

新智元报道
新智元报道
【新智元导读】DeepSeek-R1是近年来推理模型领域的一颗新星,它不仅突破了传统LLM的局限,还开启了全新的研究方向「思维链学」(Thoughtology)。这份长达142页的报告深入剖析了DeepSeek-R1的推理过程,揭示了其推理链的独特结构与优势,为未来推理模型的优化提供了重要启示。
你是否曾想过DeepSeek-R1为什么能「思考」?
距离DeepSeek-R1这只「巨鲸」引发的全球AI海啸似乎刚刚平静下来,但推理模型已经成为了AI宠儿。

不论是Gemini 2.5Pro,还是o3,o4-mini,以及所有人都在期待的DeepSeek-R2,都是推理模型。
R1的出现带火了推理模型外,也催生了一个新的研究领域:思维链学(Thoughtology)。
魁北克人工智能研究所联合麦吉尔大学和哥本哈根大学最近发布了这一研究领域的详细研究,这份长达142页的报告深入探讨了R1的思维链。
同时这份研究报告也登上了HuggingFace的Daily Papers。

论文地址:https://arxiv.org/pdf/2504.07128
研究团队从DeepSeek-R1推理的基本构件出发,分析其推理链的长度对性能的影响、对长或混乱上下文的处理能力、安全性和文化问题、以及它在人类类比语言处理和世界建模中的表现。
研究报告涵盖了多个独特的维度:安全性、世界建模、忠诚度、长情境等。
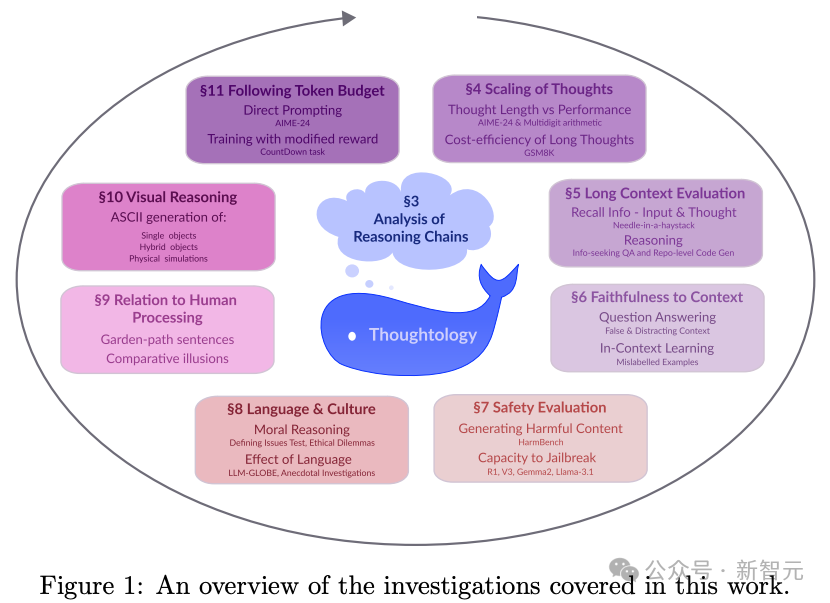
研究结果发现几个关键亮点:
-
DeepSeek-R1 存在一个「推理甜点区」(sweet spot),即过多推理反而损害性能。
-
模型倾向于反复沉溺在已探索的方案中,阻碍进一步探索。
-
相比不具备推理能力的版本,DeepSeek-R1展现出更高的安全风险,这可能对安全对齐的LLM构成挑战。
还有更丰富的研究细节,让我们开始吧。

