

极市导读
同济大学提出FaceShot,打破了传统肖像动画的局限,让表情包、玩具等非人类角色也能“开口说话”,通过语义引导关键点匹配和坐标系建模动作变换,实现了高精度的动作迁移和稳定的身份保持,为动画生成领域带来了新的突破。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

“我希望我的玩具朋友能够陪着我,跟我聊天” ——这个童年愿望,FaceShot帮你实现了。本篇分享同济大学的最新研究FaceShot: Bring Any Character into Life,一举打破肖像动画模型“驱动真人”的局限,不论是童年想象中的小熊、会眨眼的卡通猫,还是收藏夹里的表情包,现在都能从想象或者回忆中走进你的日常生活!!!

论文链接:https://arxiv.org/pdf/2503.00740
仓库地址:https://github.com/open-mmlab/FaceShot
现有方法的困境
当前的肖像动画方法大致由面部关键点序列控制驱动。 这类方法已经表现出了__良好的动作可控性与面部保真能力__,特别是在人脸驱动任务中能够生成自然、稳定的动画效果,然而由于其核心依赖的人脸关键点检测以及动作序列生成模块大多是在真实高质量面部数据集上进行监督训练,在处理非人类角色(如表情包、玩具、卡通角色)时,往往无法准确识别关键点分布和迁移面部动作,导致动画生成阶段出现结构错位、嘴型崩塌等现象。

无需训练,FaceShot潇洒破局
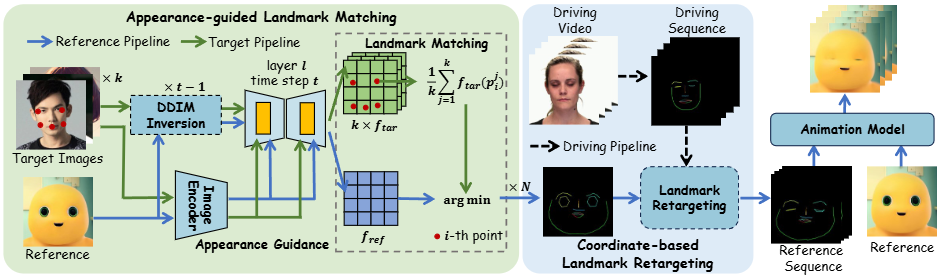
语义引导关键点匹配
DIFT等方法已经揭示了不同图像的语义相近区域的预训练扩散模型特征是相似的,可以直接进行关键点匹配。

