


近日,浙江大学赵洲教授团队联合字节跳动,发布第三代语音合成模型 MegaTTS3,在各大专业评测数据下均展现领先水平。MegaTTS3 以仅 0.45B 参数的轻量化架构,不仅实现高质量的中英双语语音合成,还在语音克隆方面展现出自然、可控、个性化的惊人潜力。

继 Mega-TTS1 解决传统语音合成技术可控性差、跨场景适应性弱问题,Mega-TTS2 解决长语音生成稳定性与自然度、细粒度特征建模问题,此次最新发布的第三代 MegaTTS3 模型,重点在语音-文本稀疏对齐精准性,生成效果可控性,生成效率与质量的平衡性上取得了重大突破。
MegaTTS3 的提出,将 AI 语音合成技术带上了接近人类自然发音的新高度,高质量、高可控、高实时、高性价比的新一代语音合成服务将很快进入大家的日常使用中。
目前,该模型已在 GitHub 和 Hugging Face 上同步开源,吸引了众多开发者和用户的关注,发布仅数天,github stars 超 4.5k,多家知名媒体报道评测。同时,用户可以在 Demo 中体验更多 TTS 效果,感受 MegaTTS3 带来的逼真度和流畅感。

开源地址:
https://github.com/bytedance/MegaTTS3
论文地址:
https://arxiv.org/abs/2502.18924

什么是 MegaTTS3?
MegaTTS3 是一款基于轻量级扩散模型的零样本文本到语音合成系统,它基于独特的零样本语音合成能力,能依托少量提示和几秒的音频样本,快速生成高度自然、富有情感且高度模仿目标说话人的语音。
与同等规模的模型相比,MegaTTS3 在实现轻量化的同时,兼具高质量与高效能,还能进行细粒度语音控制,在情感表达上处理得更细致入微。其显著特点包括:
-
轻量化高性能:其核心 TTS Diffusion Transformer 主干网络参数量仅为 0.45B,相比大规模 TTS 模型,更轻量、更高效、更易部署。
-
高质量语音克隆:可模拟目标说话人的音色、语气、节奏,生成清晰、自然、韵律丰富的语音。
-
中英双语支持:无缝支持中文和英文的文本输入,解决“英式腔调 vs. 美式腔调”不自然切换问题,甚至能在同一段语音中实现自然的代码切换(Code-Switching)。
-
口音强度可控:支持对部分语音属性进行强度控制和细粒度发音调整,自由选择语音是带点家乡味还是标准发音。

技术亮点
MegaTTS3 通过两大核心技术轻松复制你想要的音色。
1. 多条件分类器自由指导(Multi-Condition CFG):口音调控黑科技
demo 演示中可以看到,MegaTTS3 可以对口音强度进行控制,这其中多条件分类器自由指导起到关键作用。
-
功能:独立控制文本内容与说话人音色的引导权重。
-
优势:通过调整文本引导参数,生成“标准英语”或“带地方口音”的语音;生成高保真音色,说话人相似度(SIM-O)达 0.71,超越主流模型。
-
应用场景:外语教学中的发音纠正、影视配音的方言适配。
2. 分段整流流加速(PeRFlow):极速生成高质量语音
MegaTTS3 靠“分段整流流”技术给模型“踩油门”。
-
技术亮点:将生成过程拆分为多段并行计算,采样步骤从 25 步压缩至 8 步,速度提升 3 倍。
-
性能指标:生成 1 分钟语音仅需 0.124 秒(RTF 值),且质量损失可忽略(CMOS 仅下降 0.03)。
-
意义:为实时语音交互(如直播字幕生成)提供技术支持。

