

新智元报道
新智元报道
【新智元导读】两个月后就号称要淘汰GPT-4.5的GPT-4.1,实力究竟如何?在众多实测中,它的表现的确可圈可点,但却依然打不过Gemini 2.5 Pro和Claude 3.7 Sonnet。那么问题来了,OpenAI为何要发布一个远远落后于谷歌的模型?
不过两月,GPT-4.5正式出局,前浪把后浪拍在了沙滩上。
GPT-4.1家族的出世,以更强编码性能,百万token上下文,更具性价比的价格,直接击穿了4.5。
nano版的GPT-4.1性能足以媲美GPT-4o mini,而且速度更快,价格更便宜。
这些模型目前仅在API中提供,不过目前爆火编码平台Windsurf、Cursor开启了福利大放送,七天免费体验GPT-4.1。

这不,全网首波实测已经来了。

这款以超强编码著称的模型,在实际任务表现中又如何呢?

OpenAI科学家表示,GPT-4.1是不是推理模型,却可以在软件工程基准测试中拿下55%高分
网友Flavio Adamo用同一个提示——让小球在旋转的六边形中模拟自由落体,测试了GPT-4.1三款模型和GPT-4.5的编码表现。

不难看出,GPT-4.1精准模拟了小球物理运动过程,GPT-4.1-mini/GPT-4.1-nano却差了很多意思。
