

前两天闲来没事逛 HuggingFace,意外发现腾讯研发团队放出了一个开源模型 VLR1-3B 的预览版(preview),还是多模态?
模型链接:
https://hf-mirror.com/TencentBAC/TBAC-VLR1-3B-preview
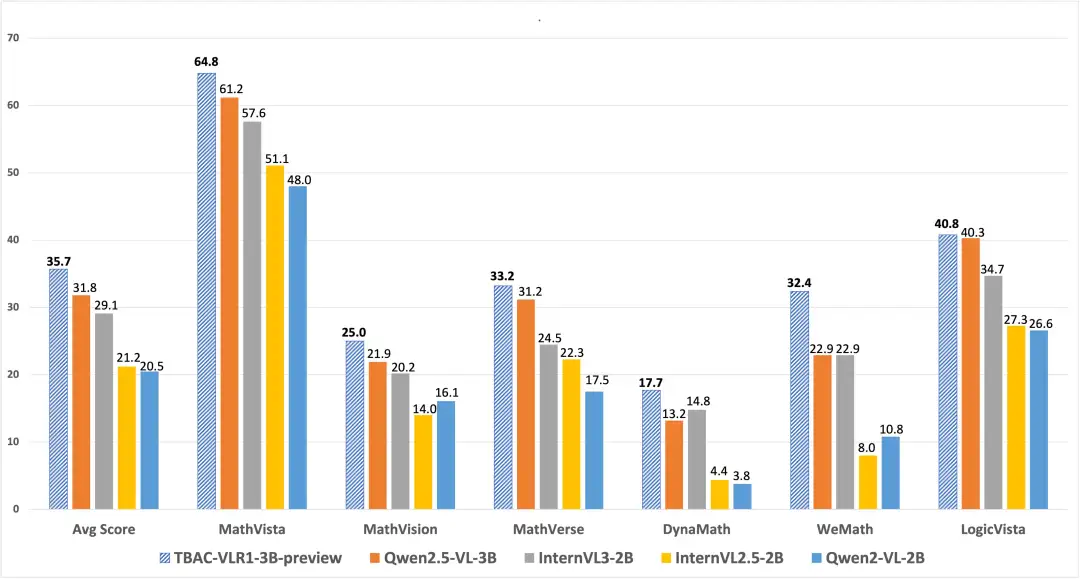
腾讯开源模型?这真是稀罕了。从模型介绍来看,对比现在动辄六七百的参数量的大模型来说,这是一个只有 3.78B 的“小”模型,使用了 GRPO 技术,增强了推理性能。介绍中声称达到了同级别模型中推理能力第一(SOTA)。

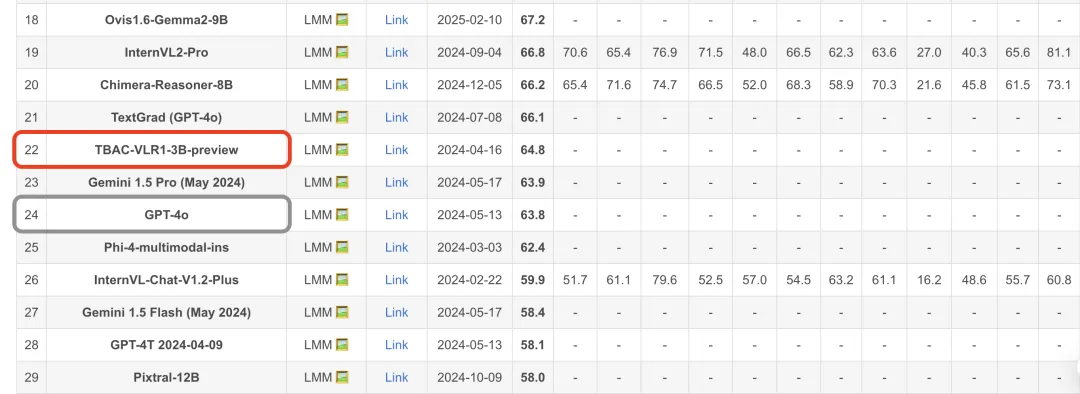
▲ MathVision 官方榜单
仔细看测试报告,都是数学相关的测试,到 MathVista [1] 和 MathVision [2] 这两个权威 AI 数学榜单的官网上查证,VLR1-3B 这“小”模型不仅都在榜,而且比很多商业闭源大模型(如 Gemini1.5 和 GPT-4V)表现都要强,甚至在 MathVista 的评测中击败了 GPT-4o!
这不正巧了吗?小编最近正愁帮邻居刚上初中的孩子批数学作业,被多项式计算和几何证明搞得焦头烂额的。
现在既有模型,又有示例代码,何不动手撸个自己的“AI 作业帮”,既可以帮我干活,又能够测试一下 VLR1-3B 的真实水平😜。

