
OctGPT 团队 投稿
量子位 | 公众号 QbitAI
近年来,智能三维形状生成(3D AIGC)技术迅速崛起,正成为推动数字内容创作革新的关键力量,特别是在游戏、影视、虚拟现实和工业设计等领域表现出巨大的应用潜力。
随着技术的不断进步,三维内容的生成质量与效率持续提升,成为业界与学界广泛关注的焦点。
最近,北京大学陈宝权教授带领团队在三维形状生成和三维数据对齐方面取得新的突破。
在三维数据生成方面,团队提出了3D自回归模型新范式,有望打破3D扩散模型在三维生成方面的垄断地位。
该论文已被SIGGRAPH 2025接收,合作者为王鹏帅助理教授,以及博士生魏斯桐和本科生王瑞环、周传智。
在三维数据对齐方面,团队设计了一种仅需单个先验即可实现同类物体对齐的框架,并构建了当前类别覆盖最广的规范化3D数据集,为三维形状生成提供了数据基础。
该论文已被CVPR 2025接收,合作者为陈文拯助理教授、王玉洁博士、高庆哲博士和秦学英教授,以及博士生金立、戴启宇。
SIGGRAPH 2025:OctGPT:3D自回归模型新范式

一、AIGC:从图像生成到3D生成
近年来,基于自回归范式的GPT模型在语言、图像和视频生成领域取得了一系列突破。
例如,最新的GPT-4o凭借其原生多模态架构,在图像生成方面掀起了轰动:它不仅延续了前代卓越的语言理解能力,还通过跨模态协同,轻松产出高质量、多风格的视觉内容。
然而,现有的自回归模型尚不能很好地完成高质量的三维生成任务,这一技术缺口恰恰对应着虚拟现实、电影工业及游戏开发等场景中快速增长的3D内容需求。
随着生成式AI技术的持续演进,如何将多模态理解能力延伸至三维空间,已成为推动下一代AI生成系统发展的关键命题。

△OctGPT能够实现无条件、类别、文本和图片条件的高质量三维形状生成和场景级别生成
二、3D自回归生成模型的挑战
当前主流的三维生成技术虽已取得显著突破,但高度依赖扩散模型的生成范式仍存在显著局限。
尽管扩散模型在连续空间建模方面表现优异,其与GPT类离散序列生成模型在架构设计上的本质差异,导致二者难以实现技术融合。
近年来,学术界虽已涌现出多项基于GPT的三维生成成果,但这一领域仍面临诸多挑战。
首先,GPT的预测机制依赖于序列建模,而现有的三维数据序列化方案往往忽略物体的层次结构与局部关联性,导致模型收敛缓慢、生成质量受限。
针对这一问题,我们提出了一种全新的序列化方法,显著提升了生成效果。
此外,以往方法的序列长度通常只有约1K,难以捕捉复杂的局部细节。
我们将序列长度扩展近50倍,使模型能够精准地建模大尺度、高分辨率的三维形状。
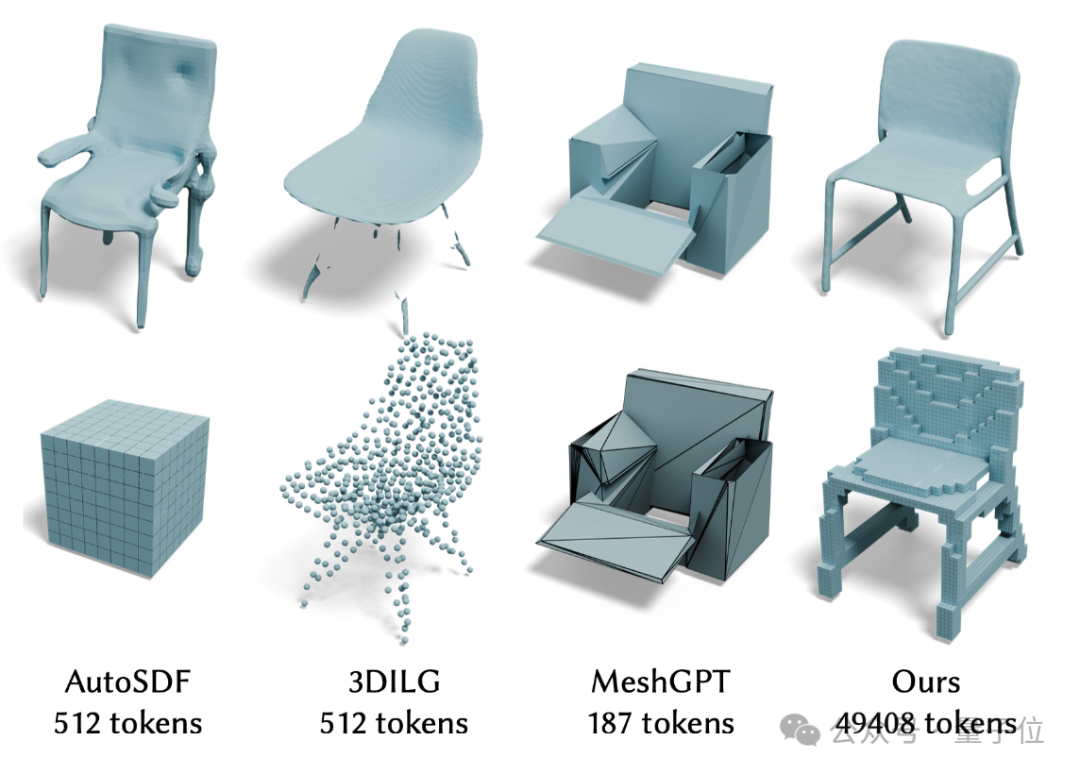
△现有的3D自回归生成模型受限于有限的序列长度,细节质量不足
三、新解决方案:OctGPT
OctGPT探索了基于八叉树Octree和GPT架构的三维生成路径。
用户可以通过多种条件进行控制,比如文本、图像、草图等等,驱动模型进行高质量的三维场景和物体的生成。
这一成果不仅有望打破扩散模型在三维生成领域的技术垄断,更开辟了多模态原生模型向三维空间拓展的新范式。
OctGPT使用一种基于八叉树的多尺度三维序列化形状表达。
八叉树的递归分裂机制自然地表达了多尺度层次特征,其Z型曲线排序策略有效保留空间局部性,为GPT的自回归预测提供理想的序列化基础。

