
编辑:Panda
今天早些时候,著名研究者和技术作家 Sebastian Raschka 发布了一条推文,解读了一篇来自 Wand AI 的强化学习研究,其中分析了推理模型生成较长响应的原因。
他写到:「众所周知,推理模型通常会生成较长的响应,这会增加计算成本。现在,这篇新论文表明,这种行为源于强化学习的训练过程,而并非更高的准确度实际需要更长的答案。当模型获得负奖励时,强化学习损失函数就倾向于生成较长的响应,我认为这能解释纯强化学习训练为什么会导致出现顿悟时刻和更长思维链。」

也就是说,如果模型获得负奖励(即答案是错的),PPO 背后的数学原理会导致响应变长,这样平均每个 token 的损失就更小一些。因此,模型会间接地收到鼓励,从而使其响应更长。即使这些额外的 token 对解决问题没有实际帮助,也会出现这种情况。
响应长度与损失有什么关系呢?当使用负奖励时,更长的响应可以稀释每个 token 的惩罚,从而让损失值更低(即更好 —— 即使模型仍然会得出错误的答案。

因此,模型会「学习」到:即使较长的回答对正确性没有帮助,也能减少惩罚。
此外,研究人员还表明,第二轮强化学习(仅使用一些有时可解的问题)可以缩短回答时间,同时保持甚至提高准确度。这对部署效率具有重大意义。
以下是该论文得到的三大关键发现:
-
简洁性与准确度之间的相关性:该团队证明,在推理和非推理模型的推断(inference)过程中,简洁的推理往往与更高的准确度密切相关。
-
对 PPO 损失函数的动态分析:该团队通过数学分析,建立了响应正确性与 PPO 损失函数之间的联系。具体而言,研究表明,错误的答案往往会导致响应较长,而正确的答案则倾向于简洁。
-
有限的数据:该团队通过实验证明,即使在非常小的数据集上,强化学习的后训练阶段仍然有效,这一结果与文献中的当前趋势相悖,并且强化学习后训练在资源受限的场景下也是可行的。
有研究者认为这项研究揭示了强化学习存在的一个普遍问题:训练的目标只是为了获得奖励,而并非是解决问题。

下面我们就来具体看看这篇论文。

-
论文标题:Concise Reasoning via Reinforcement Learning
-
论文地址:https://arxiv.org/abs/2504.05185
响应更长≠性能更好
下表展示了使用不同模型在不同基准测试上,答案正确或错误时的平均响应长度。蓝色小字表示用于计算所得平均值的样本数。
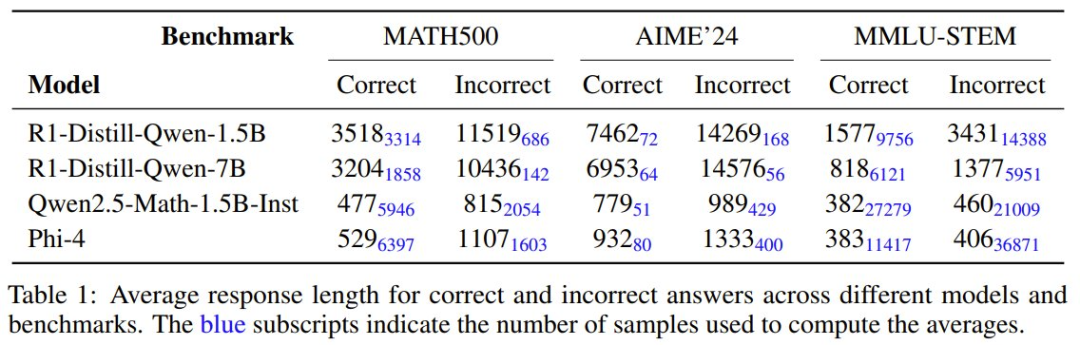
由此可知,更长响应不一定能带来更好的性能。
于是问题来了:使用 RL 训练的 LLM 倾向于在什么时候增加响应长度?原因又是为何?