AI 作业助手
要说明的是,AI 作业助手,特别是数学作业助手,仅仅有答案还不够,更重要的是给出推导过程。这也是 VLR1-3B 让人眼前一亮的原因,就是它宣称的 推理能力。
下面来看一下搭载了 VLR1-3B 模型后,我这个丐版的“作业帮”真实的答题效果(latex 解析还在优化中,大家见谅哈😂):
多项式计算
先从真题试卷中截取了两道基础计算题进行测试:
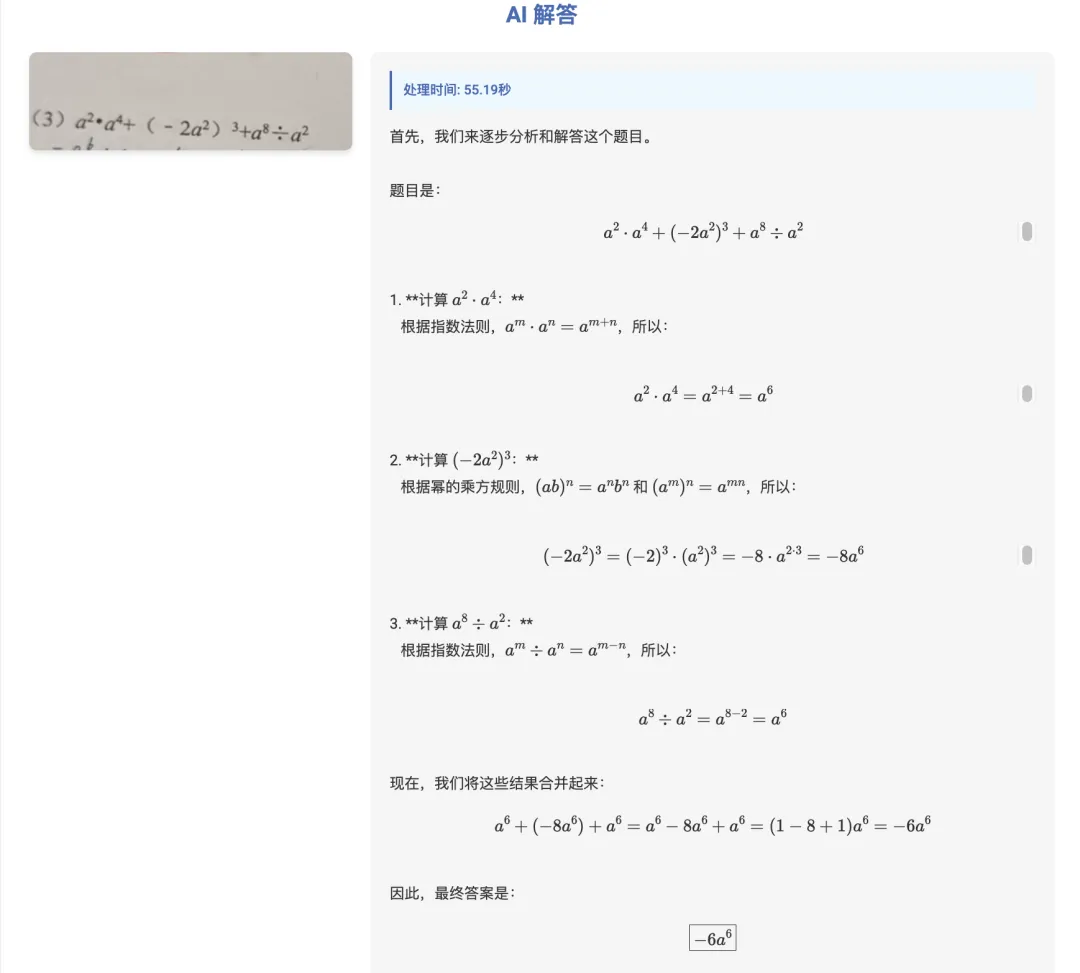
哪怕是拍照的试卷问题也可以准确的识别,计算过程也清晰,答案正确👌,通过。再试一道:

很好,应用了正确的公式👌,邻居家小孩似乎可以愉快的抄写作业了呢😝
坐标系理解
接下来要稍微上一点难度,看看 VLR1-3B 对平面直角坐标系的理解如何:

不错,一开始就理解了这一题的考点,并告知了题点,横纵坐标都为负的点,然后还分析了每个选项,给出正确答案。解释的有理有据👌。以后还会有家长给熊孩子讲题讲到心梗吗😉
函数计算
下面要进行的是函数计算,依然考验模型从图片中正确的读取函数公式,并依靠推理能力得出函数计算结果:
问题:f(4) 等于多少?

函数识别👌,计算过程👌,答案✅。
平面几何
接下来是重中之重的测试,平面几何。先来两道填空题:
问题:△ABC 的两内角平分线 OB、OC 相交于点 O,若 ∠A=110°,则 ∠BOC=()

表现依然出色,不仅给出了详尽的推理过程,还给出了准确的答案 ✅
接下来再来一题:
问题:如图,在 △ABC 中,AB=8,BC=12,点 D、E 分别是边 AB、AC 的中点,点 F 是线段 DE 上的一点,连接 AF、BF,若 ∠AFB=90°,则线段 EF 的长为()

非常棒平面几何解题能力👌,在应用了正确的公式定理下,还会用“∵”,“∴”等专业的数学推理符号,给 VLR1-3B 点赞👍🏻。
平面几何是中学数学的重点,与填空和选择不同,模型有可能靠蒙答对题(人也会哈),这种证明类型的题目更考验模型的“真本事”,再来测试一道平面几何的证明题:
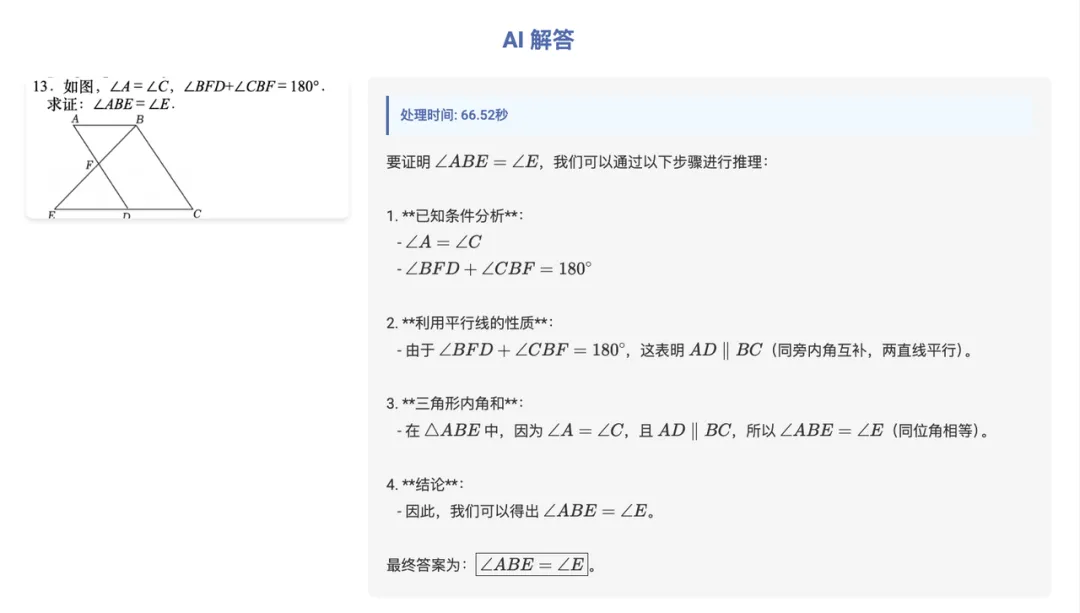
没问题,证明过程清晰,测试通过 ✅。
物理
既然 VLR1-3B 在数学方面表现的这么好,何不再挑战一下,做道物理题试试?
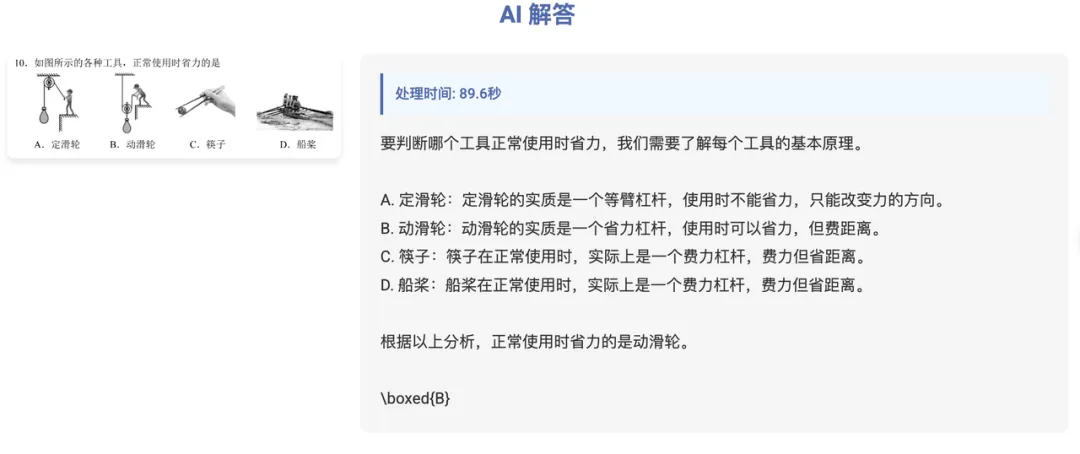
哦吼~,物理题也能答,还能解释对自己的选择。
从结果来看,在VLR1-3B的帮助下,我这个家庭丐版AI作业帮 💯大成功啊!在此诚挚的感谢我邻居,慷慨的赞助他家小孩的作业进行测试!