△OctGPT的模型框架
四、OctGPT的核心技术架构
OctGPT的整体框架包括一个基于八叉树的多尺度序列化表达和基于窗口注意力机制的高效自回归模型。
1)八叉树多尺度序列化表达

△八叉树结构和Z字形序列
首先,根据输入的三维形状构建八叉树。八叉树的节点状态被编码为0/1信号:0代表空节点,1代表细分节点,如上图(a)的浅色和深色节点所示。
然后按照Z字形进行多尺度序列化,如上图(b)和(c)Z字形序列所示。我们将不同层次的序列结构由浅到深拼接成多尺度的0/1序列。
随后,使用了基于八叉树的VQVAE,用于将八叉树表达转为完整、光滑的三维模型。
最后,GPT则是逐步生成多尺度的0/1序列。这一类似于二分查找的方式逐层的推理空间结构,极大地简化了建模目标,加速了收敛。
2)多尺度自回归模型

△多尺度自回归模型
为了表达复杂的三维形状,OctGPT将序列长度拓展至50k的量级。为了加速训练,模型采用了基于八叉树的Transformer(OctFormer,SIGGRAPH 2023),并通过交替使用膨胀注意力(如上图b)与移位窗口注意力模块(如上图c),实现跨窗口的Token交互,并将训练速度加速13倍。
OctGPT设计了尺度敏感的Teacher Forcing Mask(如上图a),在序列生成过程中,按深度层级从浅至深顺序预测,同一八叉树层内允许Token按照随机顺序并行生成,同时确保深层Token的预测能够得到已生成的浅层Token信息。
在推理时,OctGPT采用了多个token并行预测的策略,将推理速度加速69倍。基于上述创新,OctGPT能够使用4个4090 GPU在三天内完成训练。
五、结果展示
此处展示了OctGPT在ShapeNet和Objverse上的生成结果。OctGPT能够生成高质量的三维模型,展现出强大的生成能力。

