

极市导读
本文提出了一种名为ToMe的免训练方法,通过token合并技术来解决文本到图像合成中的语义绑定问题,显著提升了文生图模型的性能。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

论文链接:https://arxiv.org/abs/2411.07132
GitHub链接:https://github.com/hutaiHang/ToMe
亮点直击
分析了语义绑定问题,重点讨论了[EOT]token的作用,以及跨注意力图错位的问题。此外,探索了token可加性作为一种可能的解决方案。 提出了一种无训练方法——token合并,简称ToMe,作为一种更高效且稳健的语义绑定解决方案。通过引入提出的结束token替代和迭代复合token更新技术,ToMe得到了进一步增强。 在广泛使用的T2I-CompBench基准和GPT-4o对象绑定基准上进行的实验中,将ToMe与多种最先进的方法进行了比较,并始终在性能上大幅领先。
研究背景
近年来,随着深度学习和人工智能技术的飞速发展,文本生成图像(Text-to-Image, T2I)模型在图像生成领域取得了显著的进展。特别是扩散模型(Diffusion Models)的出现,使得T2I模型能够根据文本提示生成高质量、高分辨率的图像。这些模型在艺术创作、设计、虚拟现实等多个领域展现了巨大的应用潜力。然而,尽管T2I模型在生成图像方面表现出色,但在将文本提示中的语义信息准确映射到图像中仍然存在挑战。例如,在多对象生成中,prompt中的每个对象都有自己对应的子属性(用来修饰这个对象的形容词或者名词子对象),但现有的模型难以将文本中的对象与其属性或相关子对象正确关联,表现为错误的绑定或者属性的丢失。我们将这一问题称为语义绑定(Semantic Binding),
如下图所示,当提示词为“一只戴着帽子的狗和一只戴着太阳镜的猫”时,生成的图像可能会出现帽子戴在猫头上,太阳镜戴在狗头上的错误情况。这种错误不仅影响了图像的视觉效果,也限制了T2I模型在实际应用中的可靠性和实用性。

为了解决这一问题,研究者们提出了多种方法,包括优化潜在表示、通过布局先验引导生成过程,以及对T2I模型进行微调等。然而,这些方法往往需要大量的计算资源和复杂的训练过程,且在处理复杂场景(如多个对象和多个属性)时仍然存在局限性。因此,开发一种高效、无需训练且能够有效解决语义绑定问题的方法,成为了当前研究的重要方向。
研究动机
文本嵌入的信息耦合
在处理包含多个对象的prompt时,以往基于布局先验的方法会首先使用LLM生成合理的图像布局,例如将图像划分为不同的子区域,每个子区域只关注prompt中的单个对象。通过这种规划-生成来增强语义对齐。但尽管规划好了不同子区域与原始prompt中不同对象的text embedding进行cross attention,但不同子区域间还是会出现属性泄露等情况,把和一个对象不相关的属性绑定到这个对象上。我们认为,这是由于用来调制不同子区域的text embeeding本身的信息耦合导致的。例如,对于“a cat wearing sunglasses and a dog with hat”这个prompt,其在经由CLIP编码后得到text embedding。原始的扩散模型使用全部text token的text embedding作为cross-attention模块的输入,我们发现当仅仅使用此时的单个‘dog’token的text embedding时,产生的图像内容也是一个带了眼镜的狗。如果使用EOT token(End of Text,即每个句子末尾被padding的结束符)的text embedding,此时产生的图像和使用全部的text token产生的图像内容基本一致。
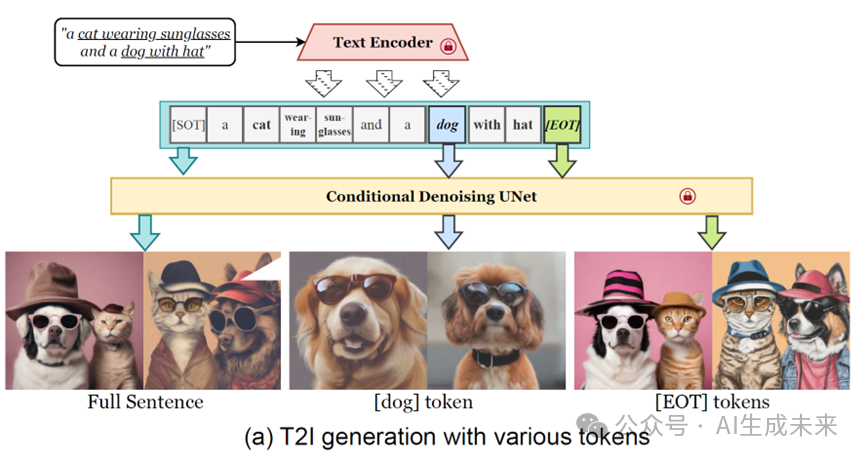
这可能是由于CLIP的causal masked attention导致的,每个text token都可以和它前面的所有token进行self-attention,这导致前面的文本信息会不可避免的传递到后面的token中,而EOT token会包含全部的语义信息。我们认为,这种text embedding层次上的信息泄露导致不同对象之间属性的混淆。
文本嵌入的可加性
此外,我们还发现了文本嵌入的可加性。如下图所示,把两个单独编码后的text embedding相加得到一个新的复合token的embedding,之后输入到扩散模型中,产生的图像可以合理的组合两个不同prompt的内容。例如,下图a的左上部分,[dog+hat]生成了一只戴帽子的狗。这种可加性还可以用于移除对象(下图a,右上、左下部分),甚至执行复杂的语义计算(下图a,右下)。为探究这一现象背后的机制,我们对每个提示词的token表示进行了PCA 降维可视化,下图b 所示。从“queen-king” 获得的方向向量与“woman-man” 的方向向量几乎相同,余弦相似度为0.998

