

在理解人类行为的视频研究中,第一人称视觉(Egocentric Vision)正成为视频理解、具身智能与虚拟现实等前沿领域的重要突破口。它要求模型不仅能识别物体,还要理解人类如何操作这些物体、为何操作,并预测接下来的动作。
然而,现有数据集大多来自受控环境,缺乏支持真实生活场景中连续、多模态感知的能力。为此,我们提出了 HD-EPIC 数据集,在真实厨房中采集 41 小时第一人称视频,并精细标注菜谱、营养、3D 感知、物体运动与视线轨迹,推动多模态AI在具身感知与交互中的深入发展。

论文标题:
HD-EPIC: A Highly-Detailed Egocentric Video Dataset
论文链接:
https://arxiv.org/abs/2502.04144
项目地址:
https://hd-epic.github.io

引言
人类可以毫不费力地理解视频中的各种细节,从短暂的细粒度动作到长达数小时的整体活动。然而,这对于目前的基础模型和专门模型而言却极具挑战性。特别是第一人称视角的视频,由于相机运动剧烈、动作粒度细、物体经常在操控过程中被遮挡或消失于画面之外,这些问题增加了理解视频的难度。
理解此类视频需要分解头部运动、手部交互及对动态场景的整体理解等综合信号。因此,第一人称视角视频为视频感知模型的全面评估提供了理想的测试平台。
近期第一人称视觉领域涌现了大量的数据集。虽然规模庞大,但这些数据集的标注通常较为稀疏,尤其是那些需要长视频多个部分关联或 3D 定位的任务。
相比之下,标注丰富的数据集通常是合成的或是在受控环境中收集的,这限制了其真实感。我们通过构建一个标注最为密集的非脚本化视频数据集,填补了这一空白,非常适合用于视频和视频-语言模型(Video-language models)的综合验证。

介绍
我们采集了新的视频数据,以捕捉额外的元数据,并确保这些视频此前未被用来训练现有模型。类似于 EPIC-Kitchens 数据集,参与者连续三天采集了所有厨房活动,我们因此命名数据集为 Highly-Detailed EPIC(HD-EPIC)。

上图展示了多层次标注的概览:
-
菜谱步骤被标注了时间信息,并链接至所有准备动作的标注。
-
食材在视频中称重并标注营养信息,记录随食材加入的菜品营养。
-
每个动作都有密集的描述,详细说明动作的内容、方法与原因。
-
为每个厨房建立一个标注了固定家具的数字孪生(digital twin),这些家具与具体动作及物品的取放相关联。
-
所有被移动的物体均被追踪,并且手动标记的掩码映射到 3D 边界框(bounding box)。
-
视线(Gaze)轨迹与物体运动关联,标注取放物体之前的注视行为。
通过这些密集标注,我们设计了包含 26K 个有挑战性的视觉问答(VQA)基准。我们刻意未使用大语言模型生成负样本,而是采用相似标注,以保证问题的真实性。
我们还提出了一些新型问题,如菜谱营养变化、跨视频菜谱、物体多步运动路径、固定家具互动计数、动作的原因与方式以及视线预测。此外,我们报告了动作识别、声音识别以及长期视频物体分割的结果。

数据采集
3.1 招募与设备
每位参与者需长期投入(约 50 小时),包括数据录制和提供详细的解说、食谱和营养信息。数据采集使用 Project Aria 智能眼镜——这是一个多传感器平台,配备有 3 个前置摄像头(1 个 RGB 摄像头和 2 个 SLAM 摄像头)、7 个麦克风,以及用于视线估计的内置摄像头。
我们以 30 FPS 录制 1408×1408 分辨率的 RGB 视频,60 FPS 记录眼球跟踪信息,以及 30 FPS 记录 SLAM 数据。此外,我们还提供了包括称重营养成分的秤在内的多个辅助设备。
3.2 指导说明与数据采集
参与者连续至少三天记录所有日常厨房活动。共计 9 名参与者,每次进入厨房时都佩戴智能眼镜,并启动录制,离开厨房时停止录制。每位参与者的录制时长介于 3.5 至 7.2 小时之间(平均 4.6 小时)。总体上,我们共收集了 156 个视频,平均长度为 15.9 分钟(标准差 14.5 分钟),累计 41.3 小时(共 446 万帧)。