What’s more?
从之前的测试来看,VLR1-3B 有确实有着出众的数学能力,从图片的公式理解到答案的推理求解,甚至格式的输出都有着令人满意的效果。既然如此,当然就要“强模型所难”, 考验一下VLR1-3B 在其他通用多模态场景的表现:
先用我最喜欢的猫咪开始测试,询问它图中猫的花纹、品种和年龄:

Bingo,回答很准确~
再来,因为有从事的是自动驾驶算法研究的经验,所以凡是遇到有视觉能力的模型,都会被我拿来测一下:
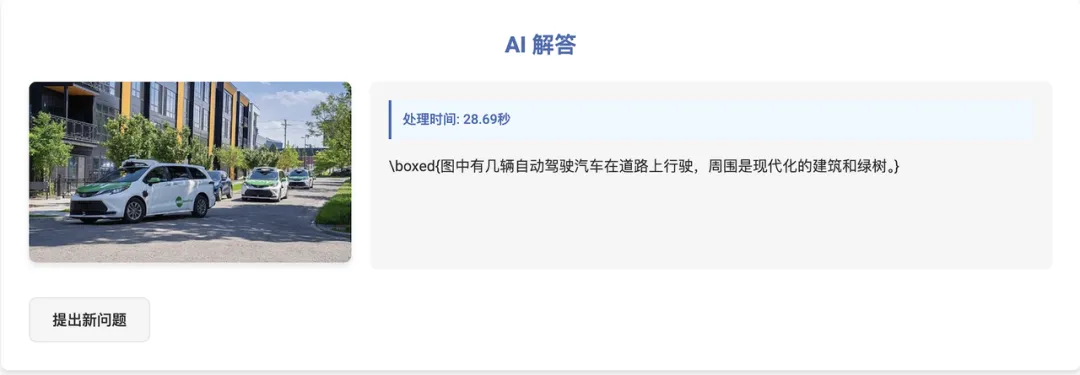
连自动驾驶车辆都认识,厉害了👍🏻。那真实道路场景表现怎么样呢?
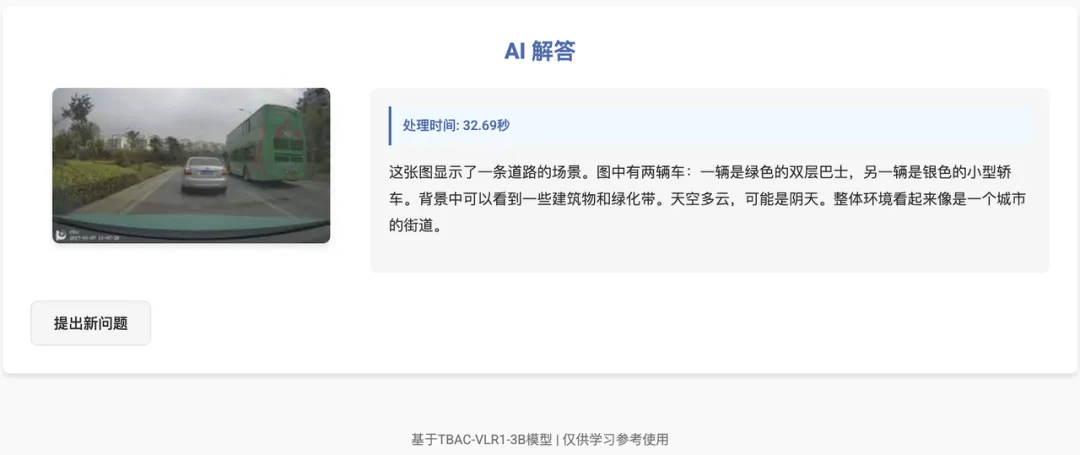
相当可以,车辆数量、颜色、类型都判断正确 ✅,同时天气和驾驶环境也准确识别。再来个夜晚场景,问问前方车辆的行驶意图:
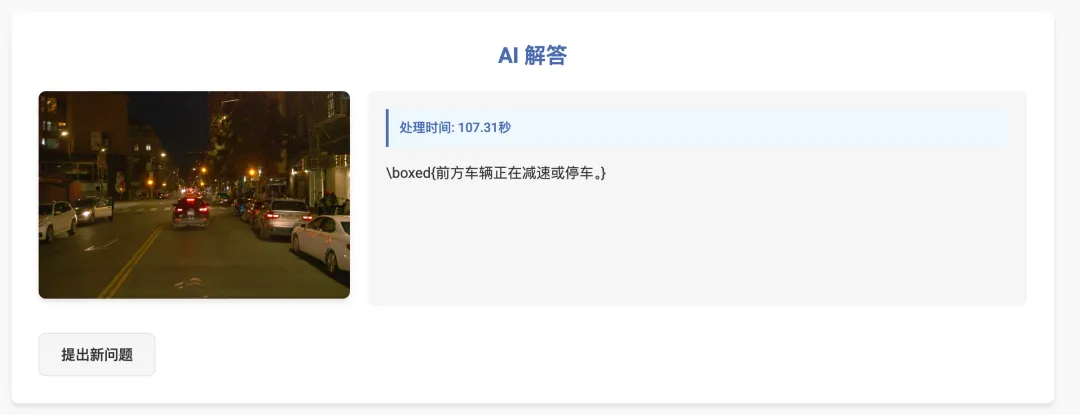
看来可以呀~
测试到这,可见VLR1-3B的通用多模态能力不是一般的强了💪。大家有没有想到这个麻雀虽小,五脏俱全的多模态模型,除了 AI 数学助手,还有哪些可靠的应用场景?