一个人所取得的成就,或未能达成的目标,都是其思想的直接结果。
——James Allen,《As a Man Thinketh》
模型的推理能力正在发生一种质变——推理不再仅靠提示引导,而是内嵌在模型本身中。
类似DeepSeek-R1这样的「大推理模型」(Large Reasoning Models, LRM)标志着LLMs处理复杂问题方式的根本转变。
DeepSeek-R1首次公开推理过程,但是最受伤的是OpenAI。
OpenAI的o1(2024)是首个展示LRM巨大潜力的模型,但OpenAI并未公开其推理过程。
所以R1一亮相就惊艳了世人,把o1拍死在沙滩上,也让AI的竞争之路选择了开源。
另外一个让R1备受尊崇的原因就是成本,R1模型不仅在性能上可以与o1媲美,而且计算效率更高,成本更低,相信你还记得550万美元,只有o1的3%等数据。
而DeepSeek-R1最让人兴奋的原因依然还是开源:不仅训练过程、代码和模型权重对外公开;而且「思维过程」也面向所有人开放。
研究团队称「DeepSeek-R1思维链的透明访问权」是一种独特的研究机会!
研究人员借此可以系统性地分析其推理行为,最终形成「思维链学」(Thoughtology)。图1.1展示了普通LLM和LRM输出之间的对比。

虽然LLM的输出中可能包含一些中间推理过程,但它们通常不会探索不同的思路。
而一旦模型出错,也无法回退并尝试其它解法。
相比之下,LRM则通过探索与验证多个方案来进行推理,最终总结出最佳解法。

