
在解析处理 PDF 文档时,我们经常要借助 OCR 工具提取内容,用于搜索、问答或数据整理。
但大部分 OCR 工具存在许多痛点,比如:配置繁琐、模型庞大、图表识别差、精度低、识别结构乱、不能图文结合理解等等。
而且传统 OCR 工具非常依赖文本提取。
今天给小伙伴们推荐一款彻底摆脱传统 OCR 限制的 AI 文档处理神器:No-OCR。
它不再依赖 OCR,而是用多模态 AI + 向量索引来理解整本 PDF,支持图文混合搜索、视觉问答、内容归档查询,是文档智能搜索与问答的全新范式!
真正的无需 OCR 即可实现轻松处理复杂布局、图表和图像,极大提升文档分析效率。
主要功能
-
• 文档集合管理:支持创建和管理PDF/文档集合,以“案例”分类方便索引查找 -
• 自动构建数据集:可构建 Hugging Face 风格的数据结构,便于训练/微调 -
• 向量检索引擎:使用 LanceDB 为每页 PDF 构建图文向量,快速定位内容 -
• 多模态问答:基于 Qwen2-VL 模型,对图像、图表进行视觉理解与问答 -
• 混合查询:支持文本 + 图像混合搜索能力,问题更自由、语义更强
快速入手
No-OCR 提供有在线Demo可以直接体验所有功能,也可以在本地或服务器上进行项目部署。
在线体验:https://no-ocr.com/
使用上主要分为两个流程:创建案例、搜索文档。