每个推理问题都是一个 MDP
从根本上讲,每个推理问题(例如,数学问题)都构成了一个马尔可夫决策过程 (MDP),而不仅仅是一个静态样本。
MDP 由状态空间 S、动作空间 A、转换函数 T、奖励函数 R、初始状态分布 P_0 和折扣因子 γ 组成。
在语言建模中,每个 token 位置 k 处的状态由直到 k 为止并包括 k 的所有 token(或其嵌入)组成,另外还包括上下文信息(例如问题陈述)。动作空间对应于可能 token 的词汇表。转换函数可确定性地将新的 token 附加到序列中。除了最后一步之外,所有步骤的奖励函数都为零。在最后一步,正确性根据最终答案和格式进行评估。初始状态取决于提示词,其中可能包含问题陈述和指令(例如,「逐步求解并将最终答案放入方框中」)。强化学习的目标是最大化预期回报,预期回报定义为根据 γ 折扣后的未来奖励之和。在 LLM 的后训练中,通常将 γ 设置为 1。
为了在仅提供最终答案的情况下解决问题,需要一个能够偶尔得出正确答案的基础模型。在对多个问题进行训练时,整体 MDP 由多个初始状态和更新的奖励函数组成。添加更多问题会修改 P_0 和 R,但会保留基本的 MDP 结构。
这会引入两个重要的考虑因素:(1) 更大的问题集会增加 MDP 的复杂性,但这可能会使所学技术具有更高的泛化能力。(2) 原理上看,即使是单个问题(或一小组问题)也足以使强化学习训练生效,尽管这可能会引发过拟合的问题。
过拟合是监督学习中的一个问题,因为模型会记住具体的例子,而不是进行泛化。相比之下,在线强化学习则不会受到这个问题的影响。与依赖静态训练数据的监督学习不同,在线强化学习会持续生成新的响应轨迹,从而使模型能够动态地改进其推理能力。此外,在线强化学习不仅仅是模仿预先定义的解答;它还会主动探索各种推理策略,并强化那些能够得出正确答案的策略。
两种关键机制促成了这种稳健性:(1) 采样技术(例如非零温度)可确保生成的响应具有变化性;(2) 训练期间持续的模型更新会随着时间的推移引入新的响应分布,从而防止训练停滞和过拟合。
