
图像、视频要想做到能整体理解,又能局部解析是比较难的事情。近日,英伟达最新发布的 Describe Anything 3B 模型,不仅填补了图像与视频局部描述的技术空白,更标志着多模态AI从全局粗放迈向区域精准的范式转变。
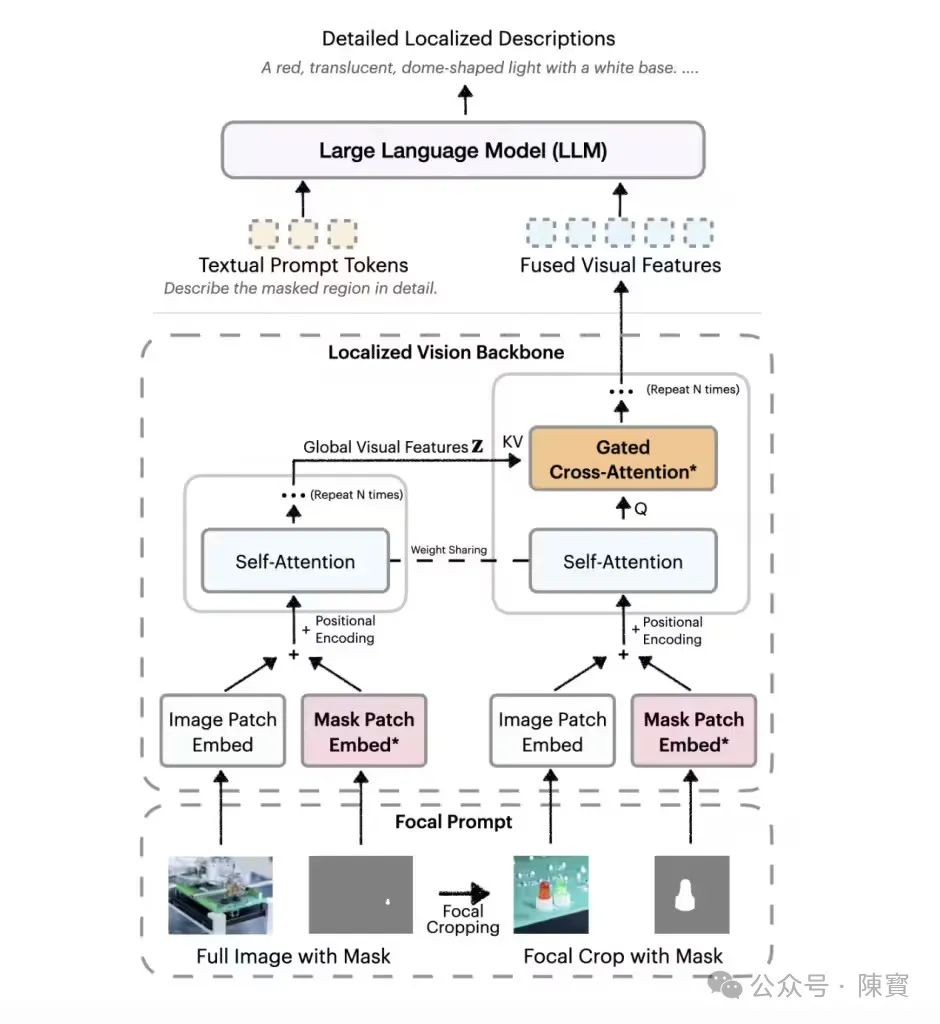
传统视觉语言模型的局限,在于它的广角镜头式的整体描述。而 DAM-3B 的核心价值,在于将AI的视觉解析能力升级为显微镜模式。
它的两大创新架构,焦点提示与局部视觉骨干网络,构成了这一跃迁的技术基石。
传统方法在处理局部区域时,往往通过简单裁剪放大细节,但会导致背景信息丢失。DAM-3B 的焦点提示技术采用双流输入,全图低分辨率信息与高分辨率局部裁剪通过动态权重分配,实现“既见树木又见森林”。
局部视觉骨干网络引入门控机制,通过可学习的权重筛选全局与局部特征的相关性。
例如,在自动驾驶场景中,当车辆检测到行人手势时,门控机制会强化手部动作与交通信号灯的关联,抑制无关背景的干扰。
选择性注意力的能力,使模型在复杂场景中保持逻辑连贯性。
DAM-3B-Video 通过逐帧掩码编码与时间序列建模,解决了动态遮挡与运动模糊的挑战。
体育赛事分析过程中,即使运动员被其他选手短暂遮挡,模型仍能通过轨迹预测生成连续动作描述。其中时空耦合能力,远超传统逐帧分析的拼凑式输出。
⋯ ⋯
DAM-3B 另一个颠覆性创新在于它的数据生成方法DLC-SDP,通过半监督学习构建了 150 万局部描述样本,打破了传统依赖人工标注的瓶颈。
利用现成的图像分割数据集,将物体轮廓掩码与类别标签转化为自然语言描述。例如,将“狗”的掩码区域自动扩展为“一只金毛犬在草地上奔跑,左前腿抬起”。
通过对比学习,从无标注图片中提取潜在区域的文本关联。能够做到从社交媒体图片的标题“落日与帆船”中,反向推导出“橙色太阳位于海平面中央,白色帆船在右下侧”的区域描述。
初始模型生成的描述经过质量筛选后,又能反哺训练数据,形成数据和模型协同进化。
这种策略显著提升了长尾场景的覆盖能力,如罕见动物或工业零件的精准描述。
