
静静看 OpenAI “表演” 的一周。
📢本周AI快讯 | 1分钟速览🚀
1️⃣ 🔍 OpenAI 推出轻量版 Deep Research :基于 o4-mini 模型,首次向免费用户开放,每月 5 次使用额度,搜索准确率达 45.6%。
2️⃣ 🧠 GPT-4o 再升级 :提升智能与个性表现,优化记忆保存时机,增强 STEM 解题能力,交互更加主动自然。
3️⃣ 📈 ChatGPT 模型额度翻倍 :o3 模型每周上限提升至 100 条,o4-mini 增至 300 条/日,o4-mini-high 增至 100 条/日。
4️⃣ 🎨 OpenAI 发布图像生成 API :gpt-image-1 模型支持多风格图像生成,定价从低质量 2 美分到高质量 19 美分不等。
5️⃣ 💻 谷歌 30% 代码 AI 辅助 :较 2024 年 10 月的 25% 有显著提升,归功于强大模型与 “agentic workflows” 工作流程。
6️⃣ 📱 Gemini 月活达 3.5 亿 :全球日活约 3500 万,仍落后于 ChatGPT(6 亿)和 Meta AI(8 亿),用户参与度有待提升。
7️⃣ ✨ Adobe 推出 Firefly 4 系列 :Image Model 4 和 Ultra 版本支持 2K 输出,新增视频模型和协作情绪板工具 Firefly Boards。
8️⃣ 🎭 Character.AI 推出 AvatarFX :首个视频生成模型 AvatarFX,静态图片转动态视频,支持口型同步和表情,严格防滥用措施。
9️⃣ 🚀 百度发布文心 4.5 与 X1 :性能超越 GPT-4o,调用成本大幅下降,输入价格仅 0.8 元/百万 token,是 DeepSeek 的 40%。
1️⃣0️⃣ 💰 Manus AI 获 7500 万美元融资 :估值飙升至近 5 亿美元,将拓展美日中东市场,但每任务需向 Anthropic 支付 2 美元成本。
1️⃣1️⃣ 🎵 月之暗面发布 Kimi 音频模型 :开源 Kimi-Audio-7B-Instruct 模型,在 1300 万小时数据上训练,支持多种音频任务,性能超越同类产品。
1. OpenAI 推出轻量版 Deep Research
4 月 24 日,OpenAI 宣布正式推出基于 o4-mini 模型的轻量版 Deep Research 功能,首次向免费用户开放。
与标准版 Deep Research 使用的 o3 模型相比,轻量版采用了更高效的 o4-mini 模型,虽然生成的回复内容较短,但依然能够保持良好的质量。官方数据显示,轻量版 Deep Research 的搜索准确率为 45.6,略低于标准版的 51.5,但明显高于其他模型组合,如 4o+Browsing 的 1.9 和 o4-mini with Python+Browsing 的 28.3。
