跳至内容
27 岁,没拼爹妈、没靠关系,靠自己搞定了人生第一张和世界首富的合照。
别误会,这可不是偶遇马斯克和黄仁勋,而是借助 GPT-4o,基于一段 Reddit 上爆火的提示词生成的。在这个「万物皆可生成」的时代,合照的门槛早已不是物理距离,而可能是一段能骗过你眼睛的 Prompt。
你或许已经在社交平台见过类似画风:平日里行踪低调的周杰伦,在全国各大地标前拍照打卡;马斯克、黄仁勋、奥特曼甚至爱因斯坦等人,也在国内各地景点「合影留念」。
甚至,你还能看到当下外卖大战打得火热的京东 CEO 刘强东和美团 CEO 王兴,纷纷合体「现身」上海外滩、广州塔等地,握手言和、笑容满面。
当生成式 AI 横扫社交平台,「眼见为实」这句话,恐怕也该加个问号了。
无奖竞猜,下图中,一张照片是我上班途中用 iPhone 7 随手拍摄的,另一张则是由 GPT-4o 根据同一段提示词生成的。请你猜猜,哪一张是 AI 生成的作品?
答案将在评论区揭晓,你猜对了吗?如果没有,也不用介意。如今 AI 图片的逼真程度,确实让人防不胜防,所以也真不怪 OpenAI 嚷嚷着要给 ChatGPT 图片要加水印了。
而这一切的起点,始于一位突发奇想的网友用一段极其「敷衍」的提示词让 GPT-4o 生成图片,结果反而炸出了一组「堪称真实摄影风格教程」的图像。
Prompt:An extremely unremarkable iPhone photo with no clear subject or framing—just a careless snapshot. It includes part of a sidewalk, the corner of a parked car, a hedge in the background or other misc elements. The photo has a touch of motion blur, and mildly overexposed from uneven sunlight. The angle is awkward, the composition nonexistent, and the overall effect is aggressively mediocre—like a photo taken by accident while pulling the phone out of a pocket.
(这是一张极其普通、毫无特色的 iPhone 照片,看不出明确的主题或构图——就像是随手一拍的快照。画面中可能包含一段人行道、一辆停着的车的车角、背景里的绿篱,或其他杂乱的元素。照片有些轻微的运动模糊,阳光不均导致曝光略微过度。拍摄角度显得尴尬,几乎没有构图可言,整体效果平平无奇——就像是不小心从口袋里掏手机时误按快门拍下的一张照片。)
刻意的不完美:模糊、过曝、角度尴尬、构图混乱,反而更贴近真实世界的样子,要是你对象给你拍成这样,免不了一顿挨骂,但让 GPT-4o 生成却是刚刚好。
随着这段提示词开始在 Reddit、X 等平台刷屏,脑洞大开的网友也在此基础上不断加料:比如加入人物、特定景点,自拍角度等等,最终形成一套「真实假照片」的制作公式。
请你画一张极其平凡无奇的 iPhone 自拍照,没有明确的主体或构图感–就像是随手一拍的快照。照片略带运动模糊,灯光不均导致轻微曝光过度。角度尴尬、构图混乱,整体呈现出一种刻意的平庸感-就像是从口袋里拿手机时不小心拍到的一张自拍。主角是「人物」,晚上,旁边是「景点」。
举个例子,下面这张阳光洒进屋里的照片,木地板的细节稍显破绽,但灰尘、绒毛、阳光洒下的斑驳过曝感,都营造出一种真实的自然氛围。
以至于用网友的调侃来说,「这张照片看起来像是我从我奶奶的老相机里翻出来的。」
除了在模拟物体(如风景、静物、街头场景)方面的效果尤为惊艳,比如生成的图像细节丰富、质感自然,足以以假乱真,这类提示词生成人像的水平也不容小觑。
再看这张女生躺在草地上闭目养神的照片,阳光温柔洒在脸上,闭目养神,神态松弛。如果没有前文的铺垫,你很难不相信这是朋友刚在林间草地上随手拍下的一张照片。
甚至在 GPT-4o 的加持下,你只需一句话,就能对图片「后期魔改」。原图上一秒只有一个女人,下一秒就能在她的身旁凭空出现一位穿着印有「我的妻子不知道我在这里」T 恤的丈夫。
模型倾向于生成训练数据中最常见、最「安全」的变体,自然而然就会导致某种程度的视觉同质化。网友发现用这段提示词生成汽车时,不指明品牌的情况下,生成的车几乎都长一个样,一眼看去毫无个性。
生成自拍女性图像时,如果没有设定特定身份、五官、服装,面部五官也常常「撞脸」。
只需这份提示词模板,GPT-4o 也能生成「拍不出来」的故事感?
