

每次有人问我,现在最好用的AI视频生成模型是什么?
我基本都会回答,可灵1.6。
动作幅度大、画质好,够稳定,真的没啥不用它理由。
本来我这几天还在美滋滋的用可灵1.6跑视频,
然后就得知了一个重磅消息:可灵2.0发布!
今天,我就在发布会现场,亲眼见证了这个国产最强视频模型又一次如何顶破自己的天花板,把最强变为更强的。

简单总结一下,这次发布都带来了哪些升级:
-
可灵2.0视频模型:语义理解、大幅度动作、画面美感均有大幅提升。
-
视频多模态编辑功能:可灵逆天的增加了可以直接替换、增加、删减视频中的元素的新功能。
-
可图2.0图像模型:语义理解、画面质感、风格化全面升级。
只是文字来说,可能感受不明显,先放一个他们官方宣传片,感受一下这个动态幅度之大和动作的合理性:
这效果更牛了!这更新太干了!下面我们再分别给大家看看具体每部分的升级!一大波效果来袭!
可灵2.0 大师版
可灵2.0版本这次加了一个大师版的title,“大师”这两个字足以可见这个版本的能力之强。
这次更新,可灵2.0同样是带来了文生视频和图生视频的各方面能力的全面升级。
首先是语义理解能力的显著提升,看下面这个文生视频的提示语:
男人先是开心的笑着,突然变得愤怒,手锤桌子起身

再来一个分镜动作描述更复杂的提示语:
镜头1:手持镜头特写男子在直升机舱内强风吹拂面部扭曲,自然光下背景广阔天空,表情坚定
镜头2:男子纵身跃出机舱急速下坠,高空云层翻滚,镜头跟随展现自由落体动态
镜头3:降落伞在空中猛然展开,镜头拉远呈现全景,阳光穿透云层照亮伞面,紧张氛围瞬间缓解

两组画面比对提示语,2.0版本明显对于提示语的指令遵循的更精准,动作也更加合理,戏剧张力更强!
还记得之前我们测可灵1.6的时候,已经感叹过它的动作幅度之大,当时我还说,可灵1.6的动作好到是可以做女团舞的程度:
100镜实测可灵1.6新版本,超大幅度女团群舞都能做了!
而更新后的可灵2.0,不仅是人物动作幅度变大,而且整个画面的运动变得更加合理,人物动作真实性更强,更符合物理规律。
先看一组图生视频的画面对比:
恐龙朝着镜头冲过来,运动模糊,镜头抖动

再来一个从前对于模型来说一直是灾难的滑板动作:
滑板运动,围绕滑板少年不断运动

这两组画面对比中,恐龙的速度感更强,视觉张力更强,滑板动作可以说是几乎完美的完成,腿部和滑板之间力的感觉,而且之前很难做出的腿部动作,现在也完美没有崩坏。
除此之外,可灵2.0在画面审美能力上也有提高,同时风格化保持也做的更好,来看一组文生视频对比:
镜头跟随蜜蜂快速的在花丛中穿行,最后聚焦在一棵沾满露珠的鲜花上