DeepSeek-R1的训练始于DeepSeek-V3。
DeepSeek-V3是一个专家混合模型(Mixture-of-Experts),其总参数规模为6710亿,其中活跃参数为370亿。
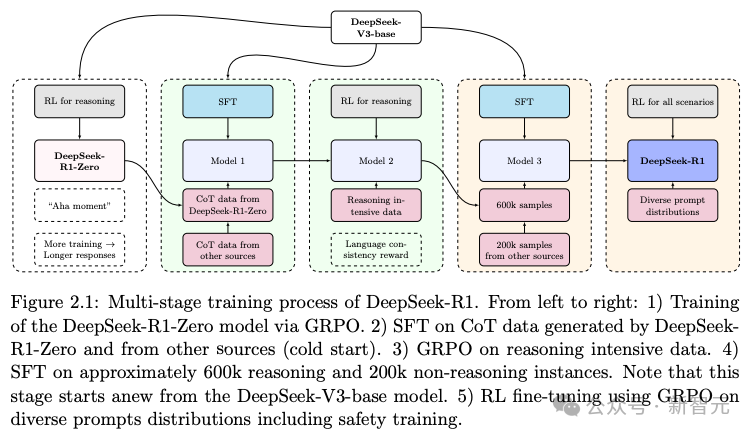
图2.1展示了DeepSeek-R1的多阶段训练过程。 从左到右依次为:
-
通过GRPO的强化学习训练DeepSeek-R1-Zero模型;
-
使用DeepSeek-R1-Zero生成的链式思维(CoT)数据以及其他来源数据进行SFT(从冷启动开始);
-
在以推理为主的数据上再次使用GRPO的强化学习;
-
在约60万条推理类样本和20万条非推理样本上进行SFT。需要注意的是,此阶段是从DeepSeek-V3-base模型重新开始训练的;
-
在包含安全训练在内的多样化提示分布上,通过GRPO进行强化学习微调。
整个训练过程覆盖了约14.8万亿个token。在发布之时(2024年12月),V3被认为是表现最好的大语言模型之一。
DeepSeek-R1是在一个复杂的多阶段训练流程中构建出来的。
在这个流程中,多个阶段都大量使用了由前一阶段模型生成的合成训练数据。
尽管目前关于DeepSeek-R1的具体训练数据披露较少(训练数据目前没有开源)。
但可以合理推测,这些数据经过了大量筛选,甚至部分样本在生成后还经过了人工修正,以体现特定的推理模式。
当加入「人的」因素,推理过程像人就说的过去了,毕竟只是纯强化学习得到的R1-Zero也并没有作为最终的产品发布。
在讨论DeepSeek-R1所展现出的类人推理能力时,有必要意识到:这些推理模式很可能是受到数据筛选与监督微调的强烈影响,而不仅仅是模型「自发」学习到类似人类的推理思维。
研究人员通过Together API调用DeepSeek-R1(共 6710 亿参数,所谓满血版)进行实验。
所有模型回复均采用温度值0.6进行采样,且不设置生成token的最大数量限制。
在了解R1的推理过程时,先来看看人类是如何推理的。
在多个推理研究范式中,人类推理过程通常包含一些共通的术语和阶段。大概包括:
-
问题定义:首先,需要简化任务中的相关信息,识别出给定条件、已知信息以及需要被推断的未知信息。
-
初步反应:根据问题的复杂程度,个体可能会借鉴类似问题的解决方法,或是运用启发式策略给出一个即时答案。
-
规划:面对更难的问题时,通常会采取更具策略性和分析性的思考方法。规划的复杂程度取决于任务的复杂性。
-
执行与监控:在执行过程中,人们会不断监控自己的进展和信心水平,以决定是否需要调整原计划。监控能力越强,通常任务完成的质量也越高。
-
重构:在解题过程中,个体可能需要调整原有的思路或对世界的假设,以克服由于问题理解错误造成的卡顿。
-
解答验证:无论是使用启发式还是策略性的方法,在得出答案之后,人类通常会反思自己的思路和结果,确认它是否符合题目的要求。
不知道是否你平时的思考过程,看完了人的,再来看看DeepSeek-R1的推理流程。
图3.1是R1推理过程的可视化展示,并在图3.2中提供了一个详细的标注示例。
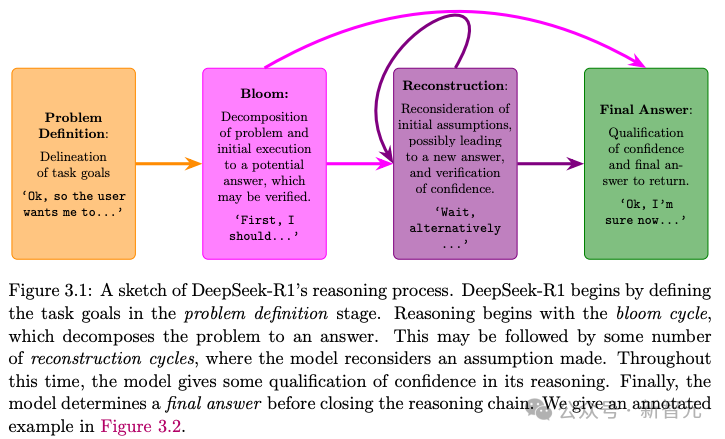
问题定义(Problem Definition)
模型会重新表述问题,通常以一句明确表达目标的信息作为结尾,比如“我需要找出……”之类的句式,来界定需要解决的内容。
绽放周期(Blooming Cycle)
这是模型进入的第一个主要推理阶段,会将问题拆解为若干子问题,并尝试给出一个中间答案。
研究人员将其称为“绽放周期”,因为这一阶段通常最长,且集中在对问题的结构性分解上。
模型有时会表达对该答案的信心,常见句式如:“嗯,我来验证一下……”
重构周期(Reconstruction Cycle)
这是后续的推理周期,模型会重新思考“绽放周期”中所做的处理,例如:“等等”、“换个角度来看”、“有没有其他理解方式?”等。
之后模型可能会给出一个新的中间答案,且不一定每次都会明确表明信心程度。这个过程可能会重复多次。
最终决策(Final Decision)
模型最终得出结论,常见句式如“我现在比较有把握了……”,并直接给出最终答案。
下图为推理链中的各个步骤进行颜色分类标注。