GPT-4.5的实力几乎不输GPT-4.1。

另一个类似的测试中,让GPT-4.1挑战旋转正方形,模拟出球体在正方形内真实弹跳的效果。
Kaggle开发者Parul Pandey表示,用GPT-4.1创建用于教育物理模拟的过程非常有趣。
如下,用小球击倒金字塔代码生成过程中,模型读取很少的不必要的文件,代码结构也非常简洁。

另一位工程师通过Windsurf让GPT-4.1在30秒内,便生成了一个贪吃蛇的游戏。
微软研究员Dimitris Papailiopoulos分别用GPT-4.1、GPT-4o、GPT-4.5去画独角兽,推测出4.1要比4o参数量小。

有一说一,GPT-4.1生成的独角兽是当中最丑的那个。
沃顿商学院教授Ethan Mollick用GPT-4.1去生成飞船控制面板的p5js。他表示,相较于GPT-4,4.1进步非常大,整体上表现出色。
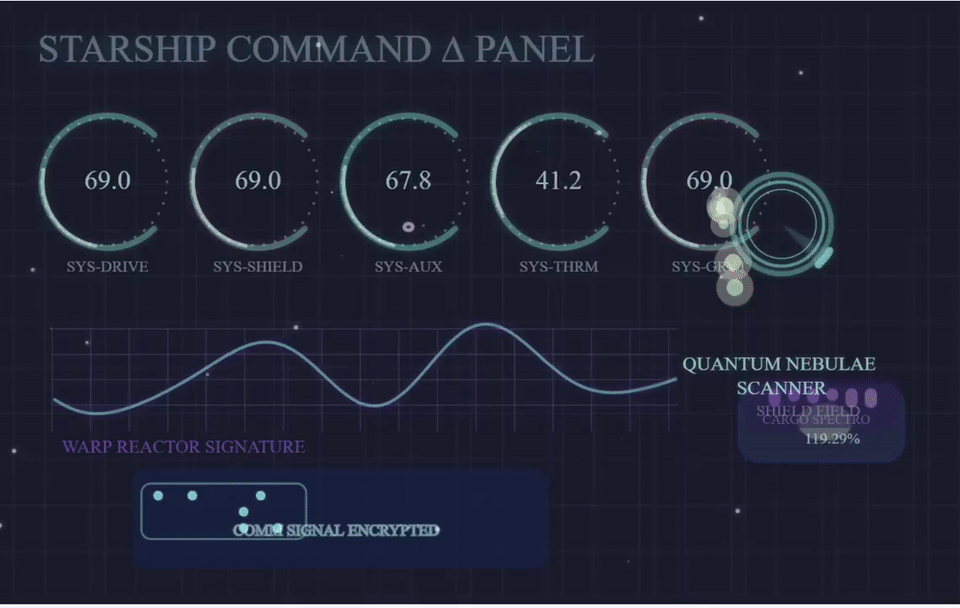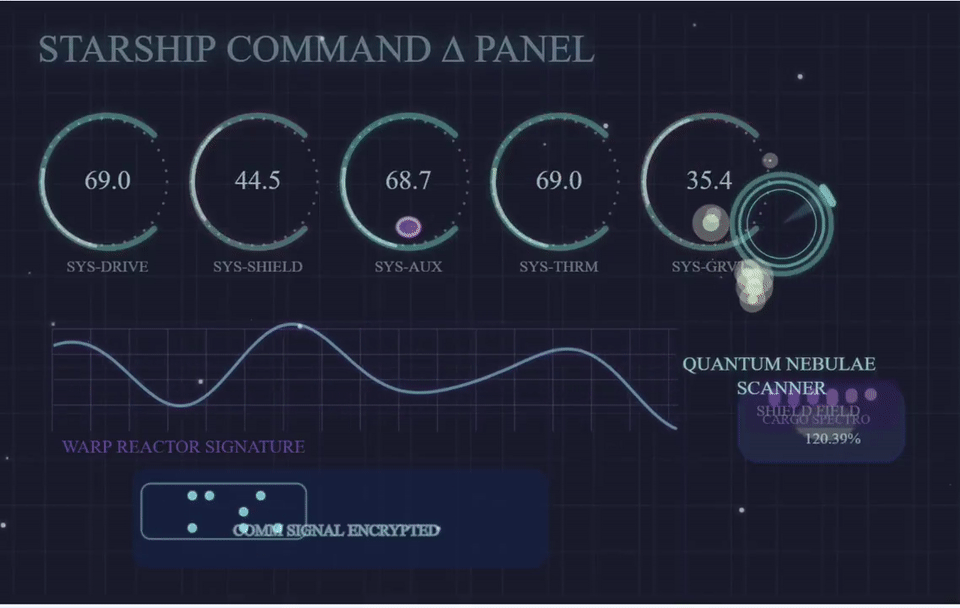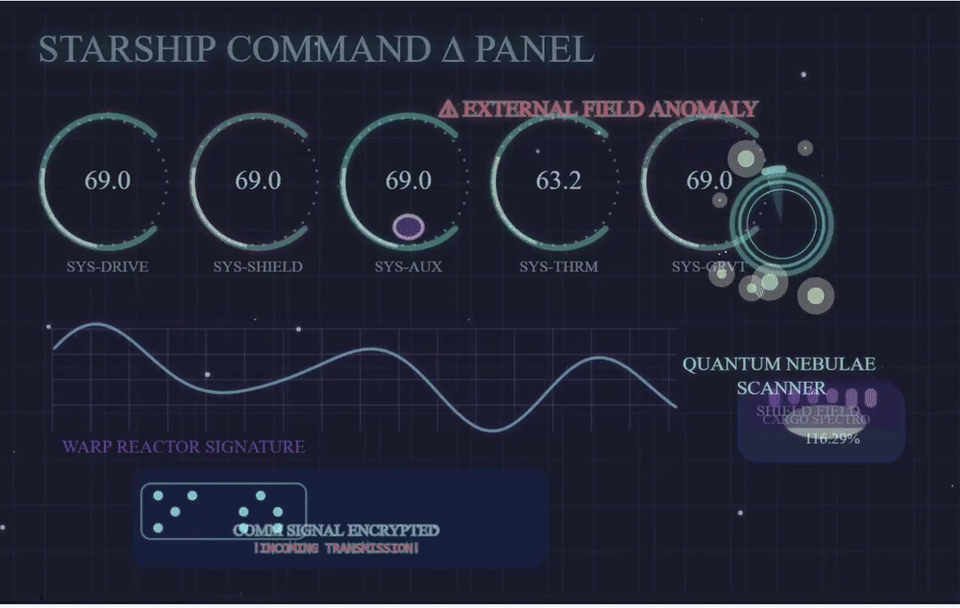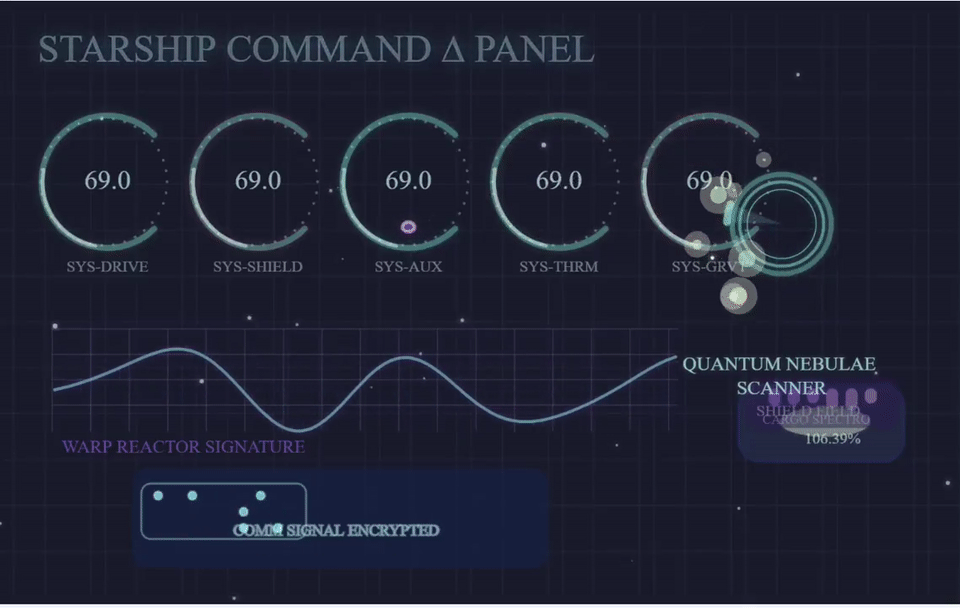