再看一组油画风格的图生视频对比:
油画,孩子们在海边奔跑,海浪拍打着海岸
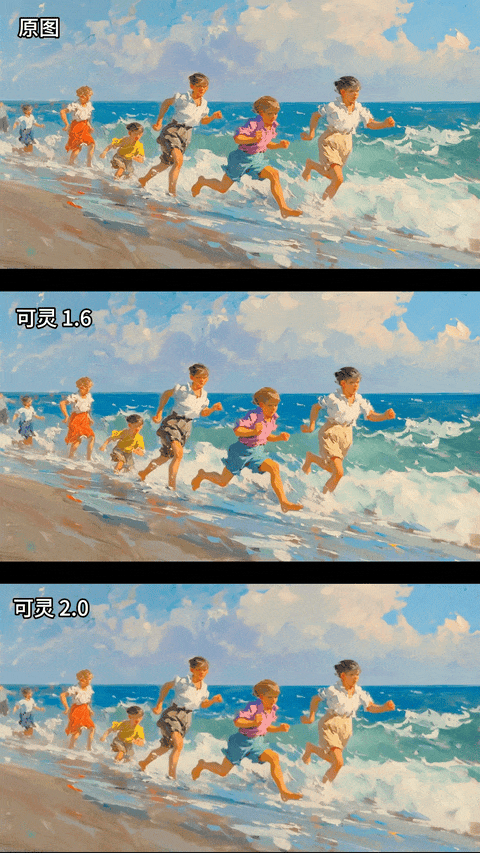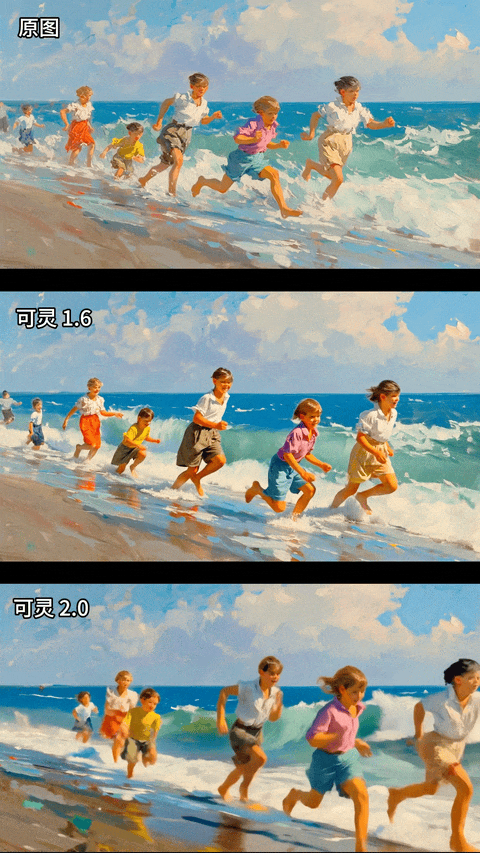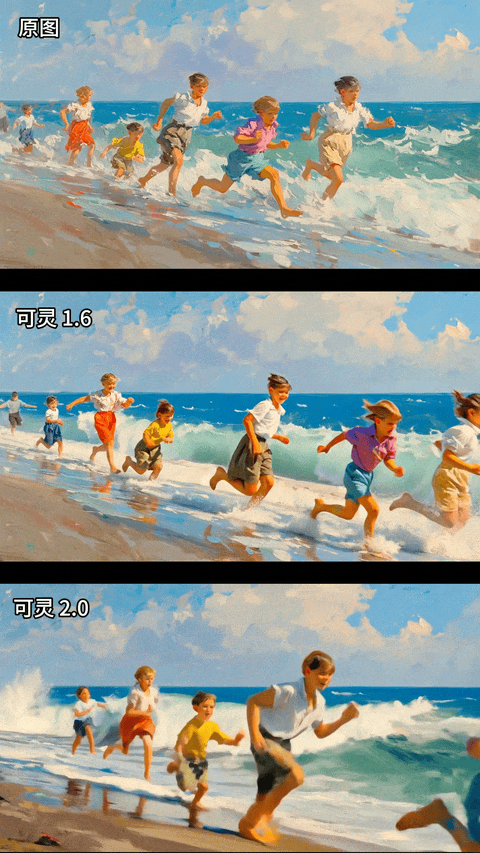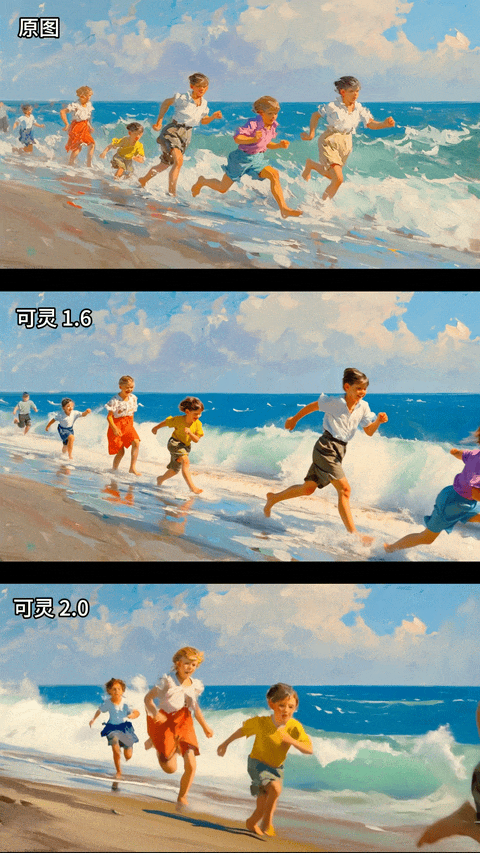
蜜蜂的画面更加具有电影感,画面细节更加细腻,审美的提升不是一点半点;同时图生视频对于原图的风格化保持的更加一致了,下面这个油画风格保持的基本不错,最牛的是,我盯着屏幕仔细看了这几个小孩的腿部动作,只有最后一个最小的小孩有点模糊,其他人腿部动作近乎完美。
看到这里,我真的还是想老套的说一句,太牛了,真的太牛了。其实,在可灵2.0没出来之前,1.6版本在我这里已经算很好了,简单的镜头它的犯错率极低,基本能够做到两三次直出的程度。但如今的2.0版本,将AI视频质量真的将进入下一个level了!
效果炸裂的多模态编辑功能
和可灵2.0一起到来的,还有一个非常令我意想不到的更新,就是“多模态编辑功能”!
你可以上传一段 1-5s 的视频,支持替换元素、增加元素、删除元素,让你方便进行视频修改、再创作,目前是在可灵1.6模型上支持使用。
这个功能以前不是没在其他模型上出现过,只是效果平平,无法实际应用。但这次可灵的这个编辑效果是出乎意料的好。
先看一个替换元素的case:

再来一个给视频中增加指定元素的case:

最后,直接删除视频中的某个元素:

我不知道你们看到这里,会是什么感受,我是觉得未来AI视频能做到的事情越来越多了。以前我们还经常苦恼的:单条镜头画面元素无法更改,现在,可灵已经帮我解决了。
可图2.0 图像模型
同时,图像生成模型也从可图1.5升级为可图2.0,在语义遵循能力、图像风格化生成、以及画面质感上都有非常显著的提升。我们同样来看几组对比:
一张超现实的照片,一条河从客厅墙上的油画中漂浮出来,洒在沙发和木地板上。这幅画描绘了山间一条宁静的河流。一艘船在水中轻轻摇晃,进入客厅。河流的边缘洒在木地板上,将艺术世界与现实融为一体。客厅装饰着高雅的家具和温馨、温馨的氛围,电影、照片

摆满了白色桌子的宴会厅,周围坐着的人在享用一顿美餐

工笔画,林黛玉,穿着唐代的服装,在咖啡店的角落,手里拿着一部智能手机,侧逆光,傍晚

比对给到的提示词,明显可图2.0对于提示语中各个细节的展现更加到位,尤其第二组餐桌的图片一下子就是乡村婚宴变成了豪门聚会,更别说对于“油画”、“工笔画”等等风格的展现了。
发布会彩蛋
多模态编辑这一块,可灵这次提出了一个新的概念:

这个概念来源于我们平时在制作AI视频的时候,有时会很难用文字具体的描述出自己想要画面如何运动的想法,这次可灵的多模态编辑提供了一个全新的写提示语的方式:

这和之前的多主体参考不同,而是让提示语中可以融合多种表达形式,不仅仅是文字、图片、视频、甚至是3D的动作序列描述文件:

这也就是,这次可灵AI正式发布的AI视频生成的全新交互理念:Multi-modal Visual Language(MVL),为的让用户能够结合图像参考、视频片段等多模态信息,将脑海中的多维度复杂创意,直接高效地传达给AI。

让AI更懂自己,可灵这次向着这个目标又近了一步。
写在最后
最后,我想给大家看看 @野菩萨 老师 和 @汗青 老师做的片子:
我可以说:
这,就是AI视频的2.0时代。
从去年6月份开始,可灵正式进入大众视野并被广泛使用,
我们见证了ta一次又一次的升级,
从最初的3s动态内容到如今流畅大幅度的长镜头,
从开始简单的提示语遵循到如今更精准的语义响应,
可灵从1.0、1.5、1.6,再到如今的2.0,
每次版本更新都没有辜负我们的期待。
我永远都可以骄傲地说出,
这是我们国产的模型,是世界的可灵,
它让每个人都能用AI讲出好故事。
@ 作者 / 阿汤 & 卡尔@ 动手学AI知识库 / learnprompt.pro
(文:卡尔的AI沃茨)