采集完成后,参与者提供了他们制作的菜谱,并注明来源(如网站)及任何修改内容。共收集 了69 个涵盖多种菜系的菜谱,每个菜谱平均包含 6.6 个步骤、8.1 种食材,从准备到完成平均耗时 4 小时 48 分钟,涉及 2.1 个视频。最长的菜谱耗时 2 天 6 小时。
为了追踪菜谱的营养信息,参与者使用 MyFitnessPal 应用手动记录并称重食材,获得了详细的营养数据。
这一环节为数据集增加了额外的维度。共计使用了 558 种食材,包括高蛋白质(如金枪鱼和腰豆)、碳水化合物(如椰枣和面粉)以及脂肪类食材(如酸奶油和松子)。参与者制作了高热量菜品(如懒人蛋糕,4800 卡路里)和低热量菜品(如脆黄瓜沙拉,274 卡路里)。
3.3 解说
我们参考了之前的数据集做法,要求参与者观看录制的视频并使用解说工具进行解说。此外,我们还要求参与者描述动作的具体内容、方法以及原因。这使得我们的解说内容比之前的数据集更加密集和详细。
3.4 后处理——多视频 SLAM 与视线数据
我们使用 Aria MPS 处理视频,获取每个厨房多日的统一点云、1000Hz 的六自由度相机轨迹以及眼球视线方向。我们还对 VRS 文件进行了后处理,转换为 mp4 格式,并移除了视线摄像头输入以保护隐私。

标注流程
为了实现 HD-EPIC 在标注精细度方面与其他视频理解数据集的差异,我们收集了丰富且多层次的标注信息,以下详细介绍了我们的标注流程。
4.1 菜谱步骤与食材标注
我们的视频不同于网络上常见的短视频菜谱,这些短视频通常仅保留关键步骤,并经常进行剪辑或加速处理。HD-EPIC 的视频包含了更全面的与菜谱相关的活动,如取材或预备食材。为了全面标注这些视频,我们引入了“准备-步骤”对(prep and step pairs)。
某个步骤对应的“准备动作”定义为执行该步骤前所需进行的所有必要动作。例如,“切西红柿”这个步骤的准备动作包括从储存空间取出西红柿、清洗以及取刀和砧板。然而,如果步骤是“加入已切碎的洋葱并搅拌”,那么切洋葱就是该步骤的准备动作的一部分, 如下图所示。
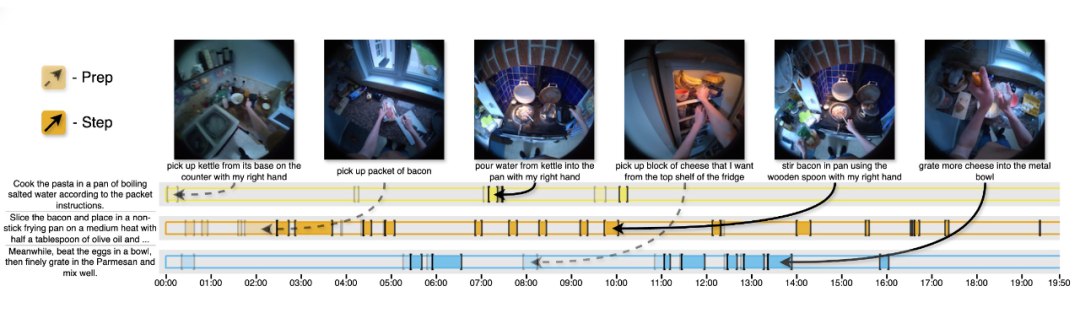
几乎所有步骤(93.1%)都有对应的准备动作标注。通常准备动作比步骤本身更短,平均准备动作时长为 54. 5秒(标准差 95.3 秒),步骤平均时长为 78.2 秒(标准差 100.7 秒)。
此外,我们还标注了食材的称重和加入时的时间片段,以便在食材加入过程中追踪整个菜品的营养变化。总共标注了 283 个称重片段(平均 18.9 秒)和 501 个加入食材的片段(平均 31.6 秒),不包括香料。