⋯ ⋯
传统视障辅助工具仅能提供整体场景描述,而 DAM-3B 可支持用户通过触控屏指定区域,实时生成细节描述。
更进一步,结合 AR 眼镜,模型能实现动态环境导航。
半导体制造中,DAM-3B 模型能够针对显微镜图像中的特定电路区域,生成缺陷分析报告,相比传统 OCR 结合规则引擎方案,效率提升 40% 以上。
视频创作者能够通过涂鸦标记关键对象,自动生成分镜头脚本。如“特写镜头:女主角的戒指在 00:12 – 00:15 从左手滑落,掉入沙发缝隙”。
广告行业中,模型甚至能根据品牌方指定的产品区域,生成多版本营销文案。
⋯ ⋯
我认为,DAM-3B 的发布不仅是技术突破,更是英伟达巩固AI领导地位的战略举措。
(一)硬件、软件协同壁垒
该模型针对 GPU 架构优化,推理速度比同类 CPU 方案快 5 倍。这促使更多开发者绑定英伟达生态,形成从芯片到框架再到应用的全栈优势。
(二)开源策略的生态收割
通过 Hugging Face 开源模型权重,英伟达既吸引社区贡献,又收集真实场景数据反哺迭代。使用“开放代码、掌控生态”的模式,与 Meta 的 Llama 系列形成差异化竞争。
(三)评估标准的话语权争夺
其中推出的 DLC-Bench 基准以属性级正确性为评估核心,间接定义了多模态模型的优劣标准。
未来产业界广泛采用该基准之后,英伟达将掌握技术路线的定义权。
⋯ ⋯
AI模型虽然能够描述微笑,但无法理解微笑背后的情绪。认知层差距的问题,在医疗、法律等高风险场景一定程度上会引发误判。
风险意识需要前置,这是很关键的。不然,区域描述能力也会被滥用于敏感信息提取,这就需建立区域标记的权限控制机制了。
尽管模型参数仅 3B,但视频处理的实时性要求仍需依赖高端 GPU,在边缘设备上的部署效率仍有待优化。
英伟达公司 DAM-3B 的诞生揭示了一个更深层的趋势:AI 正从“宏观模仿人类”转向“微观超越人类”。
当机器能观察到你未曾注意的衣领褶皱、电路蚀刻或飞鸟振翅的帧间变化时,人类与AI的关系将不再是工具依赖,而是认知维度的互补。
(文:陳寳)