

OpenAI推出的满血O3“跑分”(Benchmark)貌似又被独立测试揭穿是刷榜了,而奇怪的测试基准数据可能就是o3降智和幻觉倍增的原因?
你可能要问了,一个数学基准测试,与降智和幻觉有什么关系?
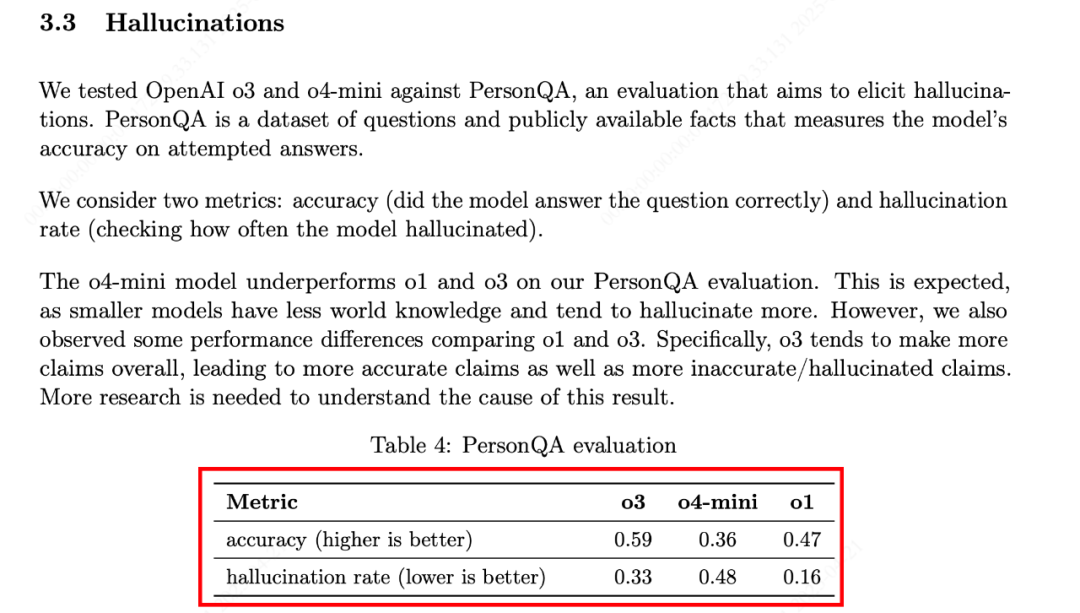
事情要从去年12月说起。OpenAI隆重推出O3模型时,公布了一个当时看来非常惊人的成绩:在专门针对数学问题的挑战性基准测试 FrontierMath 上,O3的得分超过了 25%!
这个成绩有多厉害?要知道,当时的顶尖模型在这个榜单上也只能勉强达到约 2%。OpenAI O3的这个数字,基本上是断崖式领先
真实成绩只有10%…?