4.2 细粒度动作标注
4.2.1 转录
我们自动转录参与者提供的所有音频解说,并进行人工校验与修正,以获得详细的动作描述。
4.2.2 动作边界
对所有解说内容,我们标注了精确的开始和结束时间。共获得了 59,454 个动作片段,平均时长为 2.0 秒(标准差 3.4 秒)。
4.2.3 解析
我们从开放词汇的解说中解析出动词、名词以及涉及的手,以用于闭合词汇(closed vocabulary)任务,如动作识别。我们还从 16,004 个和 11,540 个解说中分别提取了动作的方式(how)和原因(why)描述。
4.2.4 聚类
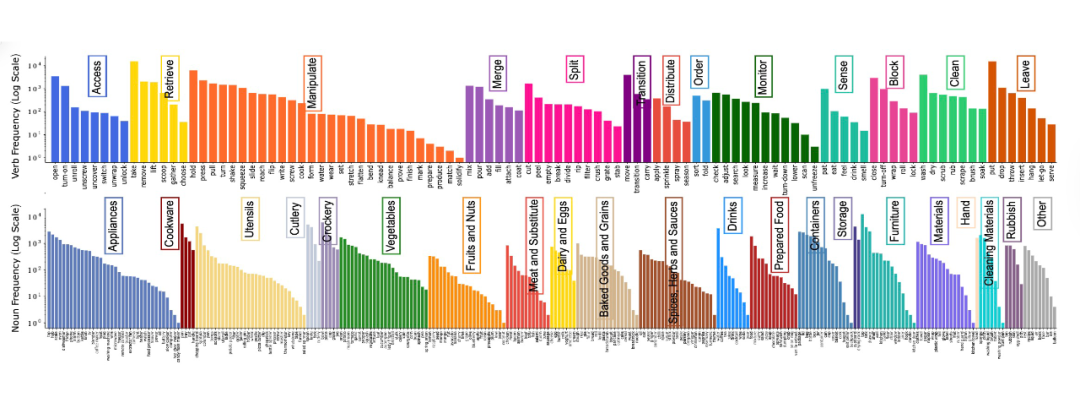
如下图所示,动作和物体的类别在所有视频中的分布呈现出长尾特性,与之前的数据集类似,我们的动作和物体类别极为多样化。
4.2.5 声音标注
我们收集了音频事件的开始-结束时间及类别名称的标注(如“点击”、“沙沙声”、“金属与塑料碰撞”、“流水声”等)。共标注了 44 个类别、50,968 个音频事件。
4.3 数字孪生:场景与物体运动
4.3.1 场景
我们通过重建厨房表面并手动标记每个固定设备(如橱柜、抽屉)、储物空间(如货架、挂钩)和大型家电(如冰箱、微波炉),为参与者的厨房创建数字孪生模型。这与基于已知环境的数字孪生不同,我们的数字孪生是在录制视频获得的多视频 SLAM 点云基础上创建的。
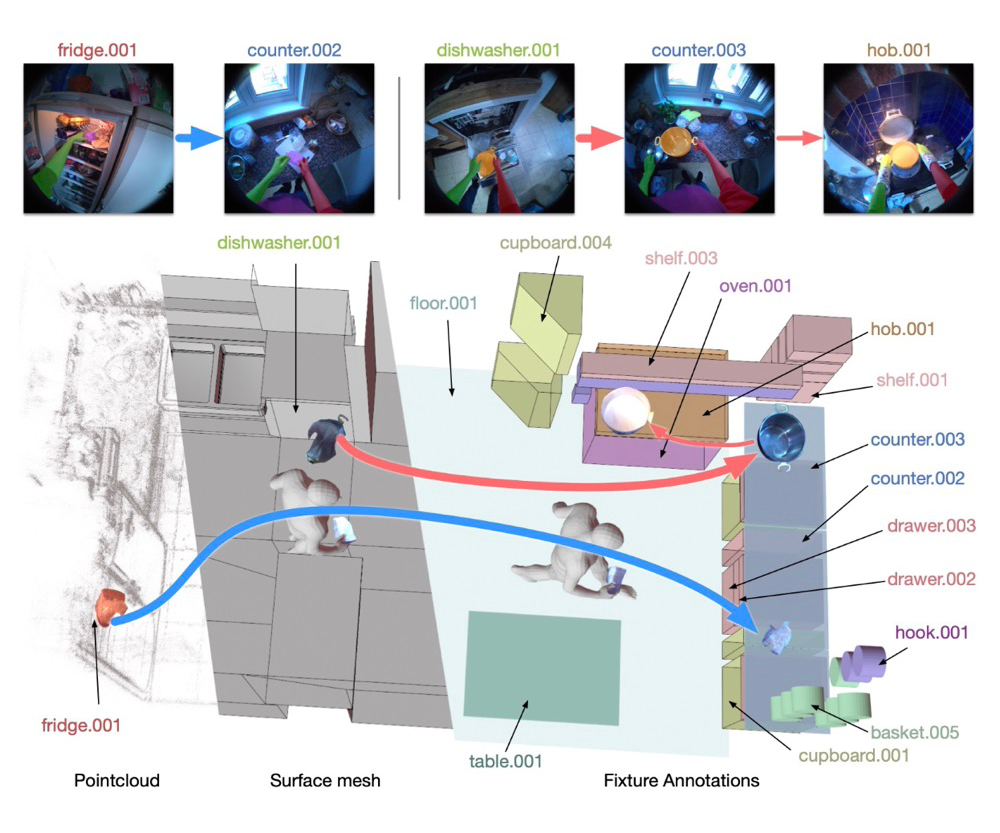
每个厨房平均标注了 45.9 个固定家具(最少 31 个,最多 62 个),包括平均 14.2 个柜台/表面、12.2 个橱柜、7.8 个抽屉和 5.2 个家电。
4.3.2 手部掩码