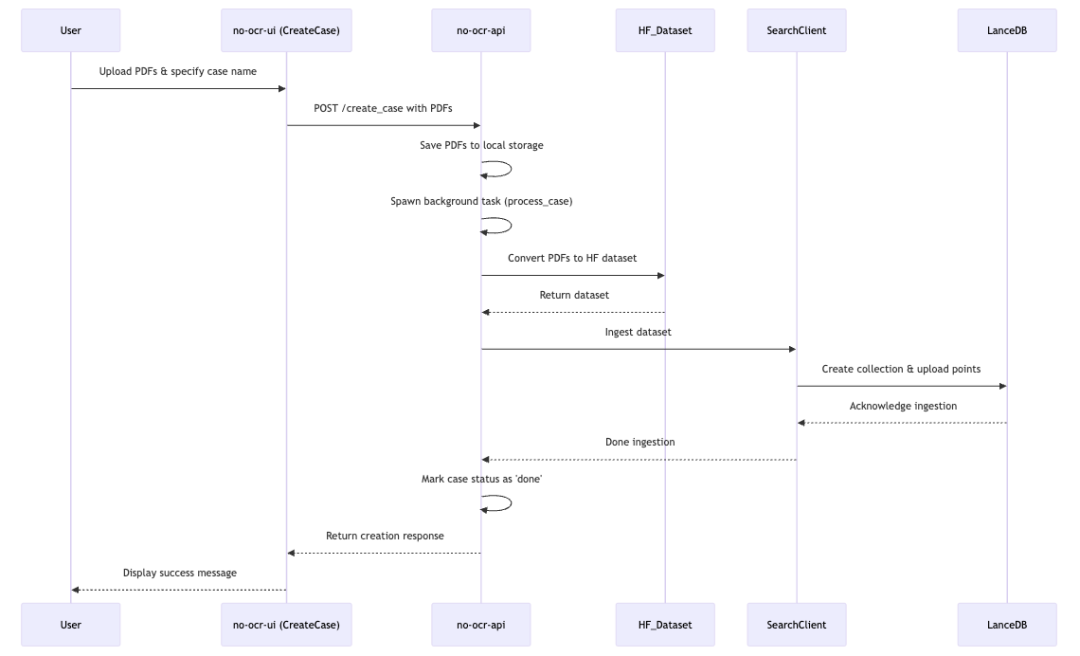
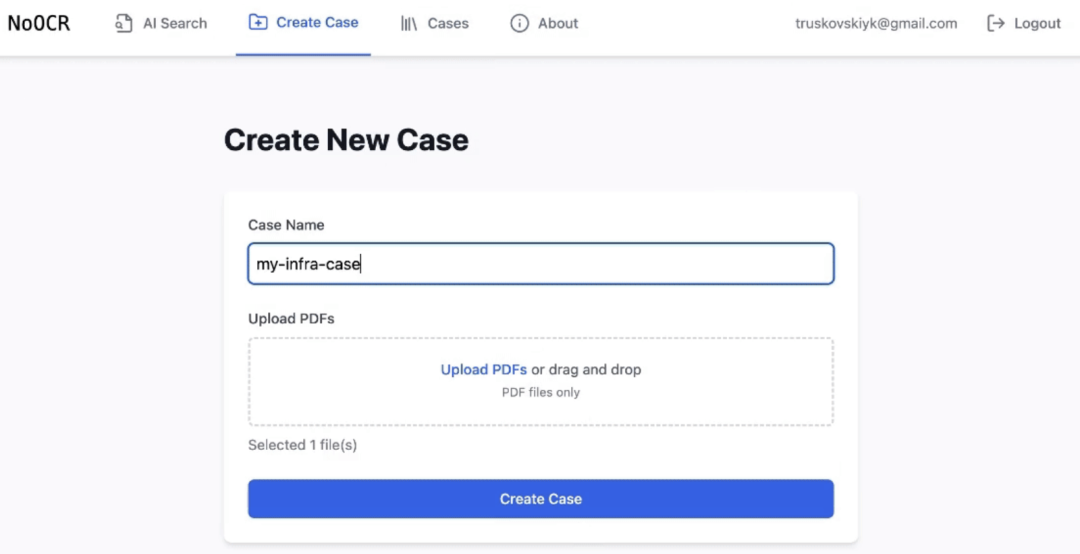
创建案例,需要在前端界面,点击“Create Case”,命名Case名并上传 PDF 文件。案例自动组织,支持批量导入。
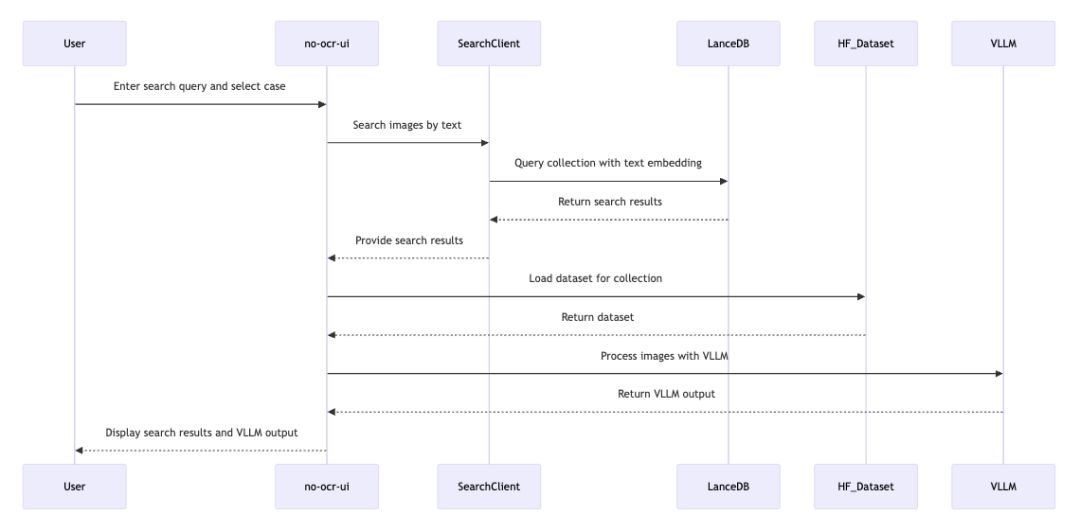
搜索文档,需要先创建案例,上传PDF文档后,再点击“AI Search”,选择案例,然后输入文本查询。
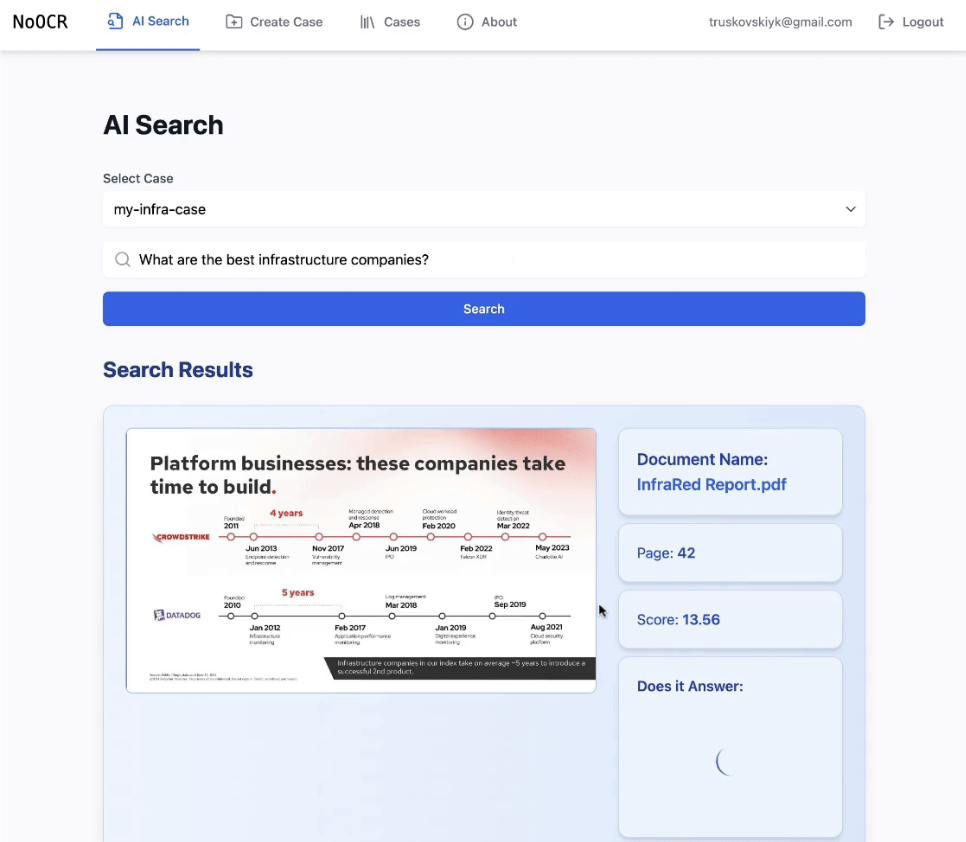
本地安装部署
1、克隆项目
git clone https://github.com/kyryl-opens-ml/no-ocr2、安装后端服务依赖项
cd no-ocr-api
pip install -r requirements.txt3、运行后端服务器
fastapi dev api.py4、安装前端服务依赖项
cd no-ocr-ui
npm install5、运行前端服务
npm run dev依赖服务—>获取 API 密钥
Modal:注册 modal.com 获取 API 密钥。
Superbase:创建项目(supabase.com)获取 URL 和密钥。
Qdrant:本地运行或使用云服务(qdrant.io)。
技术栈一览
-
• 文档存储与处理:PDF 文档结构化解析 -