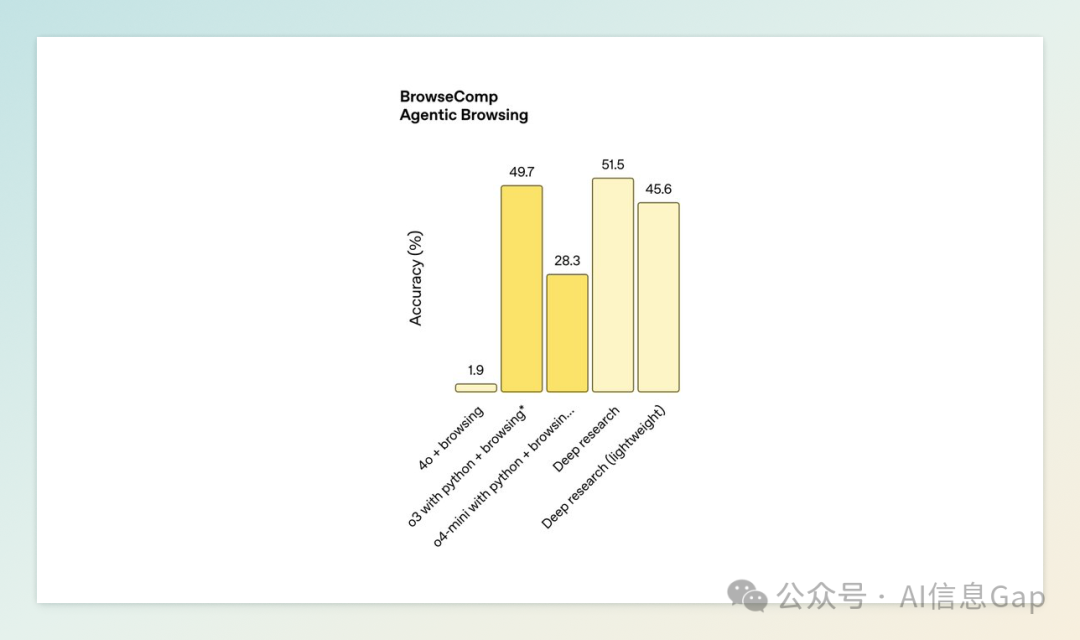
在使用额度方面,免费用户每月可使用 5 次轻量版 Deep Research 功能;Plus 和 Team 会员每月可使用 10 次标准版和 15 次轻量版;Pro 用户每月则可使用 125 次标准版和 125 次轻量版。当用户的标准版 Deep Research 使用额度用尽后,系统将自动切换到轻量版继续使用。Enterprise 和教育版用户将在下周获得相应功能,额度与 Plus / Team 方案一致。
此外,o4-mini 模型在数学、编程和视觉任务上表现优异,支持更高的使用频率,适合需要高吞吐量的推理任务。
2. GPT-4o 模型再升级:智能与个性双提升
4 月 25 日,OpenAI 首席执行官山姆・奥特曼(Sam Altman)在 X 平台宣布,对 GPT-4o 模型进行了新一轮升级,重点提升了模型的智能水平和个性表现。此次更新使 GPT-4o 的交互更加自然、主动,并增强模型在多种任务中的表现力。
根据 OpenAI 的官方说明,此次升级优化了 GPT-4o 在保存记忆的时机,并提升了其在 STEM(科学、技术、工程和数学)领域的解题能力。此外,模型的回应方式也进行了细微调整,使其更加主动,能够更有效地引导对话朝着有成效的方向发展。这些改进使得 GPT-4o 在各种任务中表现得更直观、更高效。
本次升级是继今年 3 月对 GPT-4o 进行的重大改进之后的又一重要更新。3 月的升级使模型在交互上变得更直观,功能上更具创造力,协作能力也得到提升;在指令遵循、编程表现及沟通风格方面,呈现出更加清晰流畅的特性。
3. ChatGPT o3 与 o4-mini 模型使用额度翻倍
4 月 24 日,针对 ChatGPT Plus、Team 和 Enterprise 用户,OpenAI 正式宣布上调 o3 与 o4-mini 系列模型的使用额度,旨在提升用户体验并鼓励更广泛的模型应用。
具体调整如下:
-
o3模型的每周消息上限从原先的 50 条提升至 100 条; -
o4-mini模型的每日消息上限从 150 条提升至 300 条; -
o4-mini-high模型的每日消息上限从 50 条提升至 100 条。

此次调整由 OpenAI 首席执行官山姆・奥特曼(Sam Altman)在 X 平台上宣布,他表示:“我们已将 ChatGPT Plus 订阅者的 o3 和 o4-mini-high 模型的速率限制翻倍。”
这些新限制适用于 ChatGPT Plus、Team 和 Enterprise 用户,Pro 用户则享有几乎无限制的访问权限。用户可以在模型选择器中查看当前的使用情况和重置时间。
4. OpenAI 推出图像生成模型 gpt-image-1 API