我们在每个视频中选择一些帧标注了双手,用于自动分割并人工修正一部分掩码。总共包含 770 万张手部掩码,其中 390 万为右手、380 万为左手,人工标注掩码为 1.1 万张。
4.3.3 2D 物体移动
我们首先标注物体移动时的时间片段,每次物体移动均记录直到静止,起始和终止位置均标注 2D 边界框。共标注了 19,900 个物体移动轨迹和 36,900 个边界框。
4.3.4 物体掩码
我们使用迭代的 SAM2 进行初始化分割,并进行人工修正。人工修正的掩码占总数的 74%,SAM2 与人工掩码的平均 IoU 为 0.82。
4.3.5 掩码映射至3D
我们利用稠密的深度估计和 SLAM 提供的 2D 到 3D 稀疏对应关系,将物体掩码映射至 3D。
4.3.6 3D 物体运动
平均而言,物体移动距离为 61.4 厘米(标准差 84.5 厘米),27.6% 的物体移动超过 10 厘米,而 7.6% 的物体移动超过 2 米。
4.3.7 物体与场景互动
我们将 3D 物体位置与最近的固定家具关联,并人工核验所有关联。
4.3.8 视线轨迹与物体移动
我们结合眼球视线数据与 3D 物体位置标注,确定物体被注视的时间点,即物体被取走或放置前凝视轨迹到达物体所在位置的时刻。
4.3.9 长期目标追踪
我们通过关联目标的运动轨迹,形成更长的轨迹序列,即“目标行程(object itineraries)”,以捕捉目标的连续移动过程。我们高效的处理流程利用了提升后的三维位置信息,使得对一小时长的视频的标注可以在几分钟内完成。
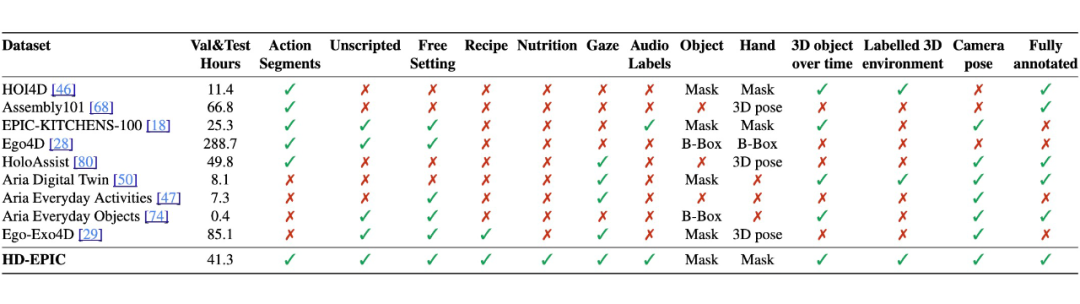
4.4 HD-EPIC 与其他第一人称视角数据集对比
与现有第一人称视角数据集相比,HD-EPIC 的视频长度、标注精细程度和场景真实性显著提升,是首个涵盖菜谱、营养、动作、音频、视线及 3D 标注的数据集,极大丰富了现有数据集所能提供的评测维度。