这能解释在小规模问题集上进行强化学习训练会保持有效性的原因。该团队表示,之前还没有人报告过将强化学习训练应用于极小数据集的研究,这也是本研究的贡献之一。
除了数据大小的考虑之外,需要强调的是,强化学习的唯一目标是最小化损失,这也就相当于最大化预期回报。从这个角度来看,强化学习训练过程中响应长度的任何显著变化都必然是由损失最小化驱动的,而非模型进行更广泛推理的固有倾向。
为了进一步研究这一点,该团队基于 DeepSeek-R1-Distill-Qwen-1.5B 基础模型,使用近端策略优化 (PPO) 算法进行了强化学习训练。训练数据是从 OlympiadBench 数据集中选择的四个问题。
之所以特意选择这些问题,是因为即使进行了广泛的采样,基础模型也始终无法解决这些问题,导致终端奖励恒定为 -0.5。其上下文大小限制为 20K token,该团队绘制了策略损失与响应长度的关系图(参见图 1)。
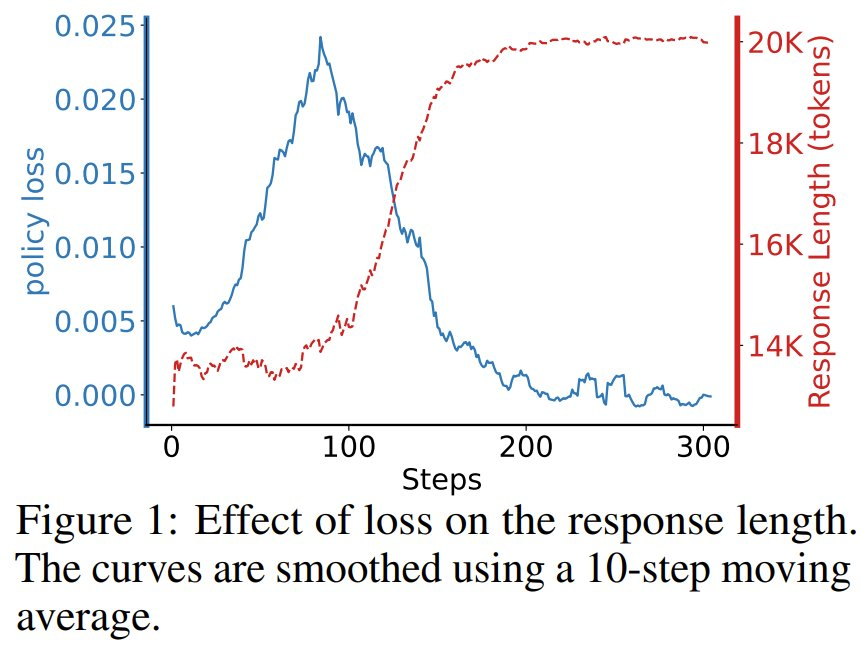
结果清楚地表明,响应长度和损失之间存在很强的相关性:随着响应长度的增加,损失持续下降。这直接证明:损失最小化(而非模型产生更长响应的内在趋势)才是驱动响应长度增长的主要动力。
对于 PPO 对响应长度的影响,该团队也从数学角度进行了解释。详见原论文。
一种两阶段强化学习策略
该团队的分析突出了几个要点。
-
当在极其困难的问题训练时,响应长度往往会增加,因为较长的响应更有可能受到 PPO 的青睐,因为模型难以获得正回报。
-
当在偶尔可解的问题上训练时,响应长度预计会缩短。
-
在大规模训练场景中,响应长度的动态会变得非常复杂,并会受到底层问题难度的巨大影响。
该团队认为,由于大多数问题至少偶尔可解,因此平均响应长度最终会减少。值得注意的是,该团队目前的分析不适用于 GRPO,对此类方法的精确分析还留待未来研究。尽管如此,由于简洁性与更高准确度之间的相关性,该团队推测:如果训练持续足够长的时间,这种增长最终可能会停止并开始逆转。