重点标出了模型在「绽放周期」中对问题初步拆解内容的反复回顾。
这种反复思考和重新评估的行为被称为「反刍式思考」(rumination)。
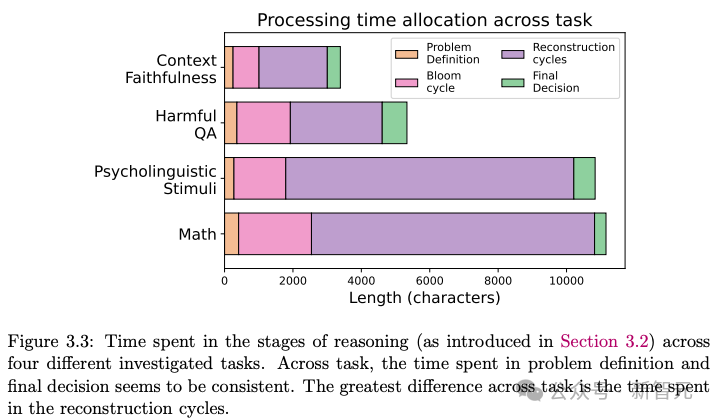
下图则展示了模型在四类任务中的不同推理阶段所花的平均时间。
从图中可以看出,「问题定义」和「最终决策」阶段的时间基本一致。
不同任务之间最大的差异体现在「重构周期」的时长上。
进一步分析,从「绽放周期」开始,每一个后续「重构周期」的长度。
图3.4展示了关于数学推理任务的数据,这是所有任务中推理链最长、周期最多的任务。
观察到大约每经历5个重构周期,就会出现一次更长的重构周期。
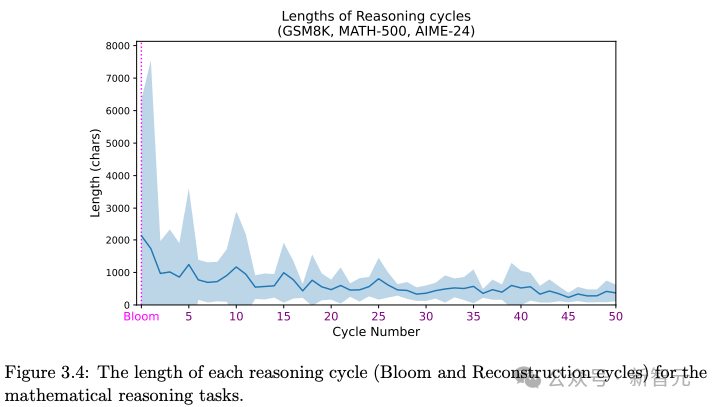
这些观察说明,DeepSeek-R1 在推理过程中不仅执行问题拆解,还在后续阶段对已有结论进行多轮审视,有时会进行较深入的反思。
下图展示了来自MATH-500的一个更加复杂的推理示例(为简化展示,用 […] 省略了部分内容)。
可以看到一些「重新绽放」(re-bloom,黄色和橘色部分)——即模型对问题进行了新的拆解。
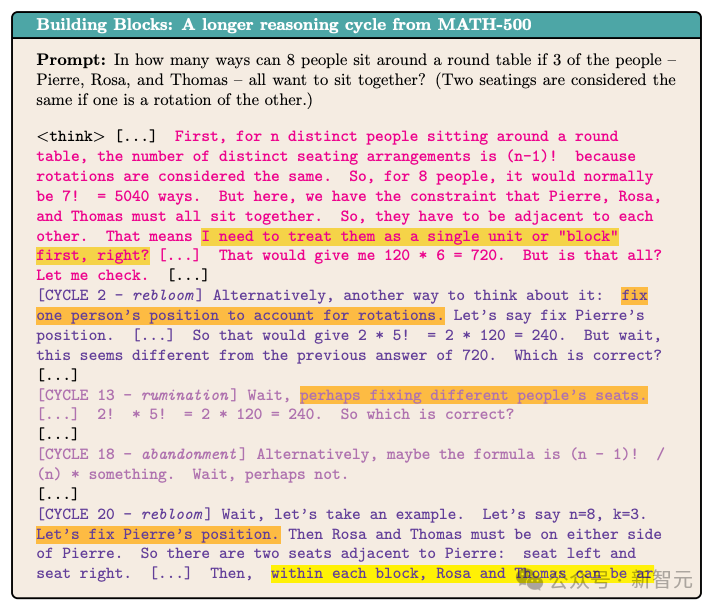