基准测试与结果
我们通过多个基准测试展示 HD-EPIC 作为验证数据集的潜力,涵盖通用的视频问答(VQA)(第 5.1 节)、动作与声音识别(第 5.2 节)以及长期视频物体分割(第 5.3 节)。
5.1 HD-EPIC视觉问答基准与分析
5.1.1 基准构建
我们基于我们的密集标注输出构建了一个覆盖七类注释内容的全面 VQA 基准:
1. 菜谱:问题涉及菜谱及其步骤的定位、检索与识别。
2. 食材:问题关于使用的食材、其重量、添加时间与顺序。
3. 营养:问题聚焦于食材的营养及其随食材加入而产生的变化。
4. 细粒度动作:包括动作的内容、方式与原因,以及时间定位。
5. 三维感知:涉及对场景中物体相对位置的理解。
6. 物体运动:涉及物体在长视频中的运动时间、位置和次数。
7. 视线:问题关于视线注视的对象和预测未来的物体交互。
我们为每类问题定义了原型,依据标注生成问题、正确答案及强负样本。例如,“物体移动次数”问题询问“视频中对象 X 在 Y 时刻出现后共移动了几次?”,这类问题需要长时间多跳信息才能正确回答。
与之相对,“动作方式识别”则会问“对于 <动词,名词> 这一动作,下列哪项最能准确描述其执行方式?”,旨在测试模型对动作细节的捕捉能力。
每个问题均为五选一选择题,我们通过在数据集内采样生成高质量干扰项,使问题更具挑战性。最终,如下图所示,我们总共生成了 26,650 个多选问题,覆盖 30 个问题原型,使其成为目前最大的视频 VQA 基准之一。
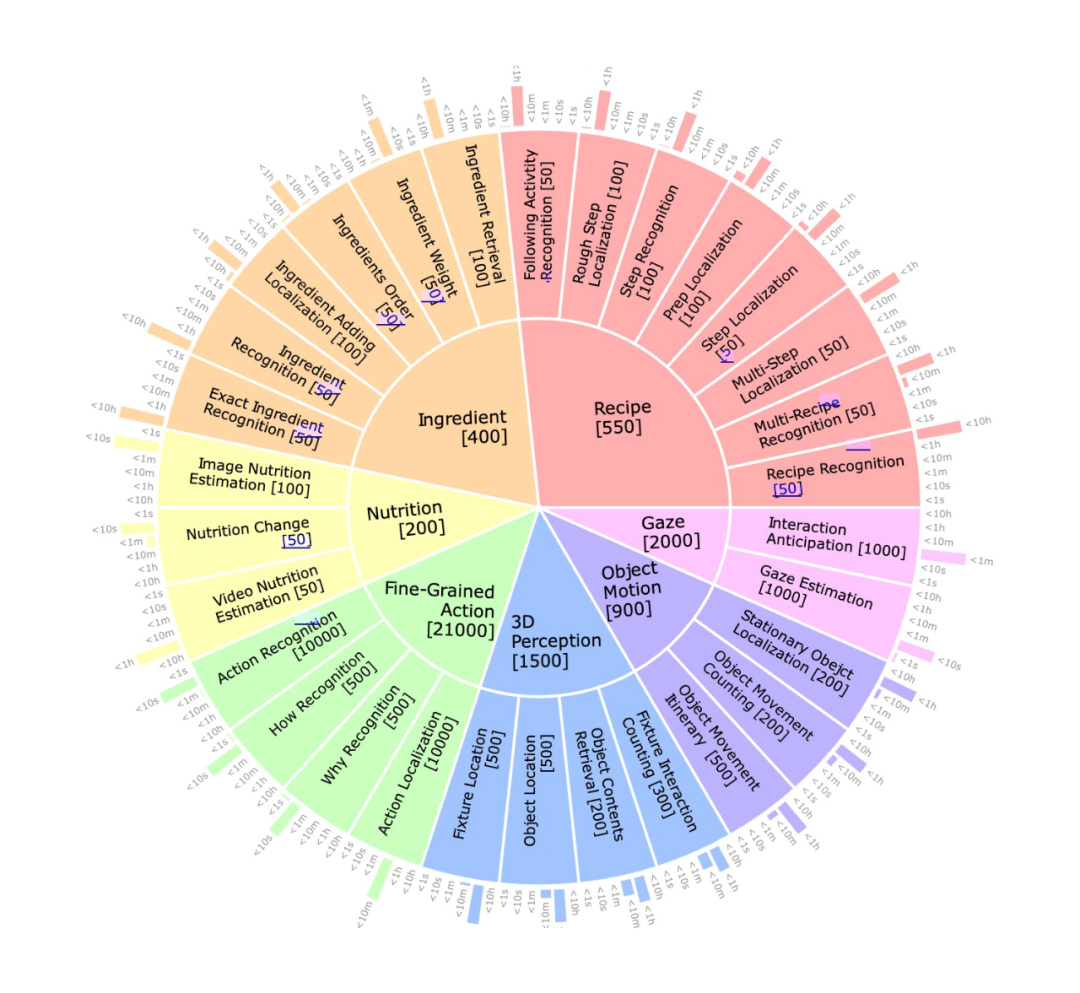
5.1.2 视觉-语言模型 (VLM models)
我们选用了 5 个代表性模型作为基准:
-
LLaMA 3.2 90B:我们使用该模型作为强大的开源 text-only 基线,因为大型语言模型即使没有视觉输入,也能在视觉问答基准上表现良好。
-
VideoLLaMA 2 7B:开源短上下文的视频语言模型。
-
LongVA:最长上下文的开源模型。
-
LLaVA-Video:训练包含第一人称数据的开源模型。
-
Gemini Pro:闭源模型,支持长视频输入,当前 SOTA。
5.1.3 VQA 结果分析