△Objaverse上文本条件生成结果

△ShapeNet上无条件生成结果

△Objaverse上无条件生成结果

△在ShapeNet上与现有SOTA方法的定性对比
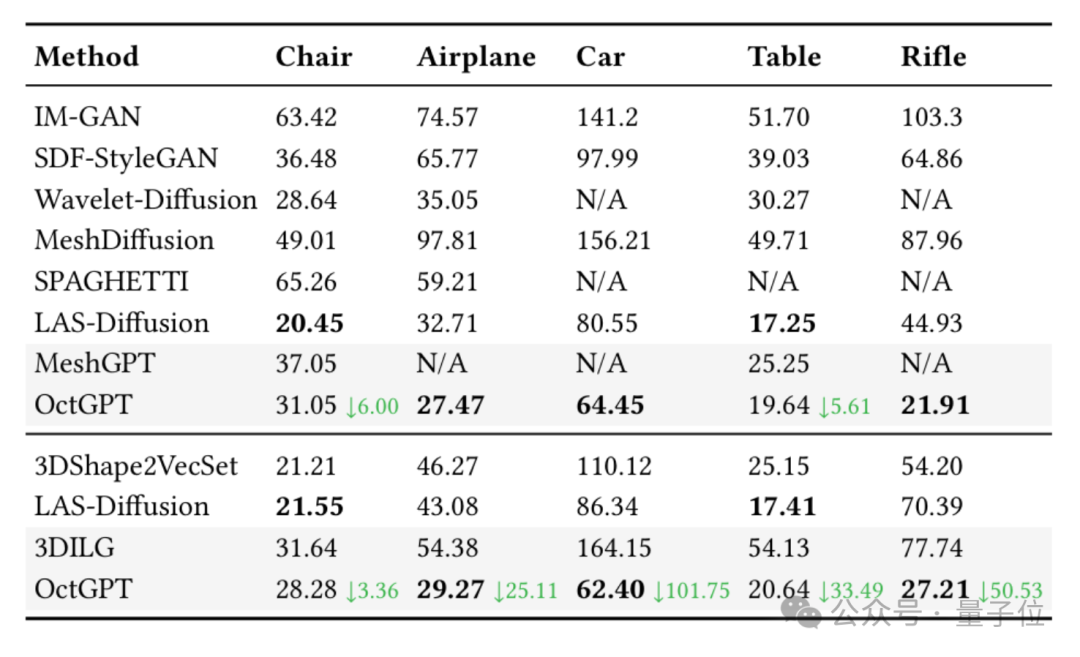
△在ShapeNet上与现有SOTA方法的定量对比
六、总结与展望
OctGPT探索了基于八叉树结构的GPT模型在三维数据生成任务中的应用潜力。
具体创新体现在以下三个方面:其一,通过八叉树结构对稀疏三维数据进行编码,有效提升了计算效率;其二,基于八叉树构建了具有层次性和局部性的多尺度0/1序列,确保序列化过程中空间特征的完整保留;其三,采用Transformer架构直接进行序列化预测,实现了对三维空间特性的端到端建模。
尽管三维数据的稀疏性、层次性与序列性看似相互独立甚至存在矛盾,但本研究成功证明在八叉树神经网络框架下,三者能够有机统一。
这一突破性成果不仅有望打破扩散模型在三维生成任务中的垄断地位,更为原生多模态三维建模技术开辟了创新路径。
论文地址:
https://arxiv.org/abs/2504.09975
项目主页:
https://github.com/octree-nn/octgpt
CVPR 2025 Highlight:大规模三维数据对齐
CVPR 2025 Highlight论文: 基于几何和语义一致性的One-shot 3D物体规范化,为三维生成技术和具身智能的快速发展提供了坚实基础。
该工作由北京大学陈宝权研究团队主导,山东大学合作完成。

一、3D物体对齐及其重要性
在三维世界里,“对齐”一个物体,意味着将它摆放到一个标准的姿态——不歪、不倒、朝向统一。
就像我们看到一个歪着的杯子,脑海中会自动将它“扶正”来理解它此时的朝向、把手、底部位置。
这样的对齐操作看似简单,却是让AI真正“看懂”3D物体的关键一步。
随着具身智能和3D生成技术的快速发展,AI不仅要“看见”物体,还要“理解”它们的位置、朝向和语义。
比如,下图中的机械臂之所以能成功倒出一杯咖啡,正是因为它准确理解了杯子的朝向和语义功能部位。
另一方面,在3D内容生成领域,研究也表明:如果训练时使用了规范化的3D数据,可以显著提高生成物体的一致性和质量。
从机器人操作到三维生成,物体对齐都在背后发挥着基础而关键的作用。
然而,如何实现任意类别、任意初始位姿3D物体的高效对齐,仍然十分具有挑战性。

△3D对齐数据在具身智能和3D生成的作用,素材来自Youtube
二、3D物体对齐的挑战
在现实世界中,要让智能体真正理解和操作三维物体,一个带有朝向、位置和尺寸标注的规范3D数据集至关重要。
它不仅让模型能统一学习标准姿态,还能支持类别识别、语义分析等下游任务。
然而,获取这样的数据极具挑战:
1)人工标注严重依赖经验,流程繁琐且易出错。在使用计算机辅助3D标注时,通常需通过2D界面对3D物体手动调整,交互效率依然不高;
2)基于学习的自动化对齐方法本身也依赖充足的先验样本才能训练,而现实中的物体分布呈严重长尾——例如在Objaverse-LVIS中,超93%的类别样本不足100个,远远满足不了现有方法所需的充足先验样本。
因此,无论是人工流程,还是基于学习的自动化方法,目前都难以支撑对大规模、任意类别3D物体进行高效高质量规范化。这也让如何高效对齐三维物体成为当前研究的核心挑战之一。