然而人脸和非人类角色之间存在较大的域差异,常常会造成错误匹配,如上图所示。
为了拉近不同域在特征空间的差异,FaceShot结合 IP-Adapter,将参考图像作为 外观引导注入扩散过程。另外FaceShot 还构建了包含眼睛、嘴巴、眉毛等五个部分的外观图库,自动选取相近域作为辅助目标,进一步缓解非人类角色与人类语义空间之间的域间差异。实现对非人类角色的面部关键点的精准定位。
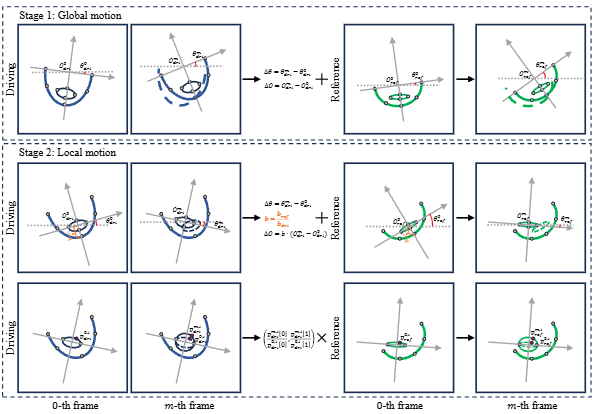
坐标系建模动作变换
为了更精准地捕捉驱动视频中的面部动作,FaceShot 构建了全局与局部坐标系,用于显式建模并迁移整体与局部表情变化。具体而言,FaceShot利用参考图中面部轮廓两端点定义全局坐标系,通过原点位置与坐标轴角度的变化建模头部的整体位移与旋转;同时,在眼、眉、嘴、鼻等局部区域分别建立子坐标系,通过点在各自坐标系中的相对变化,刻画细节动作的动态变形。
效果惊艳,实力验证
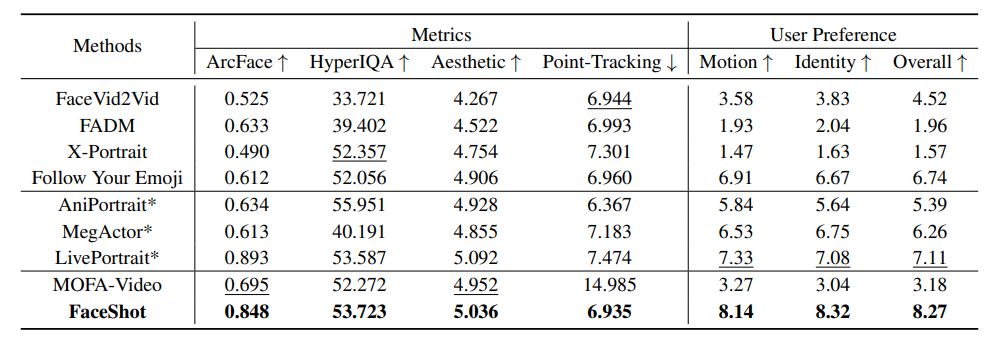
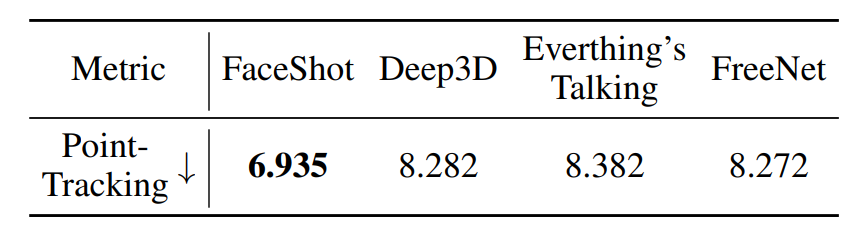
实验结果显示,FaceShot在非人类角色上表现出色。相比现有方法,FaceShot 在身份保持(ArcFace)、图像质量(HyperIQA)和动作还原(Point Tracking)等多个指标上均取得领先,尤其在结构不规则、风格差异大的角色(如玩偶、卡通形象、动物)上表现更为稳定。现有方法常常因关键点检测不准或驱动迁移失真而导致动画崩坏、嘴型错位等问题,而 FaceShot 利用语义引导的关键点匹配与坐标建模动作迁移,显著提升了角色动作的还原度和连贯性。

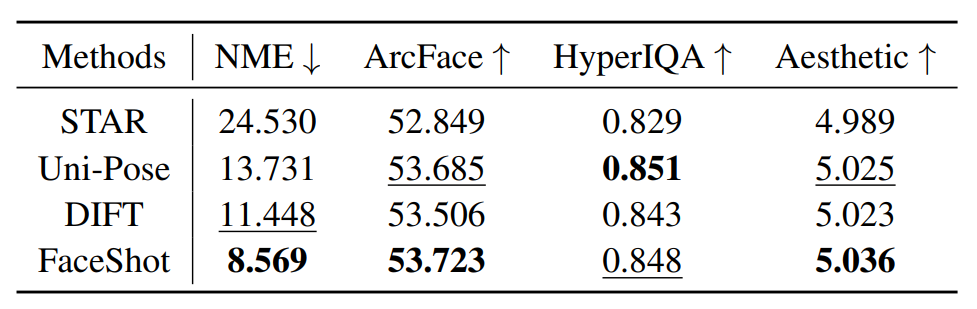
此外,在关键点匹配和面部动作迁移方面FaceShot也远强于现有的方法。例如在关键点匹配中,FaceShot 取得了最低的归一化平均误差(NME),在眼睛和嘴巴等关键区域表现尤为精准。在动作迁移方面,FaceShot 同样优于 Deep3D、Everything’s Talking 和 FreeNet,能够更稳定地还原嘴部开合、眼动等细微变化,并在 Point-Tracking 指标上取得最优成绩。


未来潜力
除了作为独立的肖像动画生成框架,FaceShot 还展现出出色的模块化扩展能力。在插件化应用方面,FaceShot 可作为关键点序列预测模块集成到现有的关键点驱动方法中(如 MOFA-Video 和 AniPortrait),显著提升其在非人类角色上的动画稳定性与结构一致性。

此外,FaceShot 还支持从非人类驱动视频中提取动作信号,并将其迁移到任意参考角色,实现跨类别、跨风格的开放域角色动画。这一能力打破了传统肖像动画对人类驱动数据的依赖,展示了FaceShot向通用、开放场景扩展的广阔潜力。


(文:极市干货)