4 月 23 日,OpenAI 宣布将其在 ChatGPT 中广受欢迎的图像生成功能以 API 形式开放,允许开发者将该功能集成到自己的应用和服务中。该功能由最新的多模态模型 gpt-image-1 提供支持,具备强大的文本理解和图像生成能力。
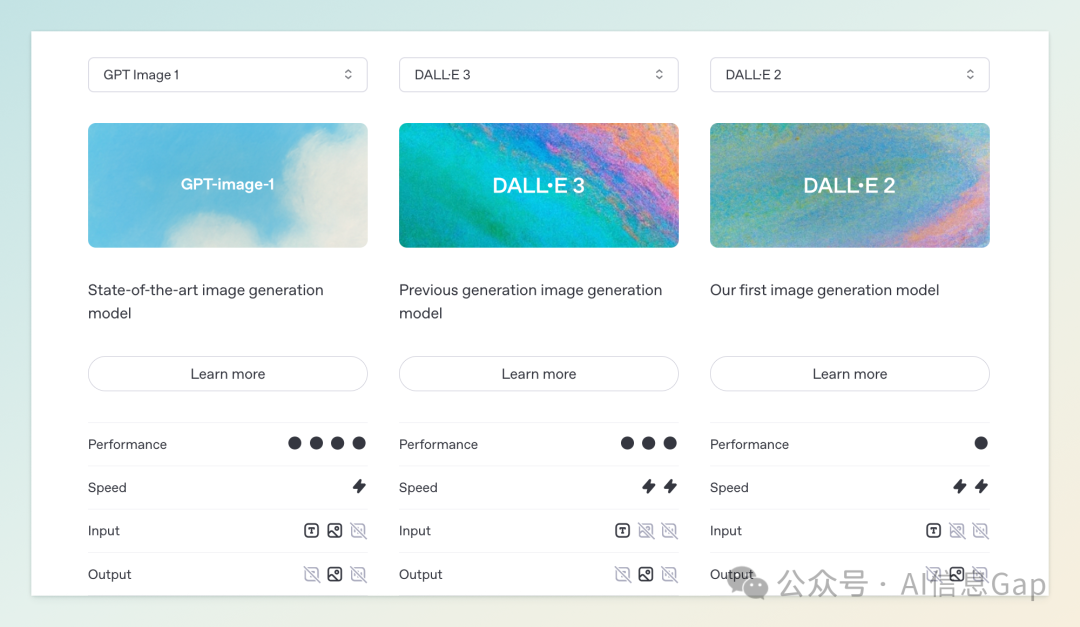
在定价方面,OpenAI 采用基于 token 的计费模式:文本输入为每百万 token 5 美元,图像输入为每百万 token 10 美元,图像输出为每百万 token 40 美元。以实际使用计算,生成一张低质量图像约需 2 美分,中等质量约 7 美分,高质量约 19 美分,具体费用取决于图像质量和尺寸。
gpt-image-1 模型支持多种图像风格和格式,能够生成包含可读文字的图像,并提供背景透明度、输出格式等多项参数设置。此外,开发者还可以通过设置 moderation 参数,控制内容审核的敏感度,以满足不同应用场景的需求。
目前,Adobe、Figma、Wix、Instacart 等多家企业已开始使用或测试该模型,将其集成到各自的平台中,以提升用户体验和内容创作效率。
5. 谷歌超 30% 代码由 AI 协助编写
在 2025 年第一季度财报电话会议上,Alphabet 首席执行官桑达尔・皮查伊(Sundar Pichai)宣布,谷歌目前超过 30% 的代码由 AI 协助生成,较 2024 年 10 月的 25% 有显著提升。这一转变得益于更强大的模型能力和“agentic workflows”的引入,即 AI 能够自主规划并执行多步骤任务的工作流程。皮查伊指出,AI 编程已在公司内部广泛应用,尤其是在客户服务团队中表现突出。

这一趋势标志着谷歌在内部开发流程中全面推进 AI 化。除了代码生成,AI 还被用于客户支持、财务报告等领域,提升了整体效率。随着 Gemini 2.5 Pro 模型的推出,谷歌在推理、编程、科学和数学等方面取得了重大突破,进一步推动了 AI 在各个产品线的集成。目前,Gemini 模型已嵌入到谷歌的 15 个拥有超过 5 亿用户的产品中,包括 Android 和 Pixel 设备。
在财务方面,Alphabet 报告称,2025 年第一季度营收同比增长 12% 至 902 亿美元,净利润增长 46% 至 345 亿美元。其中,Google Cloud 的收入同比增长 28%,达到 123 亿美元,显示出对 AI 和基础设施产品的强劲需求。谷歌计划在 2025 年投资 750 亿美元用于扩展 AI 基础设施,进一步巩固其在 AI 驱动的搜索市场中的领先地位。
6. 谷歌 Gemini 月活跃用户达 3.5 亿
