RL 算法,字节、清华 AIR 开源 DAPO》。
奖励建模
奖励建模是强化学习的关键,它确定了策略的目标。良好的奖励机制能在训练时提供准确的信号。团队针对可验证和不可验证的问题使用不同的奖励建模方法。
1、可验证问题
通过适当的原则和思维轨迹,团队利用 LLMs 来判断各种场景下的可验证问题。这种方法提供了超越基于规则的奖励系统局限性的更普遍解决方案。
团队设计了两个递进式的奖励建模方案:Seed-Verifier 和 Seed-Thinking-Verifier:
-
Seed-Verifier 基于一套由人类制定的原则,利用大语言模型的能力评估由问题、参考答案和模型生成答案组成的三元组。如果参考答案与模型生成的答案本质上等价,它返回「YES」;否则返回「NO」。这里的等价不要求逐字匹配,而是基于计算规则和数学原理进行深层评估,确保奖励信号准确反映模型回答的本质正确性。
-
Seed-Thinking-Verifier 的灵感来自人类的判断过程,通过细致思考和深入分析得出结论。为此,团队训练了一个能够提供详细推理路径的验证器,将其视为可验证任务,与其他数学推理任务一起优化。该验证器能够分析参考答案与模型生成答案之间的异同,提供精确的判断结果。
Seed-Thinking-Verifier 显著缓解了 Seed-Verifier 存在的三个主要问题:
-
奖励欺骗(Reward Hacking):非思考型模型可能利用漏洞获取奖励,而不真正理解问题。Seed-Thinking-Verifier 的详细推理过程使这种欺骗变得更加困难。
-
预测的不确定性:在参考答案与模型生成答案本质相同但格式不同的情况下,Seed-Verifier 可能有时返回「YES」,有时返回「NO」。Seed-Thinking-Verifier 通过深入分析答案背后的推理过程,提供一致的结果。
-
边界情况处理失败:Seed-Verifier 在处理某些边界情况时表现不佳。Seed-Thinking-Verifier 提供详细推理的能力使其能够更好地应对这些复杂场景。
表 1 展示了上述两种验证器的性能。结果表明,Seed-Verifier 在处理某些特殊情况时效果欠佳,而 Seed-Thinking-Verifier 展现出提供准确判断的卓越能力。尽管后者的思维过程消耗了大量 GPU 资源,但其产生的精确且稳健的奖励结果对于赋予策略强大的推理能力至关重要。

2、不可验证问题
研究团队为不可验证问题训练了一个强化学习奖励模型,使用与 Doubao 1.5 Pro 相同的人类偏好数据,主要覆盖创意写作和摘要生成。
团队采用了成对生成式奖励模型,通过直接比较两个回答的优劣并将「是 / 否」概率作为奖励分数。这种方法让模型专注于回答间的实质差异,避免关注无关细节。
实验表明,此方法提高了强化学习的稳定性,尤其在混合训练场景中减少了不同奖励模型间的冲突,主要是因为它能降低异常分数的生成,避免与验证器产生显著的分数分布差异。
基础设施
大语言模型强化学习系统需要强大基础设施支持。团队开发的流式推演架构通过优先级样本池异步处理轨迹生成,使迭代速度提升 3 倍。系统还支持自动故障恢复的混合精度训练,确保大规模强化学习运行的稳定性。
框架
Seed-Thinking-v1.5 采用的训练框架是基于 HybridFlow 编程抽象构建的。整个训练工作负载运行在 Ray 集群之上。数据加载器和强化学习算法在单进程 Ray Actor(单控制器)中实现。模型训练和响应生成(rollout)在 Ray Worker Group 中实现。
流式 Rollout 系统
其 SRS 架构引入了流式 Rollout,可将模型演化与运行时执行解耦,并通过参数 α 动态调整在策略和离策略的样本比例:
-
将完成率(α ∈ [0, 1])定义为使用最新模型版本以在策略方式生成的样本比例。
-
将剩余的未完成片段(1- α)分配给来自版本化模型快照的离策略 rollout,并通过在独立资源上异步延续部分生成来实现无缝集成。
此外,该团队还在环境交互阶段实现了动态精度调度,通过后训练量化和误差补偿范围缩放来部署 FP8 策略网络。
为了解决 MoE 系统中 token 不平衡的问题,他们实现了一个三层并行架构,结合了用于分层计算的 TP(张量并行化)、具有动态专家分配的 EP(专家并行)和用于上下文分块的 SP(序列并行)。这样一来,其 kernel auto-tuner 就能根据实时负载监控动态选择最佳 CUDA 核配置。
训练系统
为了高效地大规模训练 Seed-Thinking-v1.5 模型,该团队设计了一个混合分布式训练框架,该框架集成了先进的并行策略、动态工作负载平衡和内存优化。下面详细介绍一下其中的核心技术创新:
-
并行机制:该团队 TP(张量并行)/EP(专家并行)/CP(上下文并行)与完全分片数据并行(FSDP)相结合,用于训练 Seed-Thinking-v1.5。具体而言,他们将 TP/CP 应用于注意力层,将 EP 应用于 MoE 层。
-
序列长度平衡:有效序列长度可能在不同的 DP 等级上不平衡,从而导致计算负载不平衡和训练效率低下。为了应对这一挑战,他们利用 KARP 算法重新排列了一个 mini-batch 内的输入序列,使它们在 mini-batch 之间保持平衡。
-
内存优化:他们采用逐层重新计算、激活卸载和优化器卸载来支持更大 micro-batch 的训练,以覆盖 FSDP 造成的通信开销。
-
自动并行:为了实现最佳系统性能,他们开发了一个自动微调系统,称为 AutoTuner。具体来说,AutoTuner 可按照基于配置文件的解决方案对内存使用情况进行建模。然后,它会估算各种配置的性能和内存使用情况,以获得最佳配置。
-
检查点:为了以最小的开销从不同的分布式配置恢复检查点,该团队使用了 ByteCheckpoint。这能让用户弹性地训练任务以提高集群效率。

©
(文:机器之心)