• 向量存储:使用 LanceDB,轻量级、高速 -
• 多模态模型:采用 Qwen-VL 系列模型,支持视觉问答 -
• 部署方式:支持 Docker 快速运行 or 本地开发部署
与传统 OCR 工具对比
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
写在最后
No-OCR 这款 AI 文档处理工具可以说是 PDF 分析的一股清流,它完全不依赖传统 OCR,省心又高效!
传统 OCR 工具在 PDF 文本提取中常面临配置复杂、精度不足等问题时,No-OCR 就显得尤为重要了,而且整个流程化处理也更加通俗易懂。
图 + 文 + 问答 + 索引一体化文档理解平台,随时让文档成为“可对话”的智能体。
如果你正在做知识库整理、企业档案智能搜索、图文资料问答分析等任务,No OCR 是极具潜力的开源解决方案之一。
GitHub 项目地址: https://github.com/kyryl-opens-ml/no-ocr

● 一款改变你视频下载体验的神器:MediaGo
● 新一代开源语音库CoQui TTS冲到了GitHub 20.5k Star
● 最新最全 VSCODE 插件推荐(2023版)
● Star 50.3k!超棒的国产远程桌面开源应用火了!
● 超牛的AI物理引擎项目,刚开源不到一天,就飙升到超9K Star!突破物理仿真极限!

(文:开源星探)