研究方法
因此,为了解决文本生成图像(T2I)模型中的语义绑定问题,关键是如何获得一个更干净的text embedding表征,同时使得扩散模型意识到prompt的语法结构,把每个对象及其相关属性绑定。我们提出了一种名为token合并(Token Merging, ToMe)的新方法。ToMe的核心思想是通过将相关的token聚合为一个复合token,从而增强语义绑定。具体来说,ToMe由两部分组成:token合并与结束token替换,以及通过两个辅助损失进行推理时复合token迭代更新。

-
token合并与结束token替换 我们以“a cat wearing sunglasses and a dog with hat”这个prompt为例进行说明,具体步骤如下:
-
对象token合并:对于包含多个对象的提示词,我们将每个对象及其相关属性token的text embedding相加,生成一个复合token。例如,对于提示词“a dog with hat”,我们将“dog”和“hat”的文本嵌入相加,生成一个表征“戴着帽子的狗”这个语义的复合token [dog*]。 -
结束token替换(End Token Substitution, ETS):由于结束token([EOT])中包含的语义信息可能干扰属性的表达,我们通过替换[EOT]来减轻这种干扰,保留每个主体的语义信息。例如,当提示词为“a cat wearing sunglasses and a dog with hat”时,我们使用来自提示词“a cat and a dog”的[EOT]来替换原有的[EOT]。
通过上述步骤,我们生成了一个统一的文本嵌入,其中每个对象及其属性由一个复合token表示,并且通过替换[EOT]保留了每个主体的语义信息。Token合并使得每个对象及其属性共享同一个cross-attention map,显式的绑定了每个对象及其属性,使它们在生成过程中共表达。
-
复合token迭代更新 为了进一步优化T2I生成的初始阶段(即布局确定阶段),我们引入了两个辅助损失:熵损失和语义绑定损失。这些损失会在推理过程中迭代更新复合token,以提升生成的完整性。
-
熵损失(Entropy Loss):每个token的cross-attention map可以看作一个概率分布,这个分布的信息熵较大则说明这个token关注的区域较为发散。我们计算每个token对应的交叉注意力图的熵值,并将其作为损失函数的一部分。通过最小化熵损失,我们确保每个token专注于其指定的区域,从而防止交叉注意力图过于分散。 
-
语义绑定损失(Semantic Binding Loss):语义绑定损失鼓励复合token推断出与原始对应短语相同的噪声预测,从而进一步加强文本与生成图像之间的语义一致性。具体来说,我们使用一个干净的提示词作为监督信号,确保复合token的语义准确对应它们代表的名词短语。通过最小化语义绑定损失,我们确保复合token的语义信息与原始提示词一致。

实验
我们在T2I-CompBench基准上进行了定量比较,结果如表1所示。ToMe在颜色、纹理和形状属性绑定子集中,BLIP-VQA分数上始终优于或与现有方法相当,表明其可以有效地避免属性混淆。通过ImageReward模型评估的人类偏好得分表明,由ToMe生成的图像更能与提示词对齐。

定性比较结果如下图所示:

ToMe在名词子对象和属性绑定场景下表现出色,这与表1中反映的定量指标一致。具体来说,ToMe能够有效地避免提示词中的语义泄漏,确保每个对象与其属性正确关联。例如,在提示词“一只戴着帽子的狗和一只戴着太阳镜的猫”中,ToMe生成的图像中帽子正确地戴在狗头上,太阳镜正确地戴在猫头上。

消融实验结果如表2所示。我们可以观察到,仅使用token合并技术(Config B)带来了轻微的性能提升,这与上图中的定性结果一致。然而,token合并是后续优化的基础。当它们与熵损失结合使用(Config C)时,性能显著提升。我们推测部分原因是由于交叉注意力图更加规范化,如图7所示。然而,Config C在没有语义绑定损失的情况下,仍然导致生成性能较差,如图6所示,右侧的狗仍然表现出类似猫的特征。加入语义对齐损失可以确保两个主体正确绑定到各自的属性上,而不会出现外观混淆,从而在定量和定性上取得最佳结果。如果忽略token合并并仅应用优化(Config D和Config E),其性能仅与基线相当,这表明token合并是后续优化的基础。移除熵损失(Config F)也可以改善基线,但生成结果中会有明显的伪影,这主要是因为交叉注意力图缺乏足够的正则化。综上所述,ToMe中这三种新技术的每个元素都对实现最先进的性能做出了贡献。
结论与展望
在本文中,我们研究了文本生成图像(T2I)模型中的一个关键难题,即语义绑定。该难题指的是T2I模型难以准确理解并将相关语义正确映射到图像。我们发现了文本嵌入的语义耦合性和可加性,提出了一种无需训练的新方法,称为token合并,即ToMe,用于解决T2I生成中的语义绑定问题。ToMe通过创新性的将对象token与其相关token叠加为一个复合token。该机制通过统一交叉注意力图,消除了语义错位。此外,我们还结合了结束token替换和迭代复合token更新技术,进一步增强语义绑定。此外,本文发现的文本嵌入的可加性在其他领域也表现出一定的应用前景,如下图所示,可用来括添加对象、移除对象,甚至用于消除偏见等任务。

参考文献
[1] Token Merging for Training-Free Semantic Binding in Text-to-Image Synthesis

(文:极市干货)