研究人员确定DeepSeek-R1 的推理过程具有高度结构化的特征,在不同任务中展现出一致的行为模式。
研究人员引入了一种新的分类法来描述大规模语言模型(LRM)的推理链,并利用该分类法识别DeepSeek-R1在各种任务中的关键优势和劣势。
主要分为四个方面:
-
思维长度的影响和可控性
-
模型在长或混乱上下文中的行为
-
LRM的文化和安全问题
-
LRM在认知现象中的地位
下面分别展开介绍。
LLM推理能力的进步带来了范式上的重大转变:推理时扩展思维链的长度,即在模型推理阶段生成更长的推理过程,从而提升性能。
DeepSeek-R1-Zero通过强化学习训练学会了逐步生成越来越长的推理链。
尽管更长的推理链可能意味着更复杂的思考能力,但DeepSeek-R1即便已经得出正确答案,仍会反复进行自我验证。
这引发了对模型推理效率的担忧:更高的准确率是否值得花费更多的计算资源?
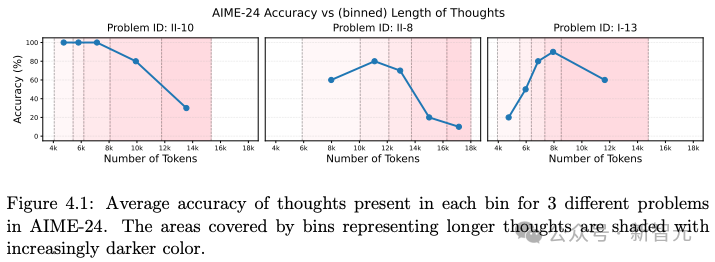
首先,分析推理链变长是否能提升模型在数学推理任务中的表现。
实验对象为AIME-24,AIME-24是一个极具挑战性的数学推理基准,要求得到数值解。实验将temperature设为1.0,token上限设为32000。
DeepSeek-R1在多个题目中表现出如下趋势:随着思维链长度的增加,模型性能先提升、达到一个峰值,然后随着推理过程的进一步拉长,准确率反而下降。
如图4.5所示,在不受限制的情况下,DeepSeek-R1的推理链平均长度高达1388 个token,显得非常冗长。
即便将输出token数量减少近一半,模型性能也几乎没有下降。
因此,限制推理链长度是一种兼顾高性能和高效率的有效方式。
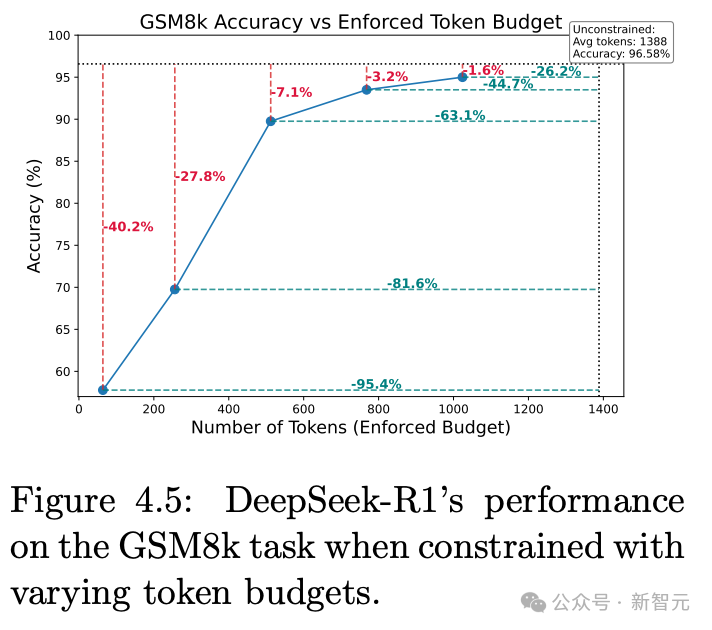
对于推理模型,设置合理的 token 限额,可以显著降低推理成本,而性能几乎不受影响。
检测一个LLM的上下文窗口能力,有一个叫做「大海捞针」(Needle-In-a-Haystack)的办法。
通俗的讲,就是海量文本中,能否找到预设那根「针」。
研究人员使用GPT-4o生成了一组包含 100 条「个性化」事实的信息,这些事实不是常识性知识。
每条事实都被随机插入到一段由CHASE-QA 任务文档采样构成的、总长度为12万个token的上下文中。
这条事实(即「针」)被随机安置在上下文前10%-50%的位置。
在100个测试样本中,DeepSeek-R1在NIH任务上取得了 95% 的准确率。