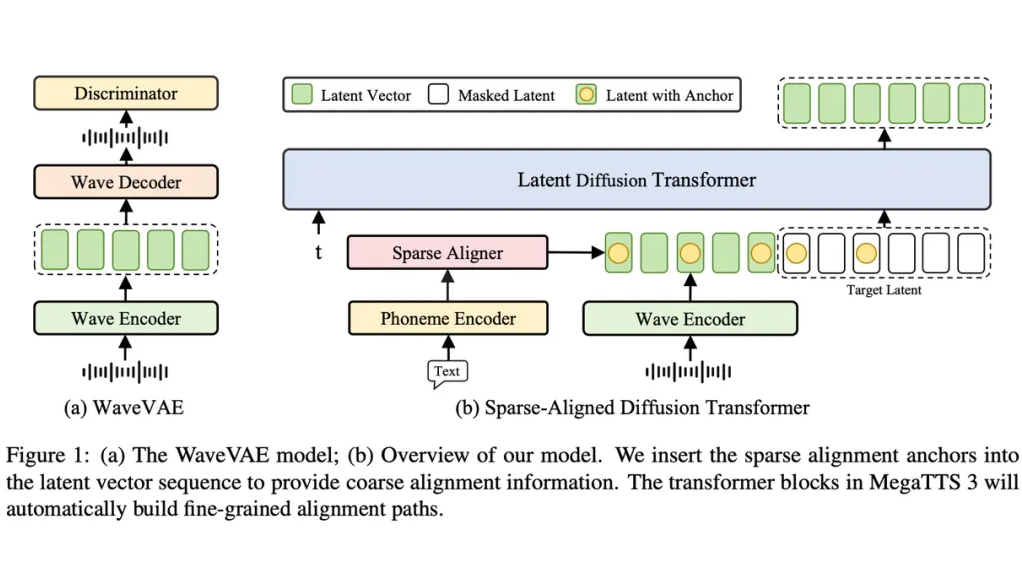
核心架构
MegaTTS3 采用 WaveVAE 和 Latent Diffusion Transformer 双模块协同合作,创造出超高质量的语音合成效果。
1. WaveVAE 模块
WaveVAE 模块的使命是将原始语音信号压缩成紧凑的潜向量:
-
编码器:对语音进行下采样,并提取关键的高频细节信息,使得每一帧潜向量都饱含声音魅力;
-
解码器:借助多尺度、多分辨率判别器(如 MPD、MSD、MRD),实现高保真语音的完美还原;
-
训练策略:通过重构误差、KL 散度和对抗损失的综合考量,确保生成的潜向量既精准又富有表现力。
2. Latent Diffusion Transformer 模块
在压缩后的潜空间中,MegaTTS3 利用扩散模型进行条件生成。
-
隐式对齐机制:Transformer 的自注意力机制在潜空间中构建出文本与语音之间的细致映射,确保语音与文本信息无缝融合;
-
稀疏对齐策略:通过在潜向量序列中嵌入少量对齐锚点,降低对齐难度,同时为每个音素提供精准的位置信息,使生成过程既自由又稳定;
-
训练方法:将潜向量序列分为“提示区域”和“遮蔽区域”,在提示条件下预测被遮蔽部分,模型在不断训练中逐步掌握精细对齐技能。