如果数据集包含过多无法解决的问题,那么从「鼓励响应更长」到「鼓励简洁性」的转变可能会大幅延迟且成本高昂。
为了解决这个问题,该团队提出了一种新方法:通过一个后续强化学习训练阶段来强制实现简洁性,该阶段使用了偶尔可解问题的数据集。于是,就能得到一种两阶段的强化学习训练方法:
在第一阶段,用高难度问题训练模型。此阶段的目标是增强模型解决问题的能力,由于 PPO 主要会遇到负奖励,从而促使模型产生更长的响应,因此响应长度预计会增加。值得注意的是,第一阶段也可被视为现有推理模型的强化学习训练。
在第二阶段,使用非零 p_a(偶尔可解)的问题继续训练。此阶段能在保持甚至提高准确度的同时提升简洁性。值得注意的是,正如后面将看到的,它还能显著提高模型对降低温度值的稳健性 —— 即使在有限的采样量下也能确保卓越的性能。
从 MDP 的角度,该团队得到了一个关键洞察:即使问题集很小,也可以实现有效的强化学习训练,尽管这可能会降低泛化能力。尤其要指出,在训练的第二阶段 —— 此时模型已经具备泛化能力,即使仅有只包含少量问题的极小数据集也可使用 PPO。
实验结果
该团队也通过实验检验了新提出的两阶段强化学习训练方法。
问题难度如何影响准确度-响应长度的相关性
图 2 给出了准确度和响应长度随训练步数的变化。
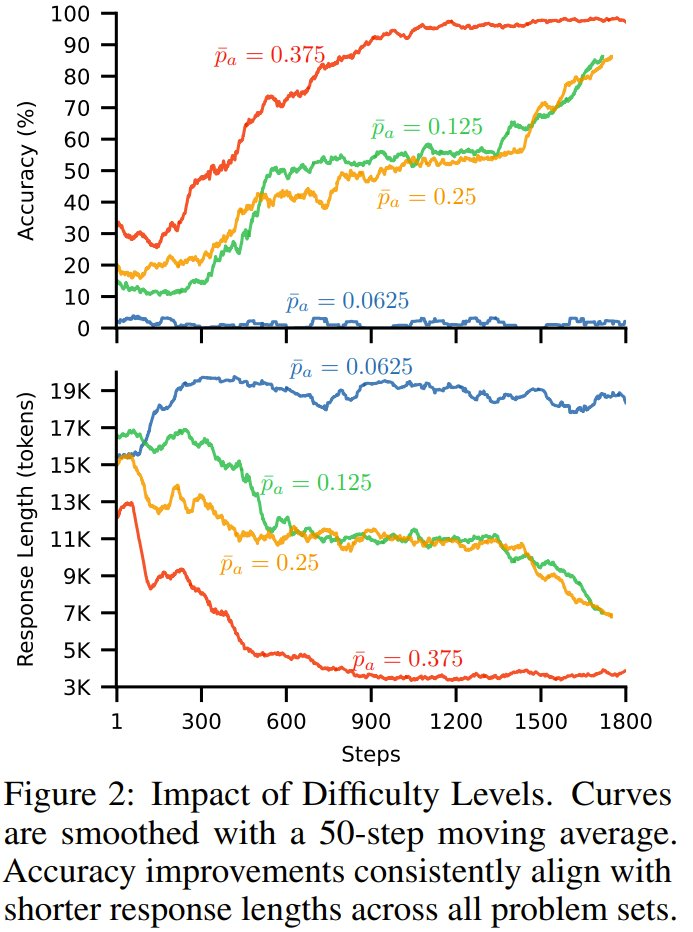
可以看到,在所有问题集中,准确度的提高与响应长度的缩短相一致 —— 这表明随着模型准确度的提高,其响应长度也随之缩短。此外,对于更简单的问题集,响应长度缩短得更快。最后,对于最难的数据集,由于问题很少能够解决,因此响应长度有所增加。
响应长度减少
图 3 展示了在不同的测试数据集(AIME 2024、AMC 2023 和 MATH-500)上,经过后训练的 1.5B 和 7B 模型的准确度和响应长度随训练步数的变化情况。