小编现在想到的就有单机、本地版的家庭助手或者智能汽车车载 LLM 智能中心,在这两个场景中结合 VLR1-3B 的视觉推理能力,观察宠物、婴儿和老人的状态,或者与乘客完成车内互动、判断车辆行驶环境和前方车辆意图,能够实现纯本地运算和数据处理,提供更加安全可靠的方案。未来量化适配端侧这类多模态“小”模型似乎是一个不错的方向。

总体测试下来, VLR1-3B 不愧于它同级别模型多模态推理 SOTA 的自我介绍。测试过程中虽然也遇到了该级别模型的常见问题——如思考过程中的幻觉,特别是一些测试中,结果是正确的,但思考过程却明显失误。
但考虑到目前还是该开源模型的预览版,相信在后续更新和实际落地场景中,使用场景数据来 Fine-tune 后的模型能取得更好的效果。
话又说回来,作为一个只有 3B,有望成为开源本地 “家庭 AI 作业帮”的的选手,我很期待这个 3B 小模型的正式版发布,也希望能仔细学习一下技术报告或者是论文。
后续的计划当然是一边等正式版发布,一边继续完善这个 AI 作业助手的前后端,同时尝试量化模型(现在 是BF16,空间很大),并采用专业的推理框架提升性能。
最后的最后,让我许个愿,希望在正式版中看到视觉坐标定位功能

(文:PaperWeekly)