实验成果与优势
MegaTTS3 前代模型的表现就很优异,在相关论文中,MegaTTS 和 MegaTTS 2的语音质量(MOS-Q)和说话人相似度(MOS-S)指标均表现出与当时顶尖模型(如 NaturalSpeech 2, Voicebox)相媲美甚至超越的性能 。
FVTTS 等研究也将 MegaTTS 系列视为 SOTA(State-of-the-Art)模型进行比较。
据论文介绍,作为升级版的 MegaTTS3,自然度、相似度双领先,在 LibriSpeech 数据集上,生成语音的自然度(CMOS)和说话人相似度(SIM-O)都是当前最优,听着就像真人说话,连细节音色都能完美还原。
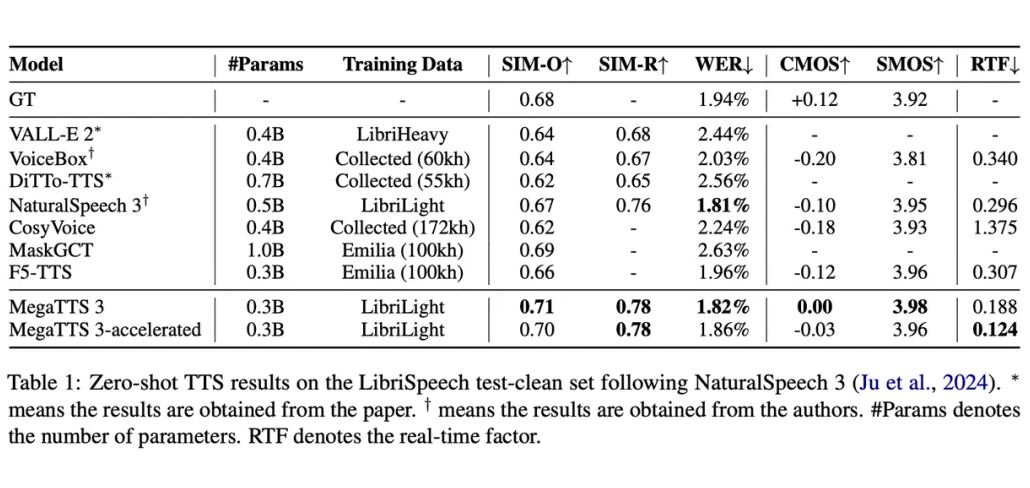
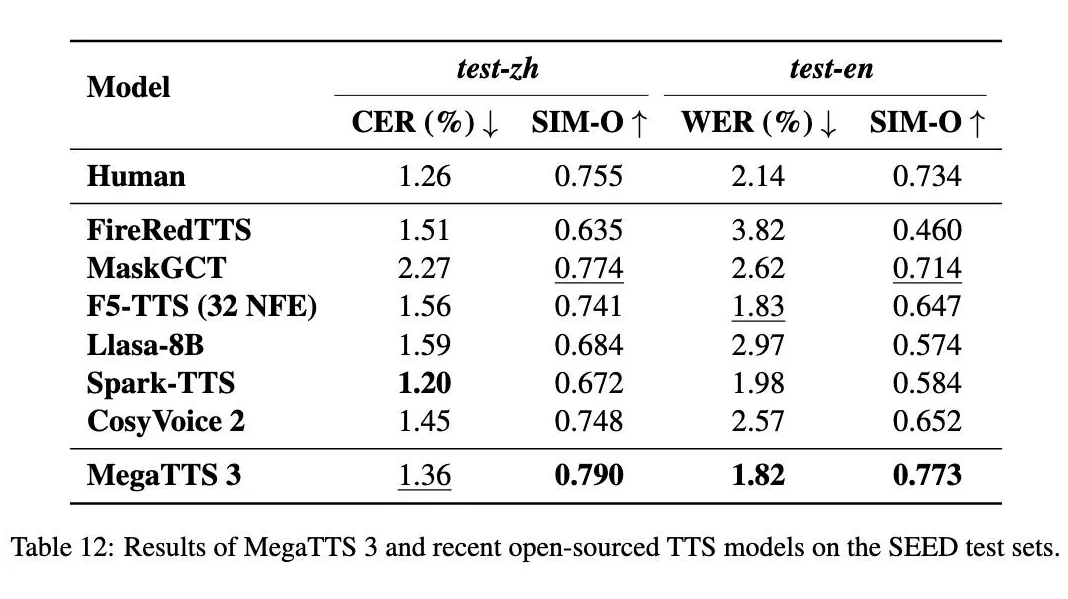
大量实验数据表明,MegaTTS3 在语音清晰度、可懂度和自然度上均表现优异。
-
高保真效果:即使在仅 8 步采样的情况下,生成的语音质量依然堪比最先进的技术;
-
鲁棒性提升:稀疏对齐策略使系统在长句和复杂文本下表现稳定,大幅减少对齐错误;
-
灵活个性化:multi-conditional CFG 策略赋予用户更多控制权,无论是语速、情感还是口音,都能轻松调节,满足个性化需求。

场景应用与未来展望
MegaTTS3 以其零样本语音合成能力、轻量级扩散模型和多语言支持等特点,为语音合成技术带来了全新的突破,满足了不同场景下的多样化需求,为用户带来自然流畅的听觉体验。
Demo 1 内容创作场景👇
视频创作者和博客主播可以通过 MegaTTS3 快速生成视频或博客旁白,MegaTTS3 仅需数秒音频样本,即可提供多样化的音色与韵律选择,支持中、英及多语言混合场景,有效适配全球化内容生产需求。
Demo 2 教育应用场景👇
MegaTTS3 通过将教材及学习资料转化为有声内容,助力视障群体及有阅读障碍的用户理解文本内容。其生成的高质量有声读物,为学习者创造了更生动直观的知识获取方式,推动教育资源的无障碍化传播。
Demo 3 智能交互场景👇
MegaTTS3 赋能智能语音助手及智能家居设备,构建亲切便捷的语音交互体验。用户可通过自然语音对话实现天气查询、音乐播放、提醒设置等功能,使智能设备真正成为兼具功能性与情感连接的生活伙伴。
Demo 4 车载语音导航场景👇
MegaTTS3 实现了路线指引、交通信息及路况播报的语音化输出,帮助驾驶员在获取关键信息时保持注意力集中,有效提升驾驶安全性。
*链接里还有更多官方demo:https://sditdemo.github.io/sditdemo/
作为语音交互的核心技术之一,TTS 已经在各行各业中展现出巨大的潜力。随着技术的持续迭代和社区的共同建设,我们期待 MegaTTS3 未来能带来更多惊喜,例如更便捷的零样本克隆能力、更丰富的情感和风格控制等。

结语
MegaTTS3 的问世打破了传统 TTS 技术的固有认知,以轻量级模型架构实现强大性能,重新定义了轻量级 TTS 模型的技术边界。这一突破不仅标志着语音合成技术的阶段性跨越,更为后续研究开辟了更广阔的优化空间。
(文:PaperWeekly)