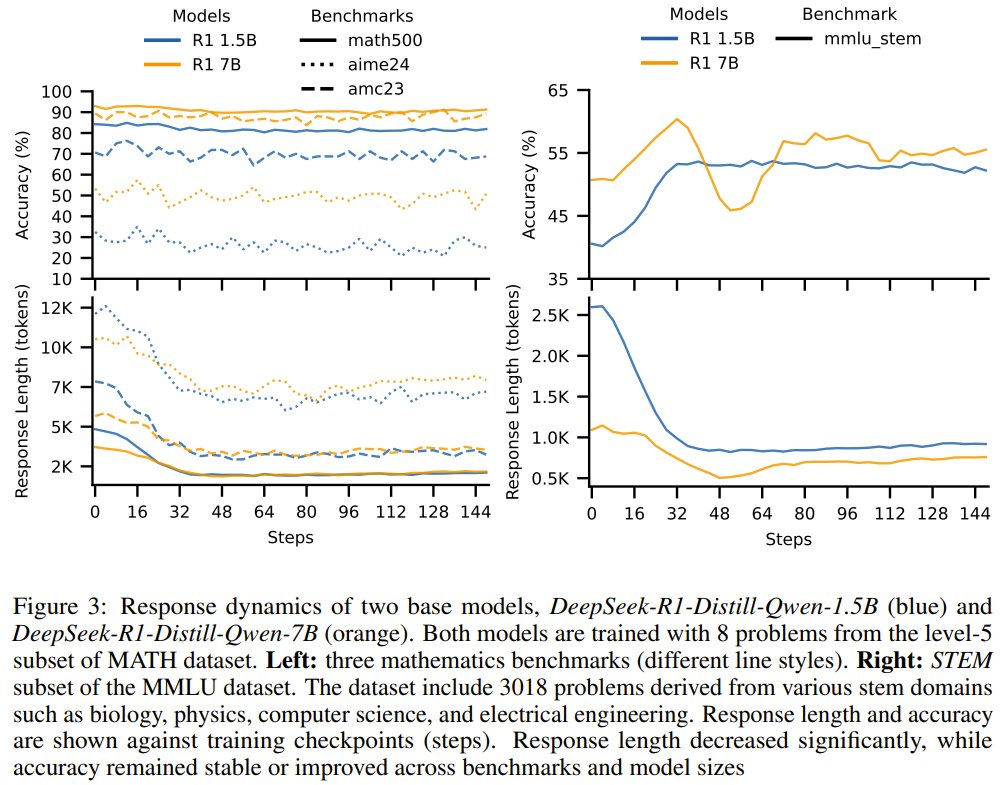
可以看到,新提出的两阶段强化学习训练方法会让响应长度显著下降,同时准确度会保持稳定。而右图在 MMLU_STEM 上的结果更是表明:仅使用 8 个样本,强化学习后训练也能带来准确度提升。
性能和稳健性的提升
前面的实验结果已经证明:进一步的强化学习后训练可以在保持准确度的同时缩短响应长度。该团队进一步研究发现:进一步的强化学习后训练也能提升模型的稳健性和性能。
为了评估模型的稳健性,该团队检查了它们对温度设置的敏感性。将温度设置为零会大幅降低 R1 等推理模型的准确度。然而,诸如 pass@1 之类的标准指标依赖于非零温度下的多个样本,这通常会掩盖在小型数据集上进行二次强化学习后训练的优势。
该团队使用 0 和 0.6 的温度值进行了实验,结果见表 3。
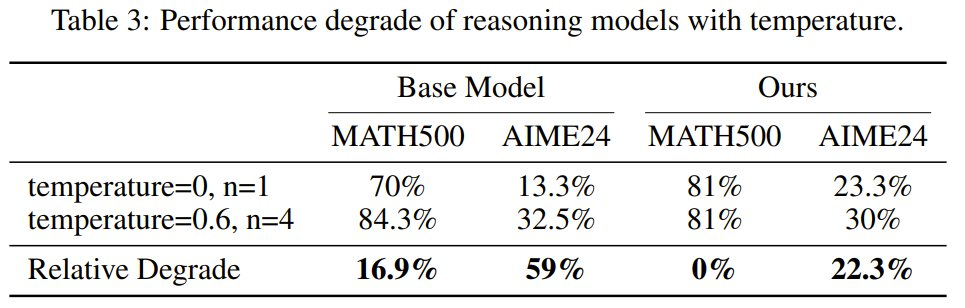
可以看到,当温度设置为 0 时,经过后训练的模型的表现显著优于基线模型,这表明经过后训练的模型与基线模型相比更加稳健。
该团队还表明,在有限数量的样本上进行进一步的强化学习训练可以显著提升准确度。这种效果取决于先前在类似(甚至相同)问题上进行过的强化学习训练程度。如果模型已经进行过大量强化学习训练,可能就更难以进一步提升准确度。
为了探究这一点,该团队基于 Qwen-Math-v2.5 使用了在线强化学习进行实验,训练样本是来自 MATH 数据集的 4 个样本。不同于 R1,该模型之前并没有经过强化学习训练,而是仅在大量数学数据上进行了 token completion 训练。结果见表 4。
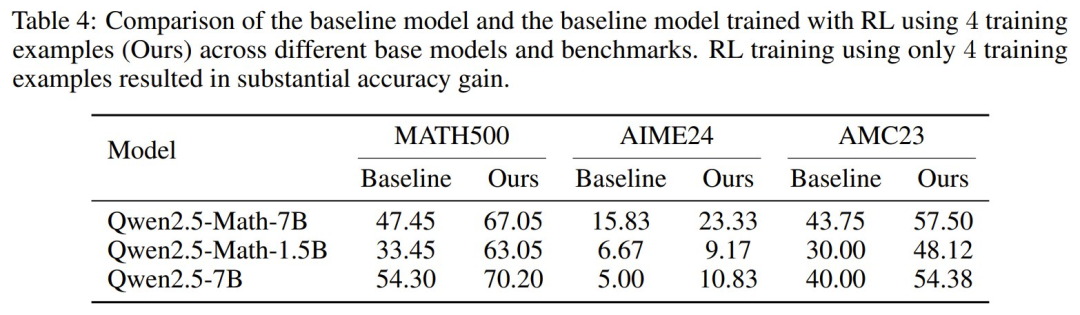
可以看到,提升很惊人!在 1.5B 模型上,提升高达 30%。这表明,就算仅使用 4 个问题进行强化学习后训练,也能得到显著的准确度提升,尤其是当模型之前未进行过强化学习推理优化训练时。
(文:机器之心)