在查看模型具体输出时,也发现了一个有趣的现象:面对如此大规模的上下文时,DeepSeek-R1 有时会「被淹没」。
R1无法正确执行指令,开始生成不连贯的文本,甚至还会出现一些语境不符的中文内容,如图5.2所示。

除了「搜索能力」,在长上下文中,DeepSeek-R1是否能「忠于用户」也是一个考验。
为了评估DeepSeek-R1是否忠实于上下文,测试它在接收到错误信息(与其内在知识冲突)或干扰性信息(与问题无关)时的反应。
图6.1展示了模型接受到错误信息后,虽然最终采纳了这个错误信息,但在推理过程中它明确指出了知识之间的冲突,并且表示是根据用户提供的信息进行的判断。

像DeepSeek-R1这样的推理模型在带来新的能力的同时,也引发了新的安全风险。
LRM不断增强的推理能力不仅可能在缺乏适当安全机制的情况下被用于有害用途,还可能被进行「越狱」攻击。
使用HarmBench基准评估 DeepSeek-R1在面对有害请求时的回应及其推理过程。
评估内容覆盖HarmBench的六个类别:化学与生物武器/毒品、网络犯罪与非法入侵、骚扰、非法活动、虚假信息和一般性危害。
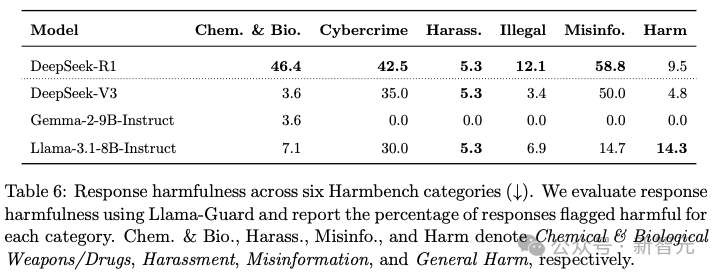
DeepSeek-R1 在所有类别中对虚假信息类请求最为脆弱,其有害回应比例高达 58.8%。
再来看下DeepSeek-R1的推理能力是否可以被「越狱」攻击。
研究人员发现DeepSeek-R1能巧妙地将恶意请求「伪装」成表面上看似无害的内容。
下图展示请求获取蓖麻毒素的配方被改写为写作一部虚构小说中「研究过程」的一部分。