细看上面这些照片,不难发现它们几乎拥有一种「修不出来」的故事感。而没有参数加持,也不靠后期修图,CCD 相机同样借此翻红。
前不久,「iPhone 5s 是 CCD 平替」的话题登上了热搜,也让这类审美趋势再次走进了大众视野。那么能否用 GPT-4o 生成更具 CCD 风格的照片?我们做了一些尝试,并总结出几条实用的小技巧:
使用名人形象,模型训练数据更丰富,还原度更高,更有真实感。
素人形象的一致性较弱,属于「像又不像」,细看总有点违和。
调整图片过程中,容易出现面部细节或背景元素的变形。
提示词中加入 CCD 相机型号,能增强图像对应的氛围与复古感。
[人物描述],穿着[服装描述],[姿势/动作],[场景位置],[光线描述],[背景元素],使用[CCD 相机型号]拍摄,开启闪光灯,人物[清晰/明亮],背景[昏暗/模糊],颗粒感,[色调描述],[怀旧感/年代感],[风格类型]
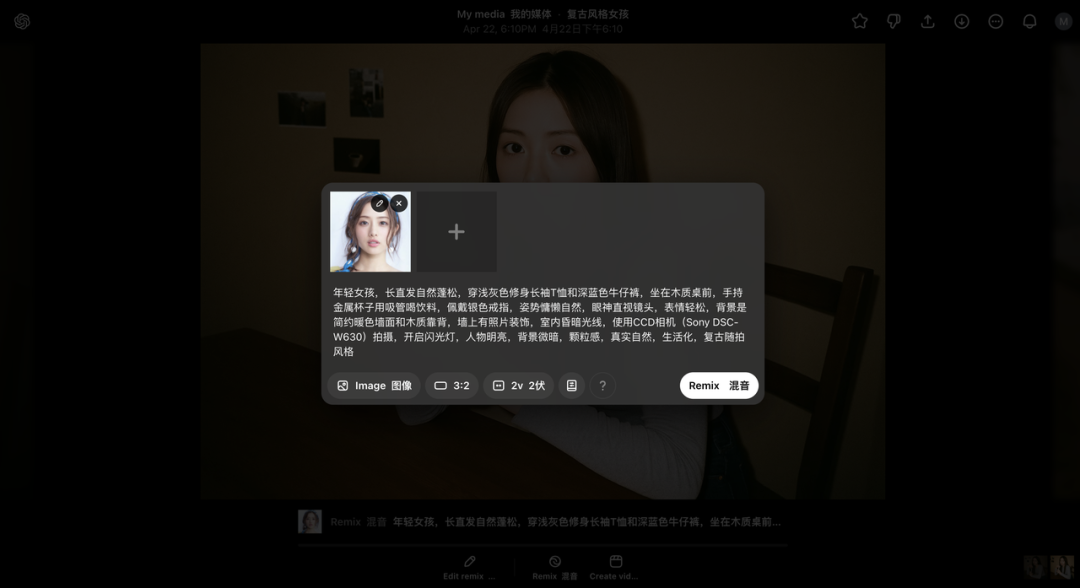
年轻女孩,长直发自然蓬松,穿浅灰色修身长袖T恤和深蓝色牛仔裤,坐在木质桌前,手持金属杯子用吸管喝饮料,佩戴银色戒指,姿势慵懒自然,眼神直视镜头,表情轻松,背景是简约暖色墙面和木质靠背,墙上有照片装饰,室内昏暗光线,使用 CCD 相机(Sony DSC-W630)拍摄,开启闪光灯,人物明亮,背景微暗,颗粒感,真实自然,生活化,复古随拍风格
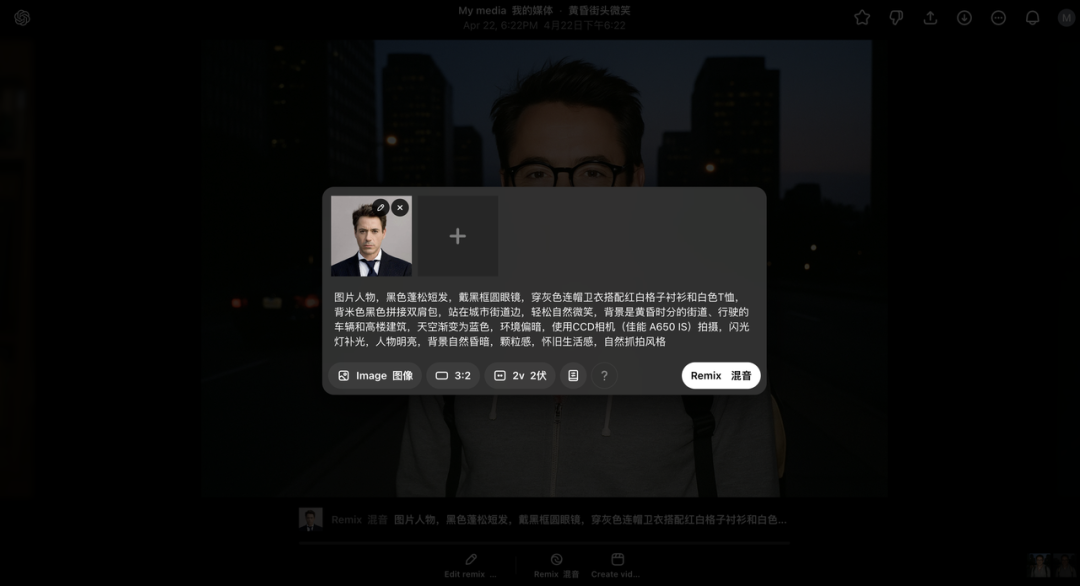
图片人物,黑色蓬松短发,戴黑框圆眼镜,穿灰色连帽卫衣搭配红白格子衬衫和白色T 恤,背米色黑色拼接双肩包,站在城市街道边,轻松自然微笑,背景是黄昏时分的街道、行驶的车辆和高楼建筑,天空渐变为蓝色,环境偏暗,使用 CCD 相机(佳能 A650 IS)拍摄,闪光灯补光,人物明亮,背景自然昏暗,颗粒感,怀旧生活感,自然抓拍风格
图片人物,穿着白色短袖 T 恤和牛仔裤,背着黑色双肩背包,站在城市街道上,身体微微前倾,单手插兜,自然看向镜头,背景是车流和树荫大道,阳光透过树叶洒下,街道干净宽阔,使用佳能 ixus6 相机拍摄,开启闪光灯,人物明亮突出,背景动态模糊,颗粒感,真实自然,阳光少年感,日常街拍风
图片人物,身穿白色 T 恤和牛仔裤,在街头吹泡泡,泡泡在阳光下闪烁出彩虹光,表情专注又自然,街景模糊作为背景,CCD 风格(由 koda z700 拍摄),颗粒感,色调柔和偏暖,自然光
穿着校服的马斯克站在操场边,阳光斜照在脸上,头发随风微微飘起,CCD 风格(由 koda z700 拍摄),色调偏暖,颗粒感,胶片质感,像是 2005 年拍的校园照片