在美国司法部对谷歌的反垄断诉讼中披露的最新数据指出,截至 2025 年 3 月,谷歌的 AI 聊天机器人 Gemini 的全球月活跃用户数已达到 3.5 亿,日活跃用户数约为 3,500 万。尽管这一增长得益于 Gemini 在 Android 设备上的预装策略,但其用户规模仍明显落后于竞争对手。同期,OpenAI 的 ChatGPT 拥有约 6 亿月活跃用户,而 Meta 的 AI 助手则以 8 亿用户位居首位。

Gemini 的用户增长主要依赖于谷歌强大的生态系统分发能力。例如,谷歌与三星达成协议,将 Gemini 设为 Galaxy S25 系列手机的默认 AI 助手,取代了三星自家的 Bixby。然而,这种捆绑策略也引发了监管机构的关注。美国司法部指出,谷歌利用其在搜索市场的主导地位,通过预装和默认设置来巩固其在 AI 领域的优势,可能违反了反垄断法。
尽管 Gemini 的用户增长迅速,但在用户参与度方面仍落后于竞争对手。数据显示,Gemini 用户平均每次访问浏览 3.28 个页面,停留时间约为 4 分 43 秒,而 ChatGPT 用户的平均访问页面数为 3.81,停留时间达到 6 分 47 秒。此外,Gemini 的跳出率为 32.75%,高于 ChatGPT 的 30.94%。
为了提升竞争力,谷歌正在将 Gemini 深度整合到其核心产品中。例如,Gemini 已被嵌入到谷歌搜索的 AI 概览功能中,该功能每月覆盖超过 15 亿用户。此外,谷歌还推出了 Gemini 2.5 Pro 模型,具备更强的推理和编码能力。
7. Adobe 推出 Firefly Image Model 4 系列模型
4 月 24 日,Adobe 在 Adobe MAX London 大会上正式发布了两款全新文本生成图像模型:Firefly Image Model 4 和 Firefly Image Model 4 Ultra。这两款模型现已在 Firefly Web 应用中全面上线,并计划很快推出 iOS 和 Android 版本的移动端应用。

Firefly Image Model 4 被称为 Adobe 迄今为止“最快、最可控、最逼真”的图像生成模型,支持最高 2K 分辨率输出,用户可精细控制图像的风格、构图、焦距和镜头角度,适用于快速创意迭代和日常设计需求。而 Firefly Image Model 4 Ultra 则专为需要极致细节和写实效果的场景而设计,擅长渲染复杂结构、人物肖像和多元素组合,适合高质量商业项目的最终输出。
此次更新还带来了 Firefly 视频模型的正式发布,支持从文本或图像生成 1080p 视频片段,并可自定义镜头运动、起止帧和氛围元素。此外,Adobe 还推出了 Firefly Boards(现已公测),这是一个 AI 驱动的协作式情绪板工具,旨在帮助创作者进行灵感收集和快速概念迭代。