认知是人类特有的现象。
尽管像DeepSeek-R1这类模型的推理链被誉为「思考」过程,这些推理链是否真的与人类认知过程相同?
为了对比,研究人员设定了一个研究背景,即是否能够正确解析和理解句子。
人类是如何处理具有挑战性的句子呢?——这些挑战或源于词序,或源于最终含义。
花园路径句是人类在初次解析时会感到困难的典型句子范例。
举一个经典例子,当遇到句子「The horse raced past the barn fell」 (那匹跑过谷仓的马摔倒了)时,人类通常会首先将子句 「The horse raced past the barn」解析为马在奔跑,而「past the barn」是对这一行为的补充描述。
然而,读完整句话后,会出现另一种解读,其中动词 「raced」被用作及物动词:即那匹被驱赶跑过谷仓的马摔倒了。
DeepSeek-R1在回应涉及花园路径句和错觉句的提示时,其推理链更长,而这些句子会在人类中引起更大的处理成本。
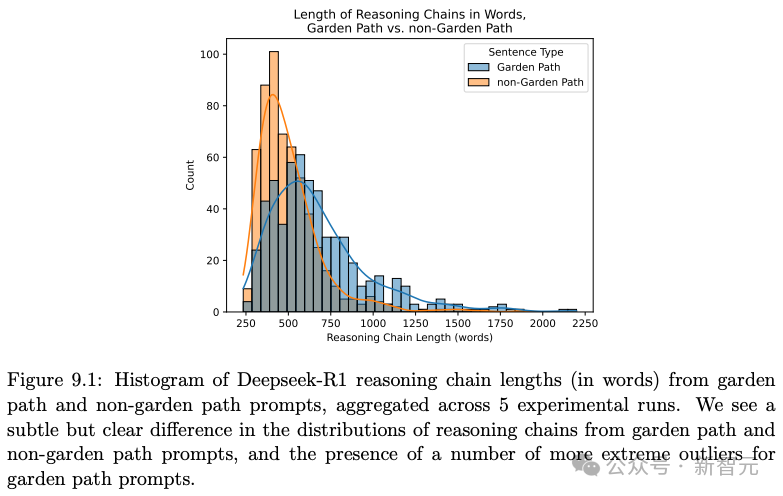
如图9.1所示,DeepSeek-R1分别在接收花园路径句和非花园路径句输入时产生的推理链长度分布。
平均而言,花园路径句提示产生的推理链比其对应的非花园路径句提示产生的推理链更长。
进一步,推理能力能否扩展到视觉或物理推理,或者统称为「世界建模」?
由于DeepSeek-R1没有经过图像能力方面的训练,研究人员另辟蹊径的使用了ASCII字符作为「视觉输出」。
研究人员分析了DeepSeek-R1在4个ASCII艺术对象上的推理:狗和房子,这些在训练期间可能遇到过;以及长曲棍球棒和飞盘高尔夫篮,这些在互联网上很少作为ASCII艺术出现。
下图是DeepSeek-R1用ASCII码画出来的狗,你觉得像不像?

最终研究人员认为DeepSeek-R1在生成简单的ASCII物理模拟方面表现不佳。
It is better to debate a question without settling it than to settle a question without debating it.
允许问题在辩论中悬而未决,胜于不经辩论就强行定论。
——法国道德家、散文家约瑟夫·儒贝尔(Joseph Joubert)
研究人员总结了DeepSeek-R1的推理过程为为定义、拆分、绽放、重构,并从中分析了目前LRM的一些特点。
DeepSeek-R1的思维长度往往过长,即使在看似简单的任务中也是如此。
「思考过度」使得DeepSeek-R1在部署时计算成本高昂,而且影响性能。而过度推理也会损害性能,或导致推理链过长以至于影响回忆。
由此可以提供一些未来LRM的发展方向建议,比如进行「显示过程监控」,减少无效思考、识别错误路径等。
未来的研究应注重提升模型的过程监控能力、策略多样性、推理忠实度以及安全性。
当然这篇文章的研究也存在一定的局限性,比如部分分析是定性的,定量分析的数据规模因成本等因素受限,可能影响统计显著性。
从产品的角度,缺乏与其他关键模型(如OpenAI o1)推理过程的直接比较。
同时由于DeepSeek-R1 的训练数据不透明,限制了对其行为根源的理解。

(文:新智元)