而且,Ethan表示GPT-4.1是第四款可以在twigl中首次运行着色器的模型。

网友让GPT-4.1和Gemini 2.5 Pro去模拟一个霓虹灯照亮的赛博朋克城市夜景,4.1模型在这个案例中还是比谷歌模型强不少。

以上demo中,不难看出GPT-4.1的编码性能确实非常惊艳,但从宏观来看,仍不如Gemini 2.5 Pro、Claude 3.7 Sonnet。
Aider多语言编码最新测试中,GPT-4.1得分为52.4%,接近Grok 3和DeepSeek V3。成本相较于o3-mini也降了一半。
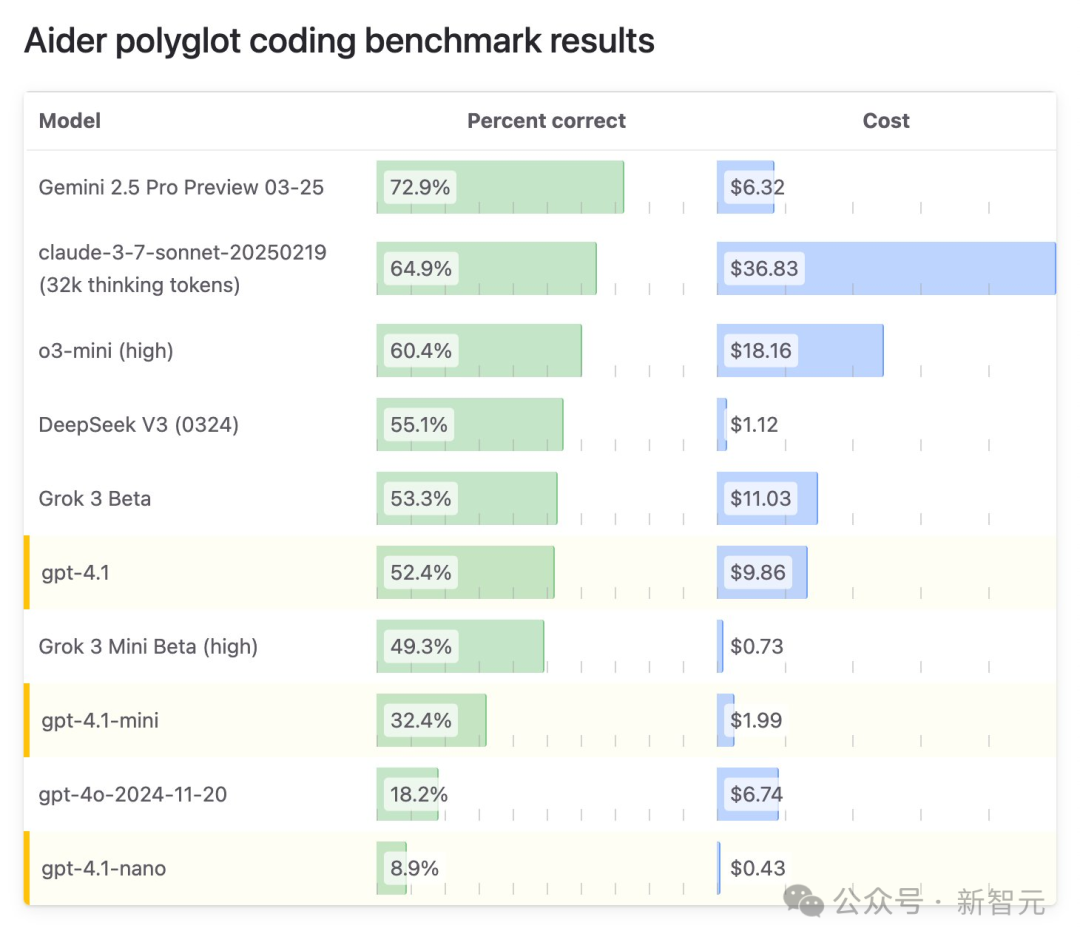
网友对此吐槽到,GPT-4.1编程不如DeepSeek V3,但价格却贵了8倍。

同样,在最新Livebench基准评估中,也同样印证了GPT-4.1推理、编码、数学实力比Gemini 2.5差。
Abacus.AI创始人Bindu Reddy表示,4.1性能在GPT-4o之上,但Livebench结果表明,新模型只是对4o的一个增量更新。