△长尾分布问题:对Objaverse-LVIS类别物体数量统计
三、提出的解决方法
为突破上述3D物体规范化中“标注难、样本少”的双重困境,我们提出了一种全新的One-shot物体对齐方法:只需一个规范化物体作为先验,结合2D基础模型的语义能力,即可自动对任意姿态下的同类3D物体进行高质量规范化。
相比以往依赖大量训练数据或手工操作的方案,我们的方法无需繁琐流程,也不怕长尾类别,在样本稀缺的场景下表现尤为出色。
实验结果显示,我们的方法显著提升了3D物体规划化的精度和鲁棒性。进一步地,我们将该方法应用于Objaverse-LVIS数据集,并通过渲染进行清洗和挑选,构建了目前已知覆盖类别最广的规范化3D物体数据集——Canonical Objaverse Dataset(COD),涵盖1,054个类别、32,000个对齐物体,现已开放下载。
同时,我们会持续扩大规范数据集的规模。

△现有方法依赖于大量的先验条件(如多个已规范化模型),我们提出的one-shot方法仅需一个先验模型即可实现有效的类别级规范化(左图)。我们构建了规范化的Objaverse数据集(右图),该数据集在现有的规范化三维数据集中涵盖了最多的类别。

△规范化的3D物体数据,来自COD数据集。
四、 方法简介
如图所示,我们希望以一个同类的物体作为先验模型,其他物体作为测试物体和先验模型进行对齐。
算法的核心思想是,结合2D基础模型提供的语义信息和3D物体的几何信息进行规范化。
整个框架由三个主要阶段组成:zero-shot物体语义对应关系建立(左图)、规范化位姿假设生成(中图)以及最终标准位姿选择(右图)。

△算法框架
在算法框架设计时,我们面临两个主要难点:
1)2D基础模型在处理任意姿态下的物体时易出现检测错误,导致3D语义信息获取不稳定;
2)同类物体间存在显著几何差异,仅依赖语义或几何信息进行对齐均存在局限,因此亟需设计一种能够有效联合利用稀疏语义与几何信息的对齐机制。
为此,我们提出:
1)基于支撑面的初始化策略:利用算法自动检测物体的多个支撑面,并以其在水平面上稳定静止的状态作为初始化位姿,显著提高了语义分割模块的的稳定性与准确性。
2)语义-几何联合能量函数:我们设计了结合语义置信度与几何一致性的能量函数,在对齐过程中实现了语义主导大致朝向、几何引导细节对齐的协同优化机制,从而更有效地完成物体规范化。
最终,在Objaverse和ShapeNet等数据集上的实验验证了我们方法在对齐精度与鲁棒性方面的显著优势,较现有主流方法表现更优,并展现出良好的泛化能力。

△3D物体规范化过程,来自COD数据集。
五、总结及展望
我们提出了一种新颖的one-shot三维物体规范化框架,只需一个先验模型,即可完成对同类别中其他物体的规范化对齐。
通过引入大型语言模型(LLMs)与视觉-语言模型(VLMs),结合提出的支撑面的位姿采样策略,我们实现了对物体的zero-shot语义感知,并通过将语义引导的粗对齐与几何驱动的精细对齐相结合,实现了3D物体的自动化高效对齐。
在多个模拟与真实数据集上的实验表明,该方法不仅精度优于现有方法,还能有效处理长尾类别,具备强大的泛化能力。
基于这一方法,我们进一步构建了COD数据集(Canonical Objaverse Dataset),涵盖1054个类别、超过3万个规范化物体,展现了我们框架在大规模3D数据集构建中的可扩展性。
为满足不同任务对3D数据的多样化需求,无论是3D生成任务对高质量网格和材质的要求,还是艺术创作类应用对平整面片和可拆解部件的偏好,我们将持续扩展标注数据规模,丰富标注维度,并欢迎更多研究者加入,共同打造更丰富、更高质量、更贴近社区实际需求的三维物体数据集。
项目主页:
https://jinli998.github.io/One-shot_3D_Object_Canonicalization/
规范数据集链接:
https://github.com/JinLi998/CanonObjaverseDataset
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
学术投稿请于工作日发邮件到:
ai@qbitai.com
标题注明【投稿】,告诉我们:
你是谁,从哪来,投稿内容
附上论文/项目主页链接,以及联系方式哦
我们会(尽量)及时回复你

🌟 点亮星标 🌟
(文:量子位)