然而,Epoch AI ( FrontierMath测试基准公司)这两天发布了他们对 满血版O3 的独立测试结果。
这一测不要紧,结果却让人大跌眼镜:Epoch发现,满血O3在同一基准测试上的得分竟然只有约 10%! 这个分数,虽然相对其他模型依然有优势,但和OpenAI最初那个25%+的“王牌”表现相比,差距可不是一点半点。Epoch直言,这个分数远低于OpenAI最初公布的最高成绩,测试成绩放在o3mini high和o4 mini当中看起来很奇怪,满血的o3竟然不如早先发布的o3 mini high
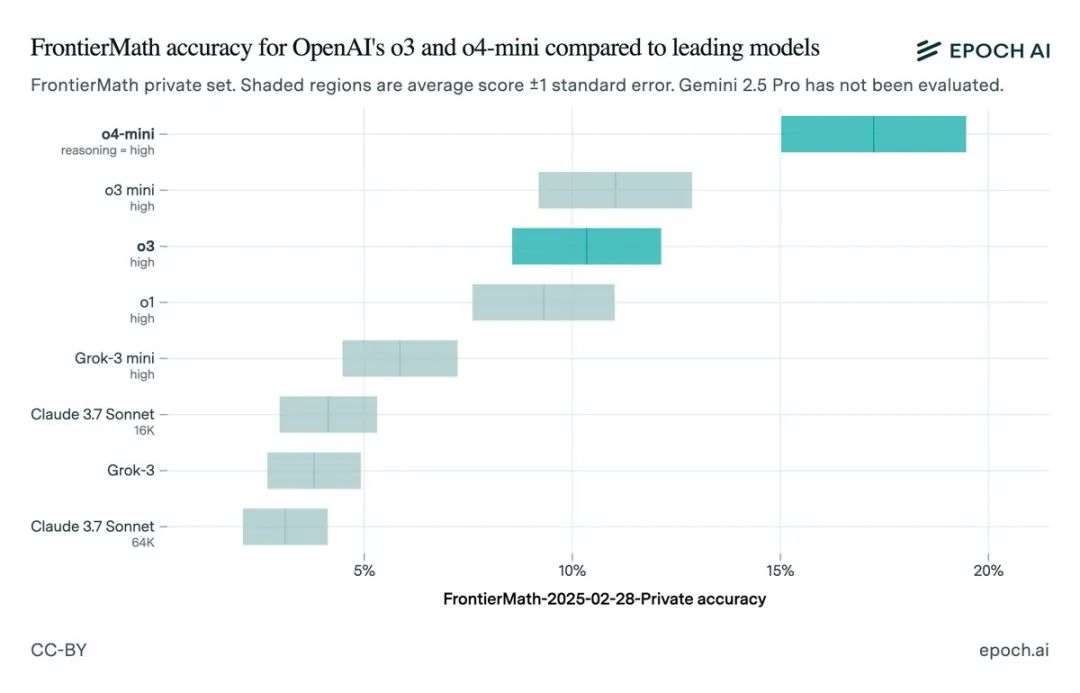
为什么会有这么大的差距?原因找到了
根据Epoch和相关方的说法,主要有几点:
测试环境与方法不同: Epoch 提到,OpenAI最初公布的那个高分,可能是在更强大的内部计算环境、或使用了更复杂的测试时间计算资源(比如多轮思考、内部推理链等)下得出的。这就像运动员平时训练时有教练指导、使用辅助器材,和正式比赛时的表现可能不一样
测试数据集不同: FrontierMath 基准测试本身也在更新。OpenAI最初可能使用了包含180道问题的旧版数据集进行测试,而Epoch测试的是包含290道问题的新版数据集。题目难度和数量变了,分数自然可能不一样
模型版本不同: 这是最关键的一点!据ARC Prize基金会等机构透露(他们也测试过O3的预发布版本),OpenAI 公开发布给用户使用的 O3 模型,特别是针对聊天和产品应用进行过优化的版本,与OpenAI最初用于跑分的那个性能更强的预发布版本是“不同的模型”。简单来说,公开版的计算层级(可以理解为模型的“大小”或“算力”)更小。通常来说,计算层级更大的模型能获得更好的跑分成绩
定位不同: OpenAI技术人员Wenda Zhou也在一次直播中解释说,公开发布的O3是针对成本效率和通用性进行了优化,以便更好地服务于实际应用。因此,它的表现可能与纯粹追求最高跑分、不计成本的演示版本存在“基准测试差异”。
写在最后
看起来这个所谓的满血版的o3也是一个优化的版本,一切都可以说通了,本来满血o3是要被整合到GPT5里边的,但是由于deepseek的冲击,还有成本等原因,最终奥特曼还是改变了注意,优化版o3还是单独推出了,有可能更好的模型被雪藏了,个人揣测这可能就是o3降智和幻觉增加的原因
如果您有不同意见,你是对的
⭐
(文:AI寒武纪)