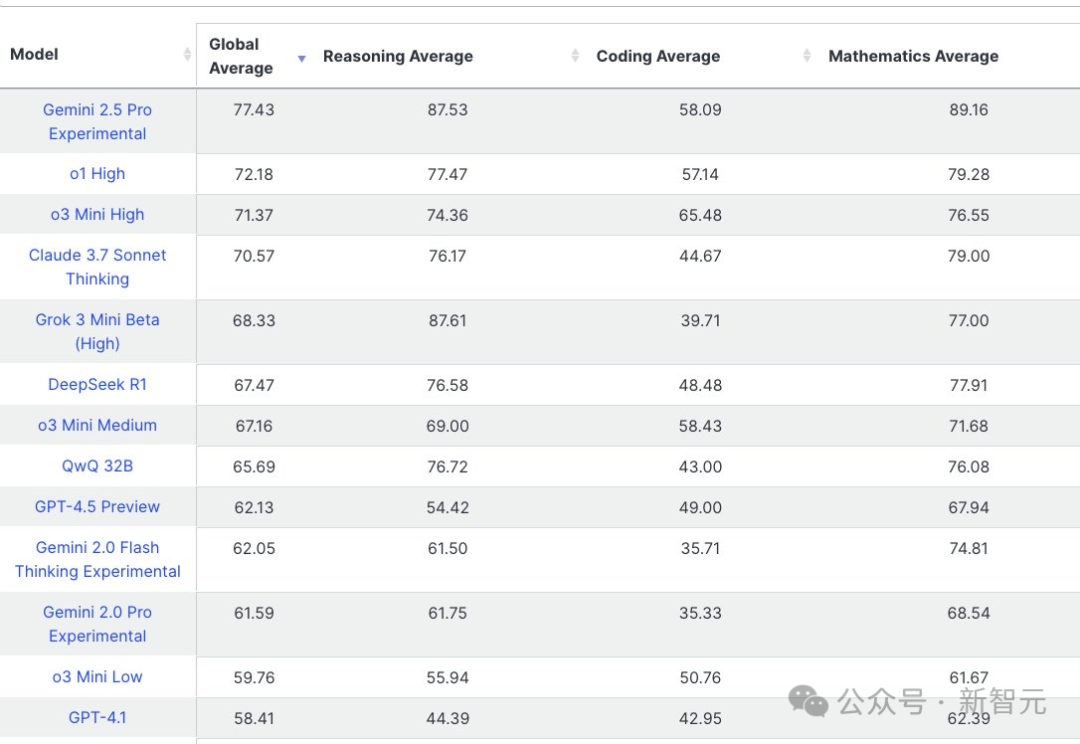
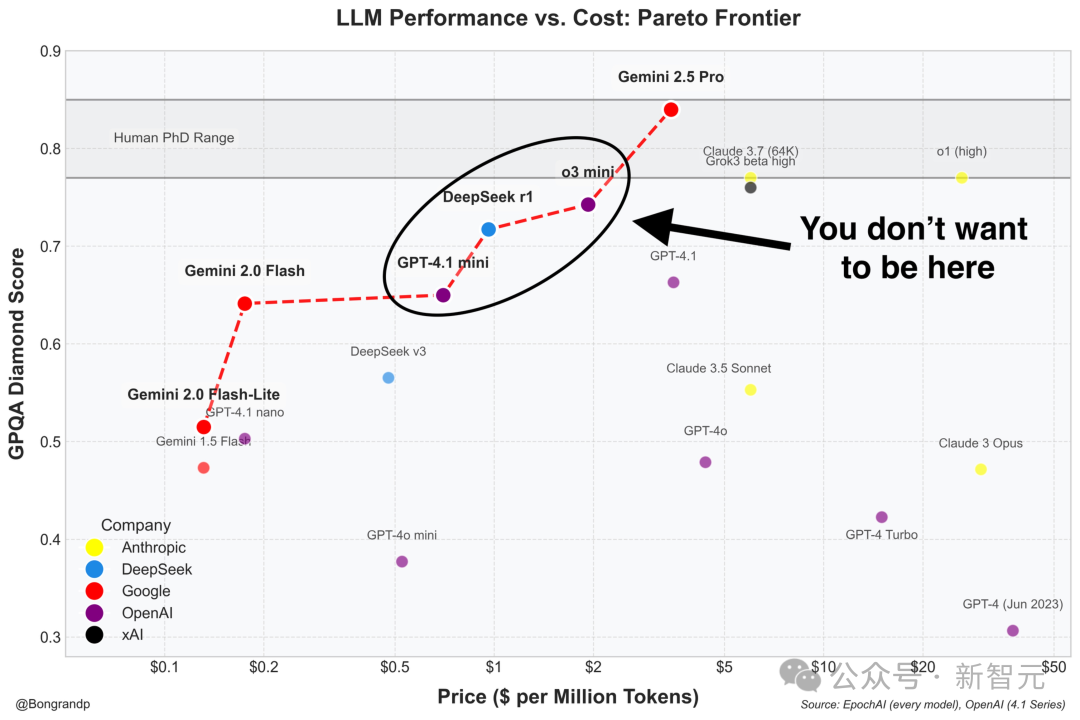
哈佛科学家Pierre Bongrand更是一针见血地指出,OpenAI首次在谷歌之后发布了一个远远落后的模型。

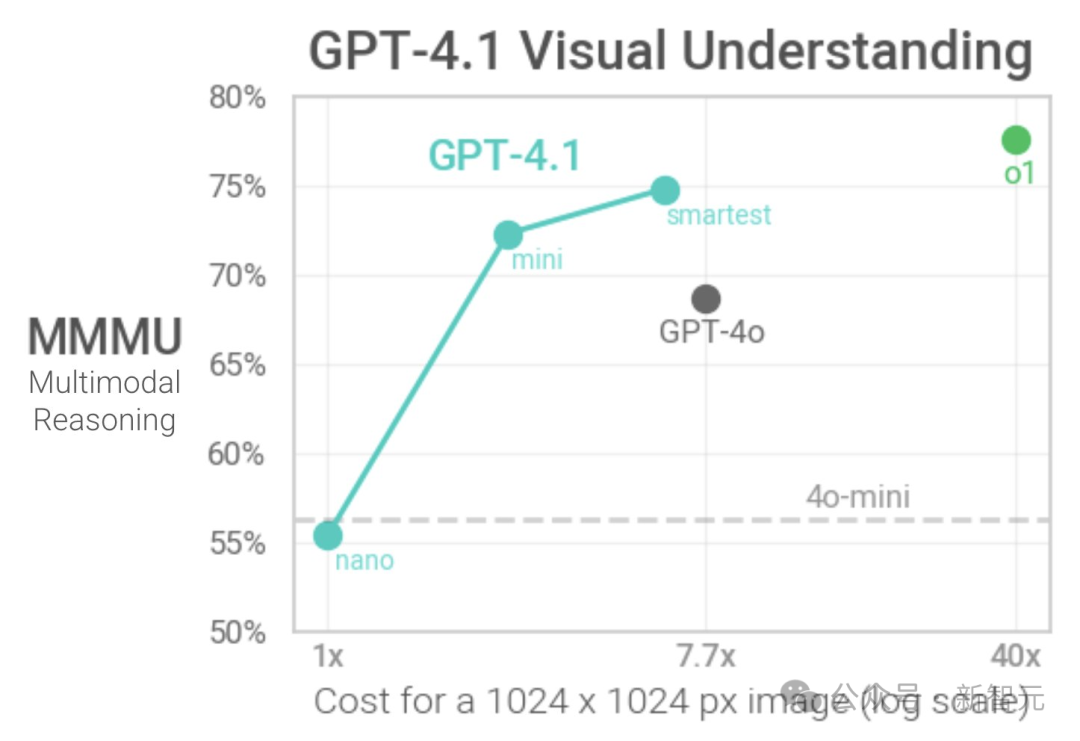
在GPQA Diamond知识问答基准测试中,GPT-4.1系家族未达到人类博士级水平,更别提超越Gemini 2.5 Pro了。
网友一张恶搞图戏称,在OpenAI发布GPT-4和GPT-4.1期间,谷歌便将Bard进化到最强Gemini 2.5版本。
今年的AI大战中,显然是OpenAI与谷歌硬碰硬的终极较量。
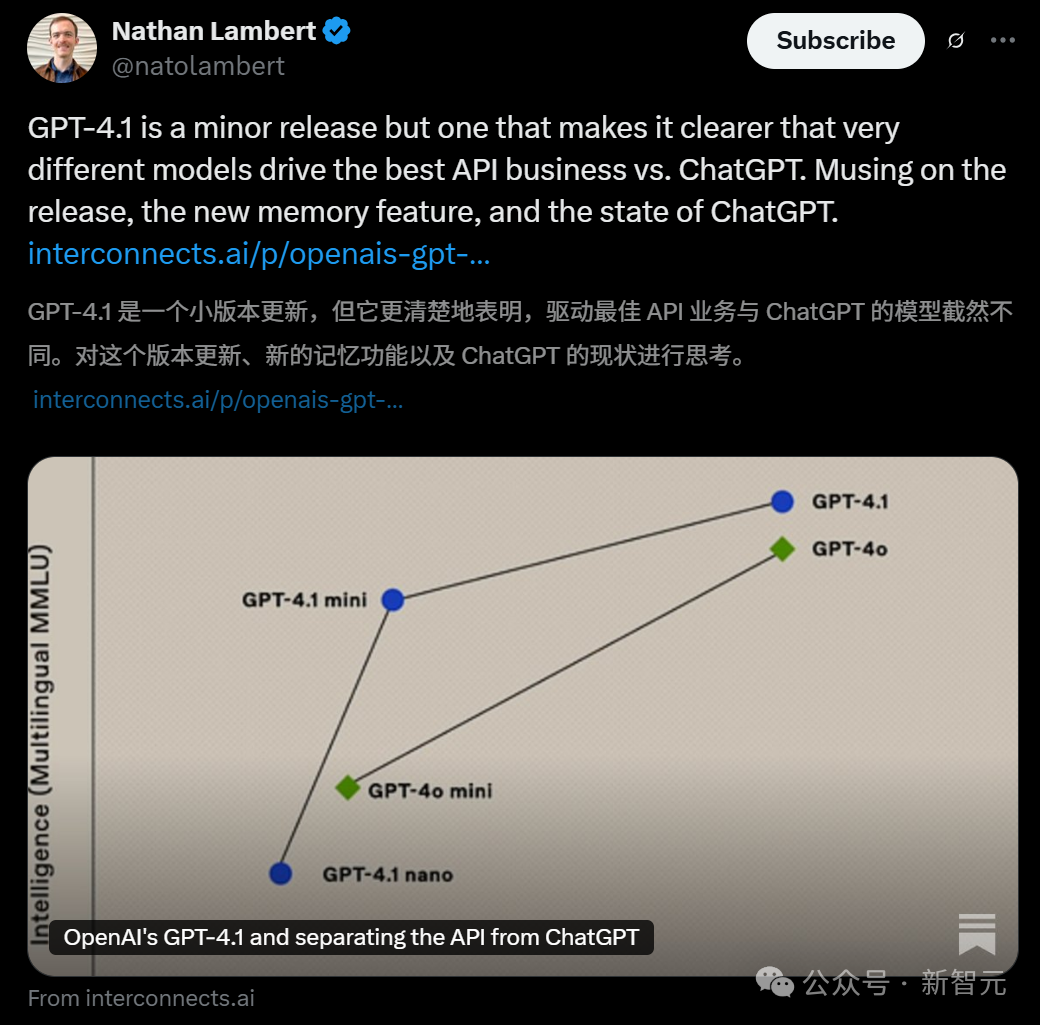
随着GPT-4.1的发布,Ai2后训练负责人Nathan Lambert也在第一时间发了一篇分析文章。
他表示,虽然GPT-4.1是一个小版本的更新,但这让人们更清楚地认识到,驱动着最佳API业务的,是非常不同的模型。
如今,OpenAI正在用GPT-4.1,将API和ChatGPT分离。