值得注意的是,Adobe 进一步开放了 Firefly 平台的生态,用户现在可以在 Firefly Web 应用中选择使用 OpenAI 的图像生成模型、Google 的 Imagen 3 和 Veo 2 等第三方模型进行实验性创作。
8. Character.AI 推出 AvatarFX 模型:让静态图片“开口说话”
4 月 23 日,Character.AI 正式发布了其首个视频生成模型 AvatarFX,该模型能够将静态图片转化为具有口型同步、表情和肢体动作的动态视频。用户只需上传一张图片并提供音频,AvatarFX 即可生成逼真的说话视频,适用于人像、动物、神话生物甚至带有面部特征的物体。
AvatarFX 基于 DiT 架构和流式扩散模型,结合 Character.AI 自研的文本转语音(TTS)技术,实现了高保真、时间一致性的视频生成。该模型支持多角色、多轮对话和长视频生成,确保面部、手部和身体动作的连贯性。
为防止滥用,Character.AI 实施了多项安全措施:禁止使用未成年人和公众人物的照片,自动对人脸进行模糊处理,所有生成视频均添加水印,并对违反规定的用户实行“一次违规即封禁”的政策。
目前,AvatarFX 正处于封闭测试阶段,CAI+ 订阅用户将优先获得使用权限,其他用户可通过官网加入候补名单。
9. 百度发布文心大模型 4.5 Turbo 与 X1 Turbo
4 月 25 日,百度在 Create 2025 百度 AI 开发者大会上正式发布了两款全新大模型:文心大模型 4.5 Turbo 和 文心大模型 X1 Turbo,主打多模态处理、强推理能力以及低成本。
文心大模型 4.5 Turbo 在性能上进行了全面升级,不仅在多模态处理能力上有所增强,还在去幻觉、逻辑推理和代码能力等方面取得了显著进步。在多个基准测试中,其表现优于 GPT-4o,平均得分达到 77.68,超过 GPT-4o 的 72.76。此外,该模型的调用成本大幅下降,每百万 token 的输入价格仅为 0.8 元,输出价格为 3.2 元,较上一代模型下降了 80%,仅为 DeepSeek V3 的 40%。
文心大模型 X1 Turbo 是基于 4.5 Turbo 的深度思考模型,具备更先进的思维链,问答、创作、逻辑推理、工具调用和多模态能力进一步增强。该模型的性能提升显著,同时价格也更为亲民,每百万 token 的输入价格为 1 元,输出价格为 4 元,仅为 DeepSeek R1 的 25%。
10. Manus AI 完成 7500 万美元融资,估值飙升至近 5 亿美元
中国初创公司蝴蝶效应(Butterfly Effect)近期完成了由美国知名风险投资公司 Benchmark 领投的 7500 万美元融资,使其估值跃升至近 5 亿美元,较上一轮增长约五倍。此次融资还吸引了包括腾讯、真格基金和 HSG(原红杉中国)在内的现有投资者的参与。据悉,所筹资金将用于拓展 Manus AI 的国际市场,计划覆盖美国、日本和中东等地区。