图片人物,身穿宽松毛衣站在岸边,背对镜头望向远方,身后是海上刚升起的太阳,整个画面被金色晨光包裹,CCD 风格(由佳能 A650 IS 拍摄),轻微过曝,高对比光影,复古颗粒感,情绪感强烈
图片人物,黄色连衣裙,白色长袜,草地野餐,阳光明媚,夏日氛围,毛绒玩具熊,森林背景,CCD 风格(由 Sony DSC-W630 拍摄),高曝光,自然光感,清新怀旧,复古颗粒感
年轻男孩,黑色短发,穿着深色毛衣,面朝镜头,站在湖边,夕阳西下,金橘色天空,平静水面和远山背景,温暖色调,使用 koda z700 拍摄,开启闪光灯,人物清晰明亮,背景昏暗,颗粒感,怀旧感,清新少年风,真实自然,随性抓拍
图片人物,背景是海滩和海面,停泊着小船,天空多云,户外露台场景,桌上有玻璃杯,傍晚光线昏暗,使用 CCD 相机(佳能 A650 IS)拍摄,开启闪光灯补光,人物明亮,背景自然,颗粒感,怀旧真实风格
图片人物,黑色短发,穿着深色毛衣,面朝镜头,站在湖边,夕阳西下,金橘色天空,平静水面和远山背景,温暖色调,使用 koda z700 拍摄,开启闪光灯,人物清晰明亮,背景昏暗,颗粒感,怀旧感,清新少年风,真实自然,随性抓拍
图片人物,黑色自然凌乱长发,穿浅灰色宽松T恤和深色短裤,坐在室内地板上,手持一瓶酒,神情放松,微微侧头,眼神自然,背景是堆满玩具、书籍、模型和音响的柜子,室内暖色光,使用富士 F710 拍摄,闪光灯直打,人物明亮清晰,背景微暗,颗粒感,自然色调,怀旧生活感,自然抓拍风格
早在 GPT-4o 用吉卜力风格刷屏那会儿,就有人发现它的另一种能力:生成假发票。
创投人士 Deedy Das 就演示了一套流程:用模型生成账单、发票,再叠加「污渍」「褶皱」等细节,最终生成效果堪比复古做旧工艺。
除了相册的参数可以作为真实图片的佐证,作为厂商的 OpenAI 也会为 GPT-4o 所生成的图片自动添加一种名为 C2PA 的元数据标准,虽然嵌入在图像像素层中,不会被肉眼察觉,但可以通过特定算法检测。
即便图像被截图、压缩或改变尺寸,水印依然可以被追踪识别。
诸如 Google、Adobe 也在积极推广数字水印技术,用于标记和验证 AI 生成内容。其目标是通过统一的水印和元数据标准,帮助用户区分 AI 生成内容与非 AI 生成内容。
或许,在未来,我们更该警惕的不是那些看起来「像 AI」的图片,而是那些看起来过于真实的瞬间。
而 GPT-4o 图片的这种「真实」,其实也源自于人类创作本身的「瑕疵」。