它的模型正在优化每一美元的智能,我们以后还将继续看到,ChatGPT的处理方式和API业务的不同。
最近,OpenAI 一直在进行各种小幅更新,而他们最终的愿景,就是将ChatGPT打造成一个独立于其API的单体应用。
上周,ChatGPT的记忆功能得到了改进。
今天,OpenAI又宣布了一套仅限API的模型GPT-4.1,直接跟谷歌的Gemini形成了竞争。
单独来看,其实最近的发布都没有什么颠覆性的前沿突破,毕竟性能相当的模型,已经存在了。
不过,从这些更新中,却可以看出OpenAI的战略重心走向。
如今,它的周活跃用户已经破了19亿,此时,它需要的是ChatGPT及背后模型,与市场上任何其他AI产品都截然不同。
其他产品的中心,主要都是编码或信息处理,与它们不同,ChatGPT则格外注重个性、氛围感和娱乐性。
体现这一点的一个经典例子,就是GPT-4.5连同它的高昂定价一起,正从API中被弃用,不过仍会保留在ChatGPT中。
即将发布的o3、o4或开放模型,目前还让人看不清OpenAI的宏观战略方向。
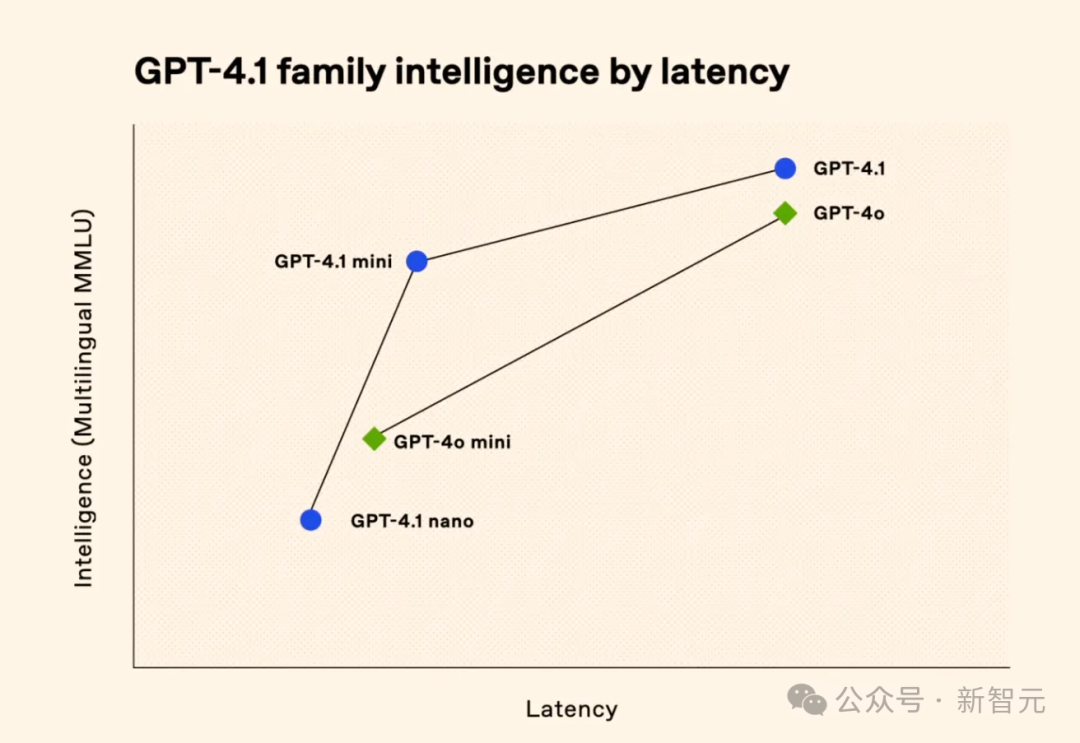
从下图可以看出,OpenAI传递的核心信息很简单——提供性能更好、推理速度更快的模型。