Manus AI 是蝴蝶效应推出的一款通用型 AI 智能体,能够根据用户的自然语言指令完成简历筛选、行程规划、股票分析等任务。该产品在今年 3 月发布后迅速获得关注,用户等待名单已超过 260 万人。Manus 官方表示,其智能体在多个任务指标上优于 OpenAI 的 Deep Research 工具。目前,Manus 已推出订阅服务,月费为 39 美元,高级版本为 199 美元。
值得注意的是,Manus 的运营成本较高。外媒报道称,Manus 平均每完成一项任务需向 Anthropic 支付 2 美元,仅在推出后的前两周内,Claude 模型的使用费用就超过了 100 万美元。为降低成本,Manus 正与阿里通义千问团队合作,计划基于国产开源模型和算力平台实现功能落地。
11. 月之暗面发布并开源音频模型 Kimi-Audio-7B-Instruct
4 月 25 日,Moonshot AI 正式发布了开源音频基础模型 Kimi-Audio-7B-Instruct,该模型在音频理解、生成和对话等任务上表现出色。此次发布包括模型权重、推理代码以及评估工具包 Kimi-Audio-Evalkit。
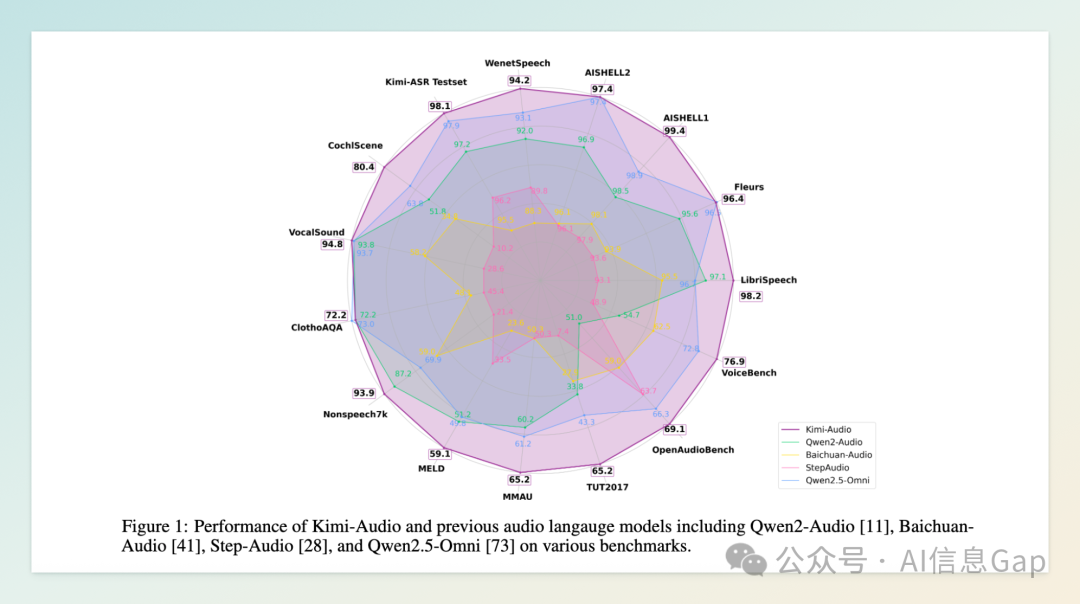
Kimi-Audio 采用混合音频输入架构,结合连续声学特征和离散语义 token,并通过大型语言模型核心实现文本和音频 token 的并行生成。该模型在超过 1300 万小时的多样化音频和文本数据上进行预训练,具备处理语音识别(ASR)、音频问答(AQA)、音频描述(AAC)、语音情感识别(SER)、声音事件/场景分类(SEC/ASC)、文本转语音(TTS)、语音转换(VC)以及端到端语音对话等多种任务的能力。
在多个音频基准测试中,Kimi-Audio 展现出领先的性能。例如,在 LibriSpeech 数据集上,其词错误率(WER)分别为 1.28%(test-clean)和 2.42%(test-other);在 AISHELL-1 数据集上,WER 低至 0.60%。这些成绩超过了同类模型,如 Qwen2-Audio-base 和 Baichuan-base。
此外,Kimi-Audio-Evalkit 提供了完整的评估工具,支持快速复现模型结果和基准测试,方便开发者进行模型评估和比较。用户可以通过 GitHub 获取模型代码和评估工具,也可在 Hugging Face 上访问模型权重。
我是木易,一个专注AI领域的技术产品经理,国内Top2本科+美国Top10 CS硕士。
相信AI是普通人的“外挂”,致力于分享AI全维度知识。这里有最新的AI科普、工具测评、效率秘籍与行业洞察。
欢迎关注“AI信息Gap”,用AI为你的未来加速。
(文:AI信息Gap)