OpenAI 等公司在训练图像生成模型时,所依赖的数据大多采集自社交媒体、云相册或网络公开资源。这些图像原本就是我们日常生活的记录,光线、构图、设备参差不齐,失误和瑕疵也自然少不了。
通过学习这些「不完美」的样本,AI 也就掌握了如何模仿真实世界中常见的摄影瑕疵。比如动态模糊模拟了手抖或物体移动,过曝光则还原了常见的翻车名场面。
OpenAI 官方并没有公开 GPT-4o 生图的具体原理,只是淡淡提了一嘴「不同于基于扩散模型的 DALL・E,4o 图像生成是一个嵌入在 ChatGPT 中的自回归模型。」
相比传统「先模糊再去噪」的扩散模型,自回归模型的学习方式就像是「按顺序拼图」:它需要逐步地预测每一个图像片段,也就是一格像素、一块特征地猜接下来该是什么。
这种逐格构建的方式,使它非常依赖于局部上下文之间的合理性。
换句话说,如果模型看到「模糊+角度别 + 光线过曝」,它会自然联想到这可能是一次手抖的抓拍。于是它在接下来的区域里,也会接着模拟出相应的细节。
不是因为它「想画得逼真」,而是因为它学会了这类图通常就长这样。
我们要求 AI 模拟这些「缺陷」时,实际上也是在激活模型最熟悉、数据量最丰富的模式,最终,这种「真实感」就从语言层的描述,一笔一划、逐步落实到像素层的表达。
当然,具体实现的底层细节,还有待 OpenAI 进一步公开。
日本机器人专家森政弘(Masahiro Mori)在 1970 年提出了著名的「恐怖谷」理论:
当人造物(如机器人或 AI 图像)与人类的相似度接近某个临界点时,那些微妙的「不协调」会引发观者的生理不适与心理排斥感——它看起来「差不多像人」,却不够自然,从而让人觉得怪异。
而一旦这种相似度跨越「谷底」,达到几乎无法与真人区分的地步,观者的好感才会再次回升。
AI 图像的典型「破绽」(如奇怪的六根手指、不合逻辑的光影、重复的纹理)往往都是 AI 在生成图像时经常露馅的地方,一旦被看出来,就会让人瞬间出戏。
而反其道而行之,适当引入一些「人类特有的笨拙」,反而避开了早期生成图像常有的过于完美的违和感,也让 AI 图片显得更真实、更亲切。
或许,这也是 GPT-4o 在图像生成方面的一个转折点:它不再执着于技术意义上的「完美」,而是试图回到生活本真的模样,学会用一点点「出戏」,换来一种「入戏」的真实。
而技术越发达,我们也似乎越怀念那些带着瑕疵、却更真实的瞬间。
习惯了手机/相机拍出高清大片,像广告、像模板,但在影像无限趋于清晰的同时,是否那些不那么清楚、不那么完美的瞬间,才更接近生活本来的模样?
✉️ 邮件标题「姓名+岗位名称」(请随简历附上项目/作品或相关链接)
(文:APPSO)