以下是新的OpenAI模型与谷歌Gemini每百万Token的价格对比(单位为美元)。
OpenAI新模型:
-
GPT-4.1:输入/输出:2.00/8.00 | 缓存输入:0.50
-
GPT-4.1 Mini:输入/输出:0.40/1.60 | 缓存输入:0.10
-
GPT-4.1 Nano:输入/输出:0.10/0.40 | 缓存输入:0.025
OpenAI旧模型:
-
GPT-4o:输入/输出:2.5/10.00 | 缓存输入:$1.25
-
GPT-4o Mini:输入/输出:0.15/0.60 | 缓存输入:$0.075
谷歌Gemini:
-
Gemini 2.5 Pro (≤200K Tokens):输入/输出:1.25/10.00 | 缓存:不可用
-
Gemini 2.5 Pro (>200K Tokens):输入/输出:2.50/15.00 | 缓存:不可用
-
Gemini 2.0 Flash:输入/输出:0.10/0.40 | 缓存输入:0.025(文本/图像/视频),0.175 (音频)
-
Gemini 2.0 Flash-Lite:输入/输出:0.075/0.30 | 缓存:不可用
虽然OpenAI的模型学术评估结果表现强劲,但这并未完全反映它们的实际情况。毕竟在实践中,它们需要执行的是重复性的小众任务。
显然,这些新模型是用来直接对标Gemini Flash和Flash-Lite的(在 Gemini 2.5 Pro惊艳发布之后,备受期待的Gemini 2.5 Flash也即将面世)。
相比之下,GPT-4o-mini的性能已经落后,且不如Flash好用。
想在API业务上取得成功,OpenAI就需要在Gemini已经占据优势的这个前沿领域实现突破。
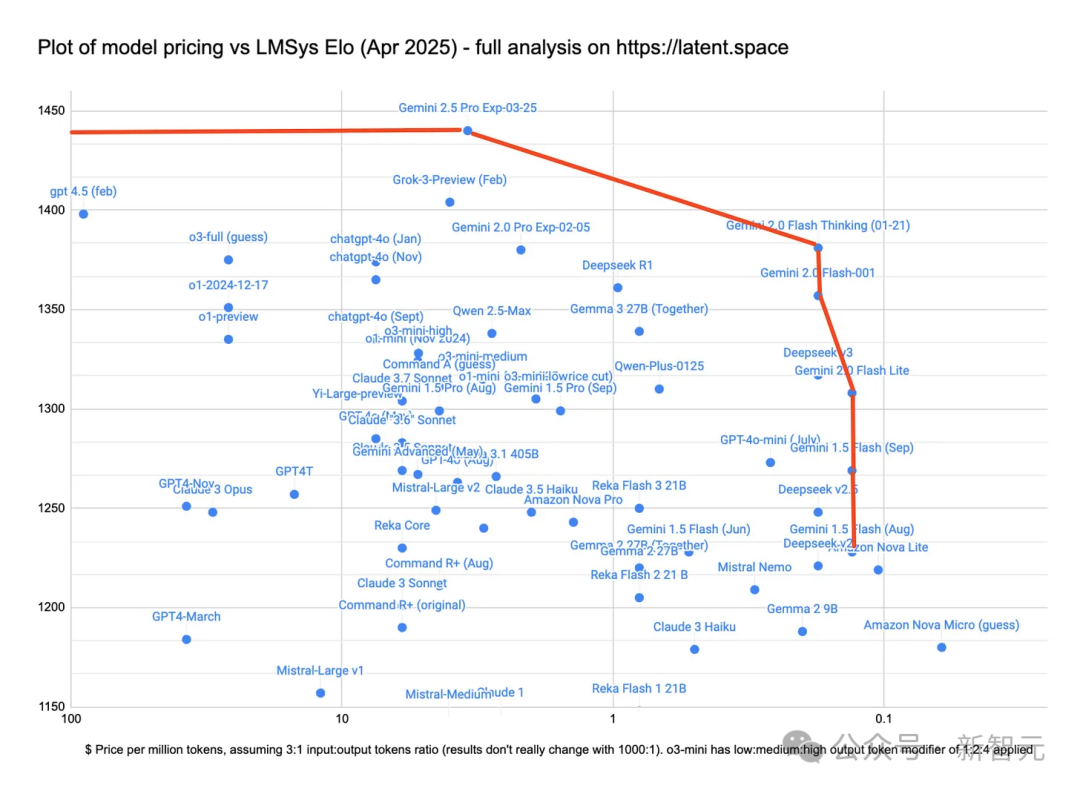

很多人已经发现了:在OpenAI的官方宣传中,这些新模型的发布模式如出一辙——有广泛改进,却很少解释具体原因。
所以几乎可以肯定,这些五花八门的新模型,都是为了获得更好的个性和推理能力,从GPT-4.5蒸馏而来的。
或者是在编码和数学上,借鉴了像o3这样的模型。
可以看出,新模型在代码上已经取得了重大进步,要知道,曾经OpenAI早期的模型在这方面曾经差得离谱,几乎挂0。
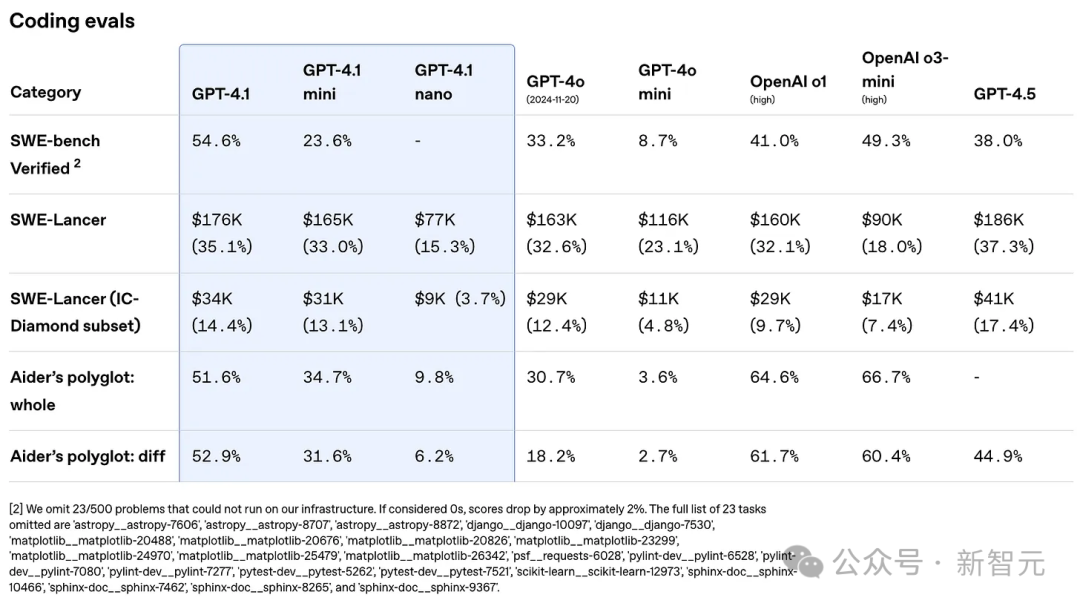