表格显示,text-only 模型 LLAMA 3.2 准确率仅为 26.5%,比随机选择高 6.7%;视频-语言模型如 VideoLLaMA、LongVA、LLaVA-Video 表现略好,约在 27–32% 之间;而 Gemini Pro 表现最佳,在菜谱与食材类问题中由于外部知识的支持取得显著优势,平均达到 37.6%。然而与人类基线(90.3%)相比仍有巨大差距,表明该基准对当前模型仍是极大挑战。
模型在所有长度的视频中表现都不理想,尤其在 1 分钟以上片段上误差最严重。常见失败案例包括:动作问题中多个答案共同物体;营养问题中模型无法读取视频中显示的食材重量;视线问题中模型倾向选择最近刚被移动的物体;3D 理解问题中方向和家具类别易混淆。
5.2 识别基准
5.2.1 动作识别
我们使用 EPIC-KITCHENS-100 中训练的 5 个动作识别模型在 HD-EPIC 上进行测试。结果显示,HD-EPIC 对现有模型具有很大挑战性。即使是最强模型,其动作类别识别准确率也仅为 24%。
5.2.2 声音识别
我们测试了 3 个在 EPIC-Sounds 上训练的音频模型,发现它们在 HD-EPIC 上的表现大幅下降(准确率下降 25% 以上),这表明当前音频模型在新环境与设备下的泛化能力较弱。
5.3 长期视频物体分割(VOS)
我们基于我们的视频段与物体轨迹构建了长期 VOS 基准,包含 1000 个视频序列,每个序列包含 1–5 个目标物体和 2 个手部掩码。我们评估了两个主流模型(Cutie 和 SAM2)以及静态掩码作为基线。
结果表明,Cutie 在物体分割方面优于 SAM2,SAM2 在手部分割方面表现更好。总体来看,第一人称视频中的视角变化、光照变化与遮挡带来了极大挑战。

展望
HD-EPIC 数据集可通过以下链接获取(包含视频、音频、视线数据、Blender 格式的数字孪生模型以及相机位姿估计):
http://dx.doi.org/10.5523/bris.3cqb5b81wk2dc2379fx1mrxh47
标注数据则可通过官网获取(包括物体移动轨迹、掩码与 3D 位置、长时段物体轨迹及物体-动作-设备的对应关系):
http://hd-epic.github.io
我们希望 HD-EPIC 能够引导未来的研究走向更加全面的人类视角感知,在真实环境中推动对第一人称视频的深入理解与多模态智能的发展。
(文:PaperWeekly)