不过,在编码和数学的评估上,这些新模型仍然明显落后于Gemini 2.5(推理模型)或 Claude 3.7(可选推理模型)这样的顶尖模型。
如今,我们正处于模型向包含推理转变的早期阶段,但究竟什么是单一的最佳模型,这个概念已经变得更为复杂了。
这些推理模型会通过消耗远多于以往的Token,来实现性能的大幅提升。性能固然是王道,但若性能相当,则是成本更低者胜出。
但说到底,对大多数普通用户来说,上面这些技术细节其实意义不大。
对他们来说,那个被戏称为「模型投入度」的、令人头疼的滑块反而更直观——

长期以来,相对于API的价格,很多人对聊天机器人的订阅费会更感到犹豫。
但显然,一个日渐清晰的现实就是,真正个性化的、受用户喜爱的体验,往往只存在于这些集成的应用程序中。
当然,开发者也可以通过API构建竞品,积累用户交互数据,但鉴于 OpenAI在产品层面已经建立起了巨大的先发优势,想要胜过OpenAI,恐怕没那么容易。
所有这些,都再次印证了我们的认知:产品化,是当前AI发展的重中之重。
记忆功能,以及将ChatGPT这条产品线与API服务进行更清晰的切割,都有助于OpenAI铺平未来的发展道路。
但要完全实现这一愿景,OpenAI前方仍有很长的路要走。
(文:新智元)